【第一章】Python爬虫教程(urllib模块、requests模块、get/post请求、User |
您所在的位置:网站首页 › requests爬虫教程 › 【第一章】Python爬虫教程(urllib模块、requests模块、get/post请求、User |
【第一章】Python爬虫教程(urllib模块、requests模块、get/post请求、User
|
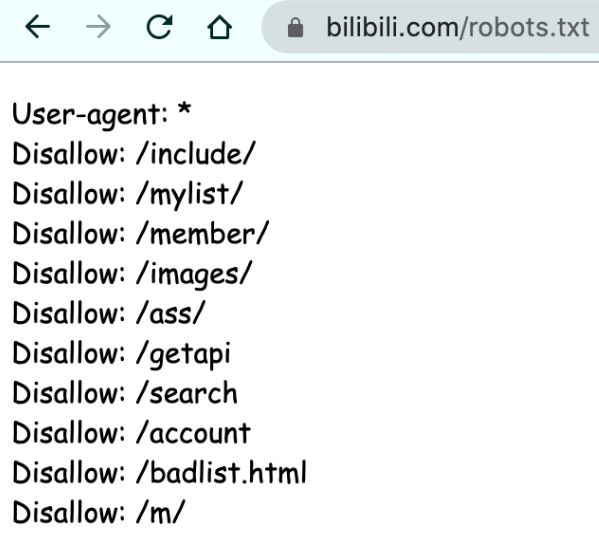
本课程共五个章节,课程地址: 【Python爬虫教程】花9888买的Python爬虫全套教程2021完整版现分享给大家!(已更新项目)——附赠课程与资料_哔哩哔哩_bilibili 第一章 爬虫概述本课程使用的软件手刃一个小爬虫web请求全过程剖析HTTP协议requests模块入门目录 第一章 (一)爬虫概述 (三)手刃一个小爬虫 (四)web请求全过程剖析 (五)HTTP协议 (六)requests模块入门 安装 案例一:get请求(headers参数) 案例二:post请求(带参数用data) 案例三:get请求(带参数用params) (补充)字符集问题 第一章总结 (一)爬虫概述爬虫就是通过编写程序来爬取互联网上的优秀资源(图片、音频、视频、数据) 反爬机制:门户网站可以通过制定相应的策略或技术手段,防止爬虫程序进行网站数据的爬取反反爬策略:爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中相关的数据robots.txt 协议(君子协议):规定了网站中哪些数据可以被爬虫爬取,哪些数据不可以被爬取,如输入 https://www.bilibili.com/robots.txt
