工具变量法(两阶段最小二乘法2SLS)线性模型分析人均食品消费时间序列数据和回归诊断... |
您所在的位置:网站首页 › 两阶段最小二乘法和最小二乘法区别 › 工具变量法(两阶段最小二乘法2SLS)线性模型分析人均食品消费时间序列数据和回归诊断... |
工具变量法(两阶段最小二乘法2SLS)线性模型分析人均食品消费时间序列数据和回归诊断...
|
原文链接:http://tecdat.cn/?p=23759 简介两阶段最小二乘法(2SLS)回归拟合的线性模型是一种常用的工具变量估计方法。 本文的主要内容是将各种标准的回归诊断扩展到2SLS。 2SLS估计的回顾我们需要2SLS回归的一些基本结果来开发诊断方法,因此我们在此简单回顾一下该方法。2SLS回归是由Basmann(1957)和Theil(引自Theil 1971)在20世纪50年代独立发明的,他们采取了略微不同但又相当的方法,都在下面描述,以得出2SLS估计器。 我们想估计线性模型y=Xβ+ε,其中y是因变量的n×1观察向量,X是回归因子的n×p矩阵,通常初始列1s为回归常数。β是一个p×1的回归系数向量,需要根据数据进行估计,ε是一个n×1的误差向量,假定其分布为Nn(0,σ2In),其中Nn是多变量正态分布,0是一个n×1的零向量,In是n阶单位矩阵。假设X中的一些(也许是全部)回归因子是内生的,即它们被认为不独立于ε的意义。因此,β的普通最小二乘法(OLS)估计值bOLS=(X⊤X)-1X⊤y通常是有偏的,而且不一致。 现在假设我们有另一组独立于ϵ的q工具变量(IVs)Z,其中q≥p。如果q=p,我们可以直接应用IV来估计β,但如果q>p,我们有更多的IV,而不是我们需要的。简单地抛弃IVs是低效的,2SLS回归是一个通过合理的方式将IVs的数量减少到p的程序。 2SLS的第一阶段通过多元普通最小二乘法对模型矩阵X中的所有回归变量进行回归,得到q×p的回归系数矩阵B=(Z⊤Z)-1Z⊤X,以及拟合值Xˆ=ZB。B的列相当于X的每一列对Z的单独最小二乘回归产生的系数。如果X的某些列是外生的,那么这些列也会出现在Z中,因此,XˆX^中与外生调节器有关的列只是复制了X的相应列。 由于XˆX^的列是Z的列的线性组合,它们(渐进地)与ε不相关,使它们成为估计回归方程的合适IV。这个IV步骤是Theil方法中2SLS的第二个阶段。 作为一种替代方法,我们可以通过对XˆX^进行OLS回归来获得完全相同的β的估计值b2SLS,产生b2SLS=(Xˆ⊤Xˆ)Xˆ⊤y。这就是巴斯曼的方法,也是 "2SLS "这个名字的由来。 无论我们把第二阶段看成是IV估计还是OLS回归,我们都可以把这两个阶段合并成一个公式。
