软件应用 |
您所在的位置:网站首页 › stata计算hhi指数 › 软件应用 |
软件应用
|
Part1三阶嵌套泰尔T指数简介
泰尔指数(Theil Index)是一种特殊的广义熵指数,首次出现于Theil(1969),可用于测度区域不平等程度。由于其具有优良的可分解特性,因此泰尔指数常被用于识别发生在不同层级的不平等状况及其对总体不平等状况的贡献。 最常见的泰尔指数分解方法为“一阶段泰尔指数分解方法”,如下图所示,将总体区域差异分解为区域内差异和区域间差异两部分。这一分解方法也适用于除了地理区划外的其他特征,如城乡、性别等。国内最早一批使用一阶段泰尔指数分解的文献有秦红梅和李彦雯(2001)、陈宗胜和周云波(2001)等,其主要研究了行业、经济所有制、收入阶层、性别、年龄、文化程度等对收入差距的影响。 
图片来源:《经济数据量化分析》课程,刘华军教授主讲,《中国人口科学》杂志主办。链接:https://www.bilibili.com/read/cv17765786 在一阶段分解的基础上,可以进一步进行“两阶段嵌套泰尔指数分解”。两阶段嵌套泰尔指数分解(two-stage nested Theil decomposition)由Takahiro Akita(2003)提出,国内学者进行的相关研究中,较早的有鲁凤和徐建华(2006),其采用两阶段嵌套泰尔指数分解的方法研究了中国区域经济的差异。 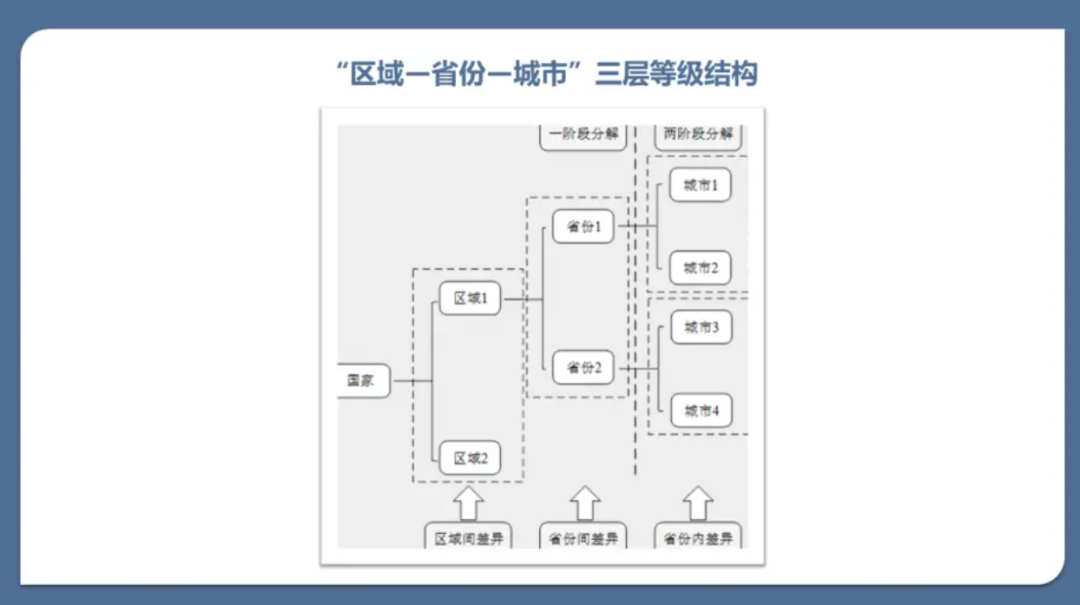
图片来源:《经济数据量化分析》课程,刘华军教授主讲,《中国人口科学》杂志主办。链接:https://www.bilibili.com/read/cv17765786 以此类推,当面对层级数更多的样本时,泰尔指数还可以继续分解。我们在此分享的就是在两阶段泰尔指数分解的基础上再分解一次的“三阶嵌套泰尔指数分解方法”,刘金东和靳连峰(2011)对三阶嵌套分解做了较早的尝试,对中国经济进行了包含地带、省、市、县的三阶嵌套分解,分解方法如下图所示: 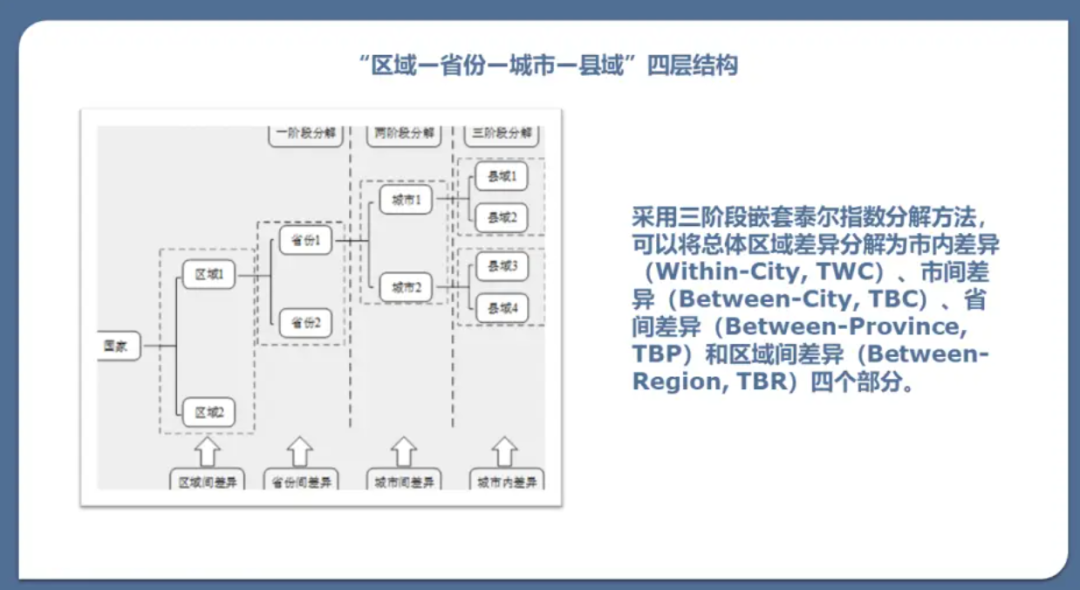
