拉格朗日乘子、拉格朗日对偶问题 (举例说明,通俗易懂) |
您所在的位置:网站首页 › 举例说明max函数的应用 › 拉格朗日乘子、拉格朗日对偶问题 (举例说明,通俗易懂) |
拉格朗日乘子、拉格朗日对偶问题 (举例说明,通俗易懂)
|
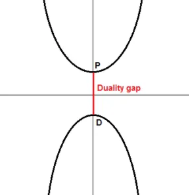
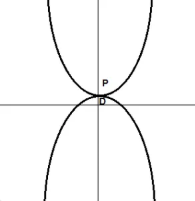
本文通过一系列的例子来说明拉格朗日乘子的运算以及原理,通俗易懂。 1、拉格朗日乘数(乘子)原理定义: In mathematical optimization, the method of Lagrange multipliers is a strategy for finding the local maxima and minima of a function subject to equality constraints. (Wikipedia) 实际上,拉格朗日乘数法(Lagrange Multipliers)是一种求函数极值的方法。 例1:求函数 解法一:直接将 解法二:观察两者的图形: 左图(最大值) 右图(最小值) 从上图(左)可以看出,当函数 从右图可以看出,也是当函数约束相切时,函数取得最大值 8.125,此时 由约束 ↓↓↓↓ 由上可知,拉格朗日乘子就是引入了乘子lambda( 注意:约束 除了上述中 因为只要求函数与约束的梯度(导数)相同,所以有: 将等式用另一符号表示: ↓↓↓↓ 上述函数L,叫做拉格朗日算符(Lagrangian),上式中的 c 代表常数,代表约束方程等号右边的1。 2、拉格朗日乘数(乘子)的解释例2:假设你在假设你在经营一家工厂,生产某种需要钢铁作为原材料的小部件。人力成本(human harbor)20块每小时,钢铁(steel)每吨70元。假设你的收入(Revenue,R)是满足一下方程: 如果成本预算是在20000块,则最大可能受益是多少? 根据以上条件可得到约束方程: 通过带入朗格朗日算符得: 对各参数求导,找到L的临界点: 这个方程可能有好几个解: 通常把临界点的最大值写成 左 中 右 假设预算为变量b,则 用 因此, 对偶定义: In mathematical optimization theory, duality means that optimization problems may be viewed from either of two perspectives, the primal problem or the dual problem (the duality principle). The solution to the dual problem provides a lower bound to the solution of the primal (minimization) problem. (Wikipedia) 对下界的理解(lower bound):假设有一集合 因为集合S的最小值为2,所有小于等于2的值均可为集合S的下界 (lower bound),如1,-3等等。但2是集合S的最大下界,因为其比其他任何下界都要大,因此又叫最大下界(infimum or greatest lower bound),最大下界有且仅有一个。 同样的是,延伸到S集合的最大值12,所有大于等于12的值均可为集合S的上界 (upper-bound),其有最小上界12(supremum)。 通过对偶的定义可以知道,如果有一个最小化问题,则可以把它看做一个最大化问题。最大化问题的最大值就是最小化问题的下界,其永远小于等于最小化问题的最小值。 为什么要用对偶性(duality)?因为有时,解对偶问题( dual problem)比解原始问题(primal problem)简单。 关于下界,对于某些问题,解对偶问题的结果与解原问题的结果是一样的。 如下图(左)所示,对于原始问题,尝试去最小化方程,得到最小值P。通过对偶方程求解,得到最大值点D。从图中可以看出,点D是原始问题的下界。定义 从下图(右)可以看出, 带约束的最优化问题: 一个优化问题的典型写法如下: minimize(x) subject to 上式是优化问题的标准形式,还有一些其他形式。
函数 当存在多个约束时,它们都必须为真。 拉格朗日优化函数为: 如果 假设函数 则最优解: 基本上,它就是用数学符号表示最优值是 进一步分析,因为 对于上式可以这么理解,需要优化的函数 进一步推导可以得到(sup表示函数的上界即最大值): 由推论可知,原问题的最优目标值大于或等于对偶问题的最优目标值。如果不等式是严格不等式,那么它就存在对偶性缺口(上图左)。 4、应用于支持向量机拉格朗日乘子有时被称为不确定乘数(undetermined multipliers),是用来找出一个多变量函数在一个或多个约束条件下的固定点(stationary points)。 已知线性支持向量机的线性模型为: 其拉格朗日方程为(拉格朗日乘子用a表示,同上面的lambda): 注意 具体推导见:https://blog.csdn.net/mengjizhiyou/article/details/103381190 Karush-Kuhn-Tucker(KKT)(5个)条件: 下面通过举例说明拉格朗日乘子在SVMs中的应用。 例3:假设有两点 从上面支持向量机的拉格朗日函数可知: 因为 因此拉格朗日函数可以写成: 求解梯度方程: 解法一:解析解 根据以上方程可得: 由 ↓↓↓↓ ↓↓↓↓ 结合上面 根据 注意,上面算得的参数结果必须符合KKT条件,将参数带入那5个式子算一下是否符合条件。 例3只有两个点,可以通过上述解析解的方式求得参数,但过于复杂。通常支持向量机优化只能在训练数据量非常小的情况下解析求解或者在线性可分离得情况下并且已知哪些点是支持向量。大多数情况下,用数值解。 解法二:拉格朗日对偶 已知: 由 因为KKT里有关于拉格朗日乘子 a 的约束: 所以需要将其考虑进拉格朗日的梯度里,像上面加入约束的方式加入 对参数求导: ↓↓↓↓ ↓↓↓↓ 不需要求出gamma的具体值,因为求w和b时用不到它,将上面 |





【本文地址】
今日新闻 |
推荐新闻 |