搞搞字节,byte的小知识 |
您所在的位置:网站首页 › 一个数字是几个字节 › 搞搞字节,byte的小知识 |
搞搞字节,byte的小知识
|
0和1 0和1是计算机的基石,000111111... 本文讲讲其中的一些小细节,小知识点,2's complement, 变长编码,等等,不定期补充更多的小知识点。 大部分只有写特别的代码才会接触,而如果你掌握其中的思想,那么就能以不变应万变。 阅读完本文,就会明白 负数在计算机怎么被表示,为什么要用2的补码来表示?为什么2的补码是取反码,然后加上1?知道一个数,怎么求它的2的补码?知道2的补码,怎么知道原来的数是多少?UTF-8怎么理解?LEB128又是什么?二进制单位bit,中文译为位,是指0或者1两个状态,是二进制中是最小的单位。 byte,即字节,有8个位。 当用16进制表示的时候,0xAB是一个byte,但是看起来是有两个数字。其中一个数字表示4bit。 一位叫bit,8位叫byte,猜猜4位叫什么?答案,是nibble。用得比较少。但是我还是喜欢它,因为它对应着16进制的时候的一个数字,比如一个字节0xAB, A或者B就是一个nibble. 进制和转换我们大部分人熟悉的是10进制。0,1,2,3,4,5,6,7,8,9。 135代表着1*10^2 + 3 *10^1 + 5* 10^0 而程序员熟悉的还有2进制(前缀0b),8进制(前缀0),16进制(前缀0x)。 10进制数字如何表示成2进制,8进制,16进制呢?这个估计大家都比较熟悉了。 以及2进制,8进制,16进制这些互转大家也很熟悉。 我一般都是直接开个gdb或者lldb来转换,比如  这里面有个小知识点:转换的目标包含的位数更少时,高位会被截断了。 比如0x12345678,一个四个字节,对应着int,那么我们转成2个字节长度的short int时候,会变成什么呢?  正如数字的发展从1开始,到正数,0,再到负数。 当我们用10进制的时候,表示负数,会在前面加个负号-。 而在计算机里面,我们不能用负号,因为我们只有0和1这两个数字。 接下来看看用0和1如何表示负数。 表示负数反码让我们先接触另外一个概念,反码。 数的反码是把每一位取反然后得到,比如0xB,表示为2进制为0b1011,它的反码是0b0100,即,0x4, 也可以这么算,拿15去减,15-0xB = 0x4。所以0xB的反码就是0x4。 任意数字的反码的每个nibble,等于15减去这个数字的每个nibble,如0xAB的反码 = 0x(15-A)(15-B) = 0x54。 这很好理解,因为每一位取反,对于nibble来说,相当于与上15/0xF,也就是拿15去减。 15以内的减法大家肯定很熟悉~所以取反码,可以拿15减去每个nibble得到新的nibble。 知道了反码,让我们继续看看如何表示负数。 因为计算机里面只有0和1,那么表示也只能用0和1来表示正和负。比较朴素的想法是可以用第一位(最高位)来表示正负,0表示正,1表示负数。剩下的位数表示具体的大小。 