Python批量处理文件的方法总结(包括folder、txt、xml、excel) |
您所在的位置:网站首页 › word文件批量导入同名文件夹里 › Python批量处理文件的方法总结(包括folder、txt、xml、excel) |
Python批量处理文件的方法总结(包括folder、txt、xml、excel)
|
目录
一、使用Python批量创建folder二、使用python批量创建txt三、使用 Python批量修改文件名四、使用Python读取txt中的数据并创建excel五、使用Python批量删除文件的第一行六、使用Python批量修改xml文件的内容七、拆分txt数据:一个txt分组成多个txt(选读Matlab)八、读取.mat文件的数据,批量写入xml文件(选读Matlab)九、使用Python读取某文件夹下所有文件并写入txt中十、使用Python根据已有的txt文件删除某文件夹下的文件十一、根据已有的txt文件提取某文件夹下的文件(选读C++)十二、使用Python调用opencv库裁剪图片
一、使用Python批量创建folder
主要用到的库就是os;代码运行的结果是:在指定文件夹下创建一组文件夹。
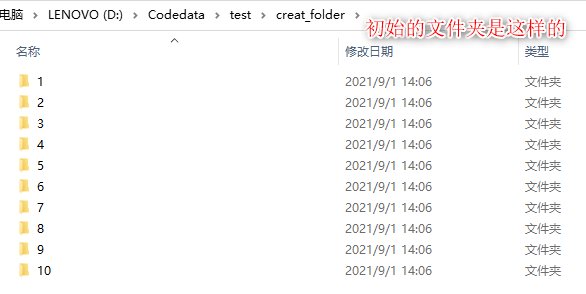
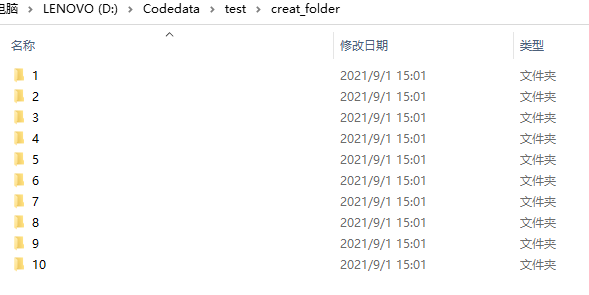
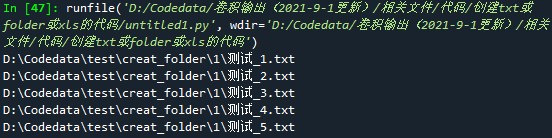
part1:代码: import os #导入os模块 for i in range(1,11): #使用for循环创建从1到x的文件夹,此处是创建10个文件夹,从 1-10 path1 = 'D:/Codedata/test/creat_folder/' #设置创建后文件夹存放的位置,此处是在creat_folder文件夹下创建一组文件夹 path2 = '测试_' + str(i) #此处可以修改/删除:'测试_' path = os.path.join(path1, path2) #路径拼接 isExist = os.path.exists(path) #定义一个变量判断文件是否存在 if not isExist: #如果文件不存在,则创建文件夹,并提示创建成功 os.makedirs(path) print("%s 目录创建成功"%i) else: #如果文件存在,则提示已经存在 print("%s 目录已经存在"%i) continue #继续上述操作,直到循环结束part2:运行结果图:
删掉第5行的 ‘测试_’ 后,path2 = str(i) ,意为只创建纯数字命名的文件夹,运行结果如下:
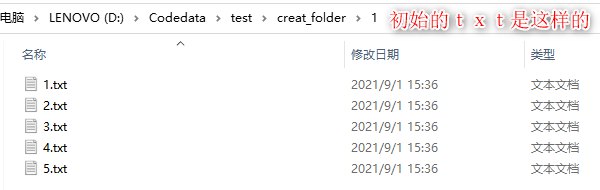
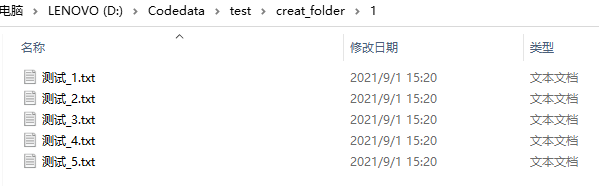
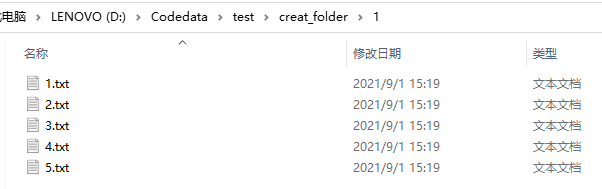
