Python人工智能 |
您所在的位置:网站首页 › 中文词语词性的分类 › Python人工智能 |
Python人工智能
|
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章分享了Keras实现RNN和LSTM的文本分类算法,并与传统的机器学习分类算法进行对比实验。这篇文章我们将继续巩固文本分类知识,主要讲解CNN实现中文文本分类的过程,并与贝叶斯、决策树、逻辑回归、随机森林、KNN、SVM等分类算法进行对比。注意,本文以代码为主,文本分类叙述及算法原理推荐阅读前面的文章。基础性文章,希望对您喜欢~ 本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。该专栏也会用心撰写,望对得起读者,共勉!本文参考B站“一只乌龟大王”老师的视频,并结合作者的实战经验进行讲解,再次感谢该老师。 文章目录: 一.文本分类二.基于随机森林的文本分类 1.文本分类 2.算法评价 3.算法对比三.基于CNN的文本分类 1.数据预处理 2.特征提取及Word2Vec词向量转换 3.CNN构建 4.测试可视化四.总结代码下载地址(欢迎大家关注点赞): https://github.com/eastmountyxz/AI-for-TensorFlow https://github.com/eastmountyxz/AI-for-Keras学Python近十年,认识了很多大佬和朋友,感恩。作者的本意是帮助更多初学者入门,因此在github开源了所有代码,也在公众号同步更新。深知自己很菜,得拼命努力前行,编程也没有什么捷径,干就对了。希望未来能更透彻学习和撰写文章,也能在读博几年里学会真正的独立科研。同时非常感谢参考文献中的大佬们的文章和分享。 - https://blog.csdn.net/eastmount 一.文本分类文本分类旨在对文本集按照一定的分类体系或标准进行自动分类标记,属于一种基于分类体系的自动分类。文本分类最早可以追溯到上世纪50年代,那时主要通过专家定义规则来进行文本分类;80年代出现了利用知识工程建立的专家系统;90年代开始借助于机器学习方法,通过人工特征工程和浅层分类模型来进行文本分类。现在多采用词向量以及深度神经网络来进行文本分类。 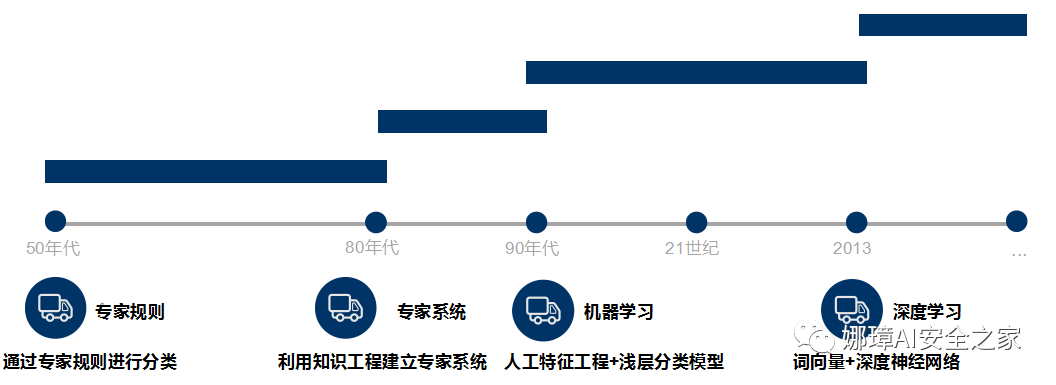 牛亚峰老师将传统的文本分类流程归纳如下图所示。在传统的文本分类中,基本上大部分机器学习方法都在文本分类领域有所应用。主要包括: Naive BayesKNNSVM随机森林 \ 决策树集合类方法最大熵神经网络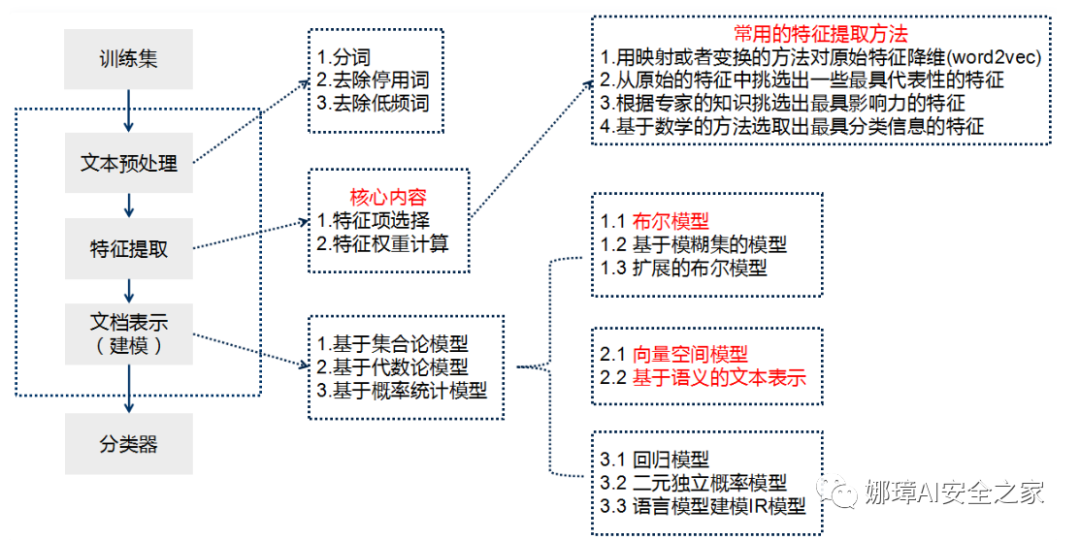 利用Keras框架进行文本分类的基本流程如下: 步骤 1:文本的预处理,分词->去除停用词->统计选择top n的词做为特征词步骤 2:为每个特征词生成ID步骤 3:将文本转化成ID序列,并将左侧补齐步骤 4:训练集shuffle步骤 5:Embedding Layer 将词转化为词向量步骤 6:添加模型,构建神经网络结构步骤 7:训练模型步骤 8:得到准确率、召回率、F1值注意,如果使用TFIDF而非词向量进行文档表示,则直接分词去停后生成TFIDF矩阵后输入模型。本文将采用词向量、TFIDF两种方式进行实验。 在知乎史老师的“https://zhuanlan.zhihu.com/p/34212945”里总结归类来说,基于深度学习的文本分类主要有5个大类别: 词嵌入向量化:word2vec, FastText等卷积神经网络特征提取:TextCNN(卷积神经网络)、Char-CNN等上下文机制:TextRNN(循环神经网络)、BiRNN、BiLSTM、RCNN、TextRCNN(TextRNN+CNN)等记忆存储机制:EntNet, DMN等注意力机制:HAN、TextRNN+Attention等推荐牛亚峰老师的文章:基于 word2vec 和 CNN 的文本分类 :综述 & 实践 二.基于随机森林的文本分类该部分主要围绕常见的文本分类案例进行讲解,由于随机森林效果较好,故主要分享该方法。具体步骤包括: 读取CSV中文文本调用Jieba库实现中文分词及数据清洗特征提取采用TF-IDF或Word2Vec词向量表示基于机器学习的分类准确率、召回率、F值计算及评估1.文本分类(1).数据集 本文的数据为近期贵州黄果树瀑布的旅游评论文本,来自大众点评网,共有240条数据,其中差评数据114条,好评数据126条,如下图所示:  (2) 随机森林文本分类 本文不再详细叙述代码实现过程,前面很多文章都介绍过,并且源代码有详细的注释供大家参考。 # -*- coding:utf-8 -*- import csv import numpy as np import jieba import jieba.analyse from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.ensemble import RandomForestClassifier #----------------------------------第一步 读取文件-------------------------------- file = "data.csv" with open(file, "r", encoding="UTF-8") as f: # 使用csv.DictReader读取文件中的信息 reader = csv.DictReader(f) labels = [] contents = [] for row in reader: # 数据元素获取 if row['label'] == '好评': res = 0 else: res = 1 labels.append(res) content = row['content'] seglist = jieba.cut(content,cut_all=False) #精确模式 output = ' '.join(list(seglist)) #空格拼接 #print(output) contents.append(output) print(labels[:5]) print(contents[:5]) #----------------------------------第二步 数据预处理-------------------------------- # 将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频 vectorizer = CountVectorizer() # 该类会统计每个词语的tf-idf权值 transformer = TfidfTransformer() #第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵 tfidf = transformer.fit_transform(vectorizer.fit_transform(contents)) for n in tfidf[:5]: print(n) #tfidf = tfidf.astype(np.float32) print(type(tfidf)) # 获取词袋模型中的所有词语 word = vectorizer.get_feature_names() for n in word[:5]: print(n) print("单词数量:", len(word)) # 将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重 X = tfidf.toarray() print(X.shape) # 使用 train_test_split 分割 X y 列表 # X_train矩阵的数目对应 y_train列表的数目(一一对应) -->> 用来训练模型 # X_test矩阵的数目对应 (一一对应) -->> 用来测试模型的准确性 X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.3, random_state=1) #----------------------------------第三步 机器学习分类-------------------------------- # 随机森林分类方法模型 # n_estimators:森林中树的数量 clf = RandomForestClassifier(n_estimators=20) # 训练模型 clf.fit(X_train, y_train) # 使用测试值 对 模型的准确度进行计算 print('模型的准确度:{}'.format(clf.score(X_test, y_test))) print("\n") # 预测结果 pre = clf.predict(X_test) print('预测结果:', pre[:10]) print(len(pre), len(y_test)) print(classification_report(y_test, pre))输出结果如下图所示,随机森林的平均准确率为0.86,召回率为0.86,F值也为0.86。 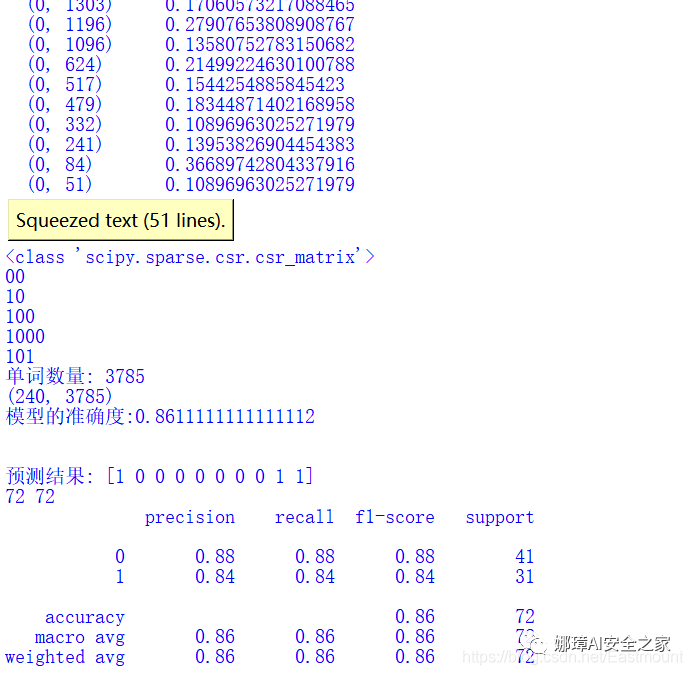 2.算法评价 2.算法评价接着作者尝试自定义准确率(Precision)、召回率(Recall)和F特征值(F-measure),其计算公式如下:  由于本文主要针对2分类问题,其实验评估主要分为0和1两类,完整代码如下: # -*- coding:utf-8 -*- import csv import numpy as np import jieba import jieba.analyse from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.ensemble import RandomForestClassifier #----------------------------------第一步 读取文件-------------------------------- file = "data.csv" with open(file, "r", encoding="UTF-8") as f: # 使用csv.DictReader读取文件中的信息 reader = csv.DictReader(f) labels = [] contents = [] for row in reader: # 数据元素获取 if row['label'] == '好评': res = 0 else: res = 1 labels.append(res) content = row['content'] seglist = jieba.cut(content,cut_all=False) #精确模式 output = ' '.join(list(seglist)) #空格拼接 #print(output) contents.append(output) print(labels[:5]) print(contents[:5]) #----------------------------------第二步 数据预处理-------------------------------- # 将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频 vectorizer = CountVectorizer() # 该类会统计每个词语的tf-idf权值 transformer = TfidfTransformer() #第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵 tfidf = transformer.fit_transform(vectorizer.fit_transform(contents)) for n in tfidf[:5]: print(n) #tfidf = tfidf.astype(np.float32) print(type(tfidf)) # 获取词袋模型中的所有词语 word = vectorizer.get_feature_names() for n in word[:5]: print(n) print("单词数量:", len(word)) # 将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重 X = tfidf.toarray() print(X.shape) # 使用 train_test_split 分割 X y 列表 # X_train矩阵的数目对应 y_train列表的数目(一一对应) -->> 用来训练模型 # X_test矩阵的数目对应 (一一对应) -->> 用来测试模型的准确性 X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.3, random_state=1) #----------------------------------第三步 机器学习分类-------------------------------- # 随机森林分类方法模型 # n_estimators:森林中树的数量 clf = RandomForestClassifier(n_estimators=20) # 训练模型 clf.fit(X_train, y_train) # 使用测试值 对 模型的准确度进行计算 print('模型的准确度:{}'.format(clf.score(X_test, y_test))) print("\n") # 预测结果 pre = clf.predict(X_test) print('预测结果:', pre[:10]) print(len(pre), len(y_test)) print(classification_report(y_test, pre)) #----------------------------------第四步 评价结果-------------------------------- def classification_pj(name, y_test, pre): print("算法评价:", name) # 正确率 Precision = 正确识别的个体总数 / 识别出的个体总数 # 召回率 Recall = 正确识别的个体总数 / 测试集中存在的个体总数 # F值 F-measure = 正确率 * 召回率 * 2 / (正确率 + 召回率) YC_B, YC_G = 0,0 #预测 bad good ZQ_B, ZQ_G = 0,0 #正确 CZ_B, CZ_G = 0,0 #存在 #0-good 1-bad 同时计算防止类标变化 i = 0 while i> 用来训练模型 # X_test矩阵的数目对应 (一一对应) -->> 用来测试模型的准确性 X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.3, random_state=1) #----------------------------------第四步 评价结果-------------------------------- def classification_pj(name, y_test, pre): print("算法评价:", name) # 正确率 Precision = 正确识别的个体总数 / 识别出的个体总数 # 召回率 Recall = 正确识别的个体总数 / 测试集中存在的个体总数 # F值 F-measure = 正确率 * 召回率 * 2 / (正确率 + 召回率) YC_B, YC_G = 0,0 #预测 bad good ZQ_B, ZQ_G = 0,0 #正确 CZ_B, CZ_G = 0,0 #存在 #0-good 1-bad 同时计算防止类标变化 i = 0 while i |
【本文地址】
今日新闻 |
推荐新闻 |