【损失函数】MSE, MAE, Huber loss详解 |
您所在的位置:网站首页 › val函数是什么意思 › 【损失函数】MSE, MAE, Huber loss详解 |
【损失函数】MSE, MAE, Huber loss详解
|
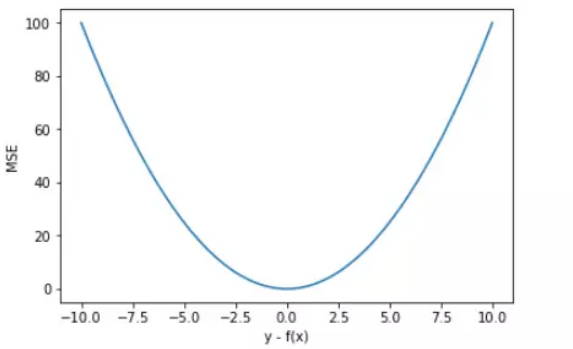
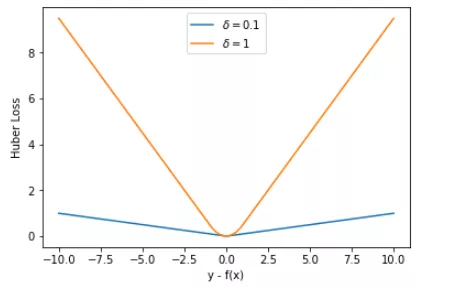
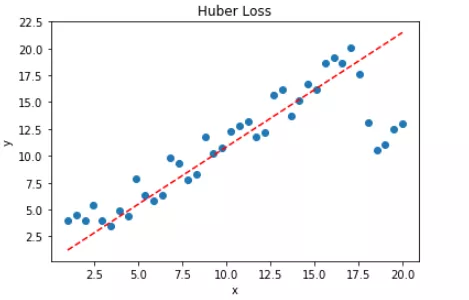
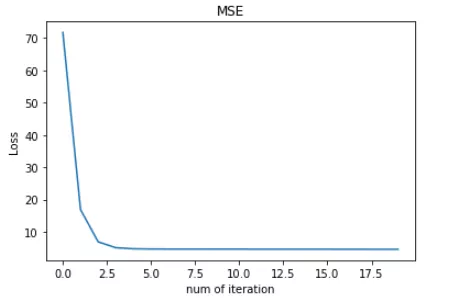
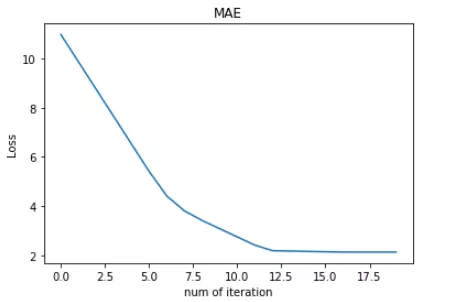
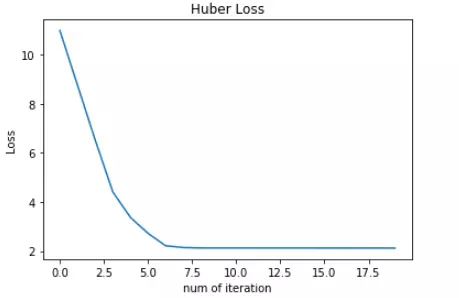
转载:https://mp.weixin.qq.com/s/Xbi5iOh3xoBIK5kVmqbKYA https://baijiahao.baidu.com/s?id=1611951775526158371&wfr=spider&for=pc 无论在机器学习还是深度领域中,损失函数都是一个非常重要的知识点。损失函数(Loss Function)是用来估量模型的预测值 f(x) 与真实值 y 的不一致程度。我们的目标就是最小化损失函数,让 f(x) 与 y 尽量接近。通常可以使用梯度下降算法寻找函数最小值。 关于梯度下降最直白的解释可以看我的这篇文章: 简单的梯度下降算法,你真的懂了吗? 损失函数有许多不同的类型,没有哪种损失函数适合所有的问题,需根据具体模型和问题进行选择。一般来说,损失函数大致可以分成两类:回归(Regression)和分类(Classification)。今天,红色石头将要总结回归问题中常用的 3 种损失函数,希望对你有所帮助。 回归模型中的三种损失函数包括:均方误差(Mean Square Error)、平均绝对误差(Mean Absolute Error,MAE)、Huber Loss。 1. 均方误差(Mean Square Error,MSE)均方误差指的就是模型预测值 f(x) 与样本真实值 y 之间距离平方的平均值。其公式如下所示: 其中,yi 和 f(xi) 分别表示第 i 个样本的真实值和预测值,m 为样本个数。 为了简化讨论,忽略下标 i,m = 1,以 y-f(x) 为横坐标,MSE 为纵坐标,绘制其损失函数的图形: MSE 曲线的特点是光滑连续、可导,便于使用梯度下降算法,是比较常用的一种损失函数。而且,MSE 随着误差的减小,梯度也在减小,这有利于函数的收敛,即使固定学习因子,函数也能较快取得最小值。 平方误差有个特性,就是当 yi 与 f(xi) 的差值大于 1 时,会增大其误差;当 yi 与 f(xi) 的差值小于 1 时,会减小其误差。这是由平方的特性决定的。也就是说, MSE 会对误差较大(>1)的情况给予更大的惩罚,对误差较小(1 还是 y-f(x) 0] = 1 mask[mask δ 时,则变成类似于 MAE,因此 Huber Loss 同时具备了 MSE 和 MAE 的优点,减小了对离群点的敏感度问题,实现了处处可导的功能。 通常来说,超参数 δ 可以通过交叉验证选取最佳值。下面,分别取 δ = 0.1、δ = 10,绘制相应的 Huber Loss,如下图所示: Huber Loss 在 |y−f(x)| > δ 时,梯度一直近似为 δ,能够保证模型以一个较快的速度更新参数。当 |y−f(x)| ≤ δ 时,梯度逐渐减小,能够保证模型更精确地得到全局最优值。因此,Huber Loss 同时具备了前两种损失函数的优点。 下面,我们用 Huber Loss 来解决同样的例子。 X = np.vstack((np.ones_like(x),x)) # 引入常数项 1 m = X.shape[1] # 参数初始化 W = np.zeros((1,2)) # 迭代训练 num_iter = 20 lr = 0.01 delta = 2 J = [] for i in range(num_iter): y_pred = W.dot(X) loss = 1/m * np.sum(np.abs(y-y_pred)) J.append(loss) mask = (y-y_pred).copy() mask[y-y_pred > delta] = delta mask[mask < -delta] = -delta W = W + lr * 1/m * mask.dot(X.T) # 作图 y1 = W[0,0] + W[0,1]*1 y2 = W[0,0] + W[0,1]*20 plt.scatter(x, y) plt.plot([1,20],[y1,y2],'r--') plt.xlabel('x') plt.ylabel('y') plt.title('MAE') plt.show()注意上述代码中对 Huber Loss 计算梯度的部分。 