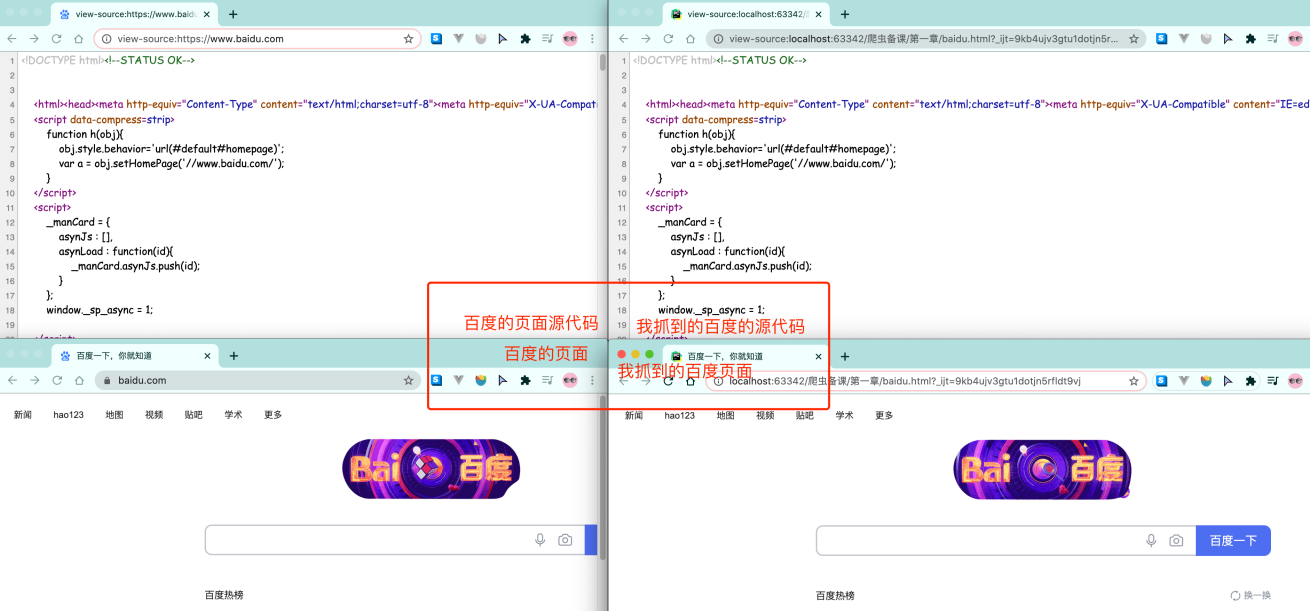
比如,此时我需要百度的资源,爬虫即用代码模拟一个浏览器,然后同样的输入百度的网址,程序就可以拿到百度的内容。在python中,用urllib模块来完成对浏览器的模拟工作 from urllib.request import urlopen resp = urlopen("http://www.baidu.com") # 打开百度 print(resp.read().decode("utf-8")) # 打印抓取到的内容 resp.close() # 关掉resp可以把抓取到的html内容全部写入到文件中,然后和原版的百度进行对比,看看是否一致 # 爬虫: 通过编写程序来获取到互联网上的资源 # 百度 # 需求: 用程序模拟浏览器. 输入一个网址. 从该网址中获取到资源或者内容 from urllib.request import urlopen # request表示请求,相当于输入网址后按下回车键 url = "http://www.baidu.com" resp = urlopen(url) # resp表示响应 with open("mybaidu.html", mode="w",encoding="utf-8") as f: # .decode()表示将字节转成字符串 f.write(resp.read().decode("utf-8")) # 读取到网页的页面源代码 print("over!") resp.close() # 关掉resp对生成的 mybaidu.html 文件,右键,Open In ——> Browser