那么最高位是哪一位呢?这就要知道计算机里面的另外一个概念,有限字节长度的数字~ 有限字节长度我们在讨论计算机里面的数字的时候,都会假定在讨论多少个字节长度的数字。 比如我们说15,都会预设是多少字节长度的。如果是两个字节长度的15,应该写作0x000F,如果一个字节的15就会是0x0F。 有人会说,这有什么区别?前面不都是0嘛。 区别是 对于两个字节长度的15,它的最高位是第16位(从右边数)。而对于一个字节的15,它的最高位是第8位.决定相加会不会溢出。比如一个字节的255 + 1就会溢出,它的结果是0x00,而两个字节长度的255+1等于256,即0x0100,不会溢出。回到最高位表示正负的方法,那么1个字节长度的数字,只能表示2^7个数字,因为只有7位可以用来计数。而两个字节长度的数字,能表示2^15个数字。 假设一个字节长度的数字,那么-9就表示为0x89。 这种表示方法,有两个“别扭”的地方, 0有两种表现形式,即+0和-0。+0为0x00,-0为0x80。减法不好执行,比如3-1,3是0x03,而-1是0x81。那么怎么计算0x03 - 0x81。所以大师们继续思考着另外的表示方法。 1的补码-9 = 0-9,那么我们是不是可以用0-9表示-9。 0-9跟数字9的反码异曲同工,所以诞生了反码来表示负数。 这种方式,又叫1的补码(后面会解释为什么叫1的补码),所以用1的补码来表示,即一个负数,可以用它的绝对值对应的反码来表示。 比如,-9,对应的绝对值为9, 9的反码为0xF6(快速计算反码,只需记住用15去减每个nibble)。 这样用最高位表示正负,剩下的位数表示大小的方法,把整数分成了三个阵营。 比如对于1字节长度的整数,把0到0xFF分为了三个阵营: 0x1到0x7F表示正数,0x81到0xFF表示负数,0x00和0x80表示0.1的补码可以表示的整数范围是-127到127。 用1的补码表示负数,那么两个数相减,可以转换为相加,比如一字节长度的整数,3-1= 3 + (-1) = 0x03 + 0xFE = 0x01 + 1(1因为有溢出了,我们要把溢出位加回来) 虽然相减可以直接转换为相加了,但是还是有点别扭。而且0仍然具有两种形式,0x00表示+0,0x80表示-0。 2的补码所以大师们继续思考,发现可以将末尾和开始的数字连成一个环形,  减去一个数x,可以认为是往回走(往箭头的反方向)走x步,走到某个圆。因为已经连成了一个环,那么效果等同于往前(按箭头方向走)走y步,到达同样的圆。 比如1减去1等于往回走一步到灰色的圆0,因为首尾相连了,那么也等于是往前走了3步到达灰色的圆0。 数学里有个工具,非常切合这个走法,这个工具就是取模 mod 2^n,又叫2的补码,因为mod 2^n = 2^n - x。 当数字长度为两个字节时候,那么, -1 的2的补码 = -1 mod 2^8 = 2^8 - 1 = 0xFF = 2^8 -1 -1 +1 = 对1取反码,然后加上1 = 1的补码加上1 所以负数-x(x>0),站在圆x,然后向前走y格到达灰色圆圈0,这个数字y的二进制表示,就是负数-x的2的补码表示形式, y = 2^n -x=2^n + (-x) 也就是负数的2的补码等于这个负数加上2^n 。