SPSSAU综合评价方法汇总 |
您所在的位置:网站首页 › spss综合得分系数占比为负怎么办 › SPSSAU综合评价方法汇总 |
SPSSAU综合评价方法汇总
|
综合评价是对某事物进行多指标综合评价的过程,是一种科学研究和科学决策的过程。一般应当包括指标体系设计、收集资料、整理资料和统计分析几个阶段。 简单从分析角度来讲,综合评价方法步骤主要包括:确定指标体系、指标数据处理(无量纲化等)、确定指标权重、计算综合评价结果及综合排名。
上图中总结了5种综合评价方法,大致可分为两类: 其中TOPSIS法、熵值TOPSIS法、秩和比RSR法、灰色关联法均是使用小样本数据对多个指标进行综合评价,为每个评价对象计算综合得分,找出最优方案。 模糊综合评价则是以模糊数学为基础,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,进而对实际的综合评价问题提供总体性的评价。 指标数据处理(1)数据正向化/逆向化处理 在进行熵值法之前,如果数据方向不一致时,需要进行提前数据处理,通常为正向化或者逆向化两种处理。 如果数据中有逆向指标(数字越大反而越不好),此时需要使用【数据处理–生成变量】的“逆向化”功能处理。让数据变成正向指标(即数字越大说明越好)。
(2)无量纲化处理 不同指标数据,往往有着不同的量纲和量级,相互之间不可直接比较或者计算。针对数据进行标准化处理,可解决量纲化问题。常见的标准化处理方法有:标准化、归一化、初值化、均值化等。 具体可以在SPSSAU【数据处理–生成变量】里进行处理。
权重的确定方法在综合评价中重中之重,不同的权重计算方法对应的计算原理并不相同。在实际分析过程中,应结合数据特征及专业知识选择适合的权重计算方式。 计算综合评价结果上述介绍了指标数据处理,及指标权重的确定,接下来是每个综合评价方法的具体操作步骤说明,下面介绍的全部方法均可在SPSSAU【综合评价】模块找到进行分析。
SPSSAU综合评价 01 TOPSIS法 (1)理论说明 TOPSIS法是一种与理想方案相似性的顺序选优技术,通俗理解即为数据大小有优劣关系,数据越大越优,数据越小越劣,结合数据间的大小找出正负理想解以及正负理想解距离,并且在最终得到接近程序C值,并且结合C值排序得出优劣方案排序。 (2)数据格式
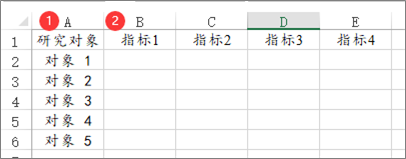