这就是sem包中的tsls()函数(Fox, Nie, and Byrnes 2020)所做的,但是从开发回归诊断的角度来看,通过两个不同的OLS回归来计算2SLS估计值是有利的。 对2Sls回归异常-数据诊断就我们所知,用2SLS拟合的回归模型的诊断是一个相对被忽视的话题,但Belsley, Kuh和Welsch(1980, 266-68)简要地讨论了这个问题。删除诊断法直接评估每个案例对拟合回归模型的影响,方法是删除案例,重新拟合模型,并注意到回归系数或其他回归输出,如残差标准差,如何变化。 对于有影响的数据,总是可以通过粗暴的计算来获得案例删除诊断,即用每个案例依次删除来重新拟合模型,但这种方法效率低下,因此在大样本中没有吸引力。对于某些类别的统计模型,如广义线性模型(如Pregibon 1981),对个案删除诊断的计算要求较低的近似值是可用的,而对于线性模型,有效的 "更新 "公式是可用的(如Belsley, Kuh, and Welsch 1980所描述的),允许精确计算个案删除诊断的。 事实证明,正如Belsley、Kuh和Welsch所指出的,Phillips(1977年,公式15和16)给出了2SLS回归的精确更新公式,允许有效地计算个案选择统计。
其中,b2SLS-i是去除第ii种情况后的2SLS回归系数向量,以及
这里,yi是第i个案例的因变量值,x⊤ixi⊤是模型矩阵X的第i行,z⊤izi⊤是工具变量模型矩阵Z的第i行。 Belsley, Kuh和Welsch特别研究了(用我们的符号)dfbetai=b2SLS-b2SLS-i的值。他们还讨论了残差标准差s-i的删除值。 然后,Belsley、Kuh和Welsch计算它们对拟合值(和回归系数)影响的综合度量dffits为
其中(如前)x⊤ixi⊤是模型矩阵X的第i行,XˆX^是第二阶段回归变量的模型矩阵。 让