正数的2的补码等于它本身。 (本文当没有说是1的补码还是2的补码,统一认为是2的补码) 提问,那么知道一个数x的补码为y,怎么知道这个数x是多少? 首先,如果使用2的补码来表示数,那么说明我们是有正有负的,那么当最高位是0的时候,这个数x是正数,所以x = y,如果最高位是1,那么这个数是负数,所以x = 2^n - y。(下次有机会讲讲取模mod) 再次提问,如果知道一个数x,那么怎么知道这个数x的2的补码是多少? 2补码的好处是减法可以变成加法,比如x -y = x + (-y的2的补码),(x>0, y>0)。 而且0也只有一种表现形式+0=-0。原来的0xFF则表示-1。提问,为什么是-1呢? 这就是2的补码形式,即, 2‘s complement code。现在大部分计算机都用2补码来表示负数。 编码2的补码,是一种编码:对负数的编码。 编码涉及到两个数字,数字O和数字N。数字O可以认为是什么,而数字N可以认为是长什么样的。 编码就是把数字O用数字N来表示。解码就是知道数字N,找到原来的数字O。  在2的补码中,负数是数字O,补码则为数字N。 计算机只认得0和1,那么怎么表示一个字符A呢?下面让我们来看看字符集和字符编码。 首先我们要先知道什么是字符集—— 字符集计算机只认得0和1,那么怎么知道这个0和1组成的数字是字符A呢? 答,约定! 电影里,会约定卧底的暗号,这样如果看到暗号就知道是自己人。 字符集,也是类似的道理。比如我们约定看到0就说明是字符A,所以字符集指的是使用数字约定对应的字符, 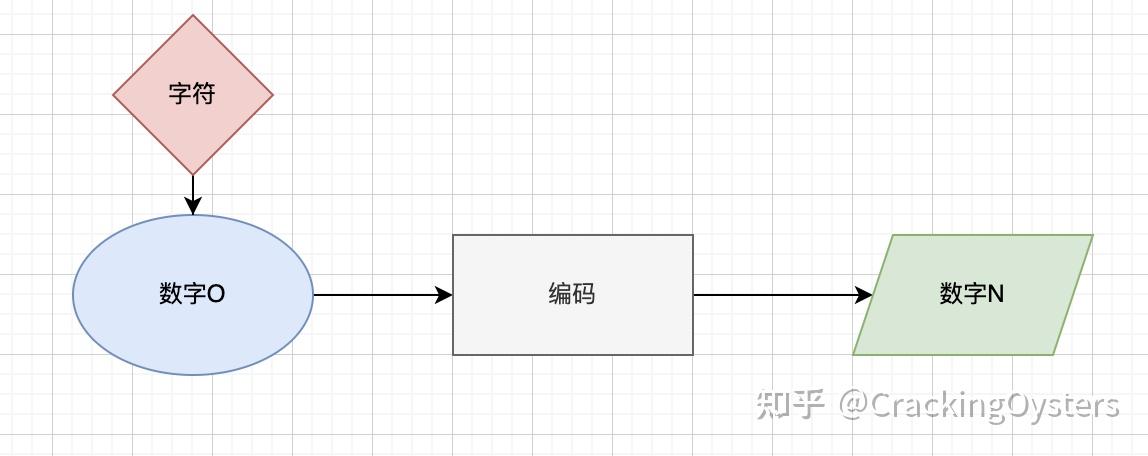 一开始的时候只有ASCII,也就是英文字母,特殊字符和一些控制字符,所以那会使用7个比特的数字,比如约定0x0A是换行符。 后面发现字符好多,用7位不够用,而且如果同样的字符不同的国家对应不同的数字,那么会很难交流。 所以Unicode诞生了,它就是相当于一个中央机构来负责规定每一个字符对应的数字。  比如规定U+1F643表示倒着的☺。 所以Unicode解决的问题是给每一个字符一个数字,相当于ID。 字符编码明白了unicode规定字符对应的数字,字符编码的问题就可以转换成了数字编码的问题——怎样表示这个数字? 有人可能会疑惑,数字用它自己本身表示不就可以了吗?比如U+1F643就用数字0x1F643来表示嘛。 实际上是可以的。但是那些只用ASCII的人不乐意了。因为他们本来7比特也就是一个字节的字符,现在就要用那么多字节来表示。因为我们需要容纳那么多字符的字节长度。 所以UTF-8诞生了。它的作用就是像2的补码来表示负数一样,使用特定的数字N来表示字符对应的数字O,并且节省空间,让那些只用ASCII的人也开心。 UTF-8是变长编码,变长是指,O和N的可以长度不相等。