使用pytorch通过OpenNMT |
您所在的位置:网站首页 › pytorch开源吗 › 使用pytorch通过OpenNMT |
使用pytorch通过OpenNMT
|
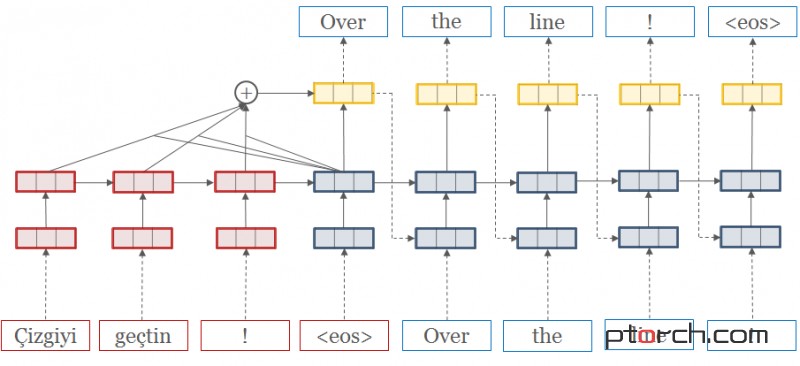
OpenNMT是一个开放源代码(MIT)神经机器翻译系统,OpenNMT的Pytorch 端口。本系统的设计基于简洁的使用性以及便捷的扩展性,同时保持高效性和最先进的翻译准确度。功能包括:高性能GPU训练的速度和内存优化。界面简单而且通用,方便部署。 扩展性强以允许其他序列生成任务,如生成汇总和图像字幕。完整的文档可以在这里。
这个代码还在很大的发展(pre-version 0.1)。我们建议分叉,如果你想要一个稳定的版本。 目录 要求 特征 快速开始 高级 要求 pip install -r requirements.txt 特征实现以下OpenNMT功能: 多层双向RNN具有注意力和缺点 数据预处理 从检查站保存和加载 推荐(翻译)与批量和波束搜索 多GPU测试版功能: 上下文门 多源和目标RNN(lstm / gru)类型和注意(dotprod / mlp)类型 图像到文本处理 源词功能 “注意就是你需要的” TensorBoard /蜡笔记录 复制,覆盖和结构化注意 快速开始 步骤1:预处理数据 python preprocess.py -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/demo我们将使用data/文件夹中的一些示例数据。 数据由并行源(src)和target(tgt)数据组成,每行包含一个句子,由空格分隔: src-train.txt tgt-train.txt src-val.txt tgt-val.txt需要验证文件,并用于评估培训的收敛性。通常不超过5000句。 运行预处理后,将生成以下文件: demo.src.dict:源索引词典到索引映射。 demo.tgt.dict:目标词汇词典到索引映射。 demo.train.pt:包含词汇,训练和验证数据的序列化PyTorch文件在内部,系统不会触及自己的单词,而是使用这些指标。 步骤2:训练模型 python train.py -data data / demo -save_model demo-model主要列车指挥很简单。最少需要一个数据文件和一个保存文件。这将运行默认模型,它由encoder/decoder上的500个隐藏单元的2层LSTM组成。您还可以添加-gpuid 1使用(说)GPU 1。 第3步:翻译 python translate.py -model demo-model_epochX_PPL.pt -src data / src-test.txt -output pred.txt -replace_unk -verbose现在你有一个模型可以用来预测新的数据。我们通过Beam搜素算法来实现。这将输出预测pred.txt。 注意预测将是非常可怕的,因为演示数据集很小。尝试运行一些较大的数据集!例如,您可以下载数百万个并行句子进行翻译或汇总。 一些有用的工具: 全翻译例子下面的示例使用Moses tokenizer(http://www.statmt.org/moses/)来准备数据和MOSE BLEU脚本进行评估。 wget https://raw.githubusercontent.com/moses-smt/mosesdecoder/master/scripts/tokenizer/tokenizer.perl wget https://raw.githubusercontent.com/moses-smt/mosesdecoder/master/scripts/share/nonbreaking_prefixes/nonbreaking_prefix.de wget https://raw.githubusercontent.com/moses-smt/mosesdecoder/master/scripts/share/nonbreaking_prefixes/nonbreaking_prefix.en sed -i "s/$RealBin\/..\/share\/nonbreaking_prefixes//" tokenizer.perl wget https://raw.githubusercontent.com/moses-smt/mosesdecoder/master/scripts/generic/multi-bleu.perl WMT'16多模式翻译:Multi30k(de-en)WMT'16多模式翻译任务的培训例子(http://www.statmt.org/wmt16/multimodal-task.html)。 1、下载数据。 # Delete the last line of val and training files. for l in en de; do for f in data/multi30k/*.$l; do if [[ "$f" != *"test"* ]]; then sed -i "$ d" $f; fi; done; done for l in en de; do for f in data/multi30k/*.$l; do perl tokenizer.perl -a -no-escape -l $l -q < $f > $f.atok; done; done python preprocess.py -train_src data/multi30k/train.en.atok -train_tgt data/multi30k/train.de.atok -valid_src data/multi30k/val.en.atok -valid_tgt data/multi30k/val.de.atok -save_data data/multi30k.atok.low -lower 2、预处理数据。 # Delete the last line of val and training files. for l in en de; do for f in data/multi30k/*.$l; do if [[ "$f" != *"test"* ]]; then sed -i "$ d" $f; fi; done; done for l in en de; do for f in data/multi30k/*.$l; do perl tokenizer.perl -a -no-escape -l $l -q < $f > $f.atok; done; done python preprocess.py -train_src data/multi30k/train.en.atok -train_tgt data/multi30k/train.de.atok -valid_src data/multi30k/val.en.atok -valid_tgt data/multi30k/val.de.atok -save_data data/multi30k.atok.low -lower 3、训练模型。 python train.py -data data/multi30k.atok.low.train.pt -save_model multi30k_model -gpuid 0 4、翻译句子。 python translate.py -gpu 0 -model multi30k_model_e13_*.pt -src data/multi30k/test.en.atok -tgt data/multi30k/test.de.atok -replace_unk -verbose -output multi30k.test.pred.atok 5、评估。 perl tools/multi-bleu.perl data/multi30k/test.de.atok < multi30k.test.pred.atok 预训模型可以下载和使用以下预培训的模型,使用translate.py(这些模型已经使用较旧版本的代码进行了培训;他们将很快更新)。 onmt_model_en_de_200k:基于OpenNMT / IntegrationTesting的200k句子数据集的英 - 德翻译模型。Perplexity:20。 onmt_model_en_fr_b1M(即将推出):一个英-法模式训练模型, benchmark-1M. Perplexity: 4.85.。OpenNMT是一个开放源代码(MIT)神经机器翻译系统,OpenNMT的Pytorch 端口。本系统的设计基于简洁的使用性以及便捷的扩展性,同时保持高效性和最先进的翻译准确度。功能包括:高性能GPU训练的速度和内存优化。界面简单而且通用,方便部署。 扩展性强以允许其他序列生成任务,如生成汇总和图像字幕。完整的文档可以在这里。这个代码还在很大的发展(pre-version 0.1)。我们建议分叉,如果你想要一个稳定的版本。 目录 要求 特征 快速开始 高级 要求 pip install -r requirements.txt 特征实现以下OpenNMT功能: 多层双向RNN具有注意力和缺点 数据预处理 从检查站保存和加载 推荐(翻译)与批量和波束搜索 多GPU测试版功能: 上下文门 多源和目标RNN(lstm / gru)类型和注意(dotprod / mlp)类型 图像到文本处理 源词功能 “注意就是你需要的” TensorBoard /蜡笔记录 复制,覆盖和结构化注意 快速开始 步骤1:预处理数据 python preprocess.py -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/demo我们将使用data/文件夹中的一些示例数据。 数据由并行源(src)和target(tgt)数据组成,每行包含一个句子,由空格分隔: src-train.txt tgt-train.txt src-val.txt tgt-val.txt需要验证文件,并用于评估培训的收敛性。通常不超过5000句。 运行预处理后,将生成以下文件: demo.src.dict:源索引词典到索引映射。 demo.tgt.dict:目标词汇词典到索引映射。 demo.train.pt:包含词汇,训练和验证数据的序列化PyTorch文件在内部,系统不会触及自己的单词,而是使用这些指标。 步骤2:训练模型 python train.py -data data / demo -save_model demo-model主要列车指挥很简单。最少需要一个数据文件和一个保存文件。这将运行默认模型,它由encoder/decoder上的500个隐藏单元的2层LSTM组成。您还可以添加-gpuid 1使用(说)GPU 1。 第3步:翻译 python translate.py -model demo-model_epochX_PPL.pt -src data / src-test.txt -output pred.txt -replace_unk -verbose现在你有一个模型可以用来预测新的数据。我们通过Beam搜素算法来实现。这将输出预测pred.txt。 注意预测将是非常可怕的,因为演示数据集很小。尝试运行一些较大的数据集!例如,您可以下载数百万个并行句子进行翻译或汇总。 