数据结构入门 |
您所在的位置:网站首页 › 中序遍历和先序遍历一样吗 › 数据结构入门 |
数据结构入门
|
遍历二叉树(Traversing Binary Tree)
二叉树的遍历是指从根结点出发,按照某种次序访问二叉树中的所有结点,使得每个结点被访问一次且仅被访问一次。 实际应用中,查找树中符合条件的结点,或对结点进行的各种处理,这里简化为输出结点的数据。 线性结构:容易解决。 二叉树遍历操作的结果----非线性结构线性化 考虑二叉树的组成:
如果限定先左后右,则二叉树遍历方式有三种: 前序(根):DLR; 中序(根):LDR ;后序(根):LRD 注:“先、中、后”的意思是指访问的结点D是先于子树出现还是后于子树出现。
前序(根)遍历 若二叉树为空,则空操作返回;否则: ①访问根结点; ②前序遍历根结点的左子树; ③前序遍历根结点的右子树。 前序遍历序列:A B D G C E F 中序(根)遍历 若二叉树为空,则空操作返回;否则: ①中序遍历根结点的左子树; ②访问根结点; ③中序遍历根结点的右子树。 中序遍历序列:D G B A E C F 后序(根)遍历 若二叉树为空,则空操作返回;否则: ①后序遍历根结点的左子树; ②后序遍历根结点的右子树。 ③访问根结点; 后序遍历序列:G D B E F C A
遍历结果 “恢复”二叉树
已知一棵二叉树的前序序列和中序序列,构造该二叉树的过程如下: 1. 根据前序序列的第一个元素建立根结点; 2. 在中序序列中找到该元素,确定根结点的左右子树的中序序列; 3. 在前序序列中确定左右子树的前序序列; 4. 由左子树的前序序列和中序序列建立左子树; 5. 由右子树的前序序列和中序序列建立右子树。 已知一棵二叉树的后序序列和中序序列,分别是DECBHGFA 和BDCEAFHG 是否可以唯一确定这棵树? ①由后序遍历特征,根结点必在后序序列尾部(即A); ②由中序遍历特征,根结点必在其中间,而且其左部必全部是左子树子孙(即BDCE),其右部必全部是右子树子孙(即FHG); ③继而,根据后序中的DECB子树可确定B为A的左孩子,根据HGF子串可确定F为A的右孩子;以此类推。 遍历的算法实现:递归和非递归实现。 用递归形式格外简单! 二叉树结点的数据类型定义 typedef struct Tnode *BiTree; typedef struct Tnode { int data; BiTree left_child, right_child; } Tnode; //结点数据类型自定义 typedef struct Tnode{ int data; struct Tnode *lchild,*rchild; } Tnode, *BiTree; //先序遍历算法 DLR(Tnode *root ){ if (root){ //非空二叉树 printf(“%d”,root->data); //访问D DLR(root->lchild); //递归遍历左子树 DLR(root->rchild); //递归遍历右子树 } return(0); } //中序遍历算法 LDR(Tnode *root){ if(root){ LDR(root->lchild); printf(“%d”,root->data); LDR(root->rchild); } return(0); } //后序遍历算法 LRD (Tnode *root){ if(root){ LRD(root->lchild); LRD(root->rchild); printf(“%d”,root->data); } return(0); }对遍历的分析 从前面的三种遍历算法可以知道:如果将printf语句抹去,从递归的角度看,这三种算法是完全相同的,或者说这三种遍历算法的访问路径是相同的,只是访问结点的时机不同。
从虚线的出发点到终点的路径 上,每个结点经过3次。 第1次经过时访问=先序遍历 第2次经过时访问=中序遍历 第3次经过时访问=后序遍历 二叉树遍历的时间效率和空间效率 时间效率:O(n) //每个结点只访问一次 空间效率:O(n) //栈占用的最大辅助空间 递归遍历的应用1:计算二叉树中叶子结点的数目 思路:输出叶子结点比较简单,用任何一种遍历算法,凡是左右指针均空者,则为叶子,将其统计并打印出来。 DLR(Tnode *root) //采用先序遍历的递归算法 { if ( root!=NULL ) //非空二叉树条件,还可写成if(root) { if(!root->lchild&&!root->rchild) //是叶子结点 {sum++; printf("%d\n",root->data);} DLR(root->lchild); //递归遍历左子树,直到叶子处; DLR(root->rchild); }//递归遍历右子树,直到叶子处; } return(0); }递归遍历的应用2:二叉树的建立 遍历是二叉树各种操作的基础,可以在遍历的过程中进行各种操作,例如建立一棵二叉树。 为了建立一棵二叉树,将二叉树中每个结点的空指针引出一个虚结点,其值为一特定值如“#”,以标识其为空,把这样处理后的二叉树称为原二叉树的扩展二叉树。