图片来源:《经济数据量化分析》课程,刘华军教授主讲,《中国人口科学》杂志主办。链接:https://www.bilibili.com/read/cv17765786 泰尔指数在分解时需要设置权重,权重不同的泰尔指数结果也不同,比如以要衡量不平等程度的数值为权重的被称为泰尔T指数,以样本个体数为权重的被称为泰尔L指数。我们计算的是泰尔T指数,这也是最常用的泰尔指数,公式如下: 
图片来源:刘金东和靳连峰,2011 Part2样例数据介绍如图所示,我们使用的样例数据共包含如下六个字段,每一行都表示了某一年度某个县级行政区的企业专利申请数量(对多个申请人共同申请的,我们将专利在所有申请人间平均分配,故会出现小数)。【年份】字段记录数据的年份,【区域】字段记录其属于六大地区中的哪个区域,【省】字段记录省级行政区,【地】字段记录地级行政区,【县】字段记录县级行政区,【count_w1】字段记录企业专利申请数,【X】字段全部为1,表示每个县级行政区都只看作一个个体。数据共有102456条。 利用以上数据,对每一年份,我们均可以将全国层面的、县级行政区的专利数量的不平等分解成四个部分:(1)发生在区域之间的;(2)发生在同一区域内部的不同省份之间的;(3)发生在同一省份内部的不同地级行政区之间的;(4)发生在同一地级行政区内部的不同县级行政区之间的。 需要注意的是,中国存在以下三类特殊的行政区划:一是直辖市,北京、天津、上海、重庆四大直辖市均由县级行政区构成,无地级行政区,故对这些地区,我们将其【地】字段用【县】字段的值填充,这意味着我们将直辖市的县级行政区看作地级行政区,并且直辖市内部仅有“地级行政区”之间的差距,而没有“县级行政区”之间的差距;二是其他省级行政区下的、由省份直管的县级行政区,例如河南省的济源市,我们对其同样将【地】字段用【县】字段的值填充,将其看作地级行政区;三是下面不含任何县级行政区的地级行政区,如广东省的东莞市和中山市,我们将其的【县】字段用【地】字段的值填充。