Python逻辑回归 |
您所在的位置:网站首页 › python逻辑回归模型简单案例解析 › Python逻辑回归 |
Python逻辑回归
|
一、引言
保费定价也成为费率厘定,是保险公司运营的环节之一。其过程是根据保单(被保险人)的损失经验和其他相关信息建立模型,并且对未来的保险成本(赔款、代理人佣金、一般管理费用、理赔费用以及支持该业务所需的资本金成本)进行预测的过程。保险公司实际使用的费率还会受到市场供求关系和公司自身发展战略的影响。 汽车保险也称机动车辆保险,失意机动车辆本身及其第三者责任等为保险标的的一种运输工具险,在非寿险井算领域中占有重要地位。车险风险的度量有三个维度:索赔概率(索赔发生的可能性)、索赔频率(给定时间区间内各风险单位发生索赔的次数)和索赔强度(平均每次索赔的额度)。车险的纯保费计算公式由索赔频率和索赔强度的期望构成。 二、模型推导对于车险索赔风险,响应变量Y只有两种可能的取值,即 Y=1(发生索赔) Y=0(未发生索赔) 记被保险人的特征向量为X,考虑X和Y之间的关系。 线性回归模型是最简单的建模方法,其优点在于计算方便(OLS估计),且容易得到边际效应(回归系数)。为使Y的预测值为0或1,在给定X的情况下,考虑Y的两点分布概率: P(Y=1|X)=F( 其中F(X,beta)是连接特征向量和响应变量的连接函数。 连接函数的选取可以导出不同的模型,本例以逻辑分布的分布函数为例,即 给定相互独立的样本,则可以使用“最大似然估计”(MLE)对参数进行统计推断,即 对于使用MLE进行估计的非线性模型,可使用准R^2或伪R^2度量模型的拟合优度,其定义为:。还尝试用偏离度(或“残差偏离度”)的概念,其定义为: 得到Logit模型的估计系数后,即可预测测试集中Y的条件概率: 逻辑回归模型的评估:常用准确率(accuracy)或错误率(error rate):
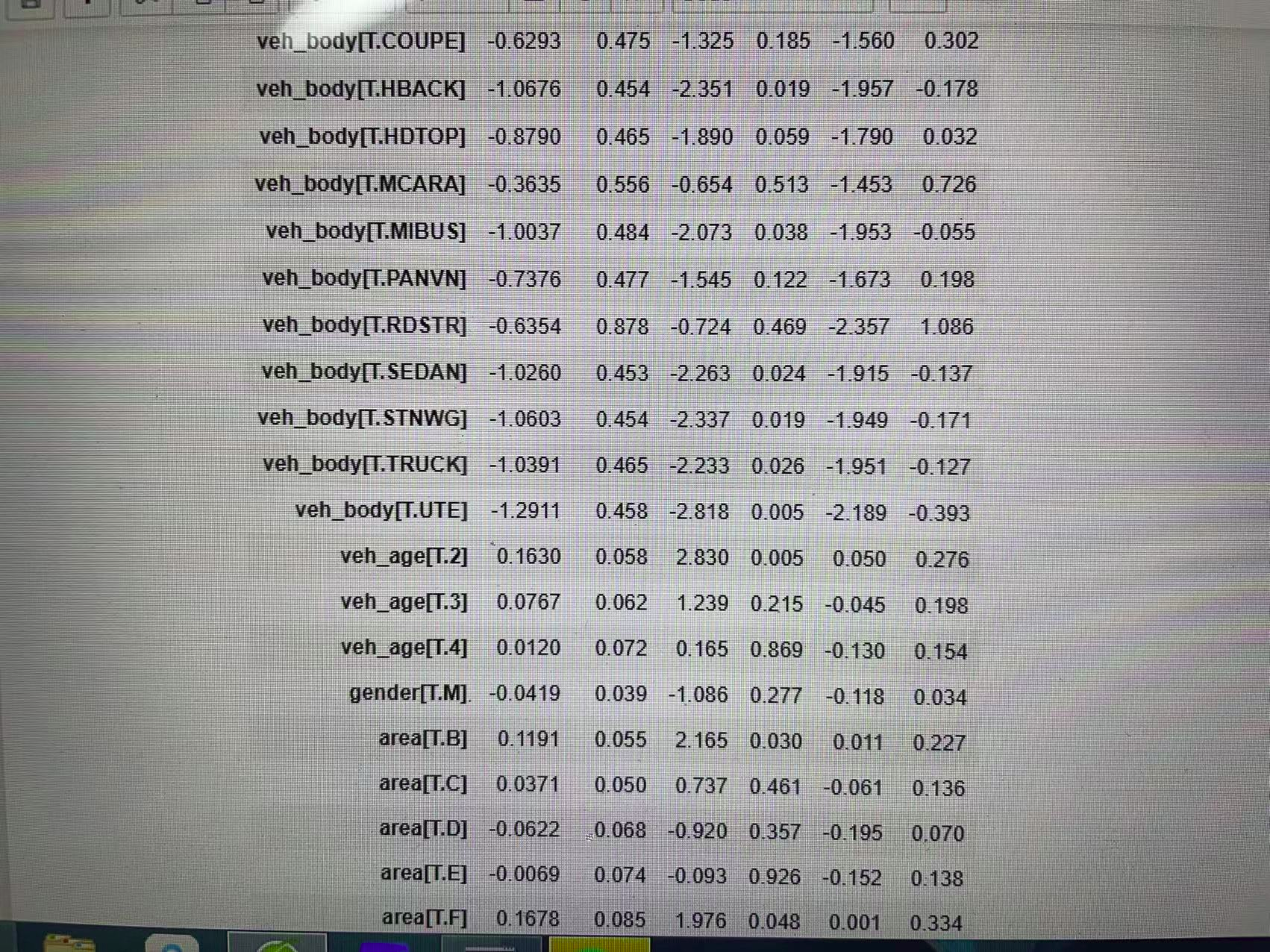
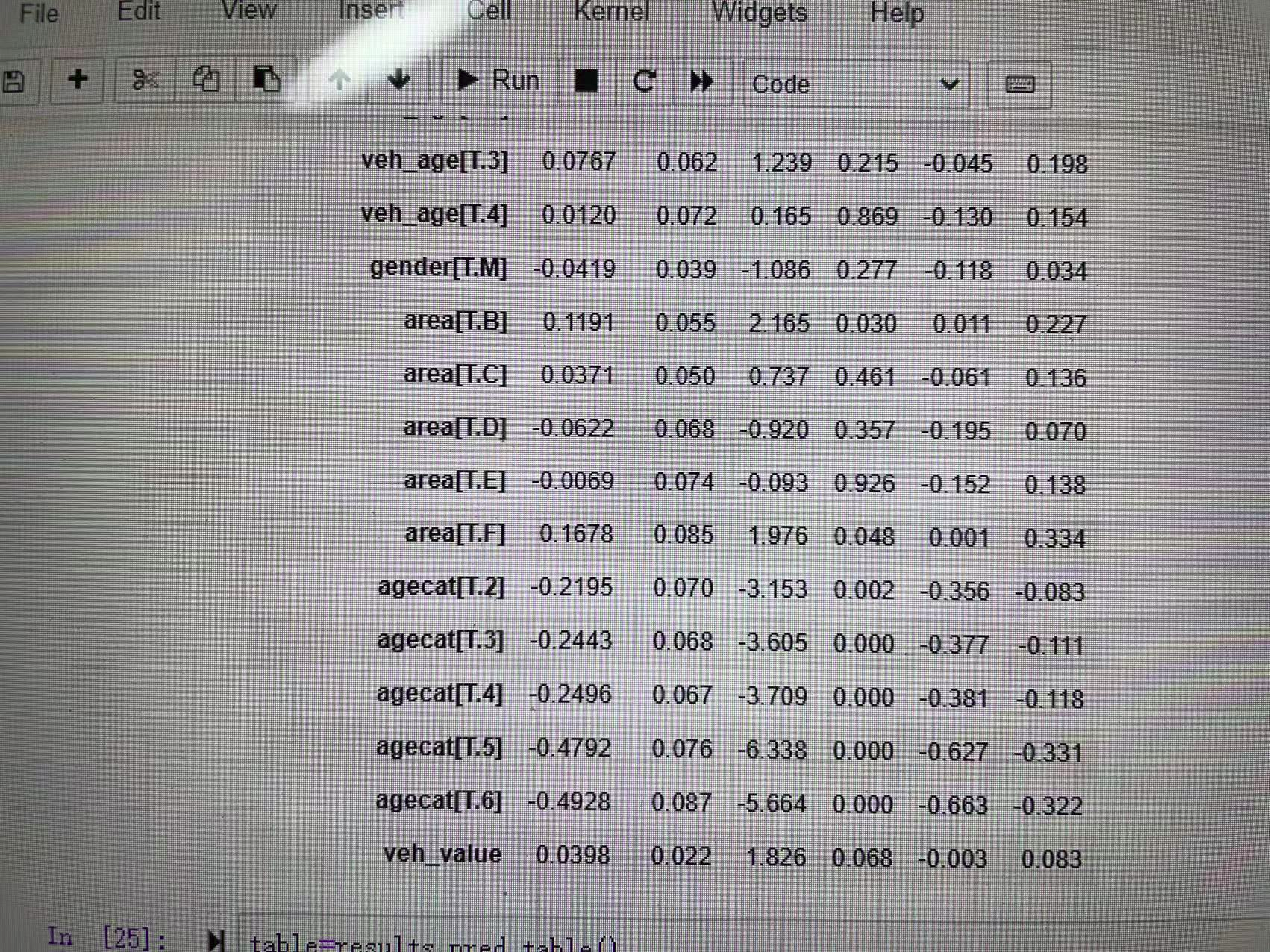
注意准确率或错分率并不适用于“类别不平衡”的数据。除此之外还可计算出混淆矩阵,根据混淆矩阵的信息,可设计更精细的模型评估指标。 三、代码实现 #####数据和库读入################ import pandas as pd import numpy as np from sklearn.model_selection import train_test_split import statsmodels.api as sm from patsy import dmatrices import matplotlib.pyplot as plt from sklearn.linear_model import LogisticRegression as LR from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report from sklearn.metrics import cohen_kappa_score from sklearn.metrics import plot_roc_curve ###patsy是一个用于描述统计模型(尤其是线性模型或具有线性组件的模型)和建构设计矩阵的库 ###kappa系数用于一致性检验,也可以用于衡量分类精度,代表分类与完全随机的分类产生错误减少的比例 cardata=pd.read_csv('car.csv') cardata.shape pd.options.display.max_columns=10 #####设置展示数据的最大列数位50 cardata.head() ######数据信息################### cardata.info() cardata.describe() pd.crosstab(cardata.gender,cardata.clm) pd.crosstab(cardata.gender,cardata.clm,normalize='index') pd.crosstab(cardata.agecat,cardata.clm,normalize='index') ####pd.crossbat()是Pandas中的交叉表和透视功能。交叉表试用于计算一列数据对于另一个数据的分组个数 ###########训练集和测试集############### cardata['clm']=cardata['clm'].map(str) cardata['veh_age']=cardata['veh_age'].map(str) cardata['agecat']=cardata['agecat'].map(str) ##map(函数名,可迭代序列)函数根据提供的函数对指定的序列作映射返回集合,且不改变原list output: RangeIndex: 67856 entries, 0 to 67855 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 veh_value 67856 non-null float64 1 exposure 67856 non-null float64 2 clm 67856 non-null int64 3 numclaims 67856 non-null int64 4 claimcst0 67856 non-null float64 5 veh_body 67856 non-null object 6 veh_age 67856 non-null int64 7 gender 67856 non-null object 8 area 67856 non-null object 9 agecat 67856 non-null int64 dtypes: float64(3), int64(4), object(3) memory usage: 5.2+ MB #####训练集和测试集################ traindata,testdata=train_test_split(cardata,test_size=0.3,stratify=cardata.clm, random_state=0) ######哑变量处理################ y_train,x_train=dmatrices('clm~veh_value+veh_body+veh_age+gender+area+agecat', data=traindata,return_type='dataframe') ###dmatrices接受公式字符串和数据集,为线性模型创建设计矩阵 