代表将y转换为拟合值的n×n矩阵,yˆ=H∗y。在OLS回归中,类似的量是hat矩阵H=X(X⊤X)-1X⊤。Belsley, Kuh和Welsch指出,H∗与H不同,它不是一个正交投影矩阵,将y正交地投影到X的列所跨越的子空间上。特别是,尽管H∗和H一样,是等值的(H∗=H∗H∗),并且trace(H∗)=ptrace(H∗)=p,但H∗和H不同,是不对称的,因此它的对角线元素不能被当作杠杆的总结性措施,也就是说,不能被当作hat值。 Belsley, Kuh和Welsch建议简单地使用第二阶段回归的hat值。这些是H2=Xˆ(Xˆ⊤Xˆ)-1Xˆ⊤的对角线条目hi=hii。我们在下面讨论一些替代方案。 除了hatvalues、dfbeta、s-i和dfits之外,还计算cook距离Di,这基本上是dfits的一个稍有不同的比例版本,它使用总体残差标准差s来代替删除的标准差s-i。
因为它们具有相等的方差,并且在正态线性模型下近似于t分布,所以 studentized残差对于检测异常值和解决正态分布误差的假设非常有用。studentized残差与OLS回归相类似,定义为
其中ei=yi-x⊤ib 2SLS是第i种情况的因变量残差。 如前所述,Belsley, Kuh, and Welsch (1980)建议使用第二阶段回归的 hatvalues。这是一个合理的选择,但是它有可能遗漏那些在第一阶段有高杠杆率但在第二阶段回归中没有的案例。让h(1)i代表第一阶段的hatvalues,h(2)i代表第二阶段的hatvalues。如果模型包括一个截距,两组hatvalues都以1/n和1为界,但第一阶段的平均hatvalues是q/n,而第二阶段的平均hatvalues是p/n。为了使两个阶段的hatvalues具有可比性,我们将每个hatvalues除以其平均值,h(1∗)i=h(1)iq/n;h(2∗)i=h(2)ip/n。然后我们可以把两阶段的hatvalue定义为每种情况下两者中较大的一个,hi=(p/n)×max(h(1∗)i,h(2∗)i),或者定义为它们的几何平均。
标准的R回归模型通用方法,包括anova()(用于模型比较),predicted()用于计算预测值,model.matrix()(用于模型或第一或第二阶段的回归),print(),residuals()(有几种),summary(),update(),和vcov()。 例子数据在Kmenta(1986年)中用来说明(通过2SLS和其他方法)对线性联立方程计量经济学模型的估计。这些数据代表了经济从1922年到1941年的年度时间序列,有以下变量。 Q,人均食品消费 P,食品价格与一般消费价格的比率 D, 可支配收入 F, 前一年农民收到的价格与一般消费价格的比率 A, 年为单位的时间 该数据集很小,我们可以对其进行检查。