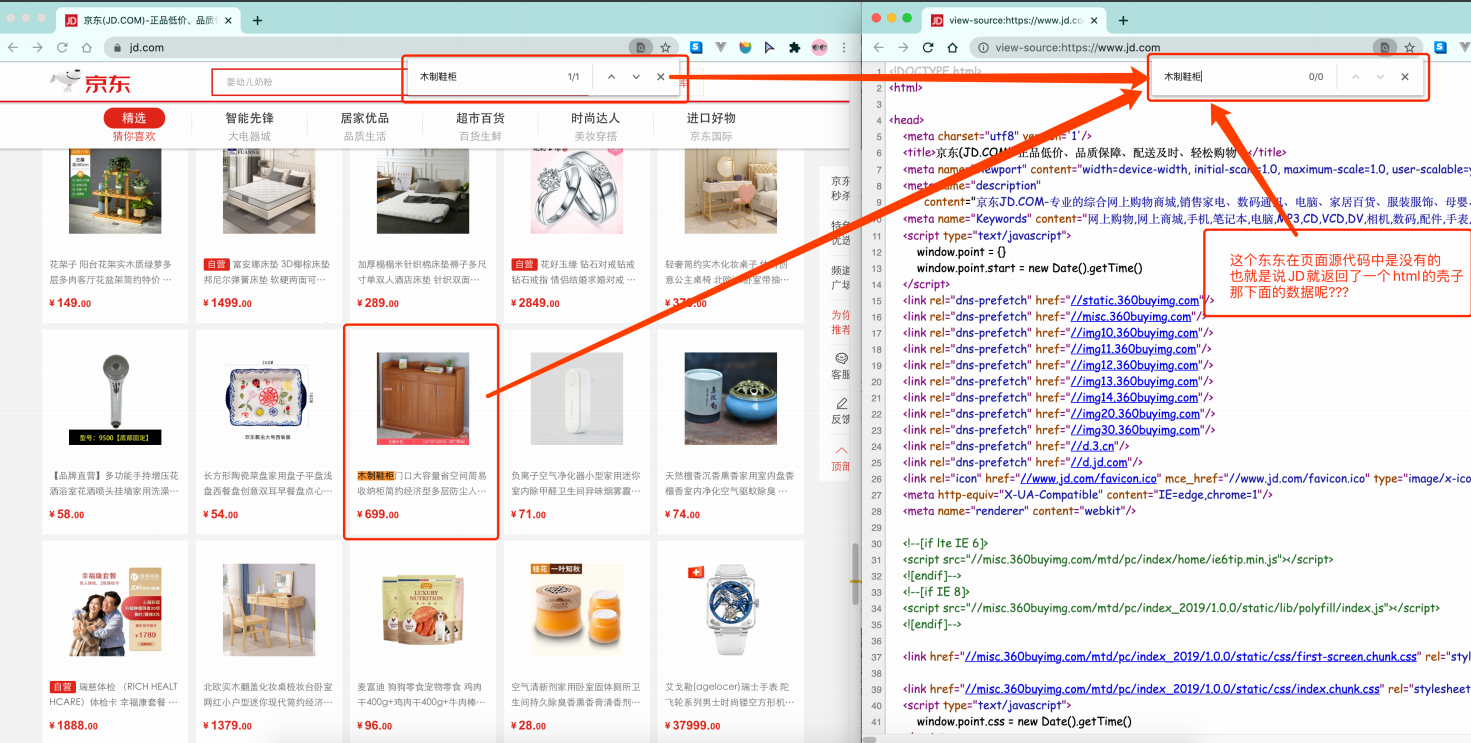
注意,从百度上爬取到的是页面的源代码,而不是可视化的页面 (四)web请求全过程剖析浏览器在输入完网址,到我们看到网页的整体内容,这个过程发生了什么? 以百度为例,在访问百度时,浏览器会把这一次请求发送到百度的服务器,由服务器接收到这个请求,然后加载一些数据,返回给浏览器,再由浏览器进行显示 注意,百度的服务器返回给浏览器的不直接是页面,而是页面源代码(由html、css、js组成),由浏览器把页面源代码进行执行,然后把执行之后的结果展示给用户
所有的数据都在页面源代码里吗? 非也 页面渲染数据的过程,有两种: 第一种: 服务器渲染:我们在请求到服务器的时候,服务器那边直接把数据和html整合在一起,统一返回给浏览器,即浏览器能直接拿到带有数据的html内容。特点是在页面源代码中能看到数据。如:  由于数据是直接写在 html 中的,所以我们能看到的数据都在页面源代码中能找到
由于数据是直接写在 html 中的,所以我们能看到的数据都在页面源代码中能找到
这种网页一般都相对比较容易就能抓取到页面内容 第二种: 客户端(即浏览器)渲染 / 前端JS渲染:第一次请求服务器返回一堆html框架结构,然后再次请求到真正保存数据的服务器,由这个服务器返回数据,最后在浏览器上对数据进行加载
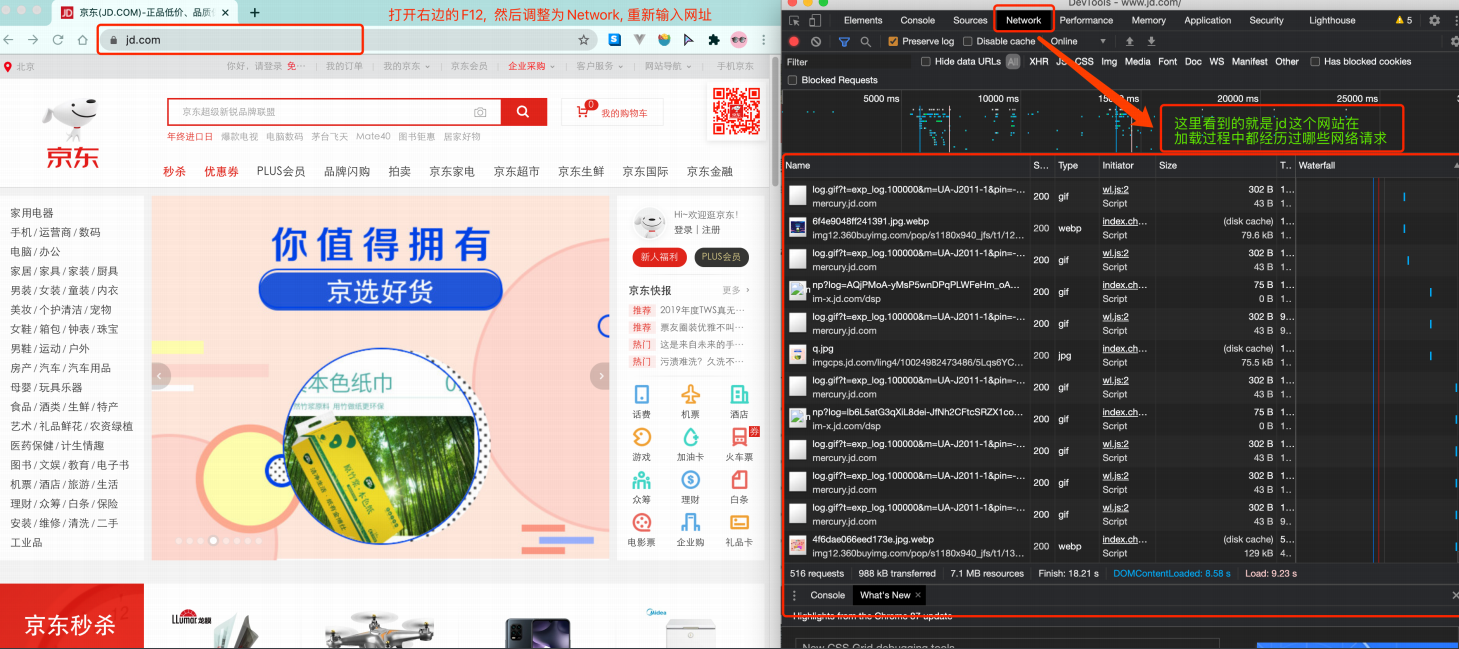
