yolov3 |
您所在的位置:网站首页 › yolov3数据标注 › yolov3 |
yolov3
|
项目地址:ultralytics/yolov3 at archive (github.com) 国内镜像:文件 · archive · mirrors / ultralytics / yolov3 · CODE CHINA (csdn.net) 现在最流行的大概是yolov5,速度较高,且精度也不错,但是翻遍了整个yolov5的所有版本,只有最初的版本是支持torch1.5的,但是实验室的机器的两块旧卡算力3.5,所能支持的最高的torch gpu版本也只是1.2,不得已使用yolov3框架来训练,且不能是最新的,这里选用的是yolov3的v6版本
首先应该确保你的机器环境与环境变量都应该完好,python3.6以上,cuda与cudnn 拷贝源码并下载,进入文件夹,执行 1pip3 install -r requirements.txtrequire
yolov3的数据需求的数据标注格式为:
分别为目标类别,归一化之后的目标框中心点x坐标,归一化之后的目标框中心点y坐标,归一化之后的目标框宽度,归一化之后的目标框高度 我们在项目文件夹的data文件夹下面创建如下两个文件夹,JPEGImages文件夹下面存放全部需要训练或者评测的图片,labels文件夹下存放所有的标注文件,对应JPEGImages文件夹下每一个图片对应一个标注文件,后缀为.txt,文件名与JPEGImages文件夹中的文件名对应,如JPEGImages中33.jpg对应labels文件夹中标注文件33.txt
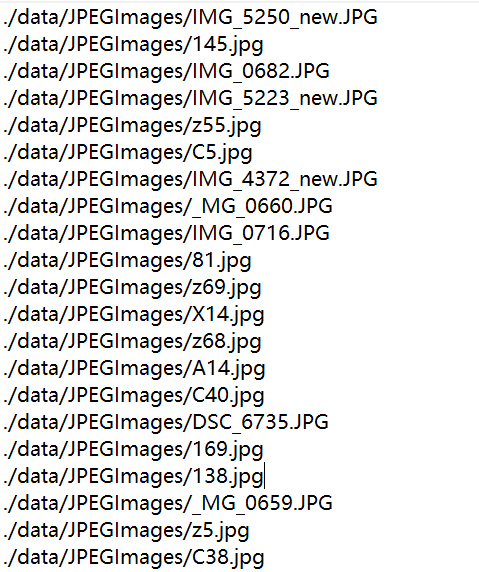
在项目文件夹data目录下存放train.txt与val.txt文件,分别为划分好的训练集与测试集,存放对应的图片路径,如:
到这里整个的数据读取流程已经清楚了,yolov3首先会读取train.txt与val.txt文件,根据其中的图片文件路径读取图片,然后将图片文件的后缀转换为txt之后到labels文件夹中读取对应的标注文件,在utils/datasets.py文件中可以看到:
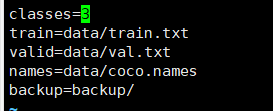
将文件夹目录与后缀名一并替换到对应的标注文件夹与后缀名。 数据划分由于在此次任务中我们我们的标注数据已经是yolo所需要的数据格式,只需要写一个简单的脚本来对标注数据进行划分即可 1234567891011121314151617181920212223242526272829303132333435363738394041424344import pandas as pdimport randomimport osimport shutiltotal_labels = './data/train/labels/'train_txt = './yolo-data/ImageSets/train.txt'trainval_txt = './yolo-data/ImageSets/total.txt'val_txt = './yolo-data/ImageSets/val.txt'img_path = './data/train/images'imgid_mp = {}imgs = os.listdir(img_path)for i in range(len(imgs)): imgid = os.path.splitext(imgs[i])[0] imgid_mp[imgid] = os.path.join('./data/JPEGImages/',imgs[i]) labels = os.listdir(total_labels)val_rate = 0.15random.shuffle(labels)total_num = len(labels)val_num = int(total_num*val_rate)train_num = total_num-val_numftrain_txt = open(train_txt,'a')ftrainval_txt = open(trainval_txt,'a')fval_txt = open(val_txt,'a')for i in range(train_num): imgid = os.path.splitext(labels[i])[0] ftrainval_txt.write(imgid_mp[imgid]+'\n') ftrain_txt.write(imgid_mp[imgid]+'\n') #img_name = img_list[i] #shutil.copy(img_path + img_name, 'trained/' + img_name)for j in range(val_num): imgid = os.path.splitext(labels[j+train_num])[0] ftrainval_txt.write(imgid_mp[imgid]+'\n') fval_txt.write(imgid_mp[imgid]+'\n') #img_name = img_list[j+train_num] #shutil.copy(img_path + img_name, 'val/' + img_name)ftrain_txt.close()ftrainval_txt.close()fval_txt.close() 如果数据格式为xml可以通过下面两个脚本生成合适的标注数据 make_txt.py 将xml格式的图片划分为训练集与测试集,两个文件中存放的都为图片id 12345678910111213141516171819202122232425262728293031323334353637#-*- coding:utf-8 -*import osimport random trainval_percent = 0.1train_percent = 0.9xmlfilepath = 'data/Annotations' txtsavepath = 'data/ImageSets' total_xml = os.listdir(xmlfilepath) num = len(total_xml)list = range(num)tv = int(num * trainval_percent)tr = int(tv * train_percent)trainval = random.sample(list, tv)train = random.sample(trainval, tr) ftrainval = open('data/ImageSets/trainval.txt', 'w') ftest = open('data/ImageSets/test.txt', 'w') ftrain = open('data/ImageSets/train.txt', 'w') fval = open('data/ImageSets/val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftest.write(name) else: fval.write(name) else: ftrain.write(name) ftrainval.close()ftrain.close()fval.close()ftest.close()voc_label.py 此脚本将在data文件夹下生成images和labels两个文件夹用于训练。images文件夹下储存训练图片,labels文件夹下储存相应的标签文件。这里的标签文件全部是由原xml文件转化而来的txt文件,且将坐标位置信息全部归一化处理,代码如下。 需要注意的是,代码中第9行的classes对应的是训练集中的标签,如果你使用本文中的训练集,那就无需改动;如果你使用自己的训练集,这里需要修改成你自己的标签。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657#-*- coding:utf-8 -*import xml.etree.ElementTree as ETimport pickleimport osfrom os import listdir, getcwdfrom os.path import join sets = ['train', 'test','val']classes = ['person','bird','cat','cow','dog','horse','bicycle','boat','bus','car','motorbike','train','bottle','chair','diningtable','pottedplant','sofa','tvmonitor'] def convert(size, box): dw = 1. / size[0] dh = 1. / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def convert_annotation(image_id): in_file = open('data/Annotations/%s.xml' % (image_id)) out_file = open('data/labels/%s.txt' % (image_id), 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd()print(wd)for image_set in sets: if not os.path.exists('data/labels/'): os.makedirs('data/labels/') image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split() list_file = open('data/%s.txt' % (image_set), 'w') for image_id in image_ids: list_file.write('data/images/%s.jpg\n' % (image_id)) convert_annotation(image_id) list_file.close() 训练参数修改训练选用的模型为yolov3-spp模型 data/coco.names 存放数据集标签:
data/coco.data 指明类别数量与训练集测试集文件路径
cfg/yolov3-spp.cfg 如下,在每一个yolo层上面的卷积层filter改为3*(类别数+4+1)。 每一个yolo层的classes改为自己的类别数: (yolov3-spp.cfg文件中应该改三处)
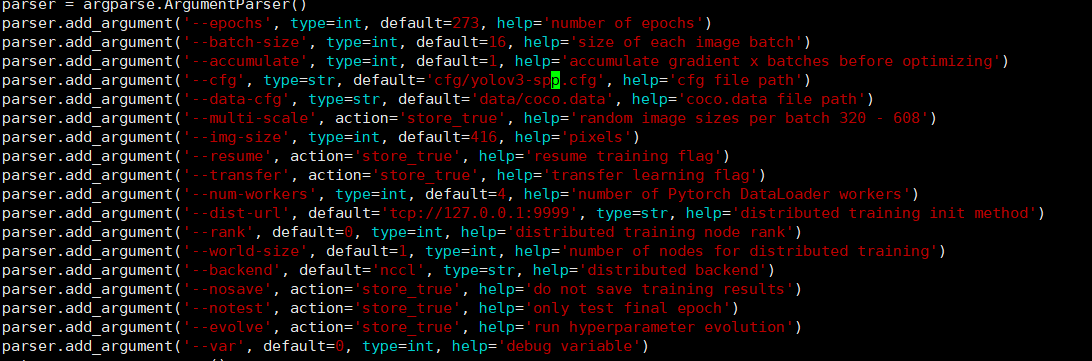
train.py 训练模型脚本,把参数改为自己对应的: 重要的:–batch_size –cfg –data-cfg
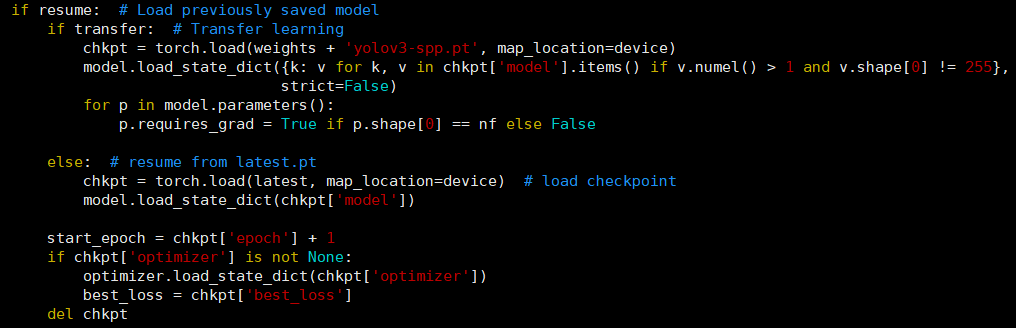
按照一般的教程到这里一般已经开始训练测试了,但是可能是我用的yolov3版本太老没人维护了,训练脚本里使用的模型并不能指定,还需要手动修改: 原:
改之后:
下面这个分支判断原本是使用主干初始化的模型来训练数据,而上面的分支则是迁移学习:
但不知为何,官方给的权重文件为weights,而在迁移学习则为pt,改动的话出现了一些莫名奇妙的错误,姑且就导入初始化主干网络。 开始训练1python3 train.py
训练完成之后将需要检测的图片放入项目文件夹下的data/samples文件夹下,运行detect脚本在项目文件夹生成output 1python3 detect.py cfg文件参数详解以yolov3.cfg文件为例 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102[net] ★ [xxx]开始的行表示网络的一层,其后的内容为该层的参数配置,[net]为特殊的层,配置整个网络# Testing ★ #号开头的行为注释行,在解析cfg的文件时会忽略该行# batch=1# subdivisions=1# Trainingbatch=64 ★ 这儿batch与机器学习中的batch有少许差别,仅表示网络积累多少个样本后进行一次BP subdivisions=16 ★ 这个参数表示将一个batch的图片分sub次完成网络的前向传播 ★★ 敲黑板:在Darknet中,batch和sub是结合使用的,例如这儿的batch=64,sub=16表示训练的过 程中将一次性加载64张图片进内存,然后分16次完成前向传播,意思是每次4张,前向传播的循环过程中 累加loss求平均,待64张图片都完成前向传播后,再一次性后传更新参数 ★★★ 调参经验:sub一般设置16,不能太大或太小,且为8的倍数,其实也没啥硬性规定,看着舒服就好 batch的值可以根据显存占用情况动态调整,一次性加减sub大小即可,通常情况下batch越大越好,还需 注意一点,在测试的时候batch和sub都设置为1,避免发生神秘错误!width=608 ★ 网络输入的宽widthheight=608 ★ 网络输入的高heightchannels=3 ★ 网络输入的通道数channels ★★★ width和height一定要为32的倍数,否则不能加载网络 ★ 提示:width也可以设置为不等于height,通常情况下,width和height的值越大,对于小目标的识别 效果越好,但受到了显存的限制,读者可以自行尝试不同组合 momentum=0.9 ★ 动量 DeepLearning1中最优化方法中的动量参数,这个值影响着梯度下降到最优值得速度decay=0.0005 ★ 权重衰减正则项,防止过拟合angle=0 ★ 数据增强参数,通过旋转角度来生成更多训练样本saturation = 1.5 ★ 数据增强参数,通过调整饱和度来生成更多训练样本exposure = 1.5 ★ 数据增强参数,通过调整曝光量来生成更多训练样本hue=.1 ★ 数据增强参数,通过调整色调来生成更多训练样本learning_rate=0.001 ★ 学习率决定着权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。 如果仅靠人为干预调整参数,需要不断修改学习率。刚开始训练时可以将学习率设置的高一点, 而一定轮数之后,将其减小在训练过程中,一般根据训练轮数设置动态变化的学习率。 刚开始训练时:学习率以 0.01 ~ 0.001 为宜。一定轮数过后:逐渐减缓。 接近训练结束:学习速率的衰减应该在100倍以上。 