Python用KShape对时间序列进行聚类和肘方法确定最优聚类数k可视化 |
您所在的位置:网站首页 › r语言计算数据集的均值 › Python用KShape对时间序列进行聚类和肘方法确定最优聚类数k可视化 |
Python用KShape对时间序列进行聚类和肘方法确定最优聚类数k可视化
|
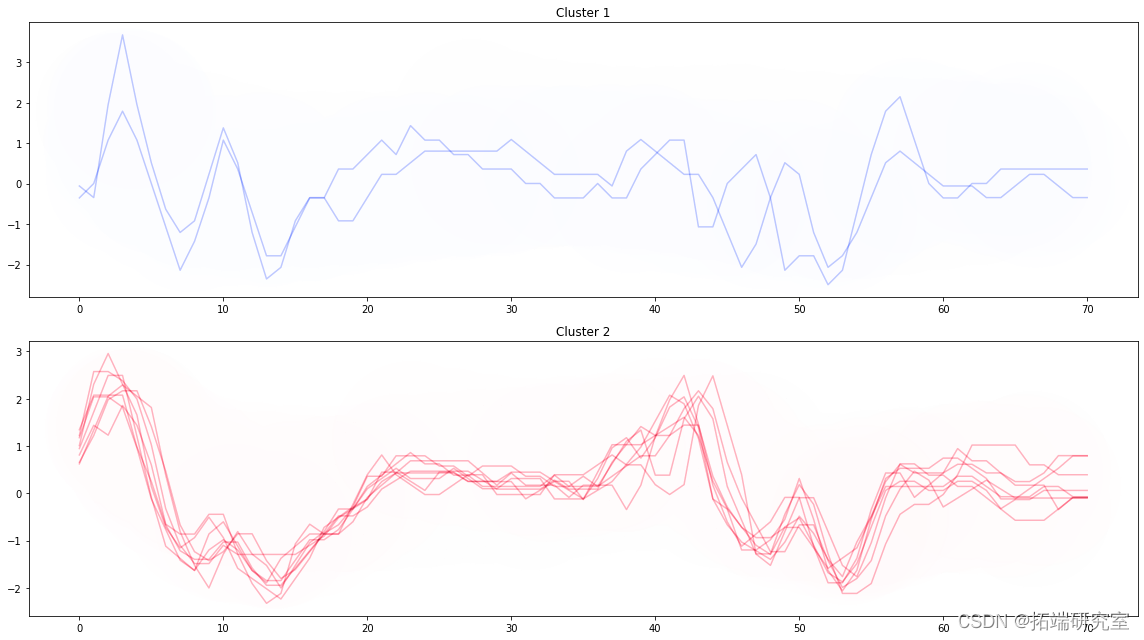
全文链接:http://tecdat.cn/?p=27078? 原文出处:拓端数据部落公众号 ?【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例 KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例 ,时长06:05 时序数据的聚类方法 该算法按照以下流程执行。 使用基于互相关测量的距离标度(基于形状的距离:SBD)根据 1 计算时间序列聚类的质心。(一种新的基于质心的聚类算法,可保留时间序列的形状)划分成每个簇的方法和一般的kmeans一样,但是在计算距离尺度和重心的时候使用上面的1和2。 import pandas as pd
什么是肘法... 计算从每个点到簇中心的距离的平方和,指定为簇内误差平方和 (SSE)。它是一种更改簇数,绘制每个 SSE 值,并将像“肘”一样弯曲的点设置为最佳簇数的方法。 #计算到1~10个群组 for i in range(1,11): #进行聚类计算。 ks.fit(sacdta) #KS.fit给出KS.inrta_ disorons.append(ks.netia_) plt.plot(range(1,11), disorins, marker='o')
最受欢迎的见解 1.R语言k-Shape算法股票价格时间序列聚类 2.R语言中不同类型的聚类方法比较 3.R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归 4.r语言鸢尾花iris数据集的层次聚类 5.Python Monte Carlo K-Means聚类实战 6.用R进行网站评论文本挖掘聚类 7.用于NLP的Python:使用Keras的多标签文本LSTM神经网络 8.R语言对MNIST数据集分析 探索手写数字分类数据 9.R语言基于Keras的小数据集深度学习图像分类 |
 ?
? ?
? ?
? ?
? ?
?【本文地址】
今日新闻 |
推荐新闻 |