特点是在页面源代码中看不到数据。如: 请求豆瓣排行榜网页(豆瓣电影分类排行榜 - 剧情片)给你一个html骨架再发送一次请求,要数据将数据返回给浏览器在客户端将数据跟html拼接这样做的好处是服务器那边能缓解压力,且分工明确,容易维护。例子:
那数据是何时加载进来的呢?其实在我们进行页面向下滚动的时候,京东就在偷偷地加载数据了,此时想要看到这个页面的加载全过程,就需要借助浏览器的调试工具(F12)
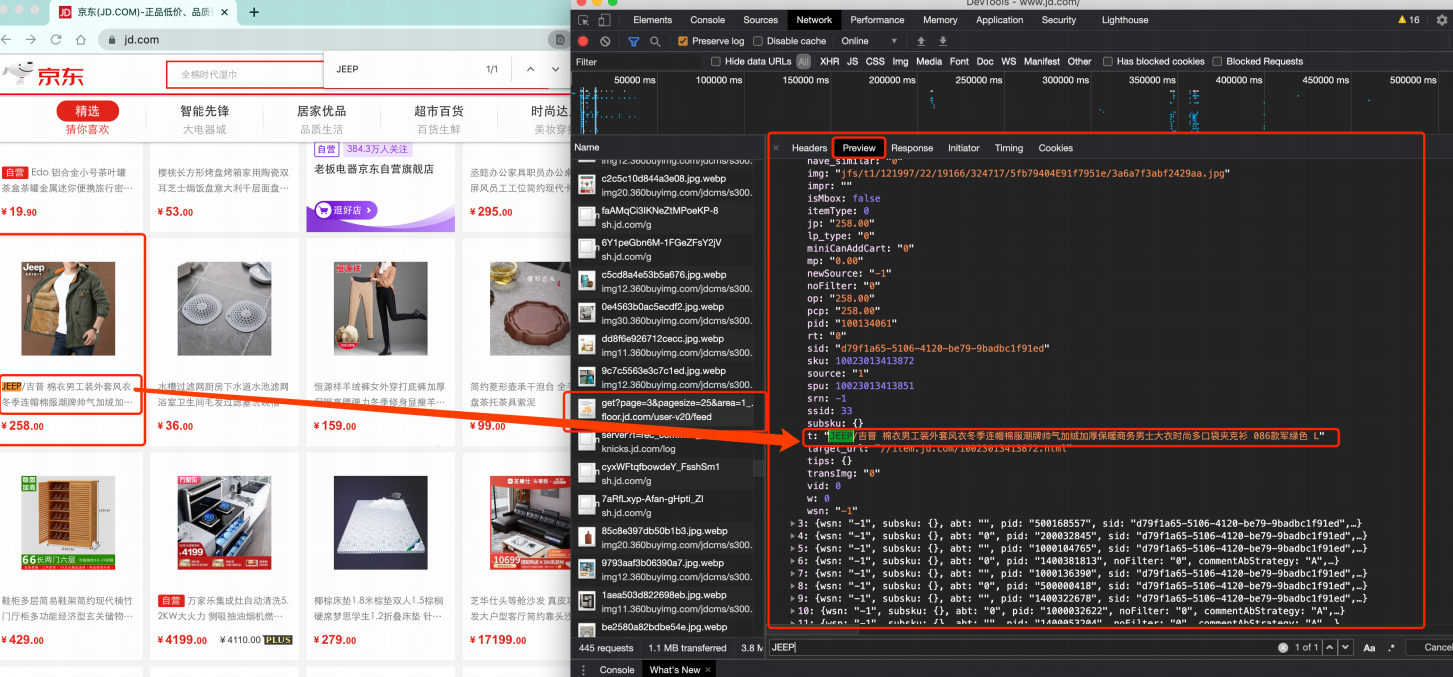 页面上看到的内容其实是后加载进来的
页面上看到的内容其实是后加载进来的
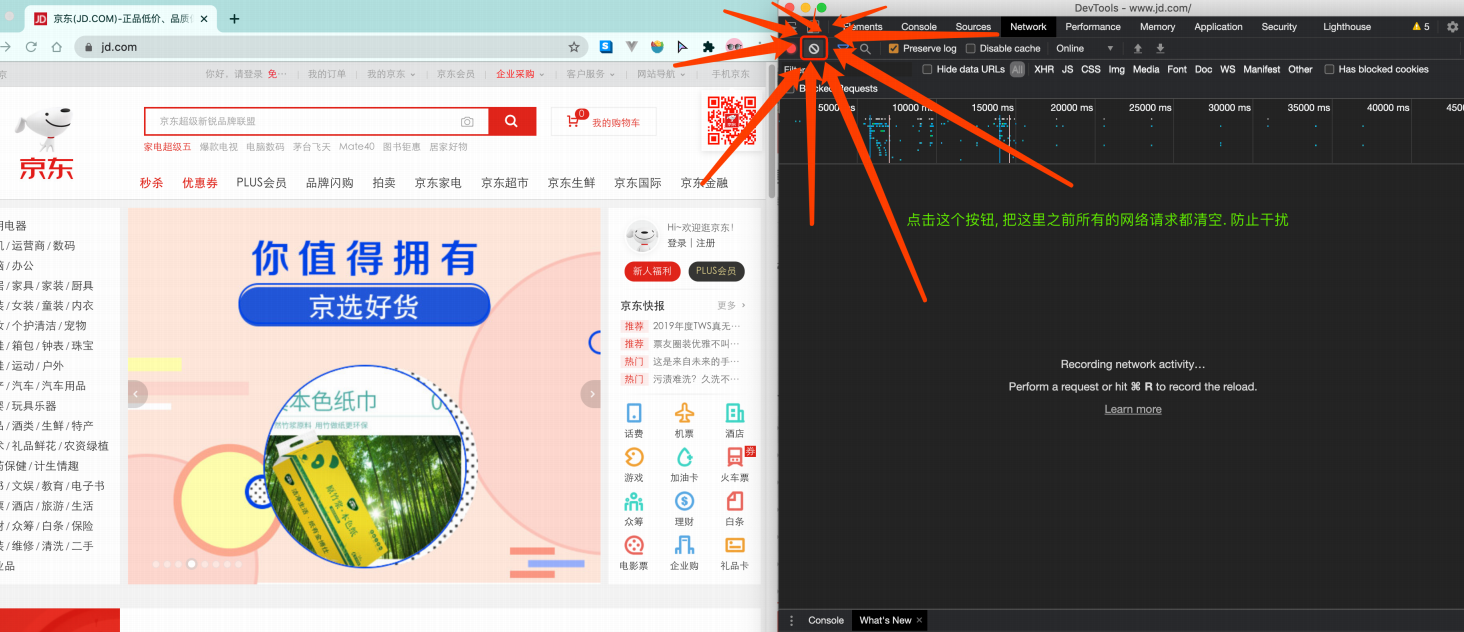
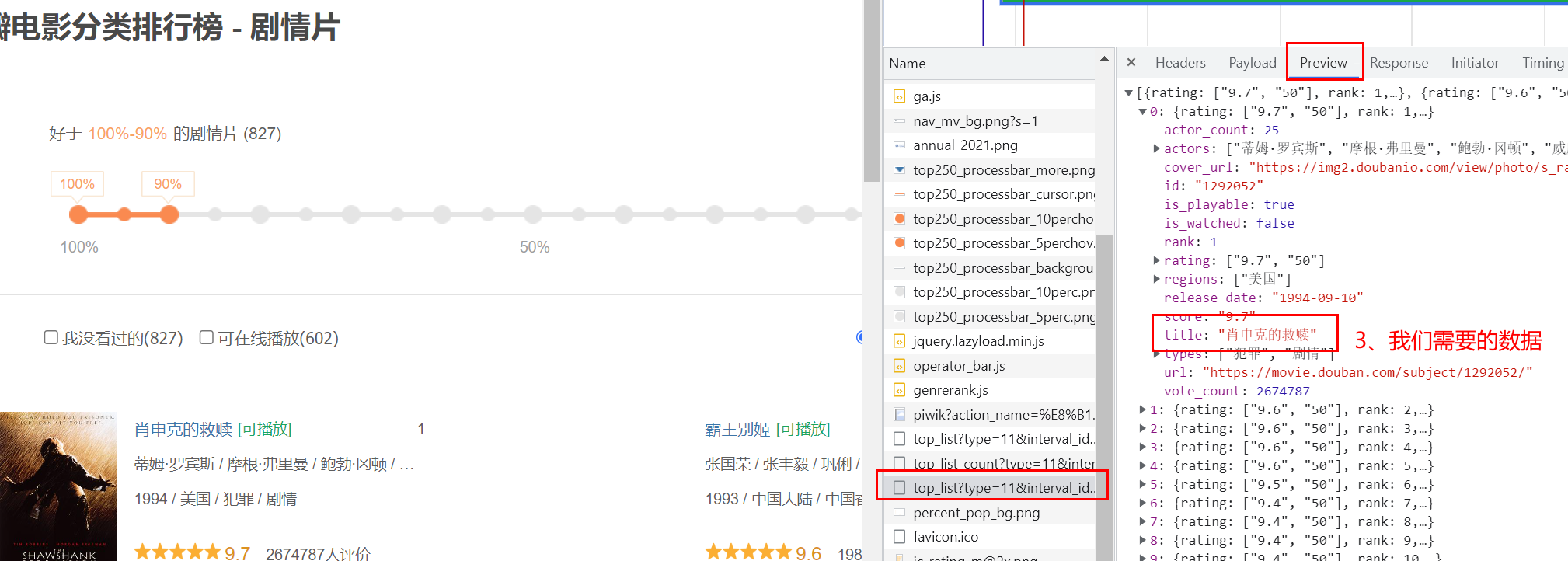
总结: 有些时候我们的数据不一定都是直接来自于页面源代码,如果你在页面源代码中找不到你要的数据时,那很可能数据是存放在另一个请求里 熟练使用浏览器抓包工具 右键检查或直接f12,再对着网址栏敲一下回车,观察Network(网络工作状态,即进入网址之后发生的所有网络请求)  只拿到html的骨架(点Preview观察)
只拿到html的骨架(点Preview观察)
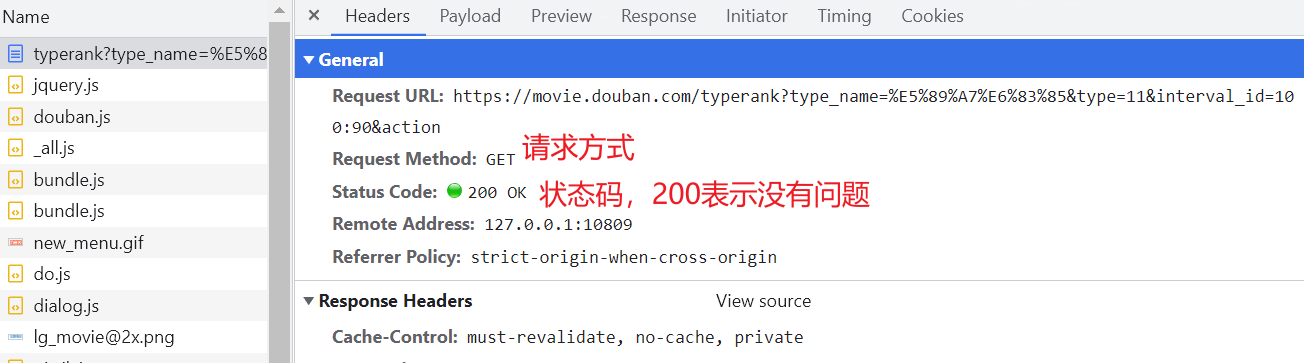
如果只要数据的话,只要第二次请求的url即可,为规则的json数据 (五)HTTP协议协议:就是两个计算机之间为了能够流畅的进行沟通而设置的一个君子协定。常见的协议有 TCP/IP协议、SOAP协议、HTTP协议、SMTP协议等等 访问网站时,在url地址前会有http或https,含义为:当前的url地址在数据传输时遵循HTTP协议 HTTP协议:Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议。