一个字节可以表示的数字,就用一个字节来表示。 比如换行字符\n,对应的数字是0x0A,那么UTF-8的表示0x0A。 对于大于一个字节的数字,UTF-8就使用了一种技巧,使得不同字节长度的数字混合在一起的时候,还能识别两者分别是什么。比如换行和☺混在一起,我们肯定要能区分它们。 UTF-8利用了巧妙的一点:一个字节表示的数字因为只用到了7bit,最高位没用,而且是0。所以只要是最高位是1,那么就可以区别开一个字节长度和多个字节长度的数字了。 多个字节的数字,比如两个字节和三个字节,四个字节的数字怎么区分。UTF-8规定第一个字节的最高位指示这个数字是几个字节。 这个指定也很简单,最高位有多少个1就表示有几个字节。比如两个字节的数字,那么就规定第一个字节的最高位为110。剩余的字节都以10开头。 文字讲解差不多了。让我们看看真正的例子,以字符'中’为例子。 通过查询,我们找到中对应的数字是U+4E2D。(U+可以认为是unicode的前缀,不同的编程语言用不一样的前缀) 那么我们一起来用UTF-8来编码一下/来表示一下。 一个字节肯定表示不下来,两个字节只能表示到2^(5+6)=2048,达不到0x4E2D。所以我们需要三个字节(三个字节可以表示到2^(4+6+6)= 131072)。 下面看看如何用三个字节来表示0x4E2D, 分为三步,如下图, 转成二进制的bits将bits分为三个部分给每个部分添加相应前缀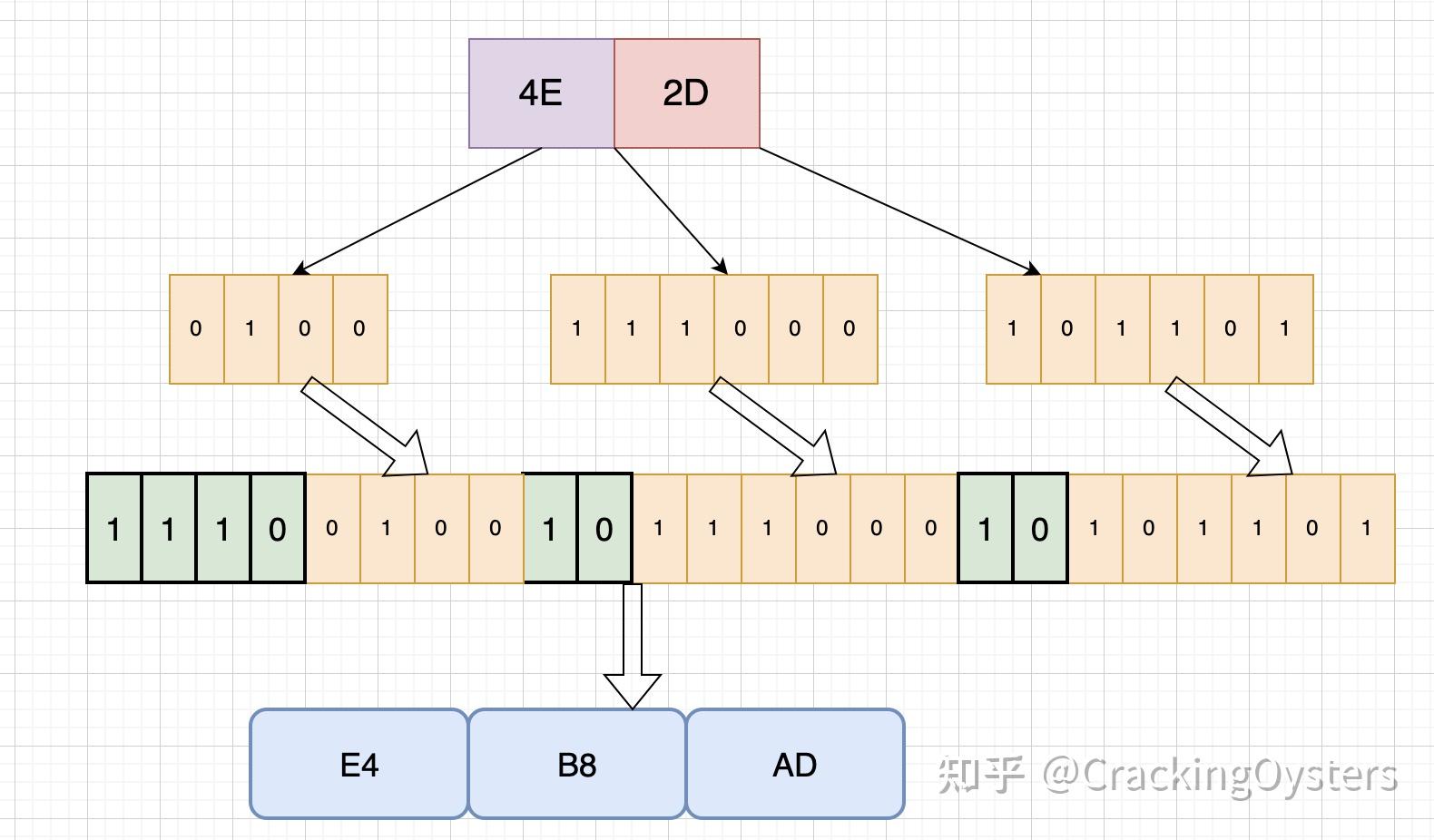 首先将0x4E2D转成二进制也就是0100,1110,0010,1101。 接下来对U+4E2D 来进行拆分,分成三个部分, 这三个部分是4+6+6,所以是0100/1110,00/10,1101 在相应的部分加上对应的前缀,得1110,0100/10,1110,00/10,10,1101。所以对应的编码为0xE4/0xB8/0xAD。 来对对网上搜索得到的结果,看看计算是否正确。  结果正确。我们还可以通过Python来验证一下,  Talk is cheap, show me the code,让我们看看Python 源码的decode是怎么工作的。 static PyObject * unicode_decode_utf8(const char *s, Py_ssize_t size, _Py_error_handler error_handler, const char *errors, Py_ssize_t *consumed) { if (size == 0) { if (consumed) *consumed = 0; _Py_RETURN_UNICODE_EMPTY(); } /* ASCII is equivalent to the first 128 ordinals in Unicode. */ if (size == 1 && (unsigned char)s[0] |
【本文地址】
今日新闻 |
推荐新闻 |