以上三类地区在计算的过程中均不会出现最后一部分,即不会出现“发生在同一地级行政区内部的不同县级行政区之间的不平等”。 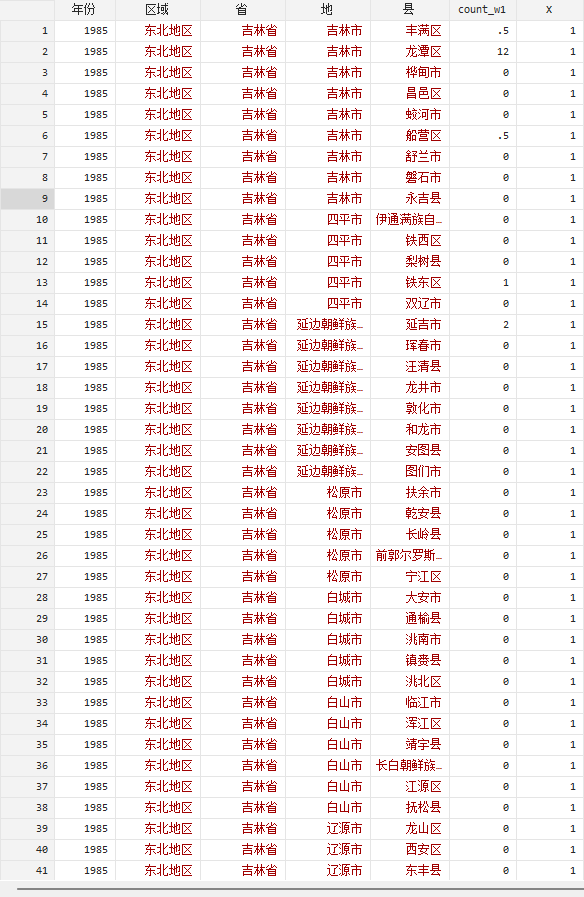 Part3 STATA代码介绍与使用说明
1.完整计算三阶嵌套泰尔T指数的情形
Part3 STATA代码介绍与使用说明
1.完整计算三阶嵌套泰尔T指数的情形
我们的STATA的Do文件中的代码依次由五部分组成: 第一部分是指定各个字段并将其赋给对应的暂元,并指定存储路径与文件名,最后是生成计算所需的各个变量,如下图所示: 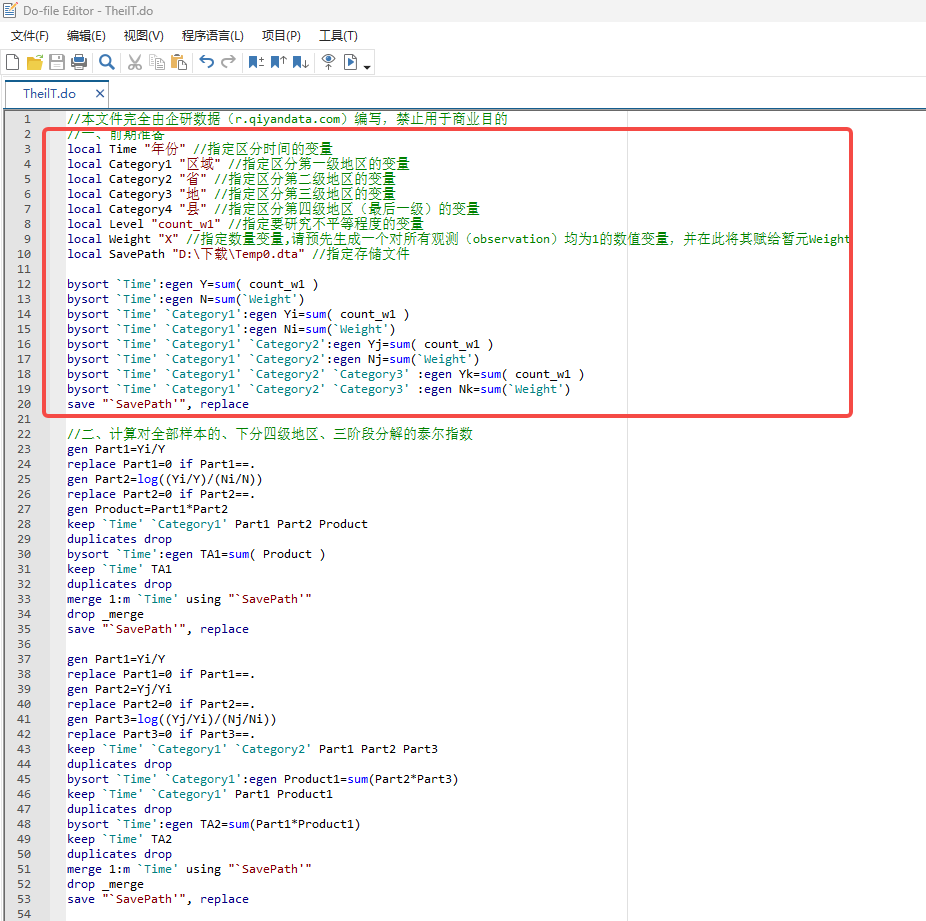
第二部分是计算对全部样本的、三阶段分解的泰尔指数,在我们使用的样例数据中,总体的不平等程度是全国所有的县级行政区的,记为TA;发生在区域之间的部分被记为TA1;发生在同一区域内部的不同省份之间的部分被记为TA2;发生在同一省份内部的不同地级行政区之间的被记为TA3;发生在同一地级行政区内部的不同县级行政区之间的被记为TA4;为了验证结果,我们将TA1到TA4相加,记为TA0,并将其与直接对所有地区计算的TA进行对比,两者相等证明计算和分解结果正确(由于存在计算误差,因此两者可能存在极小的偏差,偏差小于0.01%)。 第三部分是计算各个区域内部的、两阶段分解的泰尔指数,在我们使用的样例数据中,总体的不平等程度是各个区域内部所有的县级行政区的,记为TB;发生在同一区域内部的不同省份之间的部分被记为TB1;发生在同一省份内部的不同地级行政区之间的被记为TB2;发生在同一地级行政区内部的不同县级行政区之间的被记为TB3;为了验证结果,我们将TB1到TB3相加,记为TB0,并将其与直接对同个区域内所有地区计算的TB进行对比,两者相等证明计算和分解结果正确。 