即:浏览器和服务器之间的数据交互遵守HTTP协议 HTTP协议传输的即是页面源代码 html:超文本标记语言 HTTP协议把一条消息分为三大块内容,无论是请求还是响应都是三块内容: 请求:
响应:
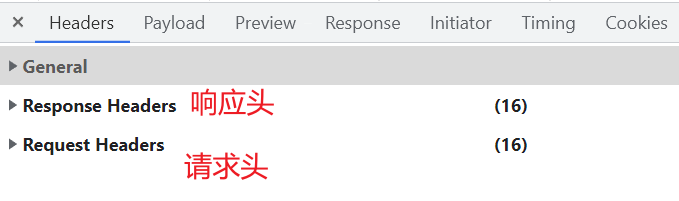
在写爬虫的时候要格外注意请求头和响应头,这两个地方一般都隐含着一些比较重要的内容
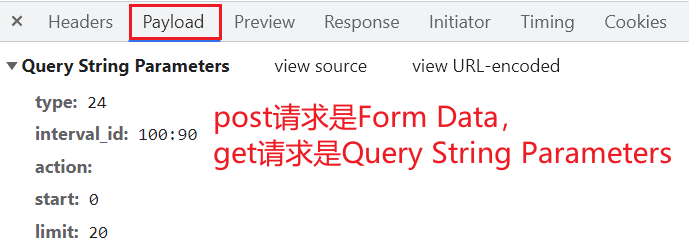
请求头(服务器需要)中一些重要内容(爬虫需要): User-Agent:当前的这次请求用的是哪个浏览器发送的请求,即请求载体的身份标识Referer:防盗链(这次请求是从哪个页面来的),反爬会用到cookie:在登录之后对当前用户登录状态的记录,会发送给服务器。即本地字符串数据信息(用户登录信息,反爬的token)响应头(浏览器需要)中一些重要内容: cookie:本地字符串数据信息(用户登录信息,反爬的token)奇怪的字符串:一般都是token字样,用来做反爬或加密的请求方式(抓包工具里会告知): GET:显式提交。一般用在查询东西时POST:隐式提交。yiban增加/修改/上传数据时 (六)requests模块入门在前面小节中,我们使用 urllib 来抓取页面源代码,这个是python内置的一个模块,但是它并不是我们常用的爬虫工具。