估计以下两个方程式模型,第一个方程式代表需求,第二个代表供应。
变量D、F和A被视为外生变量,当然常数回归因子(一列1)也是如此,而两个结构方程中的P是内生解释变量。由于有四个工具变量可用,第一个结构方程有三个系数,是过度识别的,而第二个结构方程有四个系数,是刚刚识别的。 点击标题查阅往期内容
R语言工具变量与两阶段最小二乘法
左右滑动查看更多
01
02
03
04
外生变量的数值是真实的,而内生变量的数值是由Kmenta根据模型生成(即模拟)的,参数的假设值如下。
解决内生变量P和Q的结构方程,可以得到模型的简化形式
Kmenta独立地从N(0,1)中抽出20个δ1和δ2的值,然后设定ν1=2δ1和
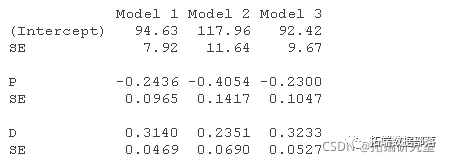
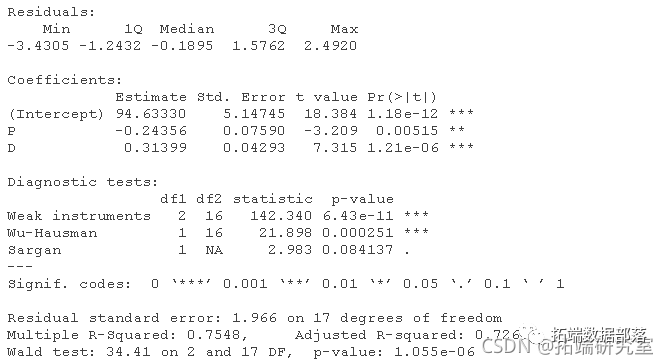
结构方程估计如下(比较Kmenta 1986, 686)。
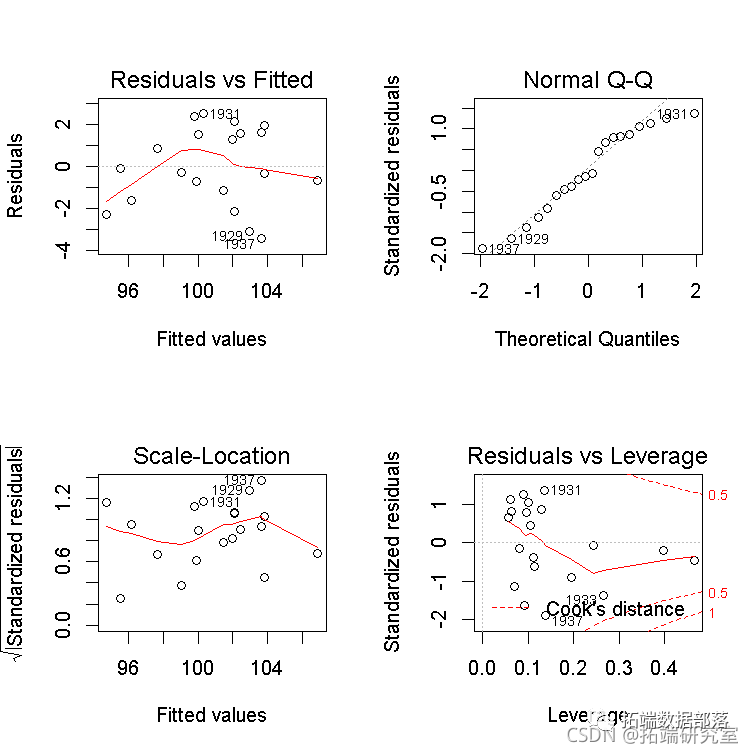
默认情况下,summary()会输出2SLS回归的三个 "诊断 "测试的结果。这些测试不是本文的重点,所以我们只对它们进行简单的评论。 一个好的工具变量与一个或多个解释变量高度相关,同时与误差保持不相关。如果一个内生的回归者与工具变量只有微弱的关系,那么它的系数将被不精确地估计。在弱工具的诊断测试中,我们希望有一个大的测试统计量和小的p值,Kmenta模型中的两个回归方程就是如此。 应用于2SLS回归中,Wu-Hausman检验是对内生性的一种检验。如果所有的回归者都是外生的,那么OLS和2SLS的估计都是一致的,并且OLS的估计更有效,但是如果一个或多个回归者是内生的,那么OLS的估计就不一致了。大的检验统计量和小的p值,就像在这个例子中一样,表明OLS估计器是不一致的,因此,2SLS估计器是首选。 Sargan检验是对过度识别的检验。也就是说,在一个过度识别的回归方程中,如Kmenta的需求方程中,工具变量比要估计的系数多,工具变量有可能提供关于系数值的冲突信息。因此,大的检验统计量和小的Sargan检验的pp值表明,该模型被错误地指定了。