TOPSIS法数据格式要求1个指标占用1列数据。1个研究对象为1行,但研究对象在分析时并不需要使用,SPSSAU默认会从上到下依次编号。 (3)操作步骤 第一步: 准备好数据,并且进行同趋势化处理; 即让所有的数据表示为数字越大越优(如果某指标项数字越大反而越劣,可使用数据处理->生成变量功能的逆向化/倒数功能进行处理) 第二步: 数据归一化处理解决量纲问题; 无量纲化处理的方法很多种,通常选择为‘平方和归一化’。 第三步: 计算权重
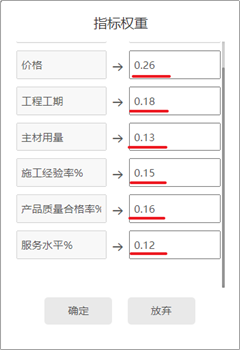
SPSSAU TOPSIS法 如果指标权重不相等,可勾选“指标权重”即可进行设置。
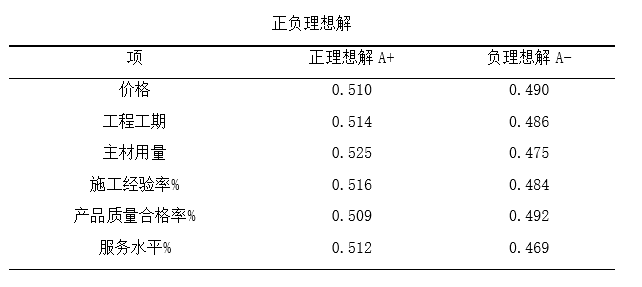
第四步: 找出最优和最劣矩阵向量(SPSSAU自动处理); 此步由SPSSAU自动得出,展示在“正负理想解”表格中。
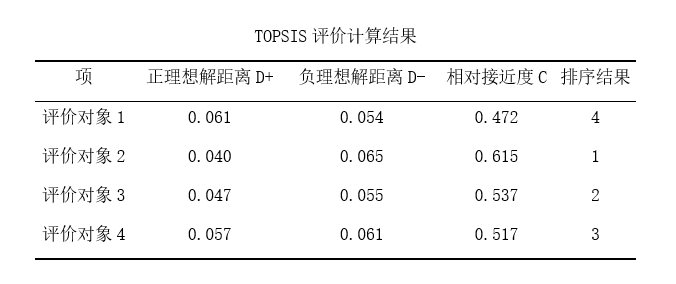
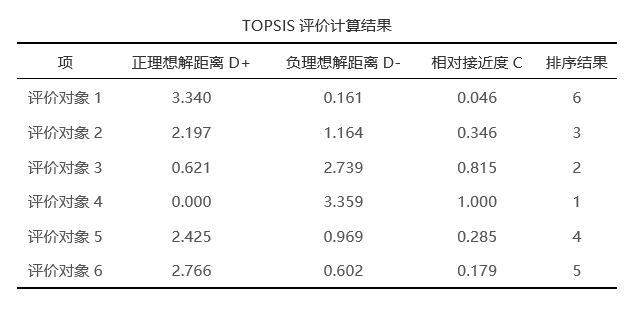
第五步: 分别计算评价对象与正理想解距离D+或负理想解距离D-;并结合距离值计算得出接近程序C值,并且进行排序,得出结论。 此步由SPSSAU自动得出,展示在“TOPSIS评价计算结果”表格中。
此表中按照样本顺序列出了每个评价对象正负理想结果、相对接近度值,以及最终排名结果。 02 熵值TOPSIS法 (1)理论说明 熵值法与TOPSIS法计算原理相同,区别在于topsis默认没有计算权重,熵权topsis以熵值法作为权重计算方法,在计算数据时,首先会利用熵值(熵权法)计算得到各评价指标的权重,并且将评价指标数据与权重相乘,得到新的数据,利用新数据进行TOPSIS法研究。 (2)数据格式
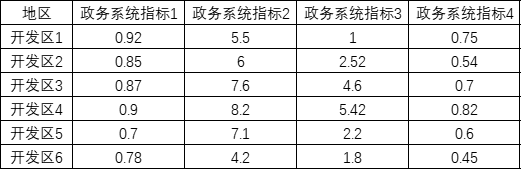
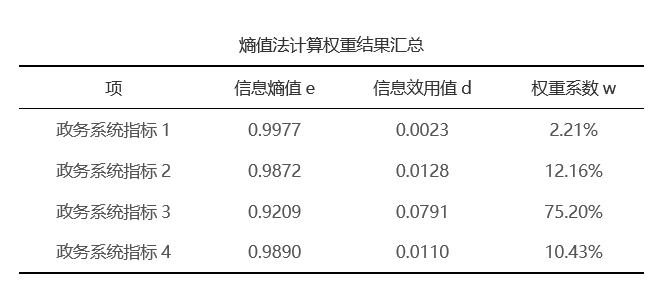
熵权TOPSIS法数据格式要求1个指标占用1列数据。1个研究对象为1行,但研究对象在分析时并不需要使用,SPSSAU默认会从上到下依次编号。 本例中有6个国家经济技术开发区,分别在政务系统的4个指标上的评分值。数字越大表示指标越优。当前希望利用熵权TOPSIS法评价出6个开发区的政务系统排名情况。 (3)操作步骤 第一步: 准备好数据,并且进行同趋势化处理 本例子的数据已经全部是正向指标,因此不需要进行正向化或逆向化处理 第二步: 数据归一化处理解决量纲问题 本例中没有量纲问题,即不需要进行处理。 第三步: 熵权法求权重,利用权重与数据相乘得到新数据newdata 此步骤为SPSSAU的中间处理过程,SPSSAU默认输出熵权法得到的权重值,并且默认在内部算法过程中计算得到newdata。
