VGG16模型代码实现 |
您所在的位置:网站首页 › vgg16实现cifar课程报告 › VGG16模型代码实现 |
VGG16模型代码实现
|
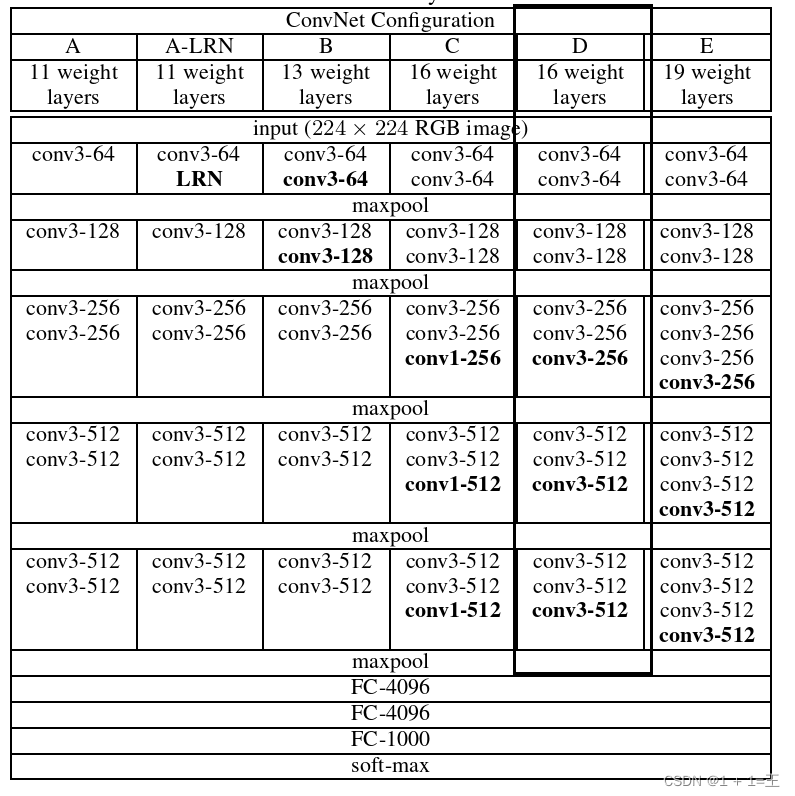
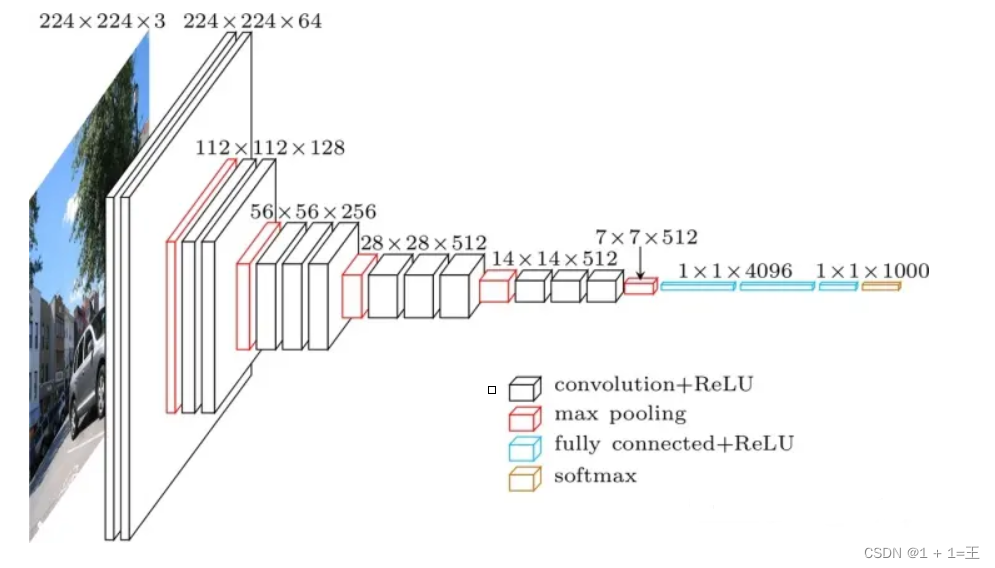
VGG16模型 原理图:(参考大佬)
在写程序前可以通过下面代码看系统是如何定义VGG16模型的: import torch import torch.nn as nn import torchvision import torchsummary model = torchvision.models.vgg16() print(model) torchsummary.summary(model, input_size=(3, 224, 224), batch_size=6, device="cuda")运行,得到以下结果,这样可以帮助我们更好理解原理。 VGG( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace=True) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace=True) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace=True) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace=True) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace=True) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace=True) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace=True) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace=True) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace=True) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace=True) (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(7, 7)) (classifier): Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=1000, bias=True) ) ) ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [6, 64, 224, 224] 1,792 ReLU-2 [6, 64, 224, 224] 0 Conv2d-3 [6, 64, 224, 224] 36,928 ReLU-4 [6, 64, 224, 224] 0 MaxPool2d-5 [6, 64, 112, 112] 0 Conv2d-6 [6, 128, 112, 112] 73,856 ReLU-7 [6, 128, 112, 112] 0 Conv2d-8 [6, 128, 112, 112] 147,584 ReLU-9 [6, 128, 112, 112] 0 MaxPool2d-10 [6, 128, 56, 56] 0 Conv2d-11 [6, 256, 56, 56] 295,168 ReLU-12 [6, 256, 56, 56] 0 Conv2d-13 [6, 256, 56, 56] 590,080 ReLU-14 [6, 256, 56, 56] 0 Conv2d-15 [6, 256, 56, 56] 590,080 ReLU-16 [6, 256, 56, 56] 0 MaxPool2d-17 [6, 256, 28, 28] 0 Conv2d-18 [6, 512, 28, 28] 1,180,160 ReLU-19 [6, 512, 28, 28] 0 Conv2d-20 [6, 512, 28, 28] 2,359,808 ReLU-21 [6, 512, 28, 28] 0 Conv2d-22 [6, 512, 28, 28] 2,359,808 ReLU-23 [6, 512, 28, 28] 0 MaxPool2d-24 [6, 512, 14, 14] 0 Conv2d-25 [6, 512, 14, 14] 2,359,808 ReLU-26 [6, 512, 14, 14] 0 Conv2d-27 [6, 512, 14, 14] 2,359,808 ReLU-28 [6, 512, 14, 14] 0 Conv2d-29 [6, 512, 14, 14] 2,359,808 ReLU-30 [6, 512, 14, 14] 0 MaxPool2d-31 [6, 512, 7, 7] 0 AdaptiveAvgPool2d-32 [6, 512, 7, 7] 0 Linear-33 [6, 4096] 102,764,544 ReLU-34 [6, 4096] 0 Dropout-35 [6, 4096] 0 Linear-36 [6, 4096] 16,781,312 ReLU-37 [6, 4096] 0 Dropout-38 [6, 4096] 0 Linear-39 [6, 1000] 4,097,000 ================================================================ Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 3.45 Forward/backward pass size (MB): 1312.69 Params size (MB): 527.79 Estimated Total Size (MB): 1843.92 ---------------------------------------------------------------- 进程已结束,退出代码为 0 完整代码 import torch import torch.nn as nn import torchvision import torchsummary # def show_model(): # model = torchvision.models.vgg16() # print(model) # torchsummary.summary(model, input_size=(3, 224, 224), batch_size=6, device="cuda") class Vgg16(nn.Module): #__init__()方法用于初始化模型的各个层和参数。 #in_channel参数表示输入数据的通道数;out_channel参数表示模型输出的特征数量;num_hidden参数表示全连接层的输入大小, def __init__(self,in_channel=3,out_channel=1000,num_hidden=25088): super(Vgg16, self).__init__() self.features = nn.Sequential( #block1 第一个卷积块 nn.Conv2d(in_channel,64,3,1,1),#输入通道数为in_channel,输出通道数为64,卷积核大小为3x3,步长为1,填充为1 nn.ReLU(inplace=True),#使用ReLU激活函数对特征图进行非线性变换,将计算结果覆盖原有数据,节省内存空间。 nn.Conv2d(64,64,3,1,1), nn.ReLU(inplace=True), nn.MaxPool2d(2,2),#使用最大值池化对特征图进行下采样,池化核大小为2x2,步长为2 # block2 nn.Conv2d(64, 128, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(128, 128, 3, 1, 1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), # block3 nn.Conv2d(128, 256, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, 3, 1, 1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), # block4 nn.Conv2d(256, 512, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, 3, 1, 1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), # block5 nn.Conv2d(512, 512, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, 3, 1, 1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), ) #self.avgpool是自适应平均池化层,可以根据输入数据的大小自动调整池化核的大小,并在不改变特征图大小的情况下进行下采样操作 #output_size=(7,7)表示得到的池化结果大小为7x7。 self.avgpool = nn.AdaptiveAvgPool2d(output_size=(7,7)) self.classifier = nn.Sequential( nn.Linear(num_hidden,4096),#输入大小为num_hidden,输出大小为4096,表示第一个全连接层 nn.ReLU(),#使用ReLU激活函数对特征进行非线性变换 nn.Dropout(),#在训练过程中对随机选取的神经元进行随机失活,防止过拟合 nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(), nn.Linear(4096, out_channel)#输入大小为4096,输出大小为out_channel,表示分类器 ) def forward(self,x):#前向传播函数forward(),用于对输入数据进行一次完整的正向计算过程 x = self.features(x) x = self.avgpool(x) x = torch.flatten(x,1) x = self.classifier(x) return x """ 将输入数据x作为参数输入到卷积部分self.features中,通过一系列卷积层、池化层和ReLU激活函数等操作提取特征信息。 将经过卷积部分后得到的特征图作为输入数据输入到自适应平均池化层self.avgpool中,将其下采样为固定大小(例如7x7)的输出结果。 将池化后的结果展开成一维向量,并输入到全连接部分self.classifier中,通过多层线性变换和非线性变换得到最终的分类结果。 将分类结果返回。 x:输入数据,例如一个batch的图片数据。 self.features:卷积部分,用于提取输入数据的特征信息。 self.avgpool:自适应平均池化层,用于对特征图进行下采样操作。 torch.flatten(x,1):将输入数据x展开成一维向量形式,方便输入到全连接部分中。 self.classifier:全连接部分,用于进行多层线性变换和非线性变换,得到最终的分类结果。 """ # show_model() vgg = Vgg16(3,1000,25088) print(vgg)运行,得到结果 Vgg16( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace=True) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace=True) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace=True) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace=True) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace=True) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace=True) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace=True) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace=True) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace=True) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace=True) (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(7, 7)) (classifier): Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU() (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU() (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=1000, bias=True) ) ) |
【本文地址】