Mysql数据库中查询重复数据和去重数据 , 删除重复数据的sql及分析 |
您所在的位置:网站首页 › sql如何删除重复的数据和数据 › Mysql数据库中查询重复数据和去重数据 , 删除重复数据的sql及分析 |
Mysql数据库中查询重复数据和去重数据 , 删除重复数据的sql及分析
|
数据库中有重复数据时,用到哪些sql语句? 建表: CREATE TABLE `user` ( `id` bigint(255) NOT NULL AUTO_INCREMENT, `name` varchar(20) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '名称', `age` int(2) NOT NULL DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;这里有若干数据,并掺杂了重复数据 思路, group by 分组可以对多个列进行分组, 分组后可以过滤掉重复的数据 这里在mysql5.7以上版本会报错,因为不支持select那些group by和聚合函数之外的字段 sql语句: SELECT id,`name`,age,count(1) FROM user GROUP BY `name`,age
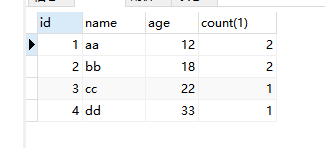
刚刚的语句已经把每个组对应的count数查询出来了,那么count>1的自然是重复的数据 SELECT id,`name`,age,count(1) as c FROM user GROUP BY `name`,age having c > 1
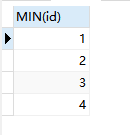
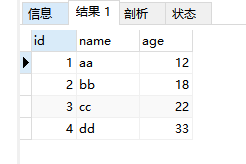
思路: 刚刚已经把重复的数据查询出来了,包括id, 那么查询出每个重复组中的唯一一个id,也就是x,就可以delete … id not in (x) 上面说虽然5.7以上版本默认不支持查询group by 以外的字段,比如id,但是聚合函数还是可以的 子语句1: SELECT MIN(id) FROM user GROUP BY name,age查询出来的id就是我们需要留下的不重复的数据的id 按理来说只要: delete from user where id not in 子语句1 DELETE FROM user WHERE id NOT IN ( SELECT MIN(id) FROM user GROUP BY name,age )但是报错了 DELETE FROM user WHERE id NOT IN ( SELECT MIN(id) FROM user GROUP BY name,age ) > 1093 - You can't specify target table 'user' for update in FROM clause > 时间: 0.007s因为在mysql中,不能在一条Sql语句中,即查询这些数据,同时修改这些数据 解决方法:select的结果再通过一个中间表temp进行select多一次,就可以避免这个错误 DELETE FROM user WHERE id NOT IN ( SELECT temp.min_id FROM ( SELECT MIN(id) min_id FROM user GROUP BY name,age )AS temp ); select * from user;删除成功: |
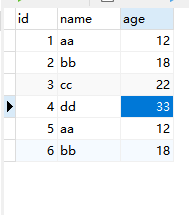
 这里要么把id去掉,要么选择临时方案:
这里要么把id去掉,要么选择临时方案:
【本文地址】
今日新闻 |
推荐新闻 |