SPSSAU 熵权TOPSIS法
第四步: 利用TOPSIS法计算 此步骤为SPSSAU的自动处理,默认输出TOPSIS相关的指标结果。
从上表可知,利用熵权法后加权生成的数据进行TOPSIS分析,针对4个指标,进行TOPSIS评价,同时评价对象为6个(样本量数量即为评价对象数量)。 最终从上表可知:评价对象4,即开发区4,它的相对接近度C值最高为0.9995,因而说明开发区4在政务系统上的表现最优;其次是开发区3,相对接近度C起来0.8141。开发区1的政务系统表现最差。 03 灰色关联法 (1)理论说明 灰色关联分析法通过研究数据关联性大小(母序列与特征序列之间的关联程度),通过关联度(即关联性大小)进行度量数据之间的关联程度,从而辅助决策的一种研究方法。适用于因素之间相关关系比较复杂、没有明确的理论模型、信息不完全确定的小样本数据。 (2)数据格式
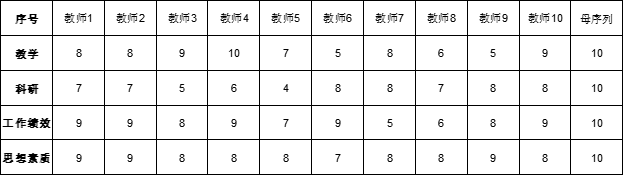
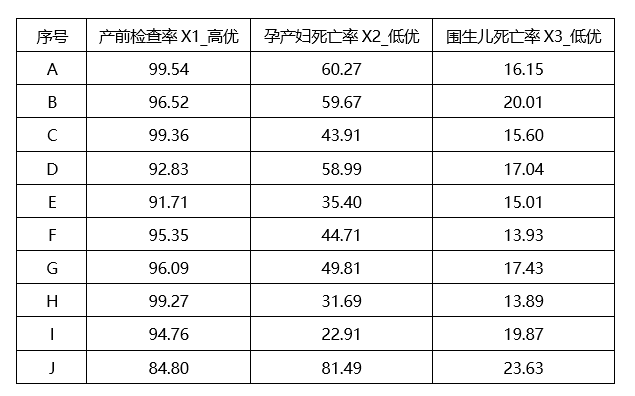
灰色关联的数据格式较为特殊,一列为一个特征序列,一行代表一个研究项。 在本例中,欲对10个教师的教学能力、科研水平、工作绩效、思想素质4个因素进行综合考察。 (3)操作步骤 第一步: 确定母序列和特征序列 母序列是在上面例子中母序列这一列,其他列均为特征序列。如果没有单独提供母序列,SPSSAU默认以特征序列的最大值作为母序列值。 第二步: 数据标准化处理 灰色关联法中无量纲化的方法常用的有初值化与均值化。初值化是指所有数据均用第1个数据除,得到新的数列,即这个数列为不同时刻的值相对于第1个时刻的百分比。经济序列(面板数据)中经常使用此方法处理。均值化是用平均值去除所有数据,以得到一个占平均值百分比的数列。 本例中已经确认好母序列和特征序列,并且按照正确格式上传,并且不存在量纲问题,因而选择“默认不处理”,操作如下。
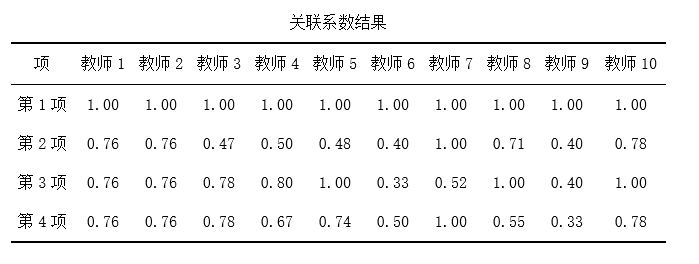
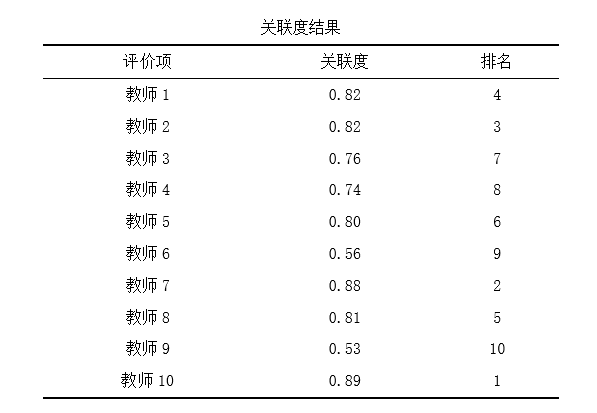
