评价类模型之优劣解距离法(TOPSIS) |
您所在的位置:网站首页 › sqrt4等于多少pascal函数过程表 › 评价类模型之优劣解距离法(TOPSIS) |
评价类模型之优劣解距离法(TOPSIS)
|
当你得知自己这次期末考试的成绩为 96 分,乍一看觉得分数不错,但是问了一圈之后发现这次的题比较简单,大家普遍都得了高分,那你如何知道自己的成绩在班级中到底是好还是不好呢?  按照常理我们通常会直接对成绩进行一个排名然后观察自己的分数在班级的哪个水平,但这种评价方法只能给出一个方向的情况,只要保证排名不变,即使随意修改成绩,评分也不会发生改变。 而优劣解距离法(TOPSIS)的原理就是找出班上最高分和最低分,然后计算自己的分数和这两个分数之间的差距,从而得到自己分数好坏的一个客观评价。距离最高分越近,那么评价情况越好,距离最低分越近,那么评价情况越糟。 1 优劣解距离法(TOPSIS)简介1.1 概念TOPSIS 法是一种常用的组内综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。基本过程为基于归一化后的原始数据矩阵,采用余弦法找出有限方案中的最优方案和最劣方案,然后分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。该方法对数据分布及样本含量没有严格限制,数据计算简单易行 1.2 适用范围评价对象得分,且各个指标值已知。 1.3 模型基本步骤 1.31 将原始数据矩阵正向化。也就是将那些极小型指标,中间型指标,区间型指标对应的数据全部化成极大型指标,方便统一计算和处理。 1.32 将正向化后的矩阵标准化。也就是通过标准化消除量纲的影响。 1.33 计算每个方案各自与最优解和最劣解的距离 1.34 根据最优解与最劣解计算得分并排序 2 案例介绍及操作为了客观地评价各风景地点的性价比,根据风景、人文、拥挤程度、票价等因素对各风景地点进行评估。  风景和人文越高越好,这样的指标称为极大型指标(效益型指标) 拥挤程度和票价越少越好,这样的指标称为极小型指标(成本型指标) 2.1 原始数据同趋势化(一般选择指标正向化) 对于极小型指标: \begin{split} & \quad&x'=M-x \end{split} 对于中间型指标: x'=\left\{ \begin{split} &2\frac{x-m}{M-m},\qquad &m\le x\le\frac12(M+m)\\ &2\frac{M-x}{M-m},&\frac12(M+m)\le x\le M \end{split} \right. 对于区间型指标: x'=\left\{ \begin{split} &1-\frac{a-x}{a-a^*}\qquad &x\lt a \\ &1&a\le x\le b\\ &1-\frac{x-b}{b^*-b}&x\gt b \end{split} \right. 将极小型指标拥挤程度和票价正向化后得:  2.2 构建标准化矩阵 2.2 构建标准化矩阵对该元素除以所在列的平方和再开根号:  经过标准化后得到:  例如A景区的风景该指标,我们使用公式 Z_{11}=\frac{4}{\sqrt{4^{2}+7^{2}+5^{2}+6^{2}+8^{2}}}=0.29 2.3 计算各评价指标与最优及最劣向量之间的差距定义第i个评价对象与最大值的距离:  定义第i个评价对象与最小值的距离:  其中w_j 为第j个属性的权重(重要程度),指标权重可以使用熵权法或者层次分析法等方法确认。 D+和D-值的实际意义:评价对象与最优或最劣解的距离,值越大说明距离越远,研究对象D+值越大,说明与最优解距离越远;D-值越大,说明与最劣解距离越远。最理解的研究对象是D+值越小同时D-值越大。 