part1:代码: import os #导入os模块 for i in range(1,6): #使用for循环创建5个txt,从1到5 path1 = 'D:/Codedata/test/creat_folder/1/' #设置创建后文件夹存放的位置,此处是在creat_folder文件夹下的1文件夹下创建一组txt path2 = '测试_' + str(i) #此处可以修改/删除:'测试_' path = os.path.join(path1,path2) #路径拼接 f = open( path + '.txt',"a") #a表示没有该文件就新建 f.write("") #写入文件,空 f.close() #执行完结束part2:运行结果图:
删掉第5行的 ‘测试_’ 后,path2 = str(i) ,意为只创建纯数字命名的txt,运行结果如下:
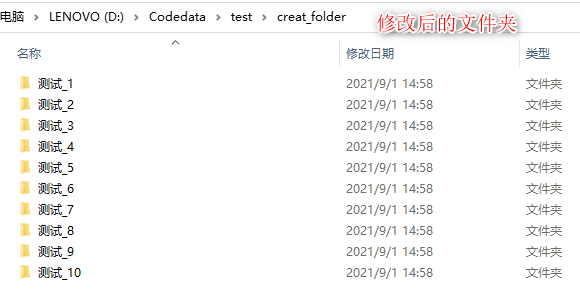
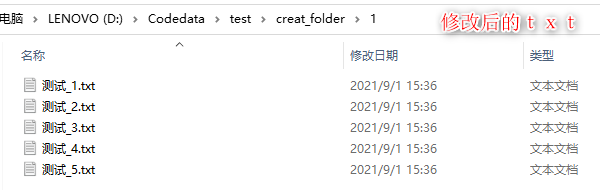
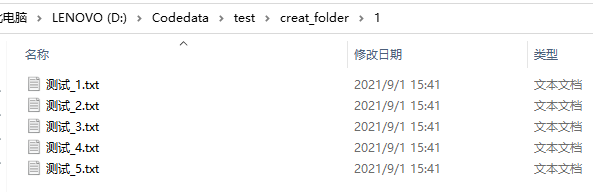
part1:代码: import os #导入os模块 path = 'D:/Codedata/test/creat_folder/' #需要修改的文件所在的路径 #此处是修改在creat_folder文件夹下的一组文件夹的名字 original_name = os.listdir(path) #读取文件初始的名字 print(original_name) for i in original_name: #遍历全部文件 os.rename(os.path.join(path,i),os.path.join(path,'测试_'+i)) #修改文件名part2:运行结果图:
 四、使用Python读取txt中的数据并创建excel
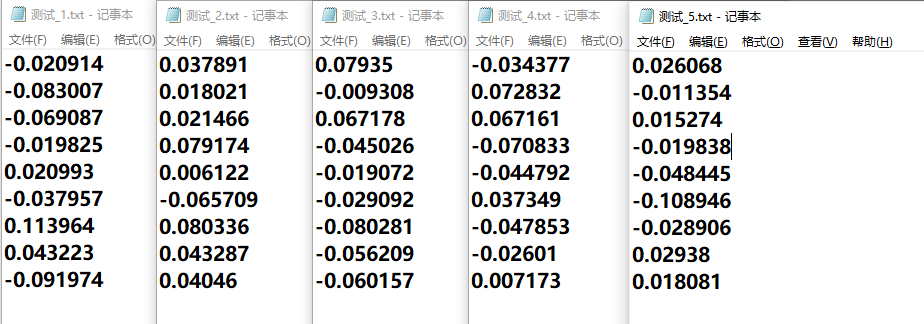
首先,在第二节创建的txt的基础上,给每个txt写入一列9个数据,如下图所示:
四、使用Python读取txt中的数据并创建excel
首先,在第二节创建的txt的基础上,给每个txt写入一列9个数据,如下图所示:
 接下来,先实现用Python读取一个txt的数据,并存入excel中,下面的代码针对“测试_1.txt”。
接下来,先实现用Python读取一个txt的数据,并存入excel中,下面的代码针对“测试_1.txt”。
part1:代码: ## 本例中要读取的txt存放的路径为: D:\Codedata\test\creat_folder\1\ ## 名字为: 测试_x.txt import xlwt #导入excel文件的库 # 打开txt文件并读取数据 with open(r'D:/Codedata/test/creat_folder/1/测试_1.txt','r+') as title: #'r+'表示对文件是进行"读取和写入的模式" layertitle = title.read() layertitle_list= layertitle.split() #读取txt文件内容默认是str类型,此处将其分割成一个个元素形成列表 # 创建excel用于存放数据 workexcel = xlwt.Workbook(encoding='ascii') #创建一个工作表对象 sheet = workexcel.add_sheet('layer1',cell_overwrite_ok=True) #创建表格,添加一个名为layer1的sheet