学习率的调整参考https://blog.csdn.net/qq_33485434/article/details/80452941 ★★★ 学习率调整一定不要太死,实际训练过程中根据loss的变化和其他指标动态调整,手动ctrl+c结 束此次训练后,修改学习率,再加载刚才保存的模型继续训练即可完成手动调参,调整的依据是根据训练 日志来,如果loss波动太大,说明学习率过大,适当减小,变为1/5,1/10均可,如果loss几乎不变, 可能网络已经收敛或者陷入了局部极小,此时可以适当增大学习率,注意每次调整学习率后一定要训练久 一点,充分观察,调参是个细活,慢慢琢磨 ★★ 一点小说明:实际学习率与GPU的个数有关,例如你的学习率设置为0.001,如果你有4块GPU,那 真实学习率为0.001/4burn_in=1000 ★ 在迭代次数小于burn_in时,其学习率的更新有一种方式,大于burn_in时,才采用policy的更新方式max_batches = 500200 ★ 训练次数达到max_batches后停止学习,一次为跑完一个batchpolicy=steps ★ 学习率调整的策略:constant, steps, exp, poly, step, sig, RANDOM,constant等方式 参steps=400000,450000 scales=.1,.1 ★ steps和scale是设置学习率的变化,比如迭代到400000次时,学习率衰减十倍,45000次迭代时,学 习率又会在前一个学习率的基础上衰减十倍[convolutional] ★ 一层卷积层的配置说明batch_normalize=1 ★ 是否进行BN处理,什么是BN此处不赘述,1为是,0为不是 filters=32 ★ 卷积核个数,也是输出通道数size=3 ★ 卷积核尺寸stride=1 ★ 卷积步长pad=1 ★ 卷积时是否进行0 padding,padding的个数与卷积核尺寸有关,为size/2向下取整,如3/2=1activation=leaky ★ 网络层激活函数 ★★ 卷积核尺寸3*3配合padding且步长为1时,不改变feature map的大小 # Downsample[convolutional] ★ 下采样层的配置说明batch_normalize=1filters=64size=3stride=2pad=1activation=leaky ★★ 卷积核尺寸为3*3,配合padding且步长为2时,feature map变为原来的一半大小[shortcut] ★ shotcut层配置说明from=-3 ★ 与前面的多少次进行融合,-3表示前面第三层activation=linear ★ 层次激活函数 ...... ......[convolutional] ★ YOLO层前面一层卷积层配置说明size=1stride=1pad=1filters=255 ★ filters=num(预测框个数)*(classes+5),5的意义是4个坐标加一个置信率,论文中的tx,ty,tw,th, c,classes为类别数,COCO为80,num表示YOLO中每个cell预测的框的个数,YOLOV3中为3 ★★★ 自己使用时,此处的值一定要根据自己的数据集进行更改,例如你识别4个类,则: filters=3*(4+5)=27,三个fileters都需要修改,切记activation=linear[yolo] ★ YOLO层配置说明mask = 0,1,2 ★ 使用anchor的索引,0,1,2表示使用下面定义的anchors中的前三个anchoranchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 ★ 类别数目num=9 ★ 每个grid cell总共预测几个box,和anchors的数量一致。当想要使用更多anchors时需要调大numjitter=.3 ★ 数据增强手段,此处jitter为随机调整宽高比的范围,该参数不好理解,在我的源代码注释中有详细说明ignore_thresh = .7truth_thresh = 1 ★ 参与计算的IOU阈值大小.当预测的检测框与ground true的IOU大于ignore_thresh的时候,参与 loss的计算,否则,检测框的不参与损失计算。 ★ 理解:目的是控制参与loss计算的检测框的规模,当ignore_thresh过于大,接近于1的时候,那么参与 检测框回归loss的个数就会比较少,同时也容易造成过拟合;而如果ignore_thresh设置的过于小,那么 参与计算的会数量规模就会很大。同时也容易在进行检测框回归的时候造成欠拟合。 ★ 参数设置:一般选取0.5-0.7之间的一个值,之前的计算基础都是小尺度(13*13)用的是0.7, (26*26)用的是0.5。这次先将0.5更改为0.7。参考:https://www.e-learn.cn/content/qita/804953random=1 ★ 为1打开随机多尺度训练,为0则关闭 ★★ 提示:当打开随机多尺度训练时,前面设置的网络输入尺寸width和height其实就不起作用了,width 会在320到608之间随机取值,且width=height,没10轮随机改变一次,一般建议可以根据自己需要修改 随机尺度训练的范围,这样可以增大batch,望读者自行尝试!参考: (102条消息) YOLOV3实战4:Darknet中cfg文件说明和理解_phinoo的博客-CSDN博客 (102条消息) 使用YOLOV3训练自己的数据集_FlyDremever-CSDN博客_yolov3训练自己的数据集 |


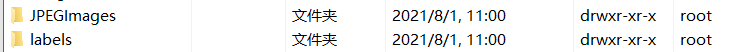




【本文地址】
今日新闻 |
推荐新闻 |