R 笔记 MICE |
您所在的位置:网站首页 › r语言缺失值的处理方法 › R 笔记 MICE |
R 笔记 MICE
|
1 MICE 算法理论部分
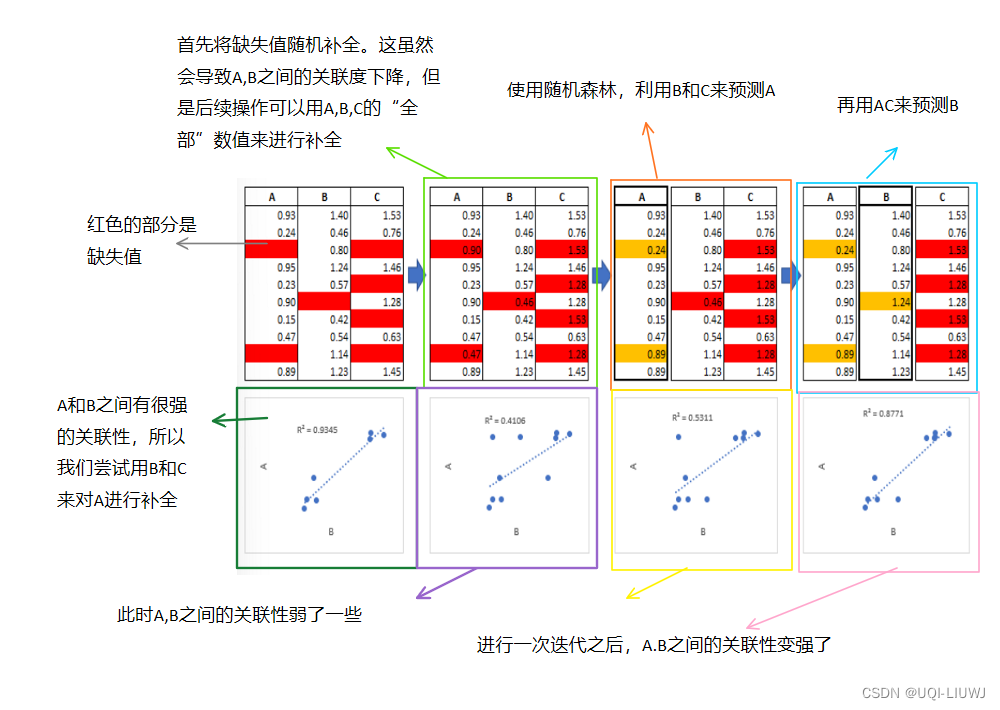
MICE(Multiple Imputation by Chained Equations)是一种处理数据集中缺失数据的稳健、信息丰富的方法。 该过程通过一系列迭代的预测模型“填充”(估算)数据集中的缺失数据。 在每次迭代中,数据集中的每个指定变量都使用数据集中的其他变量进行估算。 不断迭代在,直至收敛。 1.1 MICE举例
上述这个过程一直持续到所有指定的变量都被插补。 如果没有收敛,则可以运行额外的迭代,尽管通常不超过 5 次迭代是必要的。 插补的准确性取决于数据集中的信息密度。 没有相关性的完全独立变量的数据集不会产生准确的插补。 1.2 PMM,Predictive Mean MatchingMICE 可以使用称为预测均值匹配 (PMM) 的程序来选择要估算的值。 PMM 从原始非缺失数据中选择一个数据点,该数据点的预测值接近缺失样本的预测值。 选择最接近的 N个数据点作为候选值,从中随机选择一个值来进行补全。
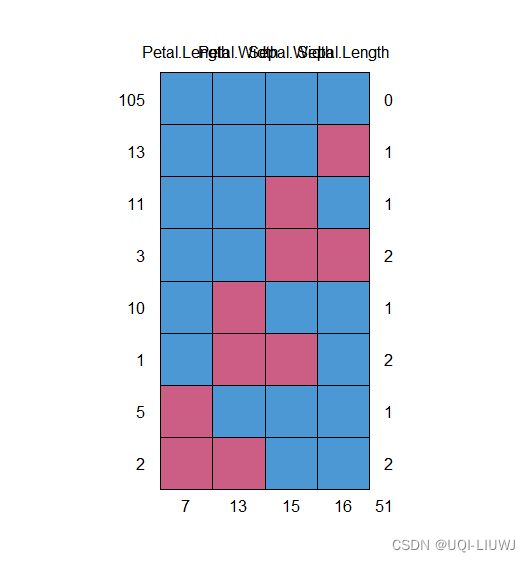
随机在数据里产生 10% 的 缺失值。同时把 Species 这个分类变量也去掉。 iris_mis % select(-Species) summary(iris_mis) # Sepal.Length Sepal.Width Petal.Length # Min. :4.300 Min. :2.000 Min. :1.000 # 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.500 # Median :5.800 Median :3.000 Median :4.300 # Mean :5.856 Mean :3.049 Mean :3.707 # 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 # Max. :7.900 Max. :4.200 Max. :6.900 # NA's :16 NA's :15 NA's :7 # Petal.Width # Min. :0.100 # 1st Qu.:0.300 # Median :1.300 # Mean :1.201 # 3rd Qu.:1.800 # Max. :2.500 # NA's :13 2.3 可视化缺失数据 md.pattern(iris_mis)
表达的意思是Petal.Length一共7个missing 数据,其中两个和第二列的Petal.Weight在同样的坐标处丢失数据;剩下5个只有在自己的坐标处丢失数据。 2.4 进行补全 imputed_Data |

【本文地址】