i=0 #行变量,初始值为第一行 j=0 #列变量,初始值为第一列 for data in layertitle_list: #遍历数据,写入excel文件 sheet.write(i,j,data) #i,j控制表格坐标,左顶点为(0,0) i=i+1 #控制j=0不变,i每次+1下移一格,表示将数据写成一列 workexcel.save('测试.xls') #保存文件,这里默认保存到相对路径,即当前工作区的路径part2:运行结果图: 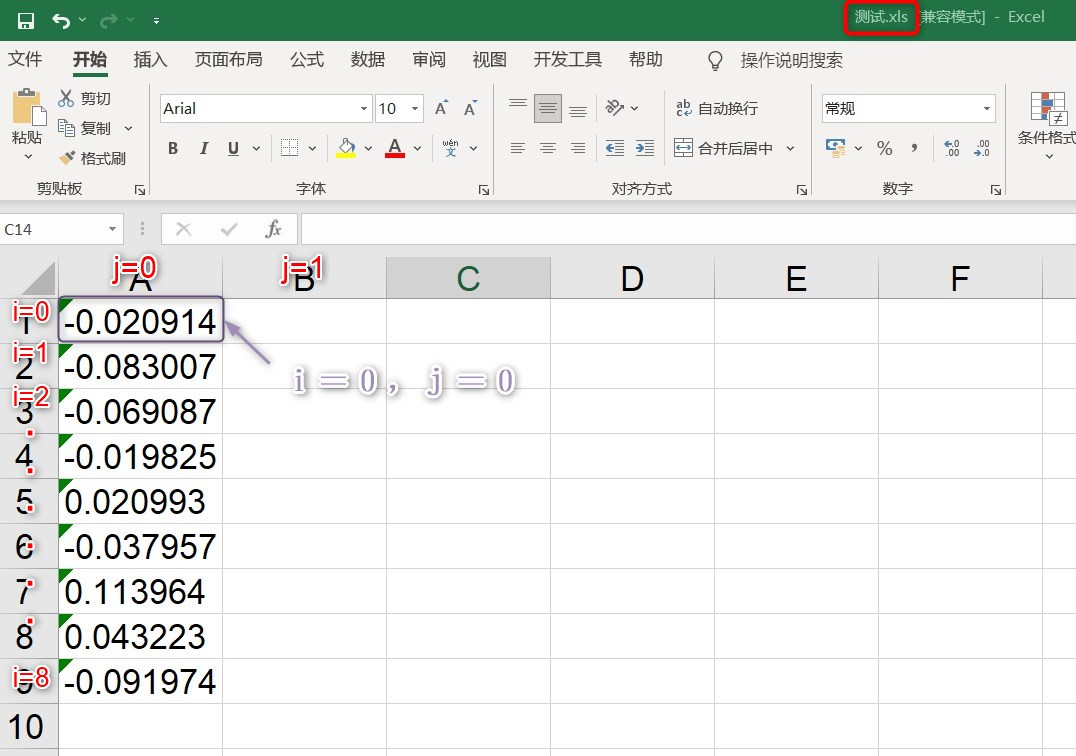 继续实现读取同一文件夹下的多个txt的数据,并存入一个表格的同一个sheet中。 思路:将上一步的代码封装成一个函数,只传入一个 txt_id 用于读取指定的.txt文件。
继续实现读取同一文件夹下的多个txt的数据,并存入一个表格的同一个sheet中。 思路:将上一步的代码封装成一个函数,只传入一个 txt_id 用于读取指定的.txt文件。
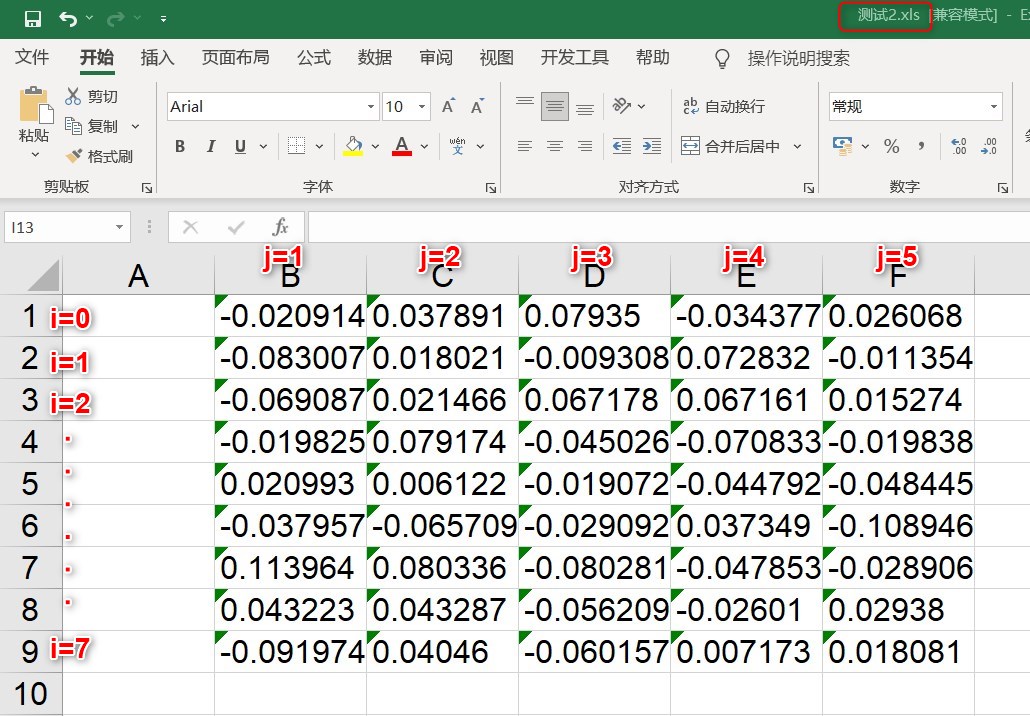
part1:代码: #本例中要读取的txt存放的路径为: D:\Codedata\test\creat_folder\1\ 名字为: 测试_x.txt import xlwt import os def read_txt(txt_id): path1 = 'D:' path2 = '\\Codedata' path3 = 'test' path4 = 'creat_folder' path5 = '1' txt_id = '测试_' + str(txt_id) + '.txt' path6 = txt_id position = os.path.join(path1,path2,path3,path4,path5,path6) print(position) with open(position,'r+') as title: # 打开txt文件并读取数据 layertitle = title.read() layertitle_list = layertitle.split() return layertitle_list if __name__ == '__main__': workexcel = xlwt.Workbook(encoding='ascii') #创建一个工作表对象 sheet = workexcel.add_sheet('layer1',cell_overwrite_ok=True) #创建表格,添加一个名为layer1的sheet for num in range(1,6): #利用for循环遍历txt文件 i=0 ##行变量,初始值为第一行 data = read_txt(num) #print(data) for d in data: sheet.write(i,num,d) #i,j控制表格坐标,左定格为(0,1)下一次(0,2)以此类推 i=i+1 #按列写入数据 workexcel.save('测试2.xls') #保存文件,这里默认保存到相对路径part2:运行结果图:
 如果想实现读取不同文件夹下的txt数据,并存入同一表格的不同sheet怎么办? 思路:在上一步的read_txt函数中再引入一个folder_id,作为每个sheet的名字同时又能用于for循环中遍历所有文件夹。
如果想实现读取不同文件夹下的txt数据,并存入同一表格的不同sheet怎么办? 思路:在上一步的read_txt函数中再引入一个folder_id,作为每个sheet的名字同时又能用于for循环中遍历所有文件夹。
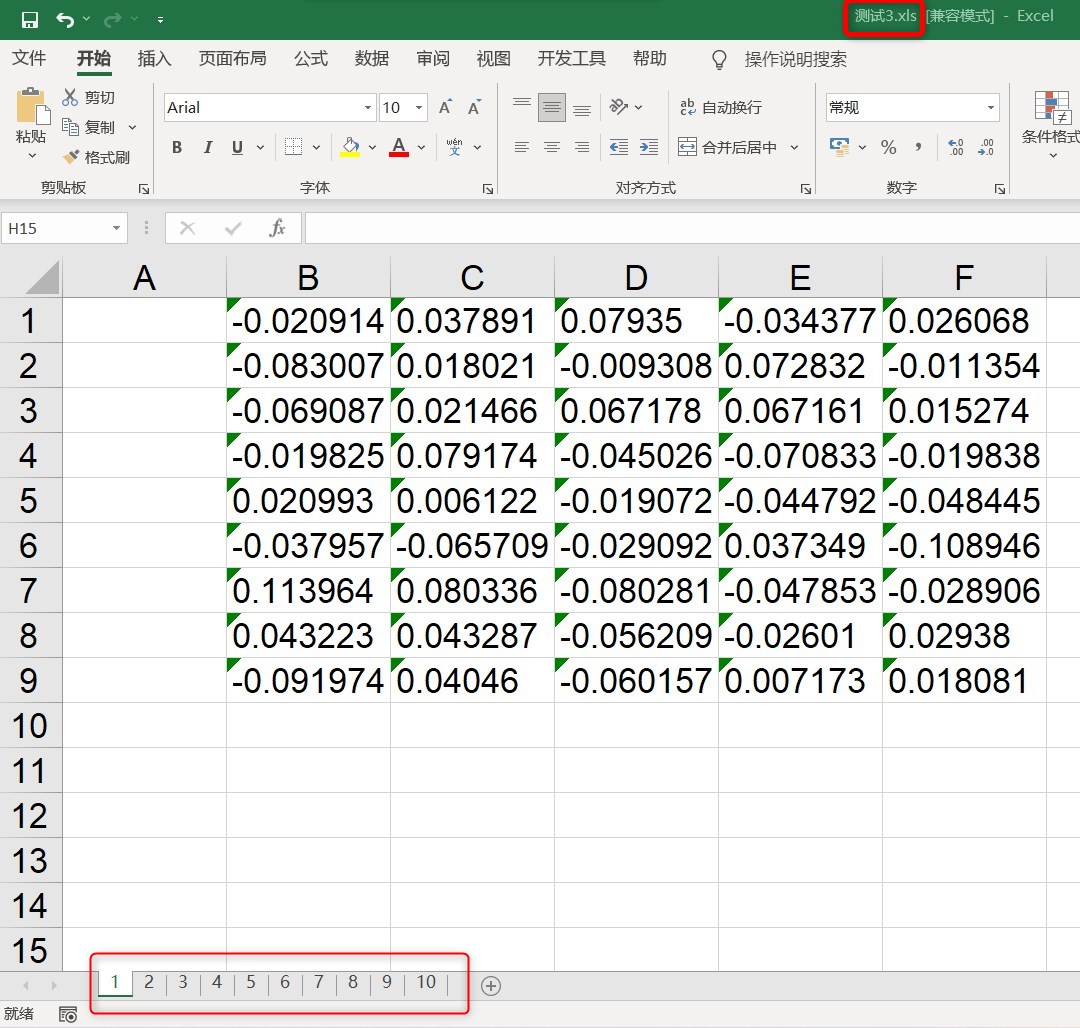
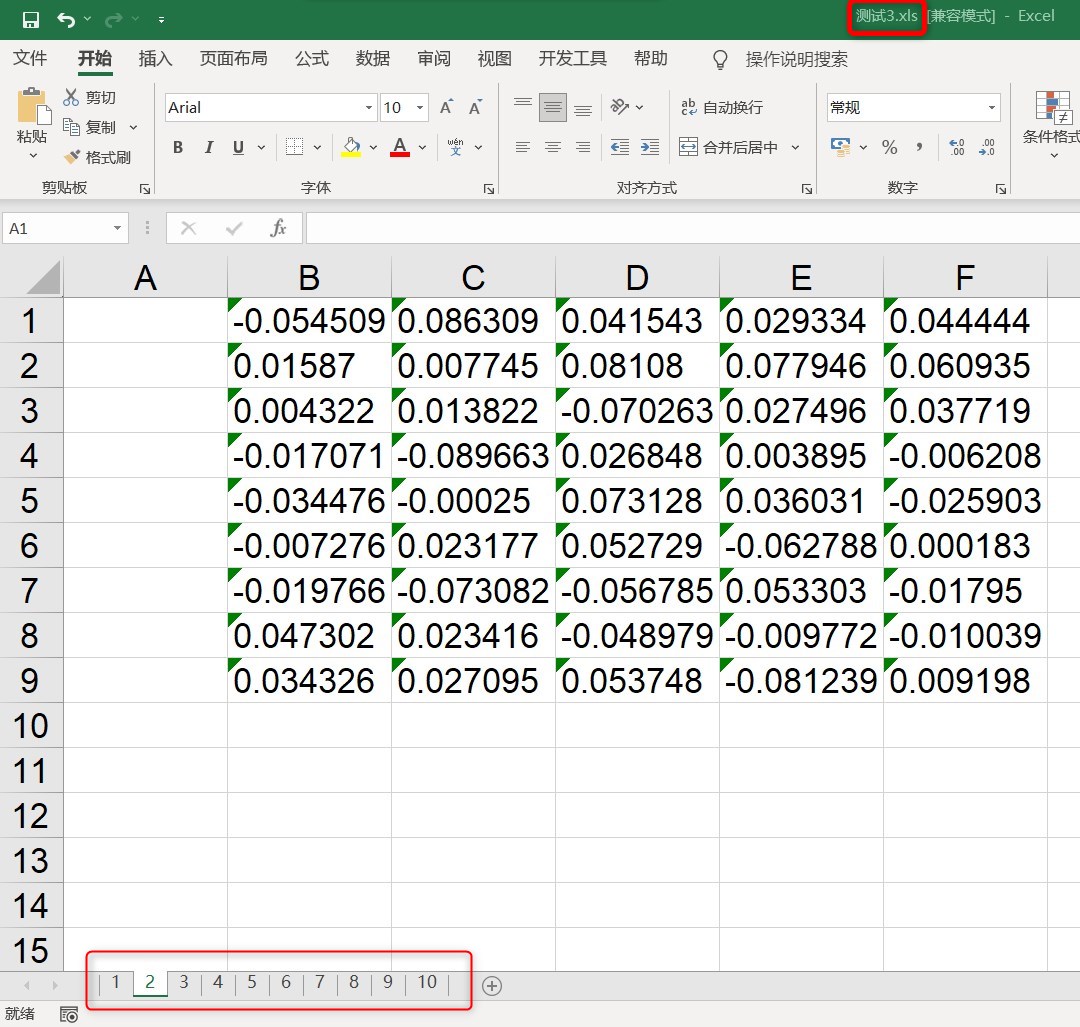
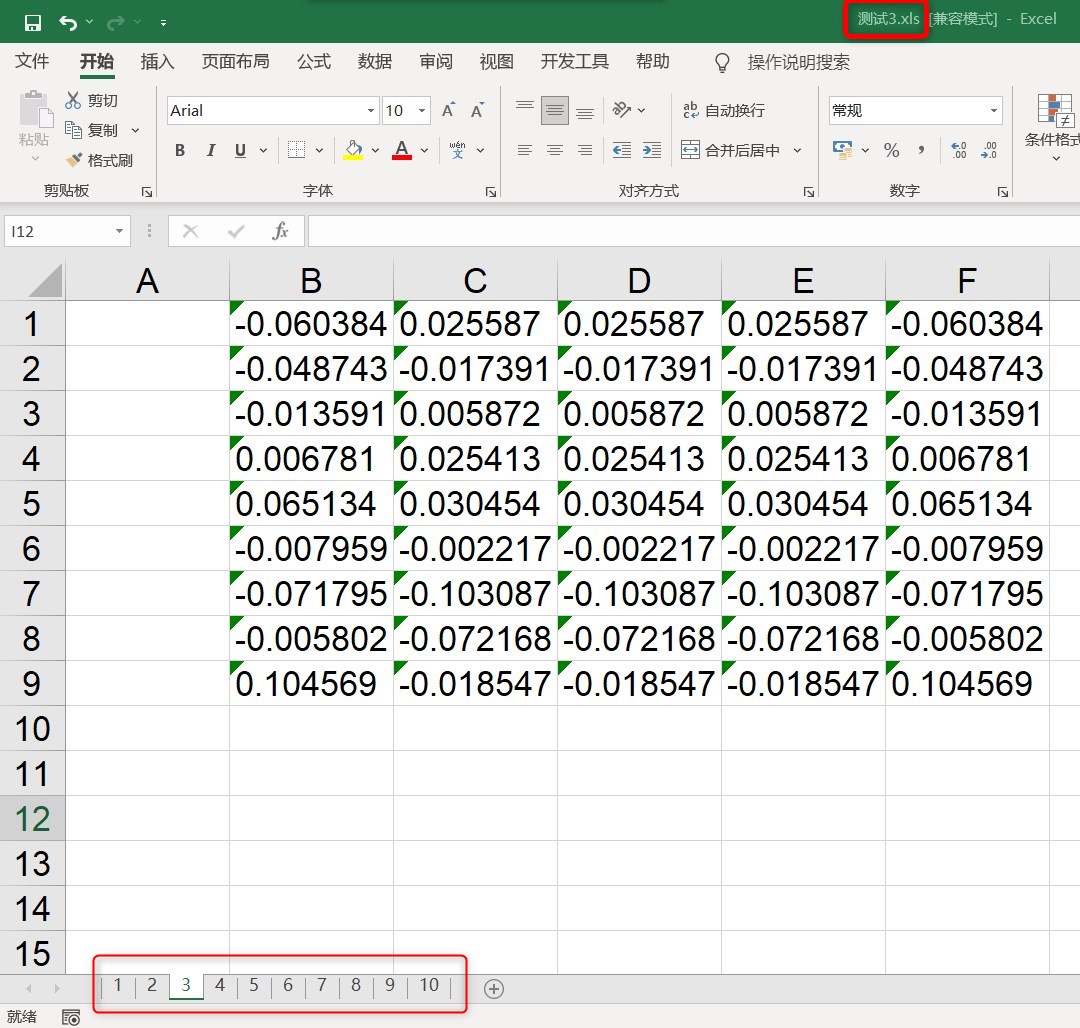
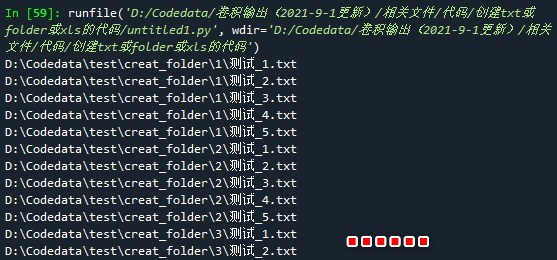
part1:代码: #本例中要读取的txt存放的路径为: D:\Codedata\test\creat_folder\x\ 名字为: 测试_x.txt import xlwt import os def read_txt(txt_id,folder_id): path1 = 'D:' path2 = '\\Codedata' path3 = 'test' path4 = 'creat_folder' path5 = str(folder_id) txt_id = '测试_' + str(txt_id) + '.txt' path6 = txt_id position = os.path.join(path1,path2,path3,path4,path5,path6) print(position) with open(position,'r+') as title: # 打开txt文件并读取数据 layertitle = title.read() layertitle_list = layertitle.split() return layertitle_list if __name__ == '__main__': workexcel = xlwt.Workbook(encoding='ascii') #创建一个工作表对象 for num1 in range(1,11): #利用for循环遍历文件夹 sheet = workexcel.add_sheet(str(num1),cell_overwrite_ok=True) #创建10个sheet for num2 in range(1,6): #利用for循环遍历txt文件 i=0 ##行变量,初始值为第一行 data = read_txt(num2,num1) #print(data) for d in data: sheet.write(i,num2,d) #i,j控制表格坐标,左定格为(0,1)下一次(0,2)以此类推 i=i+1 #按列写入数据 workexcel.save('测试3.xls') #保存文件,这里默认保存到相对路径part2:运行结果图:
 ......
五、使用Python批量删除文件的第一行
面临的问题:自己创建的标签文件,打开之后发现第一行有version的信息,所以想把所有的标签的第一行都删掉~
主要用到的库就是os;代码运行的结果是:对指定文件夹下的所有文件的第一行都进行删除的操作。 ......