在这个例子中,尽管我们知道(通过数据的构建方式)需求方程是正确的,但我们还是偶然得到了一个适度小的pp值0.084。Sargan检验不适用于刚刚确定的回归方程,其工具变量和系数的数量相等,如Kmenta的供给方程。 lm "类对象的几个方法与产生的对象正常工作。例如,对象的plot()方法调用了相应的 "lm "方法并产生了可解释的图,这里是Kmenta模型中需求方程的2SLS拟合。 par(mfrow=c(2, 2)) plot(deq)
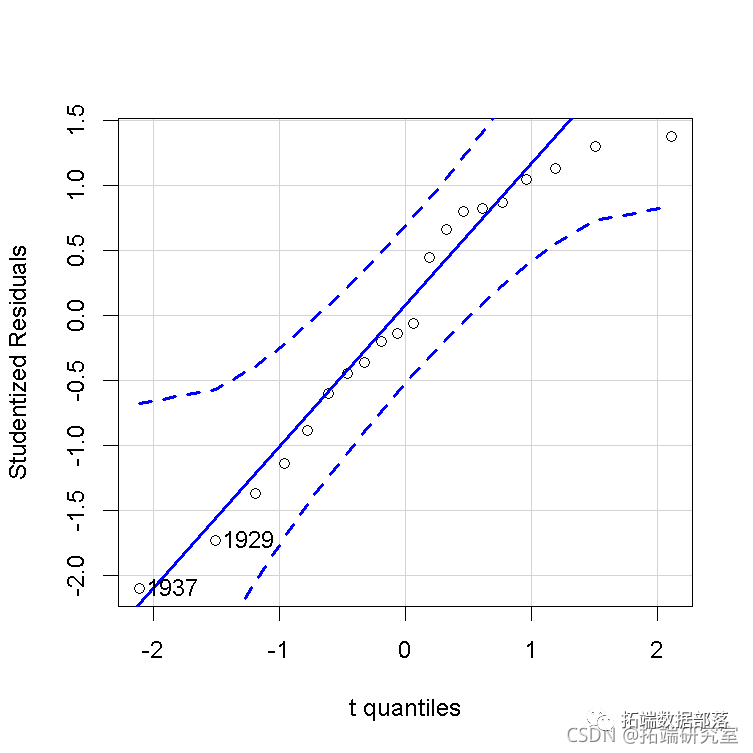
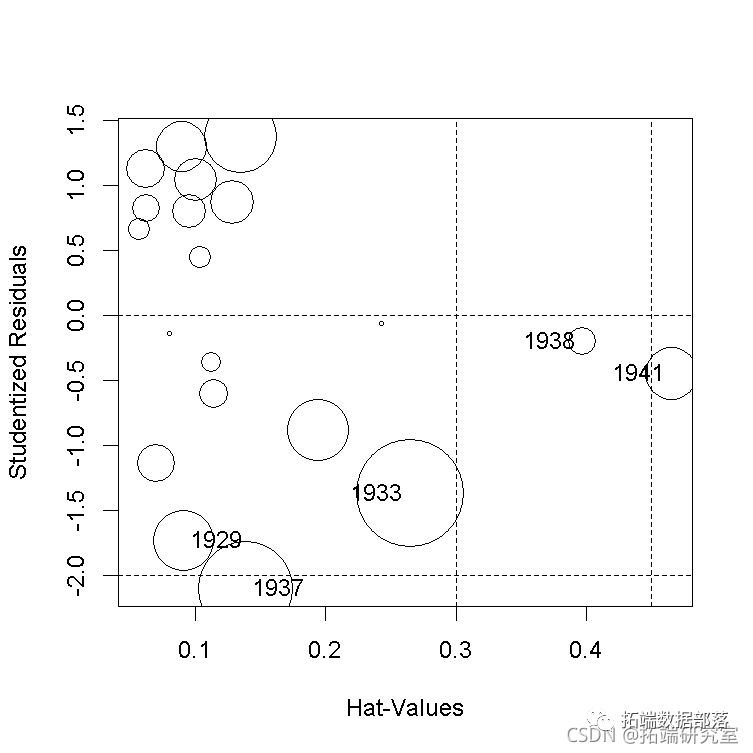
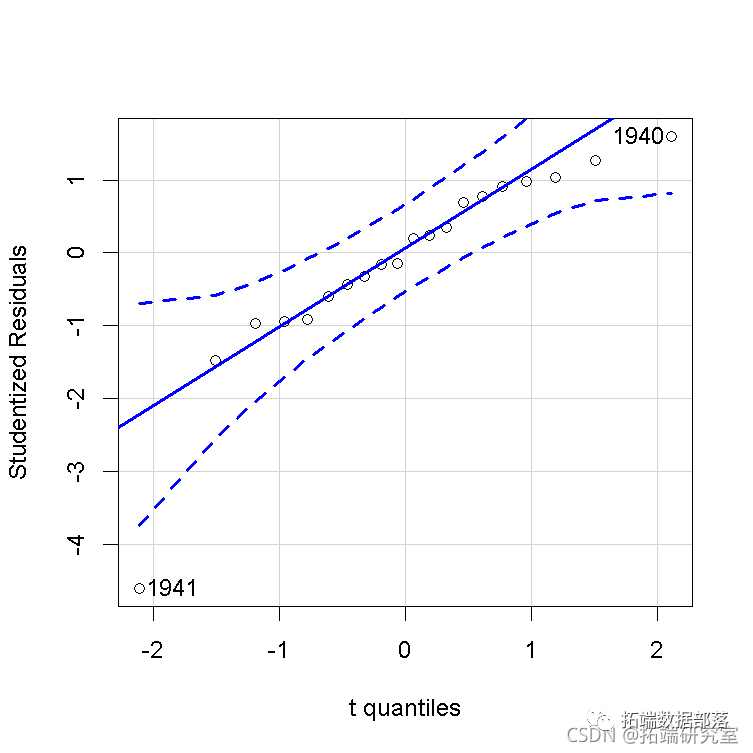
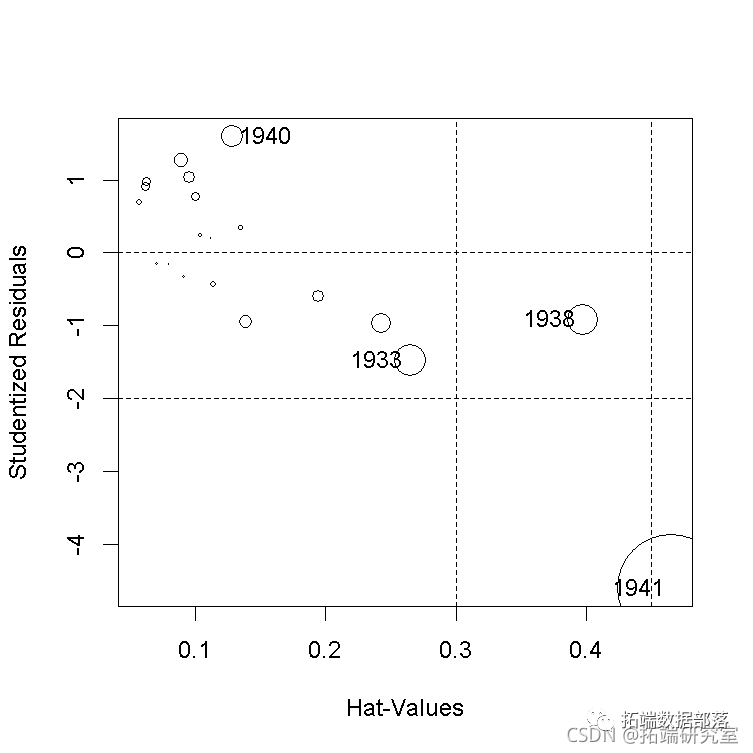
然而,在这种情况下,我们更喜欢描述的这些诊断图的版本。 数据表现良好。例如,在第一个结构方程中,学生化残差的QQ图和hatvalues、学生化残差和库克cook距离的 "影响图 "都是不明显的,除了几个高杠杆但在一起的案例。 qqPlot
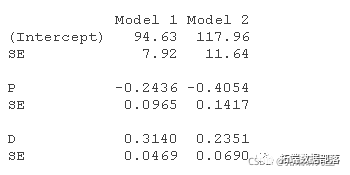
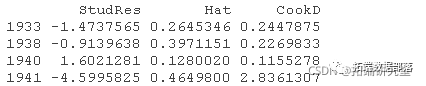
影响图中的圆圈面积与Cook's D成正比,水平线画在学生化残差标度的0和±2处(rstudent=2处的水平线不在图中),垂直线在2×h¯和3×h¯处。 为了产生一个更有趣的例子,我们将把高杠杆的第20种情况(即1941年)的QQ值从Q20=106.232改为Q20=95,这个值完全在数据中QQ的范围内,但与其他数据不一致。 然后重复对第一个结构方程的2SLS拟合,并将结果与未被破坏的数据进行比较,发现回归系数有很大变化。 compareCoefs(deq, deq1)
有问题的第20个案例(1941年)通过异常数据回归诊断法清楚地显示出来。 qqPlot(deq1)
去掉第20种情况,产生的估计系数接近于未被破坏的数据的系数。 compareCoefs(deq, deq1, deq1.20)
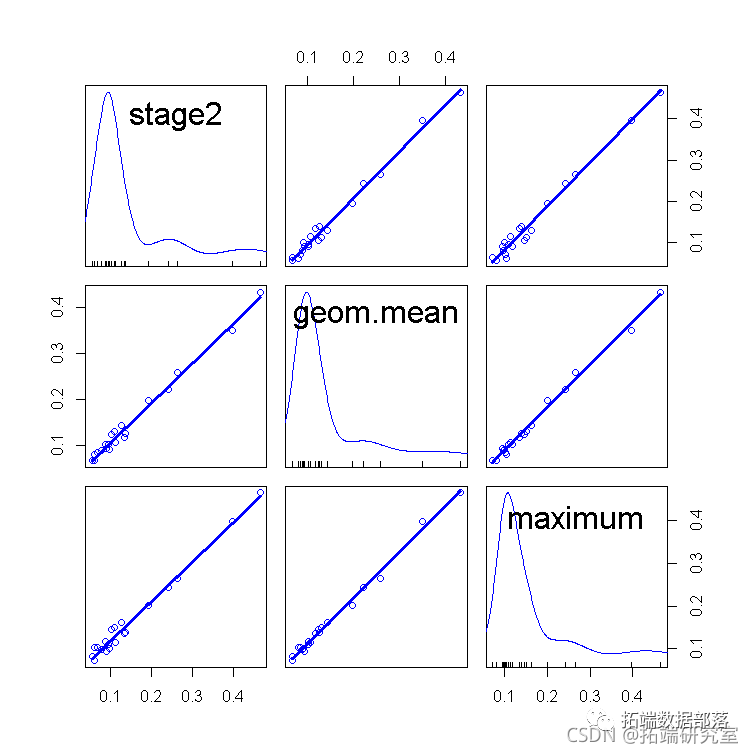
估计系数的标准误差比原来大,因为我们现在有19个而不是20个案例,也因为解释变量的变化减少了。 发现hatvaues的三种定义是否对这个例子产生了实际的影响,是有一定的意义的。三种hatvalues的散点图矩阵表明,它们都产生了类似的结果。