第四部分是计算各个省份内部的、一阶段分解的泰尔指数,在我们使用的样例数据中,总体的不平等程度是各个省份内部所有的县级行政区的,记为TC;发生在同一省份内部的不同地级行政区之间的被记为TC1;发生在同一地级行政区内部的不同县级行政区之间的被记为TC2;为了验证结果,我们将TC1到TC2相加,记为TC0,并将其与直接对单个省份内所有地区计算的TC进行对比,两者相等证明计算和分解结果正确。 第五部分是计算各个地级市内部的泰尔指数,无法分解,记为TD。 最终得到的数据表字段如下图所示,为方便比较,我们将全部样本的泰尔指数字段排在年份后;各区域内样本的泰尔指数字段排在区域后;各省份内样本的泰尔指数的字段排在省份后;各地级行政区内部样本的泰尔指数的字段排在地级行政区后。 
最终得到的计算结果如图所示:  2.使用该代码计算二阶段嵌套泰尔T指数、一阶段泰尔T指数或泰尔指数的方法
2.使用该代码计算二阶段嵌套泰尔T指数、一阶段泰尔T指数或泰尔指数的方法
我们分享的代码虽然必须包含完整的四个层级才能计算,但完全可以计算嵌套数更少的情形,例如,如果数据仅包含省、地、县三级而不包含区域级(或者不想考虑区域层面,只想从省级层面开始分解),即计算二阶段嵌套泰尔T指数,那么我们可以直接创建一个名为【区域】的字段,并将其所有取值都设为相同的值,例如“不区分”三个字,那么代码在处理时,会将其看作同一个区域处理,于是在TA TA0 TA1 TA2 TA3 TA4几个字段中,TA1将会是0,因为只有一个“区域”,所以区域之间的不平等自然为零,如下图所示;同样,也可以直接查看TB系列的泰尔指数,因为TB系列本来就是用来衡量同一区域内部的不平等。 
同样,如果只想研究地级和县级层面的,那么我们只需要将【区域】和【省】字段都设为“不区分”,那么就会直接从地级开始分解,TA1 TA2和TB1都会是0,如下图所示: 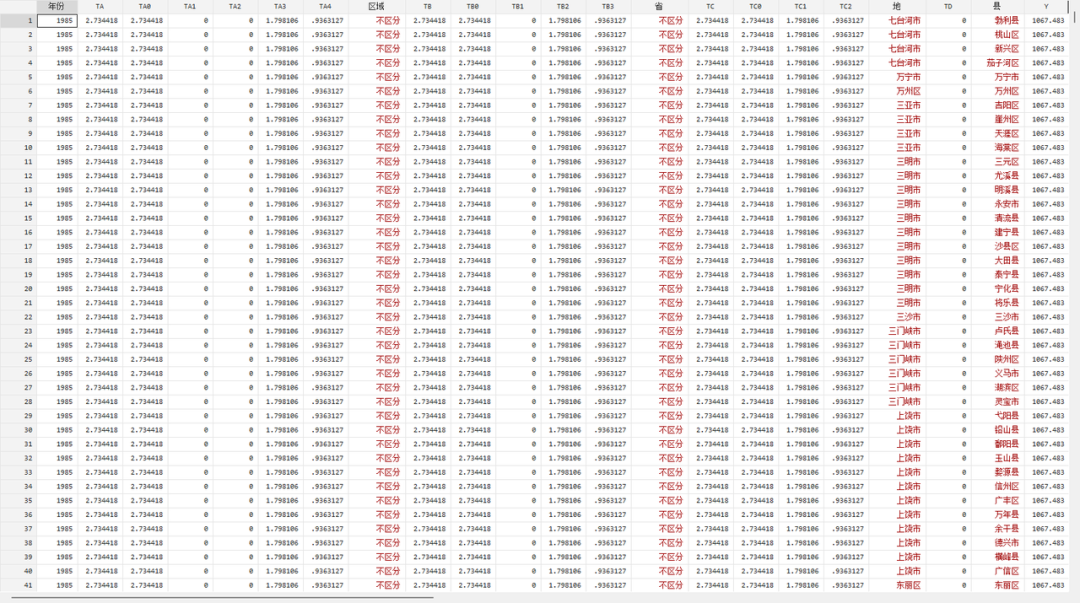