SPSSAU 灰色关联法 第三步: 计算关系系数及关联度,结合关联度值,得到每个评价项排名。
关联度值介于0~1之间,该值越大代表其与“参考值”(母序列)之间的相关性越强,也即意味着其评价越高。 从上表可以看出:针对本次10个评价项,教师10的综合评价最高(关联度为:0.89),其次是教师7(关联度为:0.88) 04 秩和比RSR法 (1)理论说明 秩和比(RSR)分析法广泛应用于医疗卫生领域的多指标综合评价,使用简单方便。比如医院医疗质量由多项指标反映,如病床的利用情况、出院这平均住院日、诊断符合率、手术前住院日等,可通过秩和比法进行综合评价。 其实质原理是利用了RSR值信息进行各项数学计算,RSR值介于0~1之间且连续,通常情况下,该值越大说明评价越‘优’。 (2)数据格式
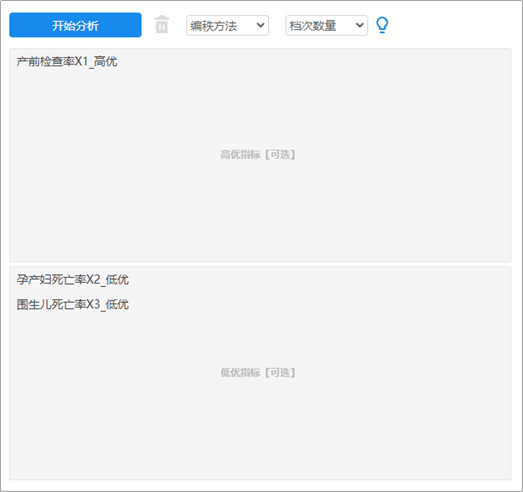
RSR秩和比数据格式上需要1列表示1上研究指标,1行表示1个研究对象。 本例欲对10个地区孕产妇保健工作的产前检查率X1,孕产妇死亡率X2,围生儿死亡率X3,结合此3个指标情况,针对10个地区进行综合评价并对此10个地区保健工作水平进行排序并且分档。 (3)操作步骤 第一步: 列出原始数据,一行代表一个评价对象,一列代表一个评价指标。最终为m*n矩阵。 将高优指标(数字越大越‘优’)、低优指标(数字越小越‘优’)分别放入分析框内。
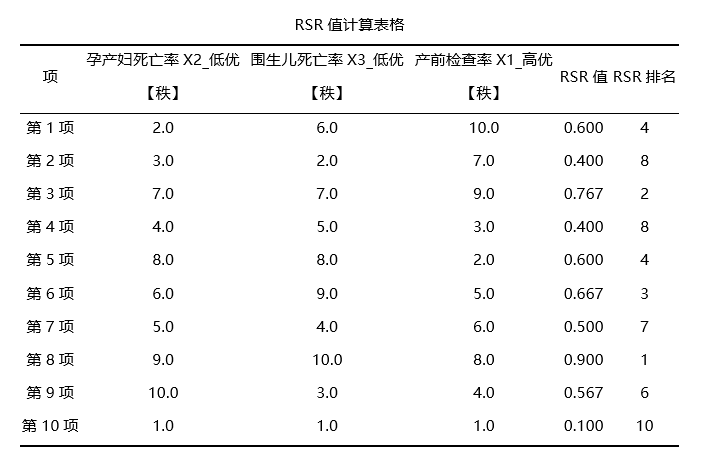
SPSSAU 秩和比RSR法 第二步: 对矩阵即原始数据进行计算秩值,利用秩值计算得到RSR值和RSR值排名(此步由SPSSAU自动处理)
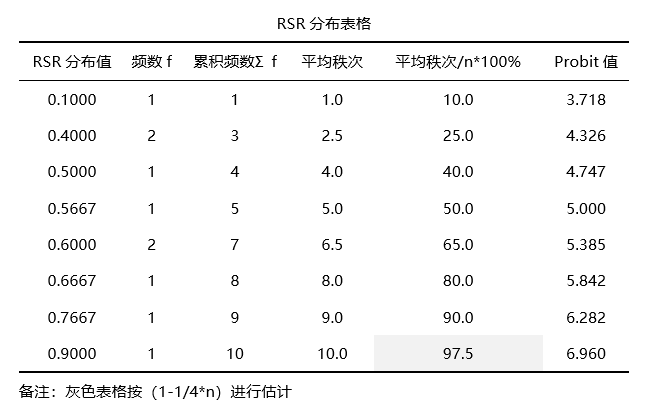
第三步: 列出RSR的分布表格情况并且得到Probit值,计算回归方程(此步由SPSSAU自动处理)
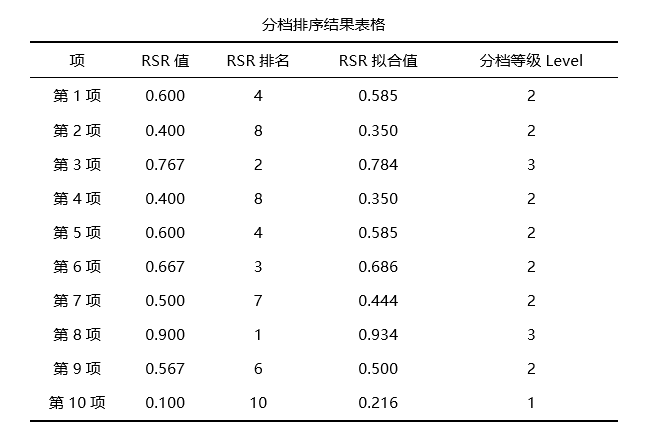
第四步: 进行排序,并且进行分档等级
上表格列出10个地区分别是的RSR值,RSR排名,以及RSR拟合值,并且结合分档排序临界值表格,得到最终10个地区的分档等级Level(注意:Level数字越大,代表等级越好)。 从上表可知:将10个地区分为3个等级,其中C,H最优;B,D,A,E,G,I,F共6个地区其次;J地区最差。并且也可以直接对10个地区进行排名,H排名最好,其次是C;J最差。 05 模糊综合评价 (1)适用范围 模糊综合评价借助模糊数学的一些概念,对实际的综合评价问题提供评价,即模糊综合评价以模糊数学为基础,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,进而进行综合性评价的一种方法。 (2)数据格式
