『NLP自然语言处理』中文文本的分词、去标点符号、去停用词、词性标注 |
您所在的位置:网站首页 › 中文语气词有哪些 › 『NLP自然语言处理』中文文本的分词、去标点符号、去停用词、词性标注 |
『NLP自然语言处理』中文文本的分词、去标点符号、去停用词、词性标注
|
利用Python代码实现中文文本的自然语言处理,包括分词、去标点符号、去停用词、词性标注&过滤。 在刚开始的每个模块,介绍它的实现。最后会将整个文本处理过程封装成 TextProcess 类。 页面导航 结巴分词词性标注去停用词去标点符号最终代码参考文章 结巴分词jieba 是比较好的中文分词库,在此之前,需要 pip install jieba 结巴分词有三种模式: 全模式 :把句子中所有的可以成词的词语都扫描出来 jieba.cut(text, cut_all=True) 精确模式 :将句子最精确地切开,适合文本分析 jieba.cut(text, cut_all=False) # 默认模式 搜索引擎模式 :在精确模式的基础上,对长词再次切分,适合用于搜索引擎分词 jieba.cut_for_search(txt)三种分词效果如下图所示: 对于一些词,比如“吃鸡”,jieba 往往会将它们分成 “吃” 和 “鸡” ,但是又不太想让它们分开,这该怎么做呢?这时候就需要加载自定义的词典 dict.txt。建立该文档,在其中加入“吃鸡”,执行以下代码: file_userDict = 'dict.txt' # 自定义的词典 jieba.load_userdict(file_userDict)效果对比图: 在用 posseg 分词后,结果是一对值,包括 word 和 flag ,可以用 for 循环获取。关于汉语词性对照表,请看 词性标注表 import jieba.posseg as pseg sentence = "酒店就在海边,去鼓浪屿很方便。" words_pair = pseg.cut(sentence) result = " ".join(["{0}/{1}".format(word, flag) for word, flag in words_pair]) print(result)
去停用词时,首先要用到停用词表,常见的有哈工大停用词表 及 百度停用词表,在网上随便下载一个即可。
导入 re 包,定义标点符号,使用 sub( ) 方法将之替换。 import re sentence = "+蚂=蚁!花!呗/期?免,息★.---《平凡的世界》:了*解一(#@)个“普通人”波涛汹涌的内心世界!" sentenceClean = [] remove_chars = '[·’!"\#$%&\'()#!()*+,-./:;?\@,:?¥★、….>【】[]《》?“”‘’\[\\]^_`{|}~]+' string = re.sub(remove_chars, "", sentence) sentenceClean.append(string) print(sentence) print(sentenceClean)
最后结合上面的内容,将它们封装到一个 TextProcess 类中。 filePath 是刚开始要处理的文本位置, fileSegDonePath 是处理完毕后要保存的位置。 思路是先将要处理的文本逐行保存到一个 fileTrainRead 的列表中,然后有两种方法可供选择: 加载停用词表,对它进行分词及去停用词操作,保存到 word_list_seg 列表中; 或者也可以选择不分词及去停用词,而是直接从句子中提取需要的词性,然后保存到 word_list_pos 列表中。 由于停用词及词性过滤都对句子标点进行了去除,因此该类中不包含标点符号的去除。最后将处理好的句子写入文件中。 import jieba import jieba.posseg as pseg class TextProcess(object): def __init__(self, filePath, fileSegDonePath): self.filePath = filePath # 需要处理的文本位置 self.fileSegDonePath = fileSegDonePath # 处理完毕后的保存位置 self.fileTrainRead = [] # 所有行保存到该列表 self.stopPath = "hit_stopwords.txt" # 自己所用的停用词表位置 self.word_list_seg = [] # 分词及去停用词后保存的列表 self.word_list_pos = [] # 词性过滤后保存的列表 # 将每一行文本依次存放到一个列表 def saveLine(self): count = 0 # 统计行数 with open(self.filePath, encoding='utf-8') as fileTrainRaw: for index, line in enumerate(fileTrainRaw): self.fileTrainRead.append(line) count += 1 print("一共有%d行" % count) return self.fileTrainRead # 加载停用词表 def load_stopword(self): f_stop = open(self.stopPath, encoding='utf-8') # 自己的中文停用词表 sw = [line.strip() for line in f_stop] # strip() 方法用于移除字符串头尾指定的字符(默认为空格) f_stop.close() return sw # 分词并且去停用词,与下一个词性过滤方法选择一个即可 def segLine(self): file_userDict = 'dict.txt' # 自定义的词典 jieba.load_userdict(file_userDict) for