对于上述数据,最大值【0.58,0.68,0.77,0.73】,最小值【0.29,0.14,0,0】,得到如下数据:  例如计算A景区的正理想解距离(D+): D_{A}^{+}=\sqrt{(0.58-0.29)^{2}+(0.68-0.34)^{2}+(0.77-0.77)^{2}+(0.73-0.73)^{2}}=0.43 2.4 评价对象与最优方案的接近程度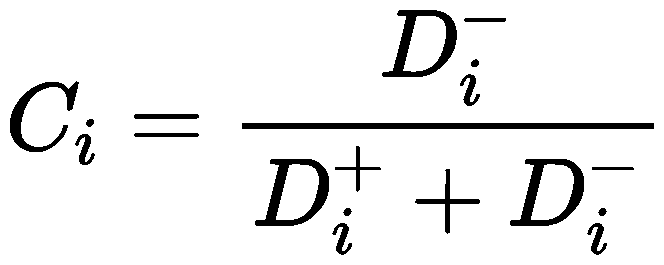 D-值相对越大,则说明该研究对象距离最劣解越远,则研究对象越好;C值越大, 表明评价对象越优  由上表可知,景点 A 的综合评价最高,说明综合评估风景、人文、拥挤程度、票价后,景点 A 的性价比较高,距离负理想解相对远,距离正理想解相对近。其次是D、E、C、B。 3 案例工具实现3.1 使用工具SPSSPRO—>【综合评价(优劣解距离法(TOPSIS))】 3.2 案例操作 Step1:新建分析; Step2:上传数据; Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;  step4:选择【优劣解距离法(TOPSIS)】; step5:查看对应的数据数据格式,【优劣解距离法(TOPSIS)】要求特征序列为定量变量,分为正向指标变量和负向指标变量,且正向指标变量和负向指标变量的个数之和大于等于两项。 step6:设置变量权重(熵权法、不设置权重)。 step7:点击【开始分析】,完成全部操作。 3.3 分析结果解读以下生成的结果来源于SPSSPRO软件的分析结果导出 输出结果 1:指标权重计算  熵权法的权重计算结果显示,风景的权重为 25.786%、人文的权重为 22.684%、拥挤程度的权重为 25.737%、票价的权重为 25.793%,其中指标权重最大值为票价(25.793%),最小值为人文(22.684%)。 输出结果 2:TOPSIS 评价法计算结果  由上表可知,景点 A 的综合评价最高,说明综合评估风景、人文、拥挤程度、票价后,景点 A 的性价比较高,距离负理想解相对远,距离正理想解相对近。 输出结果 3:中间值展示  正、负理想解(非距离),此两值分别代表评价指标的最大值,或者最小值(即最优解或最劣解),此两值用于计算D+或D-值使用,此两值大小并无太多意义。 注:进行 TOPSIS 分析时,各个指标有着权重属性(当然通常情况并没有),那么可对应设置各个指标的权重(输入的权重值可以为相对数字,SPSSPRO 默认都会进行归一化处理让权重加和为 1),在进行 D+和 D-值计算时,SPSSPRO 会对应乘上权重值(如果没有权重则下述公式中权重值为 1),计算公式如下:  对比层次分析法: 层次分析法的判断矩阵是通过“专家”评分获取的,主观性强,且n不宜过大。 优劣解距离法的指标评分则是现成的,且对较大的m与n同样适用。相较于层次分析法两两比较而言,优劣解距离法不易于发生混淆。 4 结论Topsis法避免了数据的主观性,不需要目标函数,不用通过检验,而且能够很好的刻画多个影响指标的综合影响力度,并且对于数据分布及样本量、指标多少无严格限制,既适于小样本资料,也适于多评价单元、多指标的大系统,较为灵活、方便。但是该算法需要每个指标的数据,而对应的量化指标选取会有一定难度,同时不确定指标的选取个数为多少适宜,才能够去很好刻画指标的影响力度 5 参考文献[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com. [2] Shih H S, Shyur H J, Lee E S. An extension of TOPSIS for group decision making[J]. Mathematical & Computer Modelling, 2007, 45(7):801-813. [3] 刘浩然,汤少梁. 基于 TOPSIS 法与秩和比法的江苏省基本医疗服务均等化水平研究[J]. 中国全科医学,2016,19(7):819-823. DOI:10.3969/j.issn.1007-9572.2016.07.017. |
【本文地址】