使用paddleocr实现图片文字智能提取 |
您所在的位置:网站首页 › word中怎么提取图片中的文字 › 使用paddleocr实现图片文字智能提取 |
使用paddleocr实现图片文字智能提取
|
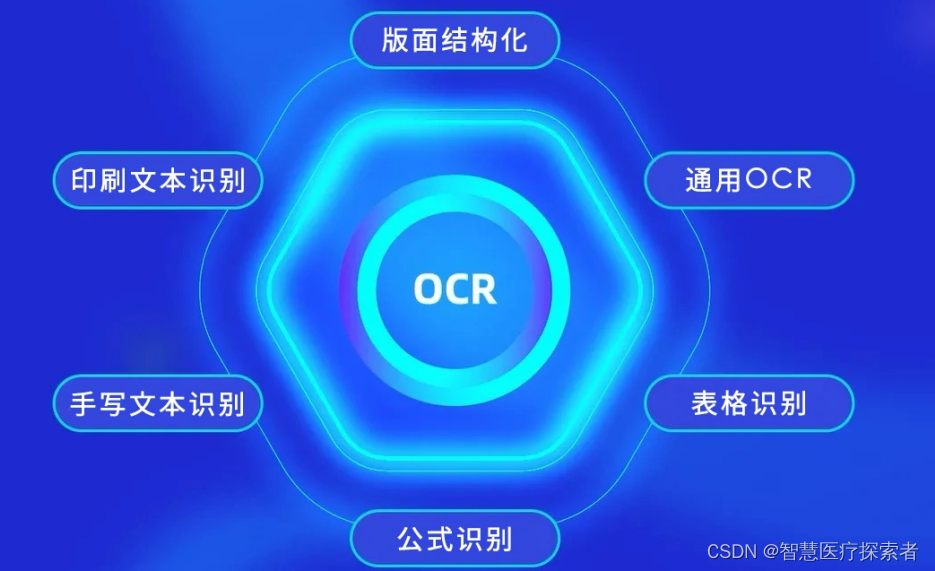
1 OCR介绍
OCR(Optical Character Recognition)即光学字符识别,是一种将不同类型的文档(如扫描的纸质文件、PDF文件或图像文件中的文本)转换成可编辑和可搜索的数据的技术。OCR技术能够识别和转换印刷或手写文字,广泛应用于数据录入、文档数字化和自动化处理领域。
OCR技术已经成为数字化时代不可或缺的一部分,它极大地方便了文本的转换和处理,为各个行业的数字化转型做出了贡献。随着技术的不断进步,OCR的应用范围将进一步拓宽,为更多领域带来便利和效率的提升。 1.1 基本原理OCR技术通常涉及以下几个步骤: 图像获取:首先获取文档的图像,这可以通过扫描纸质文档或拍摄图片来实现。 预处理:对图像进行预处理,以提高识别的准确性。这包括去噪、调整对比度、校正扭曲、二值化等。 文本检测与分割:在预处理后的图像中检测文本区域,并将其分割为行、单词或字符。 字符识别:利用模式识别技术,识别分割出的字符或单词。 后处理:将识别结果进行校正和格式化,例如修正拼写错误、保持文本的结构和格式等。 1.2 技术发展早期技术:早期的OCR系统依赖于简单的模板匹配技术,只能处理特定字体和格式。 进阶技术:随着机器学习和人工智能的发展,OCR技术引入了更复杂的算法,如神经网络,大大提高了识别的准确率和灵活性。 深度学习:最近,深度学习在OCR领域的应用取得了显著的进步,特别是在处理复杂场景和手写文本方面。 1.3 应用领域文档自动化处理:在办公自动化和文档管理系统中,OCR被用于快速输入和处理纸质文档。 银行和金融:银行使用OCR技术处理支票和其他金融文件。 法律和医疗领域:OCR有助于快速转换和管理大量的法律和医疗记录。 教育和研究:在教育和学术研究中,OCR可用于数字化历史文档和图书。 无障碍服务:OCR技术有助于为视觉障碍人士提供无障碍阅读服务。 1.4 挑战与限制识别准确率:虽然现代OCR技术已经很先进,但仍然可能在复杂的布局或低质量图像中遇到识别准确性的问题。 语言和字体多样性:对于一些较少使用的语言或特殊的字体,OCR软件可能难以准确识别。 手写文本识别:手写文本的变化性和复杂性使得其识别难度较高。 1.5 未来发展方向技术改进:不断改进OCR技术,提高对复杂文本和图像的处理能力。 深度学习的应用:利用深度学习模型进一步提升识别准确率和速度。 多语种支持:增强对多种语言和方言的支持能力。 集成与应用拓展:将OCR技术与其他技术结合,如自然语言处理(NLP),扩展到更多应用场景。 2 paddleocr介绍PaddleOCR是由百度开发的一款开源光学字符识别(OCR)工具,基于PaddlePaddle深度学习框架。它专注于提供轻量级、灵活且高效的OCR解决方案,旨在帮助开发者和研究人员在各种应用场景中快速部署OCR功能。PaddleOCR涵盖了OCR的全流程,包括文本检测、文本识别和文本校正等环节。
PaddleOCR是一个功能强大且灵活的OCR工具,它基于深度学习技术,提供了高效和准确的文字识别能力。它的轻量级设计、多语种支持和易用性使其适用于多种应用场景。作为一个开源项目,PaddleOCR持续发展和完善,是构建OCR应用的优秀选择。随着技术的不断进步和应用需求的日益增长,PaddleOCR将在自动化处理和智能识别领域发挥更大的作用。 项目地址:https://github.com/PaddlePaddle/PaddleOCR 体验地址:https://aistudio.baidu.com/application/detail/7658 2.1 核心特性多语种支持: PaddleOCR支持多种语言的识别,包括英文、中文、日文、韩文等,满足全球化应用的需求。 高识别准确率: 基于先进的深度学习模型和算法,PaddleOCR在多个公开数据集上展现出优秀的识别性能。 轻量化模型: 提供了轻量级模型,适用于移动设备和边缘计算场景,能够在资源受限的环境中快速运行。 灵活易用: PaddleOCR提供了简洁的API和丰富的文档,使得开发者可以轻松集成OCR功能到自己的应用中。 开源社区: 作为一个开源项目,PaddleOCR拥有活跃的社区支持,持续更新和改进。
