MySQL 语句(一) |
您所在的位置:网站首页 › sql语句删除重复的数据 › MySQL 语句(一) |
MySQL 语句(一)
|
前提
假设一种情况,数据库的数据重复了,只想保留最早一条。 比如,书库中《三体》录入了多次,想根据时间戳,只保留第一次入库的记录,也就是张三录入的记录。 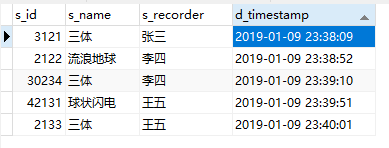 分析
分析
想要删除重复数据,需要找出不合适的数据,根据主键(s_id)删除掉。具体是以下两步: 找出想保留数据的id把其他的数据删除 实现 1、找出想保留数据的id,这一步是最关键的一步如果数据是自增长的,就比较简单,只需要一句 SELECT min(s_id) id from t_book GROUP BY s_name到此可以直接看第二步了。 但是如果id是uuid就会变得复杂,需要根据时间排序拿到第一条数据 SELECT min(d_timestamp) time,s_name FROM t_book GROUP BY s_name这样我们就拿到了同一本书最早的记录,但是缺少id。 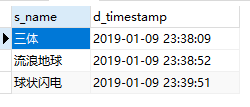
注意:这里不能把 id 直接写在SELECT 中,因为 id 不在GROUP BY后面。如果是 mysql8,强行添加在SELECT 就会报错,需要用 any_value(s_id) 处理,mysql5+ 虽然不会报错,但是和这个方法一样,从字面也能看出来,any_value 就是随便一个值,这样强行放置的结果就是拿到的数据id并不符合 min(d_timestamp) 这个条件。 想要拿到 id,需要再关联原始表。 SELECT t_left.s_name,t_right.s_id,t_right.s_name,t_right.d_timestamp FROM (SELECT min(d_timestamp) time,s_name FROM t_book GROUP BY s_name) t_left LEFT JOIN t_book t_right ON t_left.time=t_right.d_timestamp AND t_left.s_name=t_right.s_name关联结果: 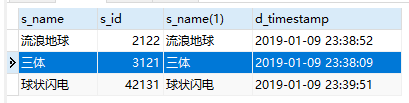
这样就拿到了需要保留数据的 id。 2、把其他的数据删除拿到了需要保留的 id ,就只需要通过 not in 语句删除不在这些 id 里面的数据就行了。一般就会写成如下这种,但是是会报错的 DELETE FROM t_book WHERE s_id not in ( SELECT t_right.s_id FROM (SELECT min(d_timestamp) time,s_name FROM t_book GROUP BY s_name) t_left LEFT JOIN t_book t_right ON t_left.time=t_right.d_timestamp AND t_left.s_name=t_right.s_name )错误信息如下,就是说不能直接操作原表数据 1093 - You can’t specify target table ‘t_book’ for update in FROM clause 解决方法是将当前表重新命名成一个独立的表 t_all,然后从 t_all 里面查询出来 id SELECT id FROM (SELECT t_right.s_id id FROM (SELECT min(d_timestamp) time,s_name FROM t_book GROUP BY s_name) t_left LEFT JOIN t_book t_right ON t_left.time=t_right.d_timestamp AND t_left.s_name=t_right.s_name) t_all最终的语句就是 DELETE FROM t_book WHERE s_id not in ( SELECT id FROM (SELECT t_right.s_id id FROM (SELECT min(d_timestamp) time,s_name FROM t_book GROUP BY s_name) t_left LEFT JOIN t_book t_right ON t_left.time=t_right.d_timestamp AND t_left.s_name=t_right.s_name) t_all )执行成功 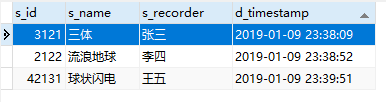
|
【本文地址】
今日新闻 |
推荐新闻 |