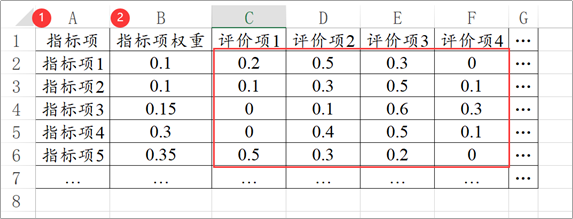
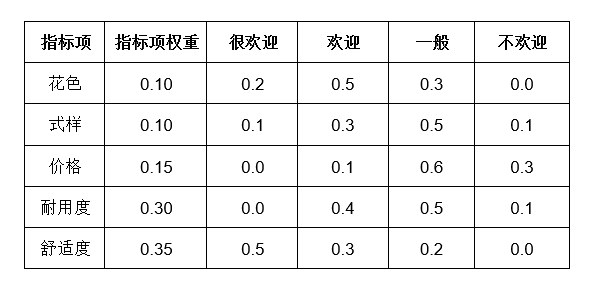
上传的数据一般包括三个部分:指标项、权重项、评语项。 其中指标项为参与评价的考核指标,1行放1个。 评语项,是指类似于{优秀,良好,一般,差} 或{非常满意,满意,一般,不满意,非常不满意}这样的评价标准。1列放1个评价项。 如果说各个指标项有着自己的权重,那么就需要单独用一列表示‘指标项权重’,‘如果没有此数据,则默认各个指标的权重完全一致。 特别提示: 一个表格对应的是一个评价对象的数据。如果有多个评价对象就需要构建多个表格矩阵,分别上传进行分析。 (3)操作步骤 第一步: 确定评价指标和评语集; 某服装品牌生产某种服装新款式,欲了解消费者对该种款式的接受程度。本例中评价指标为五项(花色,式样,价格,耐用度,舒适度),以及评语为四项(很欢迎,欢迎,一般,不欢迎)。
第二步: 确定权重向量矩阵A和构造权重判断矩阵R; 系统默认各指标权重是一样的。如果说五项指标(花色,式样,价格,耐用度,舒适度)的权重不一样此时可自行构评价指标权重。 第三步: 计算隶属度并进行决策评价;
SPSSAU 模糊综合评价法
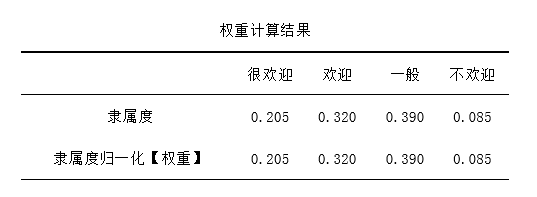
从上表可知,针对5个指标【样本量为5所以有5个指标】,以及4个评语集进行模糊综合评价;首先建立评价指标权重向量矩阵A,以及构建出5x4权重判断矩阵R,最终进行分析出4个评语集的权重值,分别是:0.205,0.320,0.390,0.085。 从上表可知,4个评语集中一般的权重值最高(0.390),结合最大隶属度法则可知,最终综合评价结果为"一般"。 第四步: 计算综合得分。 如果需要计算综合得分,则需要手工录入各个评语的重要性分值(比如优秀为4分,普通为3分,比较差为2分;非常差为1分;默认也可以全部为1分即重要性一致)。
模糊综合评价是一次针对一个研究对象计算结果,如果多个评价对象则要重复分析多次,再比较其综合得分。 |

【本文地址】