线性回归&逻辑回归 |
您所在的位置:网站首页 › spss线性回归r方小怎么办 › 线性回归&逻辑回归 |
线性回归&逻辑回归
|
文章目录
线性回归简介线性回归代码线性回归效果逻辑回归简介逻辑回归代码逻辑回归效果
线性回归简介
线性回归,就是能够用一条直线较为精确地描述数据之间的关系。这样当出现新的数据的时候,就能够预测出一个简单的值。 我们将这些数据通过python绘制出来,然后我们需要做的是找一条直线去最大化的拟合这些点,理想情况是所有点都落在直线上。希望所有点离直线的距离最近。简单起见,将距离求平方,误差可以表示为 找到最能拟合数据的直线,也就是最小化误差。通常我们使用的是最小二乘法 上述公式只有m, b未知,因此可以看最一个m, b的二次方程,求Loss的问题就转变成了求极值问题。 这里不做详细说明。另每个变量的偏导数为0, 求方程组的解。
然后我们通过梯度下降的方法去更新m和b。 在动手写算法之前我们需要理一下编写思路。回归模型主体部分较为简单,关键在于如何在给出 MSE损失函数之后基于梯度下降的参数更新过程。首先我们需要写出模型的主体和损失函数以及基于损失函数的参数求导结果,然后对参数进行初始化,最后写出基于梯度下降法的参数更新过程。 线性回归代码 import numpy as np import matplotlib.pyplot as plt # 计算loss def liner_loss(w,b,data): """ :param w: :param b: :param data: :return: """ x = data[:,0] # 代表的是第一列数据 y = data[:,1] # 代表的是第二列数据 # 损失函数:使用的是均方误差(MES)损失 loss = np.sum((y - w * x - b) ** 2) / data.shape[0] # 返回loss return loss # 计算梯度并更新参数 def liner_gradient(w,b,data,lr): """ :param w: :param b: :param data: :param lr: :return: """ # 数据集行数 N = float(len(data)) # 提取数据 x = data[:,0] y = data[:,1] # 求梯度 dw = np.sum(-(2 / N) * x * (y - w * x -b)) db = np.sum(-(2 / N) * (y - w * x -b)) # 更新参数 w = w - (lr * dw) b = b - (lr * db) return w,b # 每次迭代做梯度下降 def optimer(data,w,b,lr,epcoh): """ :param data: :param w: :param b: :param lr: :param epcoh:训练的次数 :return: """ for i in range(epcoh): # 通过每次循环不断更新w,b的值 w,b = liner_gradient(w,b,data,lr) # 每训练100次更新下loss值 if i % 100 == 0 : print('epoch {0}:loss={1}'.format(i,liner_loss(w,b,data))) return w,b # 绘图 def plot_data(data,w,b): """ :param data: :param w: :param b: """ x = data[:,0] y = data[:,1] y_predict = w * x + b plt.plot(x, y, 'o') plt.plot(x, y_predict, 'k-') plt.show() def liner_regression(): """ 构建模型 """ # 加载数据 data = np.loadtxt('D:\data.csv',delimiter=',') # 显示原始数据的分布 x = data[:, 0] y = data[:, 1] plt.plot(x, y, 'o') plt.show() # 初始化参数 lr = 0.01 # 学习率 epoch = 1000 # 训练次数 w = 0.0 # 权重 b = 0.0 # 偏置 # 输出各个参数初始值 print('initial variables:\n initial_b = {0}\n intial_w = {1}\n loss of begin = {2} \n'\ .format(b,w,liner_loss(w,b,data))) # 更新w和b w,b = optimer(data,w,b,lr,epoch) # 输出各个参数的最终值 print('final formula parmaters:\n b = {1}\n w = {2}\n loss of end = {3} \n'.format(epoch,b,w,liner_loss(w,b,data))) # 显示 plot_data(data,w,b) if __name__ == '__main__': liner_regression() 线性回归效果
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。
|
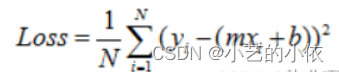
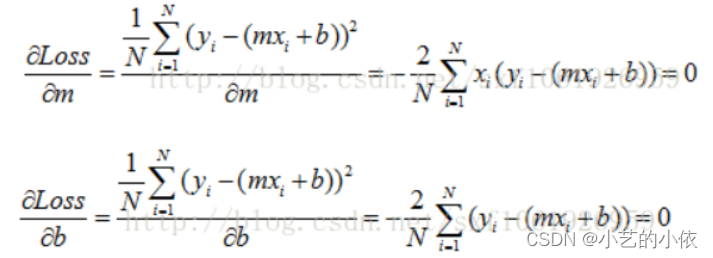


【本文地址】
今日新闻 |
推荐新闻 |