i in range(len(self.fileTrainRead)): sentence_seged = jieba.cut(self.fileTrainRead[i].strip()) stopwords = self.load_stopword() outstr = '' for word in sentence_seged: if word not in stopwords: if word != '/t': outstr += word outstr += " " self.word_list_seg.append([outstr]) print("分词及去停用词完成") return self.word_list_seg # 保留特定词性 def posLine(self): for i in range(len(self.fileTrainRead)): tag_filter = ['n', 'd', 'a', 'v', 'f', 'ns', 'vn'] # 需要保留的词性 d-副词 f-方位词 ns-地名 vn-名动词 seg_result = pseg.cut(self.fileTrainRead[i]) # 结果是一个pair,有flag和word两种值 self.word_list_pos.append([" ".join(s.word for s in seg_result if s.flag in tag_filter)]) print("词性过滤完成") return self.word_list_pos # 处理后写入文件 def writeFile(self): with open(self.fileSegDonePath, 'wb') as fs: for i in range(len(self.word_list_seg)): # 选择去停用词方法 fs.write(self.word_list_seg[i][0].encode('utf-8')) fs.write('\n'.encode("utf-8")) ''' for i in range(len(self.word_list_pos)): # 选择词性过滤方法 fs.write(self.word_list_pos[i][0].encode('utf-8')) fs.write('\n'.encode("utf-8")) ''' if __name__ == '__main__': tp = TextProcess('ex.txt', 'final.txt') tp.saveLine() # 将每一行文本依次存放到一个列表 tp.load_stopword() # 加载停用词表 tp.segLine() # tp.posLine() tp.writeFile()原始文本(爬取的酒店评论部分数据): 各方面条件都很好,就是住进去时没有明面窗户屋子里比较潮,后来用了除湿器。 位置特别好,出入方便,酒店前台、门童服务特别好。 就在步行街路口,位置不错。酒店服务也挺好的。 酒店各方面非常不错。“健身房”实在是短板。太影响整体形象 酒店位置很好中山路步行街口,有停车场出行很方便。 早餐品种丰富,工作人员很热情,海景房能观赏鼓浪屿夜景相当不错! 早点丰富,出行方便! 选择去停用词方法效果: 方面 条件 都 很好 住 进去 时 没有 明 面 窗户 屋子里 比较 潮 后来 除湿 器 位置 特别 好 出入 方便 酒店 前台 门童 服务 特别 好 步行街 路口 位置 不错 酒店 服务 挺 好 酒店 方面 非常 不错 健身房 实在 短板 太 影响 整体 形象 酒店 位置 很好 中山路 步行街 口 停车场 出行 很方便 早餐 品种 丰富 工作人员 很 热情 海景房 观赏 鼓浪屿 夜景 相当 不错 早点 丰富 出行 方便 选择词性过滤方法效果: 方面 条件 都 就是 住 进去 时 没有 明 面 窗户 屋子里 比较 潮 除湿 器 位置 特别 出入 方便 酒店 前台 门童 服务 特别 好 就 步行街 位置 不错 酒店 服务 也 挺好 酒店 方面 非常 不错 健身房 实在 是 短板 太 影响 整体 形象 酒店 位置 中山路 步行街 有 停车场 出行 早餐 品种 丰富 工作人员 热情 海景房 能 观赏 鼓浪屿 夜景 相当 不错 早点 丰富 出行 方便 就此结束!^o^y 参考文章NLP-中文文本去除标点符号 |
 想要进一步了解 jieba 三种模式,请参考 详细介绍 。因为我要做的是文本分析,所以选用的是默认的精确模式。
想要进一步了解 jieba 三种模式,请参考 详细介绍 。因为我要做的是文本分析,所以选用的是默认的精确模式。
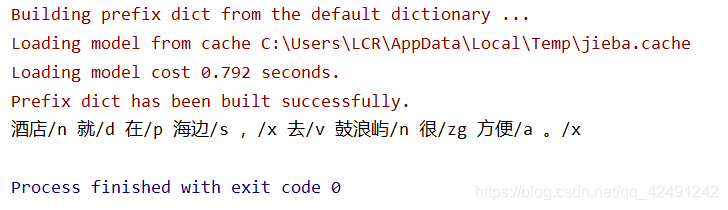 在此基础上,可以进一步做词性过滤,只保留特定词性的词。首先在 tag_filter 表明想要留下哪些词,接着对于词性标注后的句子中的每一个词,如果词性符合,则加入到 list 中。在这里只保留了名词和动词。
在此基础上,可以进一步做词性过滤,只保留特定词性的词。首先在 tag_filter 表明想要留下哪些词,接着对于词性标注后的句子中的每一个词,如果词性符合,则加入到 list 中。在这里只保留了名词和动词。
 在去停用词之前,首先要通过 load_stopword( ) 方法来加载停用词列表,接着按照上文所示,加载自定义词典,对句子进行分词,然后判断分词后的句子中的每一个词,是否在停用词表内,如果不在,就把它加入 outstr,用空格来区分 。
在去停用词之前,首先要通过 load_stopword( ) 方法来加载停用词列表,接着按照上文所示,加载自定义词典,对句子进行分词,然后判断分词后的句子中的每一个词,是否在停用词表内,如果不在,就把它加入 outstr,用空格来区分 。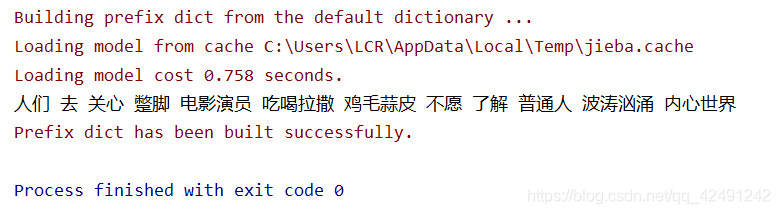

【本文地址】
今日新闻 |
推荐新闻 |