常用的抓取页面模块为一个第三方模块 requests ,这个模块的优势就是比 urllib 简单,并且处理各种请求都比较方便 requests模块可以简化我们获取页面源代码的过程(把urllib变得更加简化),为第三方库,需要安装 安装 # 安装requests # 在 PyCharm 里的 Terminal 里输入 # pip install requests # 国内镜像源 # pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests 案例一:get请求(headers参数)在“搜狗搜索”里输入周杰伦,返回页面:周杰伦 - 搜狗搜索 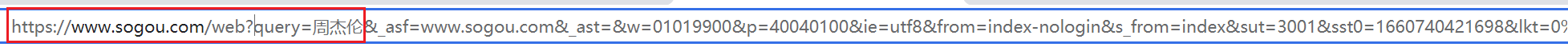 后面可以删除
后面可以删除
所有在浏览器地址栏里输入的url,统一都是使用get方式提交 # 抓取搜狗搜索内容 import requests url = 'https://www.sogou.com/web?query=周杰伦' resp = requests.get(url) # 发送get请求 print(resp) # ,表明本次请求没有问题 print(resp.text) # 拿到页面源代码 resp.close() # 关掉resp 服务器认为我们本次的请求是通过自动化程序发出的,故被拦截
服务器认为我们本次的请求是通过自动化程序发出的,故被拦截
运行代码,发现报错,故对上述代码做一些调整。 在请求头(Request Headers)里有User-Agent,描述当前的请求是通过哪个设备发出的 # 抓取搜狗搜索内容 import requests url = 'https://www.sogou.com/web?query=周杰伦' headers = { # 字典 