一些有用的工具: 全翻译例子下面的示例使用Moses tokenizer(http://www.statmt.org/moses/)来准备数据和MOSE BLEU脚本进行评估。 wget https://raw.githubusercontent.com/moses-smt/mosesdecoder/master/scripts/tokenizer/tokenizer.perl wget https://raw.githubusercontent.com/moses-smt/mosesdecoder/master/scripts/share/nonbreaking_prefixes/nonbreaking_prefix.de wget https://raw.githubusercontent.com/moses-smt/mosesdecoder/master/scripts/share/nonbreaking_prefixes/nonbreaking_prefix.en sed -i "s/$RealBin\/..\/share\/nonbreaking_prefixes//" tokenizer.perl wget https://raw.githubusercontent.com/moses-smt/mosesdecoder/master/scripts/generic/multi-bleu.perl WMT'16多模式翻译:Multi30k(de-en)WMT'16多模式翻译任务的培训例子(http://www.statmt.org/wmt16/multimodal-task.html)。 1、下载数据。 # Delete the last line of val and training files. for l in en de; do for f in data/multi30k/*.$l; do if [[ "$f" != *"test"* ]]; then sed -i "$ d" $f; fi; done; done for l in en de; do for f in data/multi30k/*.$l; do perl tokenizer.perl -a -no-escape -l $l -q < $f > $f.atok; done; done python preprocess.py -train_src data/multi30k/train.en.atok -train_tgt data/multi30k/train.de.atok -valid_src data/multi30k/val.en.atok -valid_tgt data/multi30k/val.de.atok -save_data data/multi30k.atok.low -lower 2、预处理数据。 # Delete the last line of val and training files. for l in en de; do for f in data/multi30k/*.$l; do if [[ "$f" != *"test"* ]]; then sed -i "$ d" $f; fi; done; done for l in en de; do for f in data/multi30k/*.$l; do perl tokenizer.perl -a -no-escape -l $l -q < $f > $f.atok; done; done python preprocess.py -train_src data/multi30k/train.en.atok -train_tgt data/multi30k/train.de.atok -valid_src data/multi30k/val.en.atok -valid_tgt data/multi30k/val.de.atok -save_data data/multi30k.atok.low -lower 3、训练模型。 python train.py -data data/multi30k.atok.low.train.pt -save_model multi30k_model -gpuid 0 4、翻译句子。 python translate.py -gpu 0 -model multi30k_model_e13_*.pt -src data/multi30k/test.en.atok -tgt data/multi30k/test.de.atok -replace_unk -verbose -output multi30k.test.pred.atok 5、评估。 perl tools/multi-bleu.perl data/multi30k/test.de.atok < multi30k.test.pred.atok 预训模型可以下载和使用以下预培训的模型,使用translate.py(这些模型已经使用较旧版本的代码进行了培训;他们将很快更新)。 onmt_model_en_de_200k:基于OpenNMT / IntegrationTesting的200k句子数据集的英 - 德翻译模型。Perplexity:20。 onmt_model_en_fr_b1M(即将推出):一个英-法模式训练模型, benchmark-1M. Perplexity: 4.85.。 原创文章,转载请注明 :使用pytorch通过OpenNMT-py实现开源神经机器翻译 - pytorch中文网 原文出处: https://ptorch.com/news/56.html 问题交流群 :168117787 |
【本文地址】
今日新闻 |
推荐新闻 |