中文分词算法总结 |
您所在的位置:网站首页 › 中文分词算法包括哪些 › 中文分词算法总结 |
中文分词算法总结
|
1 基于词典的分词算法
最大匹配分词算法:贪心算法。trie树,当到根节点时分词,开始查询下一个单词 正向(从左至右)匹配“他说的确实在理”,得出的结果为“他/说/的确/实在/理”。 反向最大匹配,则为“他/说/的/确实/在理”。 可见,词典分词虽然可以在O(n)时间对句子进行分词,但是效果很差,在实际情况中基本不使用此种方法。 考虑语义 得到所有可能分隔,选出最好的 ngram 语言模型判断 最短路径分词算法:先将所有词匹配出来,再寻找由词组成的最短路径 基于NGram的分词算法 利用统计学规律。p(当前词|前n个词)概率 2.基于字的分词相当于标注任务,对每个字给出B(Begin), I(Inside), O(Outside), E(End), S(Single)标记 生成式模型分词算法 主要有n-gram模型、HMM隐马尔可夫模型、朴素贝叶斯分类等。在分词中应用比较多的是n-gram模型和HMM模型。 判别式模型分词算法 主要有感知机、SVM支持向量机、CRF条件随机场、最大熵模型等。在分词中常用的有感知机模型和CRF模型 神经网络分词算法 主要为RNN,常用Bi-LSTM + CRF 3 数据结构词典 词图:邻接矩阵,邻接表 |
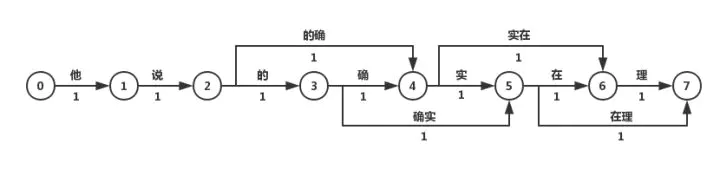 例如0-7的最短路径一定包含1-7的最短路径,因此可以用贪心算法求解
例如0-7的最短路径一定包含1-7的最短路径,因此可以用贪心算法求解【本文地址】