五、使用Python批量删除文件的第一行
面临的问题:自己创建的标签文件,打开之后发现第一行有version的信息,所以想把所有的标签的第一行都删掉~
主要用到的库就是os;代码运行的结果是:对指定文件夹下的所有文件的第一行都进行删除的操作。
part1:代码: import os for f in os.listdir('.'): if '.xml' in f: #此处的.xml可以修改为.txt等文件格式 lines = open(f,encoding='utf-8').readlines() open(f, 'w',encoding='utf-8').writelines(lines[1:])part2:运行结果图:  六、使用Python批量修改xml文件的内容
面临问题:在处理一个数据集的标签时,我发现读取的分类标签name是同时含有大小写的,所以想把所有的分类都替换为小写的~运行下面的代码时,需要注意的是区分:当前工作路径 和 xml文件存储的路径
六、使用Python批量修改xml文件的内容
面临问题:在处理一个数据集的标签时,我发现读取的分类标签name是同时含有大小写的,所以想把所有的分类都替换为小写的~运行下面的代码时,需要注意的是区分:当前工作路径 和 xml文件存储的路径
part1:代码: #第一步:导入库 import os import os.path from xml.etree.ElementTree import parse, Element #第二步:定义一个函数,功能:批量修改xml中内容 def test(): path = "E:\\annotation" #xml文件所在的目录,举例 E:\annotation files = os.listdir(path) # 获得文件夹下所有文件名 s = [] for xmlFile in files: # 遍历文件夹 if not os.path.isdir(xmlFile): # 判断是否是文件夹,不是文件夹才打开 print xmlFile pass path = "E:\\annotation" print(xmlFile) #输出文件名,方便知道在处理哪个xml文件 path1 = xmlFile #定位当前处理的文件的工作路径 newStr = os.path.join(path, xmlFile) class1 = "bus" #这是你想最终显示的内容 class2 = "truck" #此处我想换成把原来的全部换成小写 class3 = "suv" #这里举了3个例子 dom = parse(newStr) #路径拼接,输入的是具体路径 root = dom.getroot() #print(root) for obj in root.iter('object'): #获取object节点中的name子节点 if obj.find('name').text == 'Bus': #判断获取的name节点下的内容是否为Bus print('1') # 输出1 obj.find('name').text=class1 name1 = obj.find('name').text #修改 print(name1) elif obj.find('name').text == 'Truck': print('2') obj.find('name').text=class2 name2 = obj.find('name').text #修改 print(name2) elif obj.find('name').text == 'SUV': print('3') obj.find('name').text=class3 name3 = obj.find('name').text #修改 print(name3) dom.write(path1, xml_declaration=True) #将修改后的xml保存到当前工作的路径下 pass if __name__ == '__main__': test()part2:运行结果图: 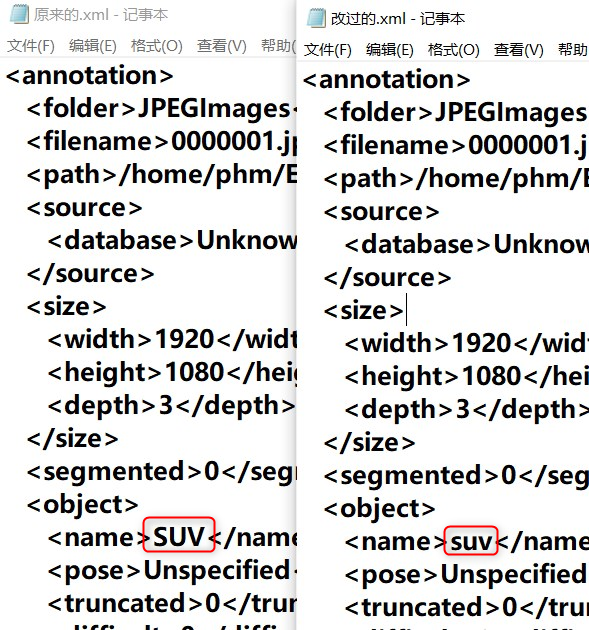 七、拆分txt数据:一个txt分组成多个txt(选读Matlab)
七、拆分txt数据:一个txt分组成多个txt(选读Matlab)
【注】拆分一个包含很多数据的txt文件,使用的工具是matlab。 基础版:将一个包含73728(576*128)个数据的按列存放的txt文件,拆分成128组,每组的576个数据存于一个txt中。也就是说,代码运行之后,在指定文件夹下应该有128个txt,每个txt中有576个数据是按列存放的。
part1:代码: A =importdata('D:\Codedata\test\newspace\forexcel\weights_32.txt'); %导入包含带分组数据的txt文件 B=reshape(A,576,128); %将数据分成128组,每组576个 mkdir('D:\Codedata\test\newspace\forexcel\','分组1'); %创建一个名为‘分组1’的文件夹 for j=1:128 %生成128个txt,每个txt中包含576个数据 n = strcat('D:\Codedata\test\newspace\forexcel\','分组1','\',num2str(j),'.txt'); fid=fopen(n,'w'); fprintf(fid,'%g\n',B(:,j)); fclose(fid); endpart2:运行结果图: 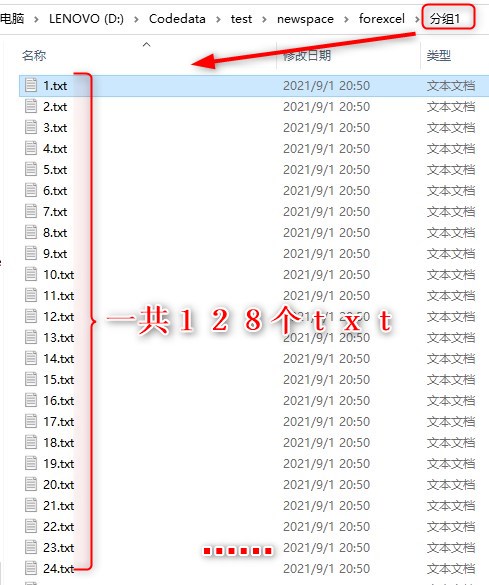 打开1.txt 的结果--> 打开1.txt 的结果-->
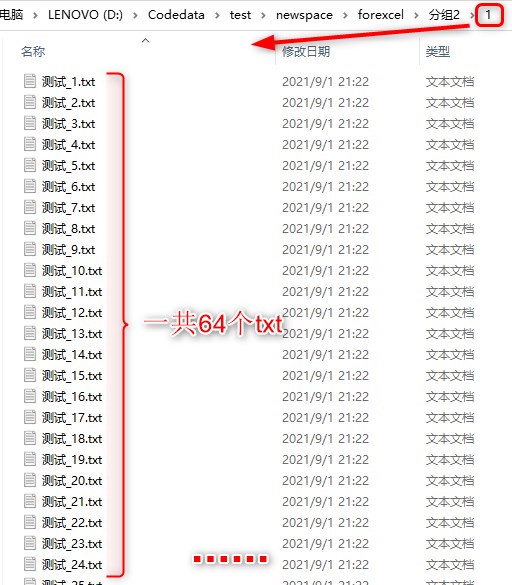
 升级版:将上一步的128个txt进行拆分,每个txt对应一个文件夹,每一个文件夹下将576(9*64)个数据拆分成64组,每组的9个数据存于一个txt中。
升级版:将上一步的128个txt进行拆分,每个txt对应一个文件夹,每一个文件夹下将576(9*64)个数据拆分成64组,每组的9个数据存于一个txt中。