扩展二叉树的前序遍历序列:A B # D # # C # # 设二叉树中的结点均为一个字符。假设扩展二叉树的前序遍历序列由键盘输入,root为指向根结点的指针,二叉链表的建立过程是: 首先输入根结点,若输入的是一个“#”字符,则表明该二叉树为空树,即root=NULL;否则输入的字符应该赋给root->data,,之后依次递归建立它的左子树和右子树 。 思路:利用前序遍历来建树(结点值陆续从键盘输入) Status createBTpre(BiTree T ){ scanf(“%c”,&ch); if(ch==’# ’)T=NULL; else{ T=( Bintree )malloc(sizeof(Tnode)); T->data=ch; createBTpre(T->lchild); createBTpre(T->rchild); } return OK; }递归遍历的应用3:求二叉树深度 求二叉树深度,或从x结点开始的子树深度。 算法思路:只查各结点后继链表指针,若左(右) 孩子的左(右)指针非空,则层次数加1;否则函数返回。 当T= NULL时,深度为0; 否则, T的深度= MAX{左子树深度,右子树深度}+1; int Depth(BiTree T) { if (T= =NULL) return 0; else { hl= Depth(T->lchild); hr= Depth(T ->rchild); return max(hl, hr)+1; } }1. 求二叉树结点数。 int num(BiTree T) { if (T= =NULL) return 0; else { left= num (T->lchild); right= num(T ->rchild); return left+right+1; } }2. 按层次输出二叉树中所有结点。
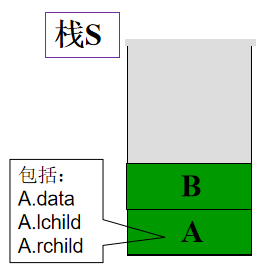
算法思路:既然要求从上到下,从左到右,则利用队列存放各子树结点的指针是个好办法,而不必拘泥于递归算法。 技巧:初始时把根节点入队,当根结点出队后,令其左、右孩子结点入队(空不入队),而左孩子出队时又令它的左右孩子结点入队,……由此便可产生按层次输出的效果。 遍历序列:A B C D E F G 3.判别给定二叉树是否为完全二叉树(即顺序二叉树)。 算法思路:完全二叉树的特点是:没有左子树空而右子树单独存在的情况(前k-1层都是满的,且第k层左边也满)。 技巧:按层序遍历方式,先把所有结点(不管当前结点是否有左右孩子)都入队列.若为完全二叉树,则层序遍历时得到的肯定是一个连续的不包含空指针的序列.如果序列中出现了空指针,则说明不是完全二叉树。 非递归算法——前序遍历 二叉树前序遍历的非递归算法的关键:在前序遍历过某结点的整个左子树后,如何找到该结点的右子树的根指针。 解决办法:在访问完该结点后,将该结点的指针保存在栈中,以便以后能通过它找到该结点的右子树。 在前序遍历中,设要遍历二叉树的根指针为p,则有两种可能: ⑴ 若p!=NULL,Visit(p->data);Push(S,p); p= p->lchild ⑵ 若p=NULL,Pop( S,p); p = p->rchild;
前序遍历——非递归算法(伪代码) 1.栈s初始化; 2.循环直到p为空且栈s为空 2.1 当p不空时循环 2.1.1 输出p->data; 2.1.2 将指针p的值保存到栈中; 2.1.3 继续遍历p的左子树 2.2 当p为空,栈s不空,则 2.2.1 将栈顶元素弹出至p; 2.2.2 准备遍历p的右子树; Status preTraverse(BiTree T,Status( *Visit)(TElemType e)) { //前序遍历的非递归算法 InitStack( S ); p=T; while ( p || !StackEmpty(S) ) {// 栈不空或树不空 if ( p ) { if ( !Visit( p->data) ) return ERROR;访问根结点, Push(S,p); p= p->lchild; } // 根指针进栈,遍历左子树 else { // 左子树访问完了,根指针退栈, 遍历右子树 Pop( S,p); p = p->rchild; } // else } // while return OK; } // InorderTraverse用二叉链表法(l_child, r_child)存储包含n个结点的二叉树,结点的指针区域中会有多少个空指针? 分析:用二叉链表存储包含n个结点的二叉树,结点必有2n个链域(见二叉链表数据类型说明)。 除根结点外,二叉树中每一个结点有且仅有一个双亲(直接前驱),所以只会有n-1个结点的链域存放指针,指向非空子女结点(即直接后继)。所以, 空指针数目=2n-(n-1)=n+1个。 二叉链表空间效率这么低,能否利用这些空闲区存放有用的信息或线索? ——我们可以用它来存放当前结点的直接前驱和后继等线索,以加快查找速度。 ——线索二叉树 线索二叉树(Threaded Binary Tree) 1. 定义普通二叉树只能找到结点的左右孩子信息,而该结点的直接前驱和直接后继只能在遍历过程中获得。 若将遍历后对应的有关前驱和后继预存起来,则从第一个结点开始就能很快“顺藤摸瓜”而遍历整个树了。 例如中序遍历结果:B D C E A F H G,实际上已将二叉树转为线性排列,显然具有唯一前驱和唯一后继。 预存信息两种方法:增加两个域:fwd(存放前驱指针)和bwd(存放后继指针);利用空链域(n+1个空链域) 规定: 1)若结点有左子树,则lchild指向其左孩子; 否则, lchild指向其直接前驱(即线索); 2)若结点有右子树,则rchild指向其右孩子; 否则, rchild指向其直接后继(即线索) 。