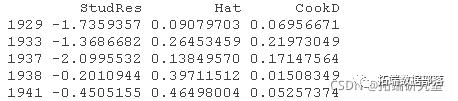
最后,让我们验证一下删除诊断的计算结果是否正确。
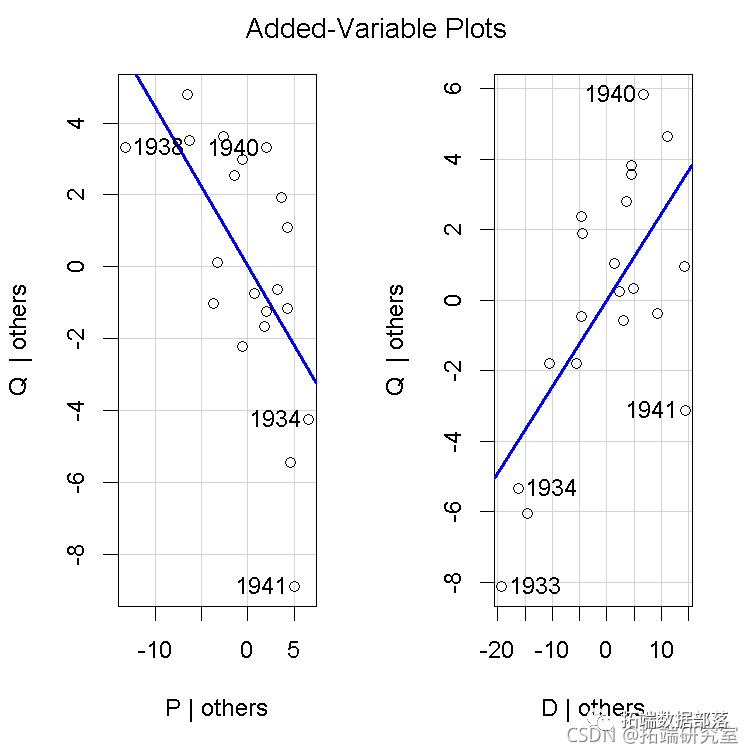
Cook(1993)和Cook and Croos-Dabrera(1998)系统地探讨了成分、残差图作为非线性诊断的理论属性。按照这些作者的说法,并把重点放在解释变量x1上,让我们假设响应y与x1的部分关系可能是非线性的,由部分回归函数f(x1)表示,而y与其他xxs的部分关系是线性的,因此,数据的准确模型是。
我们不知道f(),所以改用工作模型来拟合
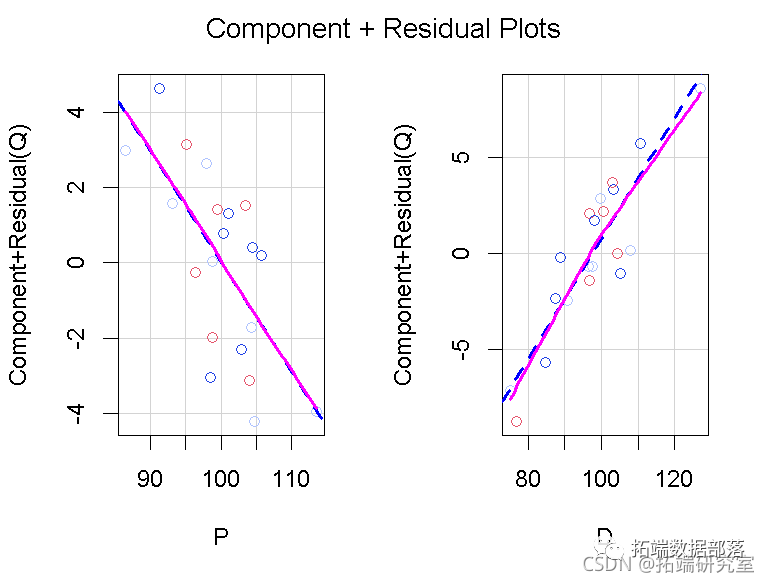
在我们的例子中,通过2SLS回归,得到估计的回归系数a′,b′1,b′2,...,b′k。Cook和Croos-Dabrera的工作表明,只要回归估计是一致的,XXS是线性相关的。部分残差b′1x1+e可以被绘制出来,并对x1x1进行平滑处理,以显示f()的估计。其中e=y-(a′+b′1x1+b′2x2+⋯b′kxk)是因变量残差。在实践中,如果x1和其他xxs之间有很强的非线性关系,或者y与另一个与x1相关的x有非线性关系,那么分量加残差图就会被分解为f()的准确表示。 Fox和Weisberg(2018)将成分加残差图扩展到更复杂的回归模型,例如可以包括交互作用,将偏残差添加到预测变量效应图中。这些图也可以应用于由2SLS回归拟合的线性模型。 诊断非线性:一个例子我们再一次转向Kmenta的数据和模型的需求方程来说明成分残差图,数据再一次表现良好。为一个加法回归方程中的所有数字解释变量构建了分量残差图。比如说。 crPlots(deq, smooth=list(span=1))
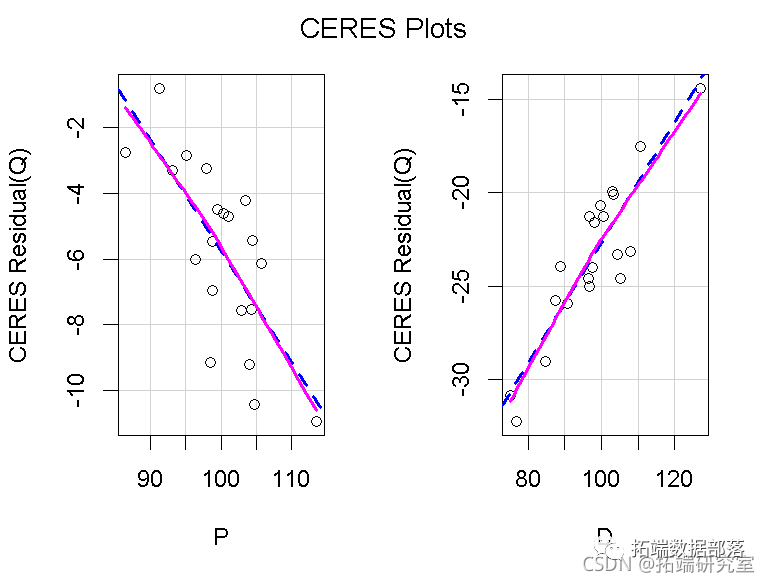
我们在图中为局部加权回归loess 平滑(Cleveland, Grosse, and Shyu 1992)设置了一个较大的跨度,因为在数据集中只有n=20个案例。跨度的默认值是2/3。在每个面板中,红线给出的loess 平滑度与蓝线给出的最小二乘线紧密匹配,蓝线代表的是解释变量方向的拟合回归面,左边是P,右边是D。因此,两种偏关系似乎都是线性的。 CERES图(Cook 1993),是成分加残差图的一个版本,它使用平滑器而不是线性回归,因此对预测因子之间的非线性关系更加稳定。 ceresPlots(deq, smooth=list(span=1))