part1:代码: for i=1:128 mkdir('D:\Codedata\test\newspace\forexcel\分组2\',int2str(i)); %创建128个文件夹,同时将matlab的当前工作路径设置为此 filename = ['D:\Codedata\test\newspace\forexcel\分组1\',int2str(i),'.txt']; A = load(filename); %使用load()函数读取128个txt文件的数据 B=reshape(A,9,64); %将数据分成64组,每组9个数据 for j=1:64 %生成64个txt,每个txt中包含9个数据 n = strcat('D:\Codedata\test\newspace\forexcel\分组2\',int2str(i),'\','测试_',num2str(j),'.txt'); fid=fopen(n,'w'); fprintf(fid,'%g\n',B(:,j)); fclose(fid); end endpart2:运行结果图: 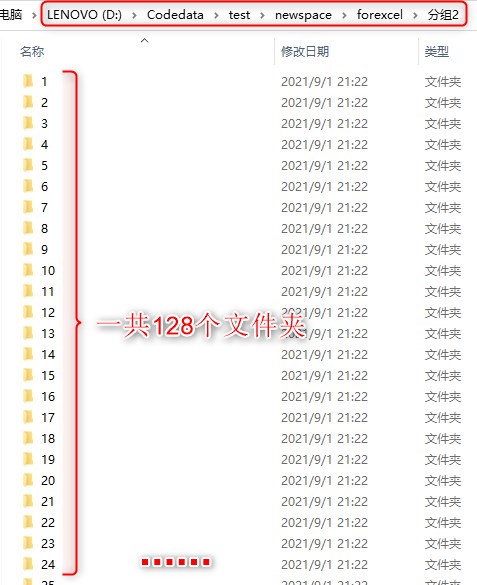 打开1文件夹 -> 打开1文件夹 ->
 打开测试1.txt -> 打开测试1.txt ->
 八、读取.mat文件的数据,批量写入xml文件(选读Matlab)
面临问题:下载了一个网上的数据集,没有提供直接的标签,只给了一个.mat格式的文件,用Matlab读取,批量转换为符合VOC数据集格式的标签文件。
八、读取.mat文件的数据,批量写入xml文件(选读Matlab)
面临问题:下载了一个网上的数据集,没有提供直接的标签,只给了一个.mat格式的文件,用Matlab读取,批量转换为符合VOC数据集格式的标签文件。
part1:代码: data=load('D:/Program Files/MATLAB2019b/MYcode/VehicleInfo.mat') %.mat文件存储的路径 cars=data.VehicleInfo; for n=1:length(cars) n; car=cars(n); %% %每一辆车新建一个xml文件存储车的信息 carName=car.name; %图片的高度 carHeight=car.height; %图片的宽度 carWidth=car.width; %新建xml文件 annotation = com.mathworks.xml.XMLUtils.createDocument('annotation'); annotationRoot = annotation.getDocumentElement; %定义子节点.xml的存储路径 folder=annotation.createElement('folder'); folder.appendChild(annotation.createTextNode(sprintf('%s','JPEGImages')));%这里为xml存放的目录 annotationRoot.appendChild(folder); %图片的名称 jpgName=annotation.createElement('filename'); jpgName.appendChild(annotation.createTextNode(sprintf('%s',carName(end-10:end-4),'.jpg'))); %获取倒数第11-倒数第5的字符 annotationRoot.appendChild(jpgName); %路径 jpgPath=annotation.createElement('path'); jpgPath.appendChild(annotation.createTextNode(sprintf('%s','/home/phm/E/YOLOX/YOLOX-main/datasets/JPEGImages/',carName(end-10:end-4),'.jpg'))); annotationRoot.appendChild(jpgPath); %source jpgSource=annotation.createElement('source'); annotationRoot.appendChild(jpgSource); database=annotation.createElement('database'); database.appendChild(annotation.createTextNode(sprintf('%s','Unknown'))); jpgSource.appendChild(database); %添加图片的size jpgSize=annotation.createElement('size'); annotationRoot.appendChild(jpgSize); %定义size的子节点 %图片宽度 width=annotation.createElement('width'); width.appendChild(annotation.createTextNode(sprintf('%i',carWidth))); jpgSize.appendChild(width); %图片高度 height=annotation.createElement('height'); height.appendChild(annotation.createTextNode(sprintf('%i',carHeight))); jpgSize.appendChild(height); %图片深度,彩色图片3 depth=annotation.createElement('depth'); depth.appendChild(annotation.createTextNode(sprintf('%i',3))); jpgSize.appendChild(depth); segmented=annotation.createElement('segmented'); segmented.appendChild(annotation.createTextNode(sprintf('%i',0)));%表示已经标注过了 annotationRoot.appendChild(segmented); %接下来是每一辆车的标注信息 %% carVehicles=car.vehicles; L=length(carVehicles); if L>1 carName L end for nn=1:length(carVehicles) vehicle=carVehicles(nn); %标注框的最左侧坐标 