总之,使用本代码的原则是,Category1到Category4分别存储从高到低四个层级的区分变量,其中Category4必须存储用以计算不平等的最小单位的个体变量,在本样例中就是县级行政区。如果某个层级不想进行分解或缺少数据,直接将该层级的变量的取值统一成一个取值即可,那么按照泰尔指数的含义,该层级只有一个组别,将不存在组间差异,组间差异为0。以此方法可以计算出按区域——省——县分解的泰尔指数,或区域——地——县分解的泰尔指数。 Part4 参考文献[1]Johnston J. H. Theil. Economics and Information Theory[J]. The Economic Journal, 1969,79(315):601-602. [2]秦红梅,李彦雯.城镇居民收入分配差异及其影响[J].东岳论丛,2001(02):24-26 [3]陈宗胜,周云波.文化程度等人口特征对城镇居民收入及收入差别的影响——三论经济发展对收入分配的影响[J].南开经济研究,2001(04):38-42. [4]Takahiro, Akita. Decomposing regional income inequality in China and Indonesia using two-stage nested Theil decomposition method[J]. The Annals of Regional Science, 2003. [5]鲁凤,徐建华.基于不同区划系统的中国区域经济差异分解研究[J].人文地理,2006(02):77-81. [6]刘金东,靳连峰.基于泰尔指数嵌套分解的中国地区经济差异分析[J].税收经济研究,2011,16(01):87-93.DOI:10.16340/j.cnki.ssjjyj.2011.01.007. |
【本文地址】
今日新闻 |
推荐新闻 |