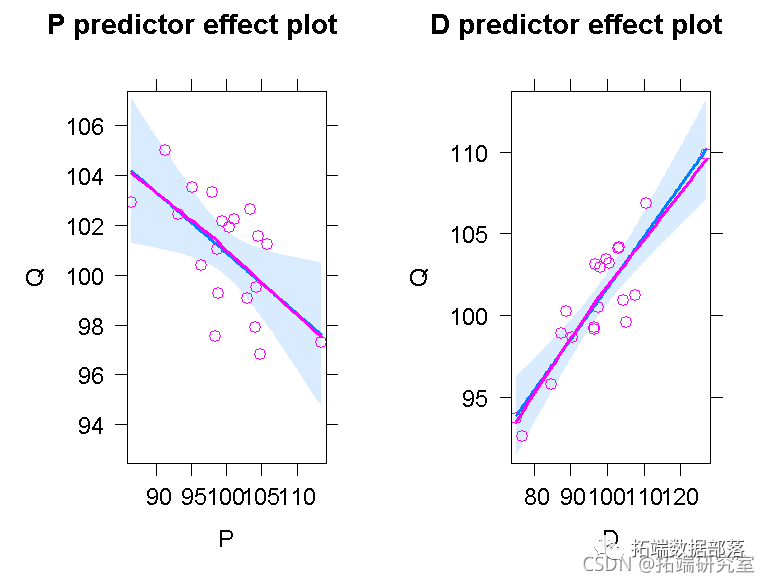
在当前的例子中,这是一个加性模型,我们得到的图形与之前的基本相同,只是y轴的缩放比例不同。 plot(predictorEffects)
预测效应图中的蓝色阴影区域代表拟合的部分回归线周围95%的置信度包络。 然而,假设我们对数据拟合了错误的模型。 deq2 0,建议的变换是顺着Tukey的幂和根的阶梯,例如,λ=1-b=1/2代表平方根变换,λ=1-b=0代表对数变换,以此类推。对于模型,我们有
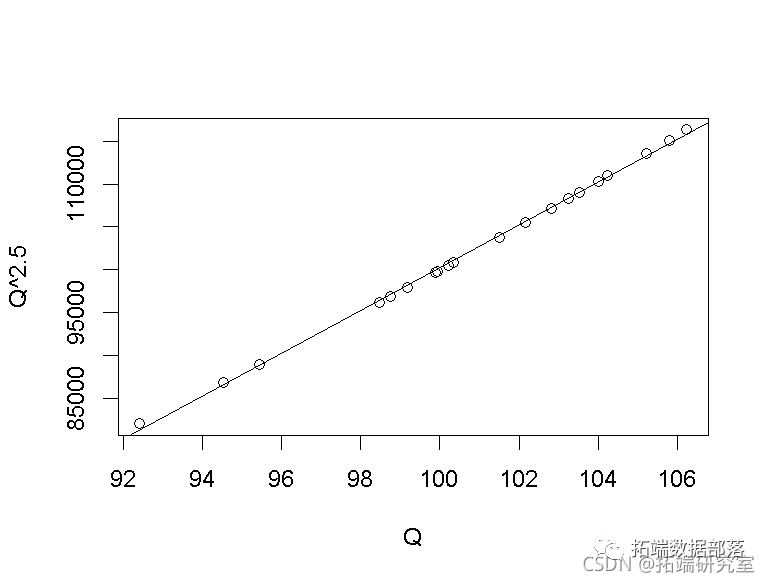
这表明分布有随水平提高的轻微趋势。λ=-2.45的转换似乎很强,直到我们注意到QQ的值离0很远,而且最大和最小的值Qmax/Qmin=106.23/92.42=1.15的比率接近1,所以Q-2.45几乎是QQ的线性转换,也就是说,实际上根本没有转换。
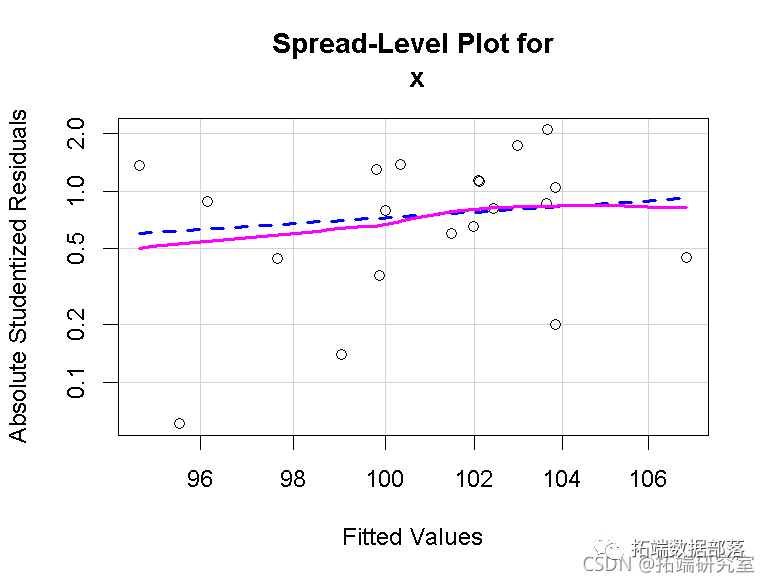
由Breusch和Pagan(1979)提出的最小二乘回归中的非恒定误差方差的普通分数测试,是基于模型的
其中函数g()是未指定的,变量z1,...,zs是误差方差的预测因子。在最常见的应用中,由Cook和Weisberg(1983)独立提出,有一个zz,即回归的拟合值yˆ,尽管使用初级回归中的回归者x作为zs也很常见。测试是通过将标准化残差的平方e2i/σˆ2回归到zs上实现的,其中σˆ2=∑e2i/n。然后,在误差方差不变的无效假设下,该辅助回归的回归平方和除以2的渐近分布为χ2s。 Breusch-Pagan/Cook-Weisberg检验很容易适应2SLS回归。对于需求方程。
在这里,第一个检验是针对拟合值的,第二个更一般的检验是针对需求方程中的解释变量的;这两个检验的p值都很大,表明没有什么证据反对恒定方差的假说。 2SLS回归中对非恒定方差的补救方法与最小二乘回归中的补救方法相似。 我们已经提出,如果误差方差随着响应水平的提高(或降低),并且因变量是正的,那么我们就可以通过对因变量进行幂变换来稳定误差方差。 