vLeft=vehicle.left; %标注框的最上边坐标 vTop=vehicle.top; %标注框的最右侧坐标 vRight=vehicle.right; %标注框最下面坐标 vBottom=vehicle.bottom; %车的类别 vCategory=vehicle.category; %图片中有多少个标注对象 carNvehicles=car.nVehicles; %在这里生成每一符图片的txt文件,用于 %%注意一张图片中可能会有多个对象 %%matlab直接生成xml对象??? %将这一辆车的信息注入xml中 object=annotation.createElement('object'); annotationRoot.appendChild(object); %标注框类别名称 categoryName=annotation.createElement('name'); categoryName.appendChild(annotation.createTextNode(sprintf('%s',vCategory))); object.appendChild(categoryName); pose=annotation.createElement('pose'); pose.appendChild(annotation.createTextNode(sprintf('%s','Unspecified'))); object.appendChild(pose); truncated=annotation.createElement('truncated'); truncated.appendChild(annotation.createTextNode(sprintf('%i',0))); object.appendChild(truncated); difficult=annotation.createElement('difficult'); Difficult.appendChild(annotation.createTextNode(sprintf('%i',0))); object.appendChild(Difficult); bndbox=annotation.createElement('bndbox'); object.appendChild(bndbox); xmin=annotation.createElement('xmin'); xmin.appendChild(annotation.createTextNode(sprintf('%i',vLeft))); bndbox.appendChild(xmin); ymin=annotation.createElement('ymin'); ymin.appendChild(annotation.createTextNode(sprintf('%i',vTop))); bndbox.appendChild(ymin); xmax=annotation.createElement('xmax'); xmax.appendChild(annotation.createTextNode(sprintf('%i',vRight))); bndbox.appendChild(xmax); ymax=annotation.createElement('ymax'); ymax.appendChild(annotation.createTextNode(sprintf('%i',vBottom))); bndbox.appendChild(ymax); end %存储xml savePath=['D:\BITVehicle_xml\',carName(1:end-3),'xml']; %指定文件夹用于存放生成的xml文件 xmlwrite(savePath,annotation); end2022/4/26补充: 九、使用Python读取某文件夹下所有文件并写入txt中 面临问题:在准备好数据集后,都是通过读取.txt的内容实现对图片的调用训练的,因此需要将一个包含图片的文件夹中的全部.jpg名字读成一个txt。举例:以下文件夹是存放图片的文件夹,我想将它包含的10张图片读成一个.txt,详见如下两图介绍。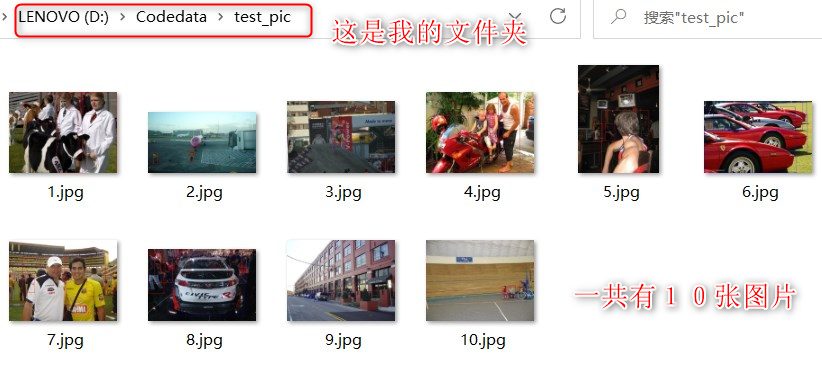
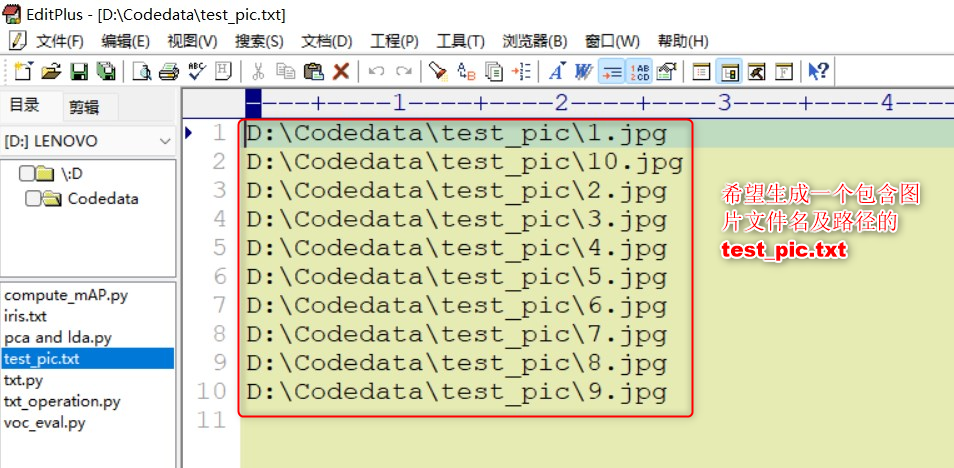
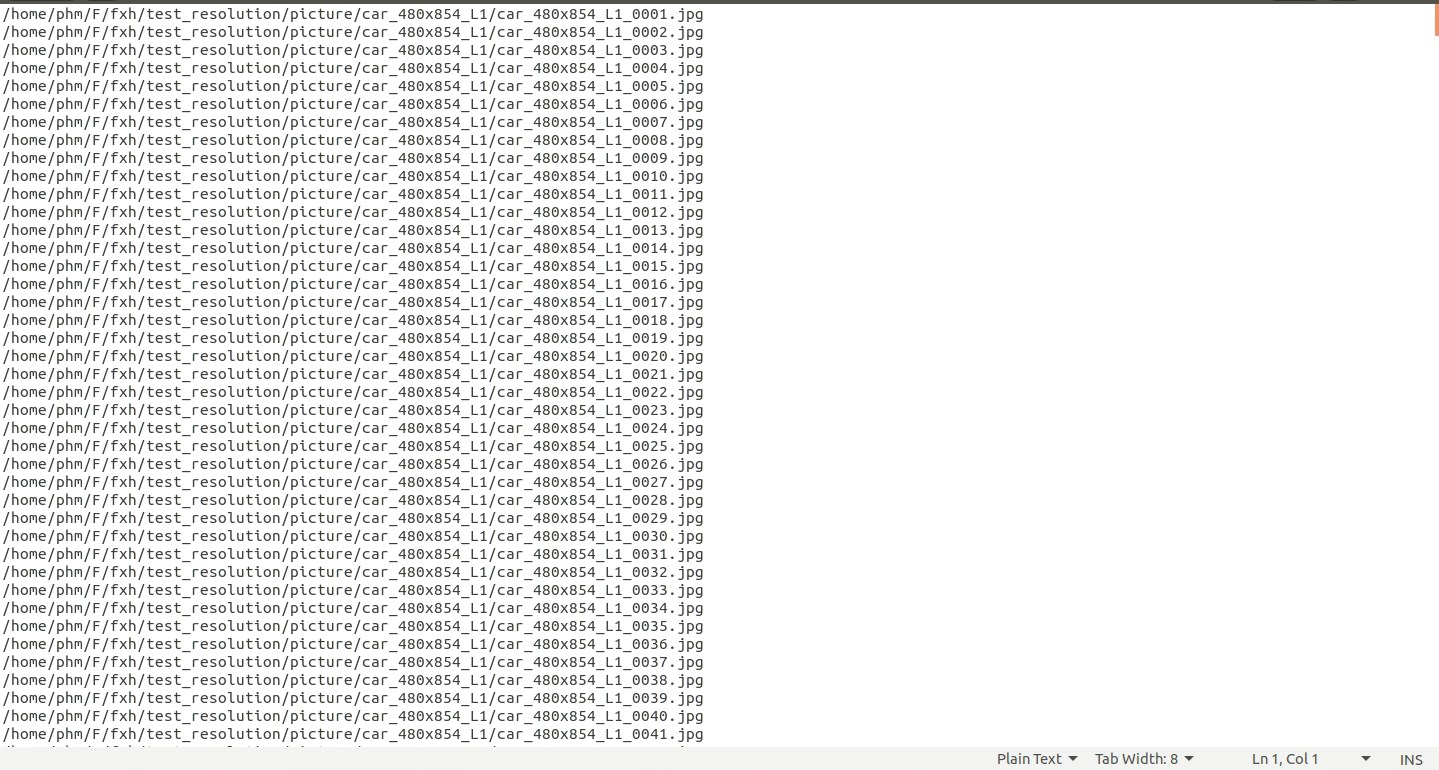
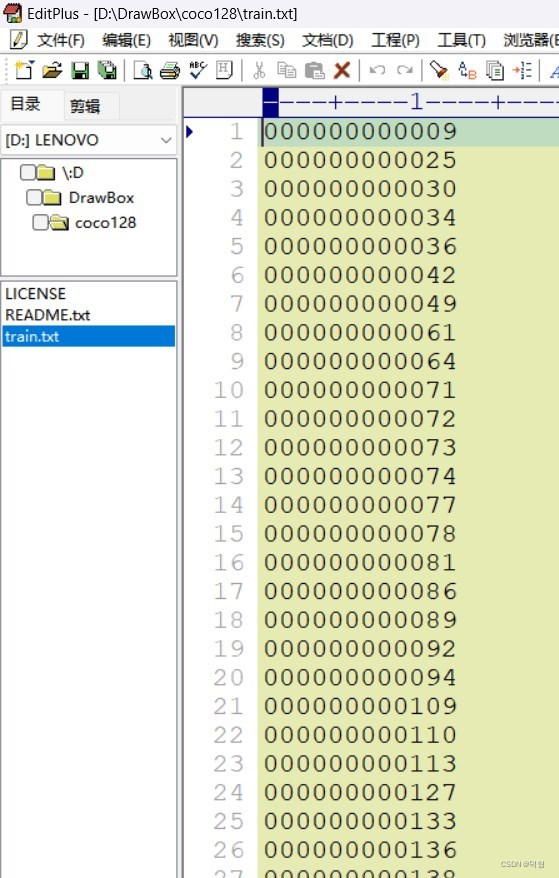
way1:生成的txt中只有图片名的代码: 需要先创建一个.txt用于存放信息,因为代码中没有创建的过程注意修改自己的路径,一共有两处 #导入需要的库 import sys import os import random #导入随机函数 #存放原始图片地址 data_base_dir = r"D:\Codedata\test_pic" #建立列表,用于保存图片信息 file_list = [] #读取图片文件,并将图片名写到txt文件中 write_file_name = 'D:/Codedata/test_pic.txt' write_file = open(write_file_name, "w") #以只写方式打开write_file_name文件 for file in os.listdir(data_base_dir): #file为current_dir当前目录下图片名 if file.endswith(".jpg"): #如果file以jpg结尾 write_name = file #图片路径 + 图片名 + 标签 file_list.append(write_name) #将write_name添加到file_list列表最后 sorted(file_list) #将列表中所有元素随机排列 number_of_lines = len(file_list) #列表中元素个数 #将图片信息写入txt文件中,逐行写入 for current_line in range(number_of_lines): write_file.write(file_list[current_line] + '\n') #关闭文件 