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36" } resp = requests.get(url,headers=headers) # 处理一个小小的反爬 print(resp) print(resp.text) # 拿到页面源代码 resp.close() # 关掉resp 成功爬取出页面内容
成功爬取出页面内容
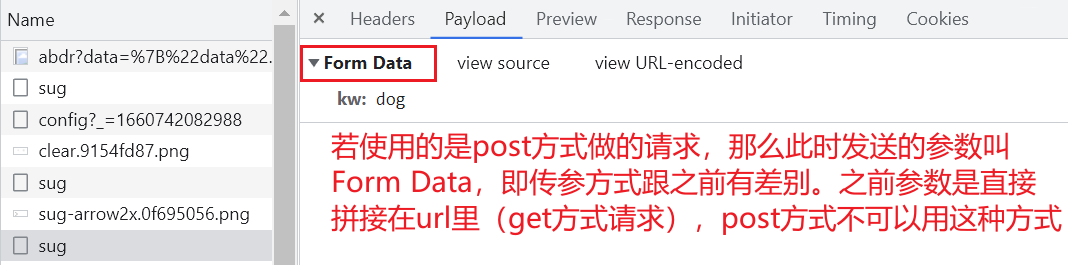
更进一步,让用户自己输入搜索内容: # 抓取搜狗搜索内容 import requests query = input("输入一个你喜欢的明星") url = f'https://www.sogou.com/web?query={query}' # 把某个变量塞到一个字符串里,前面要加上f dic = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36" } resp = requests.get(url, headers=dic) # 处理一个小小的反爬 print(resp) print(resp.text) # 拿到页面源代码 with open("sogou.html", mode="w", encoding="utf-8") as f: f.write(resp.text) resp.close() # 关掉resp 案例二:post请求(带参数用data)进入百度翻译(fanyi.baidu.com),打开f12抓包工具,用英文输入法搜索dog 注意百度翻译这个url不好弄出来,记住在输入的时候,关掉各种输入法,要用英文输入法,不要回车,才能看到 sug
