SVC真实数据案例:预测明天是否会下雨(包括数据预处理和建模过程) |
您所在的位置:网站首页 › 下一周会下雨吗 › SVC真实数据案例:预测明天是否会下雨(包括数据预处理和建模过程) |
SVC真实数据案例:预测明天是否会下雨(包括数据预处理和建模过程)
|
文章目录
SVC真实数据案例:预测明天是否会下雨处理困难特征:时间处理困难特征:地点处理分类变量用众数填补缺失值进行编码
处理连续型变量统一量纲:标准化建模与模型评估选择最佳的kernel
模型调参追求最高Recall追求高准确率追求平衡画ROC曲线,找到最佳阈值,通过调整阈值来判断准确率和召回率
SVC真实数据案例:预测明天是否会下雨
一般来说很少能一次性导入所有需要的库,可以一边码一边添 import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from math import radians, sin, cos, acos import sys import re from sklearn.impute import SimpleImputer from sklearn.preprocessing import OrdinalEncoder from sklearn.preprocessing import StandardScaler from time import time import datetime from sklearn.svm import SVC from sklearn.model_selection import cross_val_score from sklearn.metrics import roc_auc_score, recall_score from sklearn.metrics import confusion_matrix as CM import matplotlib.pyplot as plt from sklearn.metrics import roc_curve as ROC from sklearn.metrics import accuracy_score as AC weather = pd.read_csv("weatherAUS5000.csv", index_col=0) print(weather.head()) print(weather.info()) #探索数据集特征
缺失率低的字段可以不进行填补 查看是否存在样本不均衡的问题 y_label_count = ytrain.value_counts() print(y_label_count)可以看出来yes是少数类,no是多数类,少数类的标签是1,多数类的标签是0,多少有一点样本不均衡,比例基本上是在3:1左右 观察特征中具体的值,是否存在不符合常理的情况 xtrain.describe([0.01, 0.05, 0.1, 0.25, 0.5, 0.75, 0.9, 0.99]).T xtest.describe([0.01, 0.05, 0.1, 0.25, 0.5, 0.75, 0.9, 0.99]).T其中温度有零下摄氏度的情况,有负数是正常表现。没有特别严重的偏态问题,就是量纲不统一,一会一起处理。 接下来处理最难的两个特征:时间和地点,因为时间和地点在一定程度上影响降雨量,但是我们又没有办法让计算机直接了解到这一点,所以需要对这两个特征进行转换。首先,我们需要把时间转换成数字型;其次,还需要将时间转化为月份,因为不同的月份所处季节不同,降雨的概率也不同。地点就转换为气候类型。 #首先我们来看一下时间,同一个时间是否只出现一次,如果是,那有可能是时序数据,如果不是,考虑是否能进行分类 xtrain.iloc[:, 0].value_counts()可以发现每个时间并不是只出现一次。如果我们把它当作分类型变量处理,类别太多,有2141类,如果换成数值型,会被直接当成连续型变量,如果做成哑变量,我们特征的维度会爆炸。那我们可以换一种思路,既然算法处理的是列与列之间的关系,我是否可以把”今天的天气会影响明天的天气“这个指标转换成一个特征呢?因此,我们可以将时间对气候的连续影响,转换为”今天是否下雨“这个特征,巧妙地将样本对应标签之间的联系,转换成是特征与标签之间的联系 了。 |
 object是文本类型数据集,一共有22个特征(字段)大部分字段有缺失值
object是文本类型数据集,一共有22个特征(字段)大部分字段有缺失值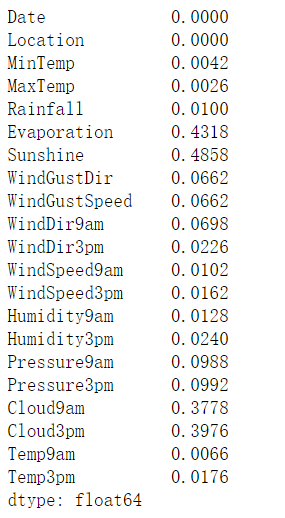 在实际情况下,通常很难得到测试集,所以我们在这个案例中提前将训练集和测试集进行拆分,拆分之后要更新索引
在实际情况下,通常很难得到测试集,所以我们在这个案例中提前将训练集和测试集进行拆分,拆分之后要更新索引
 测试集和训练集的分布比较接近,没有特别严重的问题
测试集和训练集的分布比较接近,没有特别严重的问题 

【本文地址】
今日新闻 |
推荐新闻 |