write_file.close()way2:生成的txt包含图片路径及图片名的代码: 需要先创建一个.txt用于存放信息,因为代码中没有创建的过程注意修改自己的路径,一共有三处 #导入需要的库 import sys import os import random #导入随机函数 #存放原始图片地址 data_base_dir = r"D:\Codedata\test_pic" #建立列表,用于保存图片信息 file_list = [] #读取图片文件,并将图片地址、图片名写到txt文件中 write_file_name = 'D:/Codedata/test_pic.txt' #以只写方式打开write_file_name文件 write_file = open(write_file_name, "w") for file in os.listdir(data_base_dir): #file为current_dir当前目录下图片名 if file.endswith(".jpg"): #如果file以jpg结尾 write_name = file #图片路径 + 图片名 + 标签 file_list.append(write_name) #将write_name添加到file_list列表最后 sorted(file_list) #将列表中所有元素随机排列 number_of_lines = len(file_list) #列表中元素个数 #将图片信息写入txt文件中,逐行写入 for current_line in range(number_of_lines): write_file.write('D:\\Codedata\\test_pic\\' + file_list[current_line] +'\n') #关闭文件 write_file.close()way3:如果是linux系统,在终端输入一条指令就可以生成txt,包含图片路径及图片名: 在想要生成txt的路径下打开终端,输入: ls -R 包含图片的路径/* >xxx.txt例如:我的包含图片的路径是/home/phm/F/fxh/test_resolution/picture/car_480x854_L1 我想在这个路径下生成一个input.txt,所以在此路径下打开终端,输入: ls -R /home/phm/F/fxh/test_resolution/picture/car_480x854_L1/* > test.txt 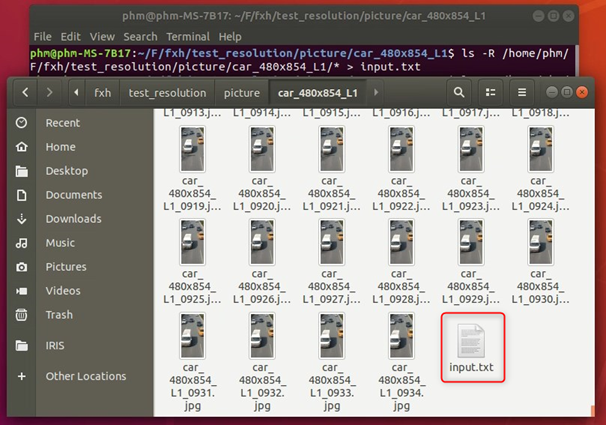 生成的input.txt的内容如下:【注意:此方法仅适用于图片数量较少的情况】
生成的input.txt的内容如下:【注意:此方法仅适用于图片数量较少的情况】
 十、使用Python根据已有的txt文件删除某文件夹下的文件
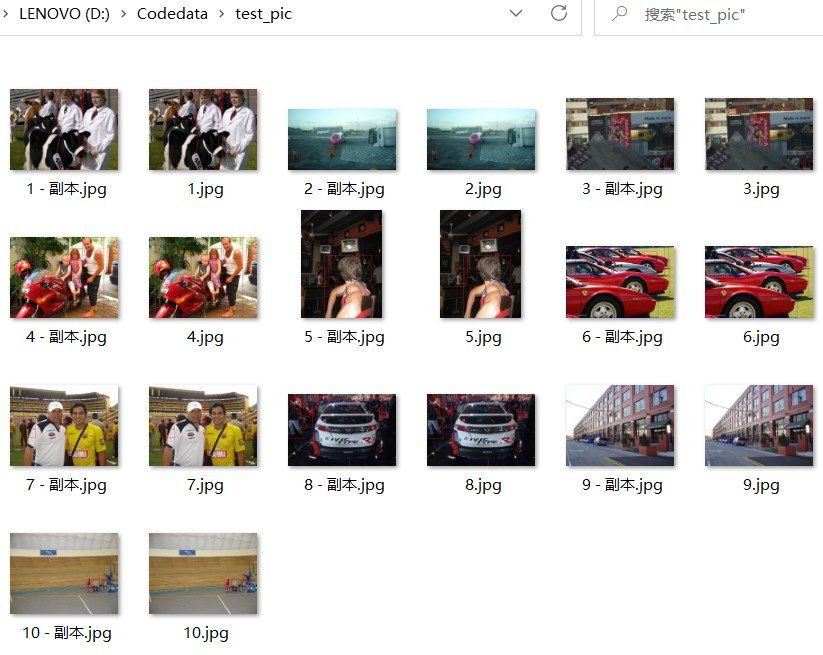
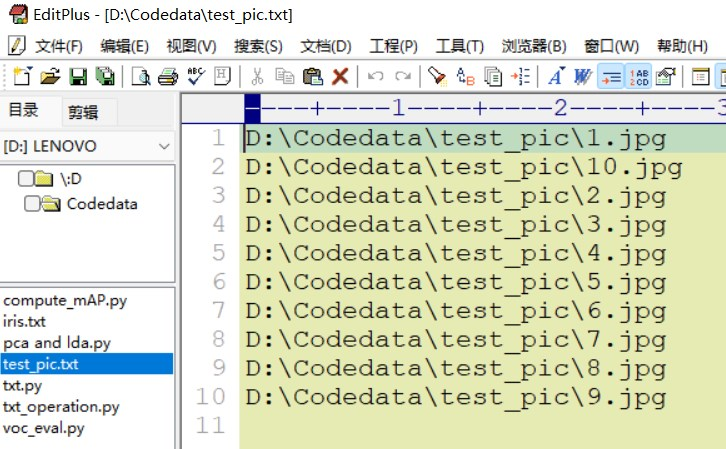
在上一节的基础上,我们已经获得了包含图片路径及图片名的.txt文件,现在想利用这个txt删除指定文件夹下的图片文件先展示已经具备的文件环境:
test_pic的文件夹中有需要删掉的图片,也有需要保留的图片可以通过test_pic.txt中包含的图片路径对此文件夹进行操作假设想删除1-10.jpg,保留1-10-副本.jpg
十、使用Python根据已有的txt文件删除某文件夹下的文件
在上一节的基础上,我们已经获得了包含图片路径及图片名的.txt文件,现在想利用这个txt删除指定文件夹下的图片文件先展示已经具备的文件环境:
test_pic的文件夹中有需要删掉的图片,也有需要保留的图片可以通过test_pic.txt中包含的图片路径对此文件夹进行操作假设想删除1-10.jpg,保留1-10-副本.jpg
part1:代码: #导入库 import os #把txt读成列表data input_file = r'D:/Codedata/test_pic.txt' ##需要删除的文件名组成的txt文件 with open(input_file, 'r') as f: data = f.read().splitlines() #读取待删除的文件夹下的全部文件,读成列表filelist rootdir=r'D:\Codedata\test_pic' filelist=os.listdir(rootdir) #删除操作 for file in data: if '.jpg' in file: del_file = file #使用txt中的路径 os.remove(del_file)#删除文件 print("已经删除:",del_file)part2:运行结果图: 
如果.txt是只包含图片名,而没有路径的,则需要在上述代码中做一处修改 第16行的del_file = file修改为: del_file = rootdir + '\\' + file #当代码和要删除的文件不在同一个文件夹时,必须使用绝对路径 十一、根据已有的txt文件提取某文件夹下的文件(选读C++) 利用第九节的读取文件名生成txt的代码,拿到某文件夹下所有文件的文件名,不包含后缀,如下图所示:
 不同于第十节的删除,本节使用C++实现以下功能:按照txt中的文件名,在一个更大的文件夹中提取出txt中包含的文件,并创建新的文件夹存放。可以按以下简单图示理解:
不同于第十节的删除,本节使用C++实现以下功能:按照txt中的文件名,在一个更大的文件夹中提取出txt中包含的文件,并创建新的文件夹存放。可以按以下简单图示理解:

part1:代码: /********************************************************************* 程序名: readtxt_extractfile.cpp 日期: 2023-04-15 10:16 说明: 使用此代码前,需要创建保存提取出来的文件的文件夹 *********************************************************************/ #include #include #include #include using namespace std; int main() { string s1, s2, s3; cout |




【本文地址】
今日新闻 |
推荐新闻 |