为区别两种不同情况,特增加两个标志域(各1bit) 约定:当Tag域为0时,表示正常情况;当Tag域为1时,表示线索情况. 附:有关线索二叉树的几个术语: 线索链表:用含Tag的结点样式所构成的二叉链表。 线 索:指向结点前驱和后继的指针。 线索二叉树:加上线索的二叉树。 线 索 化:对二叉树以某种次序遍历使其变为线索二叉树的过程。 增加了前驱和后继等线索能方便找出当前结点的前驱和后继,不用堆栈也能遍历整个树。 2. 线索二叉树的生成线索化过程就是在遍历过程中修改空指针的过程: 将空的lchild改为结点的直接前驱; 将空的rchild改为结点的直接后继。 非空指针仍然指向孩子结点(称为“正常情况”)
线索二叉树的生成算法 目的:在依某种顺序遍历二叉树时修改空指针,添加前驱或后继。 注解:为方便添加结点的前驱或后继,需要设置两个指针:p指针→当前结点之指针; pre指针→前驱结点之指针。 技巧:当结点p的左/右域为空时,只改写它的左域(装入前驱pre),而其右域(后继)留给下一结点来填写。 或者说,当前结点的指针p应当送到前驱结点的空右域中。 若p->lchild=NULL,则{p->Ltag=1;p->lchild=pre;} //p的前驱结点指针pre存入左空域 若pre->rchild=NULL, 则{pre->Rtag=1;pre->rchild=p;} //p存入其前驱结点pre的右空域 Status InorderThreading(BiThrTree & Thrt, BiThrTree T) { //中序遍历二叉树T,并将其中序线索化, Thrt 指向头结点. if ( ! (Thrt = (BiThrTree) malloc ( sizeof (BiThrnode) ) ) exit ( OVERFLOW ) ; Thrt ->LTag = Link; Thrt ->RTag = Thead; // 建头结点 Thrt ->rchild = Thrt ; //右指针回指 if ( !T ) Thrt ->lchild = Thrt ; // 若二叉树空,则左指针回指 else { Thrt ->lchild = T; pre = Thrt; //将头结点与树相连 InThreading(T); // 中序遍历进行中序线索化 pre ->rchild = Thrt; pre ->RTag = Thread; //最后一个结点线索化 Thrt ->rchild = pre; } return OK; } // InOrderThreading void InThreading (BiThrTree p) { if (p) { InThreading( p->lchild ); // 左子树线索化 if ( !p->lchild ) { p->LTag=Thread; p->lchild=pre; } // 前驱线索 if ( !pre->rchild ) { pre->RTag=Thread; pre->rchild=p; } //后继线索 pre = p; // 保持pre指向p的前驱 InThreading(p->rchild); //右子树线索化 } } // InThreading 3. 线索二叉树的遍历理论上,只要找到序列中的第一个结点,然后依次访问结点的后继直到后继为空时结束。但是,在线索化二叉树中,并不是每个结点都能直接找到其后继的,当标志为0时,R_child=右孩子地址指针,并非后继!需要通过一定运算才能找到它的后继。 以中序线索二叉树为例: 对叶子结点(RTag=1),直接后继指针就在其rchild域内; 对其他结点(RTag=0),直接后继是其右子树最左下的结点; (因为中序遍历规则是LDR,先左再根再右 该结点访问完后,下一个要访问的是其右子树 上第一个要访问的结点) 线索二叉树的中序遍历算法 //程序注解 (非递归,且不用栈): P=T->lchild; //从头结点进入到根结点; while( p!=T) { while(p->LTag==link)p=p->lchild; //先找到中序遍历起点 if(!visit(p->data)) return ERROR; //若起点值为空则出错告警 while(p->RTag==Thread ……){ p=p->rchild; Visit(p->data);} //若有后继标志,则直接提取p->rchild中线索并访问后继结点; p=p->rchild; //当前结点右域不空或已经找好了后继,则一律从结点的右子树开始重复{ }的全部过程。 } Return OK;算法流程
代码实现:二叉树的应用https://blog.csdn.net/qq1457346557/article/details/107122992
|




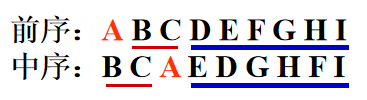


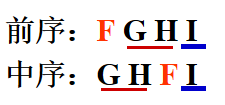

















【本文地址】