文本检测: PaddleOCR使用深度学习模型来检测图像中的文本区域。它支持检测多种形状和布局的文本,如水平文本、倾斜文本和弯曲文本。 文本识别: 在检测出文本区域后,PaddleOCR使用文本识别模型来识别这些区域中的文字内容。 文本校正: 对于检测或识别过程中的错误,PaddleOCR提供了文本校正功能,以提高最终识别结果的准确性。 2.3 应用场景文件数字化: PaddleOCR可用于将纸质文件或PDF文档转换为可编辑的数字格式。 身份验证: 在身份验证和KYC(了解你的客户)流程中,PaddleOCR可以用来识别身份证件上的信息。 自动化办公: 在自动化办公系统中,PaddleOCR可以用于自动处理和分析文档中的文字。 智能交通: 在智能交通系统中,PaddleOCR可以用于车牌识别和交通标志识别。 零售和商业分析: PaddleOCR可以应用于零售场景,用于识别收据、发票和产品标签上的信息。 2.4 性能优化和部署模型优化: PaddleOCR针对不同的应用场景提供了多种优化后的模型,以满足性能和资源消耗之间的平衡。 跨平台部署: PaddleOCR支持在多种平台上部署,包括服务器、云平台、移动设备和IoT设备。 容器化和云服务: PaddleOCR支持容器化部署,也可以作为云服务提供OCR能力。 2.5 社区和支持开源协作: 作为一个开源项目,PaddleOCR鼓励社区成员参与贡献,包括代码贡献、问题反馈和功能建议。 文档和示例: PaddleOCR提供了详细的文档、快速入门指南和丰富的应用示例,帮助开发者快速上手。 3 使用paddleocr进行文字识别 3.1 conda环境准备conda环境准备详见:annoconda 3.2 运行环境构建 conda create --name paddleocr python=3.8 conda activate paddleocr git clone https://github.com/PaddlePaddle/PaddleOCR cd PaddleOCR pip install paddlepaddle==2.5.2 -i https://mirror.baidu.com/pypi/simple pip install -r requirements.txt pip install paddleocr==2.7.0.3 -i https://mirror.baidu.com/pypi/simple 3.3 模型下载PP-OCR系列模型列表 模型简介模型名称推荐场景检测模型方向分类器识别模型中英文超轻量PP-OCRv4模型(15.8M)ch_PP-OCRv4_xx移动端&服务器端推理模型 / 训练模型推理模型 / 训练模型推理模型 / 训练模型中英文超轻量PP-OCRv3模型(16.2M)ch_PP-OCRv3_xx移动端&服务器端推理模型 / 训练模型推理模型 / 训练模型推理模型 / 训练模型英文超轻量PP-OCRv3模型(13.4M)en_PP-OCRv3_xx移动端&服务器端推理模型 / 训练模型推理模型 / 训练模型推理模型 / 训练模型 超轻量OCR系列更多模型下载(包括多语言),可以参考PP-OCR系列模型下载,文档分析相关模型参考PP-Structure系列模型下载PaddleOCR场景应用模型 行业类别亮点文档说明模型下载制造数码管识别数码管数据合成、漏识别调优光功率计数码管字符识别下载链接金融通用表单识别多模态通用表单结构化提取多模态表单识别下载链接交通车牌识别多角度图像处理、轻量模型、端侧部署轻量级车牌识别下载链接 更多制造、金融、交通行业的主要OCR垂类应用模型(如电表、液晶屏、高精度SVTR模型等),可参考场景应用模型下载根目录下创建models目录 mkdir models下载检测模型:ch_PP-OCRv4_det_infer.tar 下载方向分类器:ch_ppocr_mobile_v2.0_cls_infer.tar 下载识别模型:ch_PP-OCRv4_rec_infer.tar 下载完成后,解压存储到models目录中 3.4 识别效果展示 3.4.1 文字检测 python tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./models/ch_PP-OCRv4_det_infer"
其他识别结果展示
输入图片:
识别结果: ('浦发银行', 0.9934564232826233) ('UnionPay', 0.9892090559005737) ('银联', 0.9966715574264526) ('SPDBANK', 0.9192584156990051) ('45641880010', 0.8774389624595642) ('010', 0.9592215418815613) ('4564', 0.95279860496521) ('MONTH/YEAR', 0.9459193348884583) ('MONTH/YEAR', 0.9803943634033203) ('00/00', 0.9096955060958862) ('VALID', 0.9954994320869446) ('00/00', 0.901260256767273) ('VALID', 0.8590766787528992) ('FROM', 0.8717232942581177) ('THRU', 0.8828291296958923) ('VISA', 0.9928451180458069) ('WANGWANGWANG', 0.9333059191703796) ('信用卡', 0.9985775947570801) |




【本文地址】
今日新闻 |
推荐新闻 |