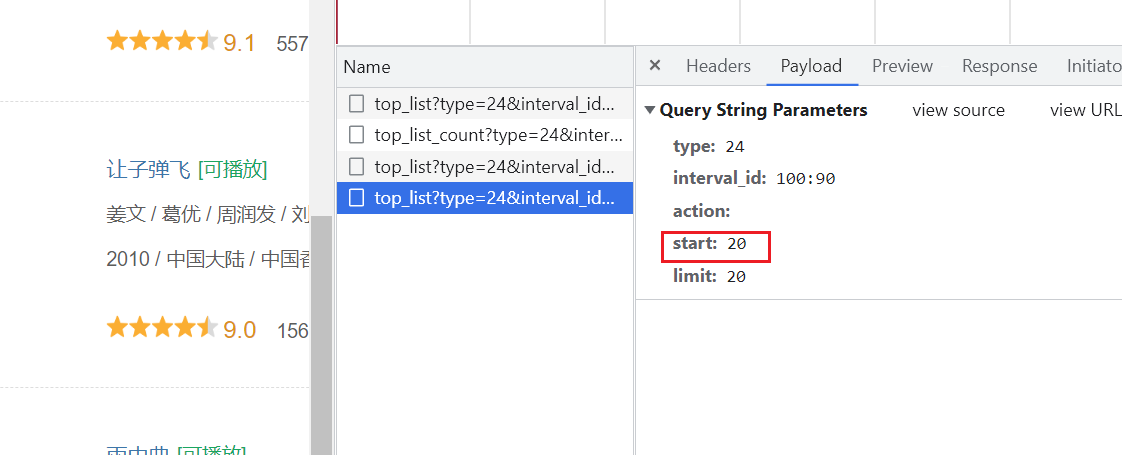
有一些网站在进行请求的时候会校验你的客户端设备型号,比如抓取豆瓣电影 douban.com ——> 电影 ——> 排行榜 ——> 分类排行榜(喜剧)(豆瓣电影分类排行榜 - 喜剧片)  XHR:第二次请求
XHR:第二次请求
向下滑动页面,发现Network里也在更新,start从0变为20
可以改变 start 或 limit 值再重新跑一下代码试试 (补充)字符集问题 # open()函数 def open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True): # file:文件路径 # mode:读/写 # encoding:python内存层面用的是Unicode,不能存储或传输,必须变为utf-8或gbk等 encoding is the name of the encoding used to decode or encode the file. This should only be used in text mode. The default encoding is platform dependent(由电脑的操作系统默认,Windows默认gbk,mac默认utf-8) 第一章总结 爬虫就是写程序去模拟浏览器,用来抓取互联网上的内容python中自带了一个 urllib 提供给我们进行简易爬虫的编写requests 模块的简单使用,包括 get、post 两种方式的请求,以及 User-Agent 的介绍 |










【本文地址】