另外,如果我们知道误差的方差与一个常数成正比,那么我们可以对2SLS估计使用反方差加权。 最后,我们可以在2SLS中使用系数协方差矩阵的估计(或自举法:例如,见Davison和Hinkley 1997)来修正非恒定误差方差的标准误差,就像Huber(1967)和White(1980;也见Long和Ervin 2000)提出的最小二乘法回归那样。 对于例子,非恒定误差方差的证据是轻微的,标准误差与传统的2SLS标准误差相似,甚至比它略小。
我们将修改数据以反映非恒定误差方差,像最初那样从还原形式方程中重新生成数据,将内生变量P和Q表示为外生变量D、F和A的函数,以及还原形式误差ν1和ν2。 w |

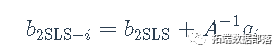
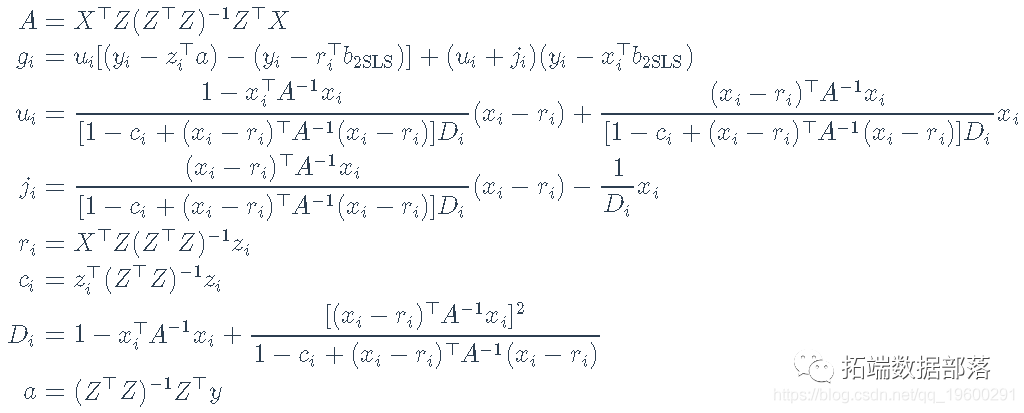
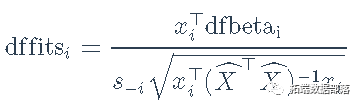
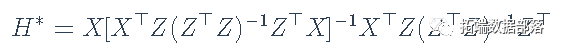
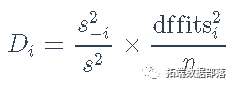
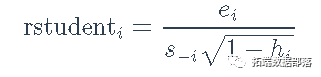
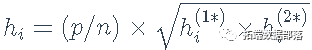

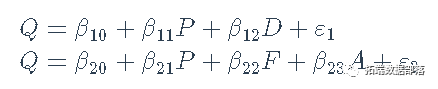






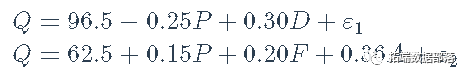
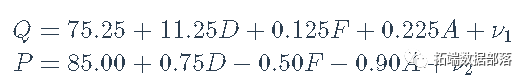
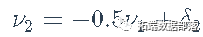



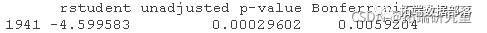


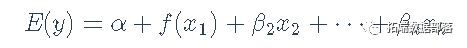
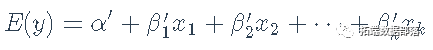

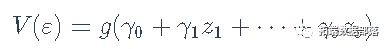
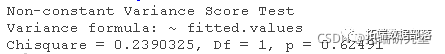
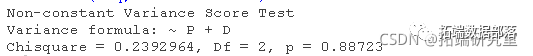

【本文地址】
今日新闻 |
推荐新闻 |