拟合结果如下图所示: 可见,使用 Huber Loss 作为激活函数,对离群点仍然有很好的抗干扰性,这一点比 MSE 强。另外,我们把这三种损失函数对应的 Loss 随着迭代次数变化的趋势绘制出来: MSE: MAE: Huber Loss:
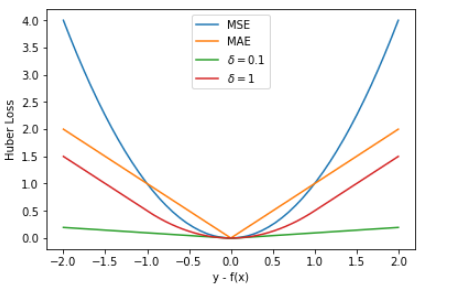
对比发现,MSE 的 Loss 下降得最快,MAE 的 Loss 下降得最慢,Huber Loss 下降速度介于 MSE 和 MAE 之间。也就是说,Huber Loss 弥补了此例中 MAE 的 Loss 下降速度慢的问题,使得优化速度接近 MSE。 最后,我们把以上介绍的回归问题中的三种损失函数全部绘制在一张图上。 好了,以上就是红色石头对回归问题 3 种常用的损失函数包括:MSE、MAE、Huber Loss 的简单介绍和详细对比。这些简单的知识点你是否已经完全掌握了呢? 除了MSE,MAE,huber loss,在回归任务中,我们还会使用log-cosh loss,它可以保证二阶导数的存在,有些优化算法会用到二阶导数,在xgboost中我们同样需要利用二阶导数;同时,我们还会用到分位数损失,希望能给不确定的度量。 除了log和hinge,在分类任务中,我们还有对比损失(contrastive loss)、softmax cross-entropy loss、中心损失(center loss)等损失函数,它们一般用在神经网络中。 4 focal loss转自:https://blog.csdn.net/zjucor/article/details/84259969 比如batch为32 sample的,8个多标签输出,可以等价看成32*8个sample的二分类问题,自然这32*8个sample正负样本比很容易不均(如果每个sample只有1,2个标签的话)。这是focal loss就可以发挥很大的作用了 For the multi-label classification, you can try tanh+hinge with {-1, 1} values in labels like (1, -1, -1, 1). Or sigmoid + hamming loss with {0, 1} values in labels like (1, 0, 0, 1). In my case, sigmoid + focal loss with {0, 1} values in labels like (1, 0, 0, 1) worked well. You can check this paper https://arxiv.org/abs/1708.02002. class FocalLoss(nn.Module): def __init__(self, gamma=2): super().__init__() self.gamma = gamma def forward(self, input, target): if not (target.size() == input.size()): raise ValueError("Target size ({}) must be the same as input size ({})" .format(target.size(), input.size())) max_val = (-input).clamp(min=0) loss = input - input * target + max_val + \ ((-max_val).exp() + (-input - max_val).exp()).log() invprobs = F.logsigmoid(-input * (target * 2.0 - 1.0)) loss = (invprobs * self.gamma).exp() * loss return loss.sum(dim=1).mean()
|
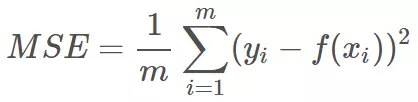
【本文地址】