pd.options.display.max_columns=30 x_train.head() y_train.head() y_train=y_train.iloc[:,1] y_train.head() y_test,x_test=dmatrices('clm~veh_value+veh_body+veh_age+gender+agecat', data=testdata,return_type='dataframe') y_test=y_test.iloc[:,1] model=sm.Logit(y_train,X_train) results=model.fit() results.params np.exp(results.params) results.summary() ##哑变量指的是数据中的文本数据,哑变量处理就是将文本数据转换为线性不相关矩阵的过程 #训练集上训练指标######################## table=results.pred_table() table#####训练集上混淆矩阵 Accuracy=(table[0,0]+table[1,1])/np.sum(table) Accuracy Error_rate=1-Accuracy Error_rate Sensitivity=table[1,1]/(table[1,0]+table[1,1]) Sensitivity Specificity=table[0,0]/(table[0,0]+table[0,1]) Specificity Recall=table[1,1]/(table[0,1]+table[1,1]) Recall output: [[44262. 0.] [ 3237. 0.]] 0.9318511968673024 0.06814880313269756 0.0 1.0 nan ############测试集误差#################### prob=results.predict(x_test) pred=(prob=0.1) table=pd.crosstab(y_test,pred,colnames=['Predicted']) table table=np.array(table)##########数据类型转换 Accuracy=(table[0,0]+table[1,1])/np.sum(table) Accuracy Error_rate=1-Accuraacy Error_rate Sensitivity=table[1,1]/(table[1,0]+table[1,1]) Sensitivity Specificity=table[0,0]/(table[0,0]+table[0,1]) Specificity Recall=table[1,1]/(table[0,1]+table[1,1]) Recall ########### model=LR(C=1e10,class_weight='balanced',random_state=0) #model=LR(C=1e10,class_weight={0:0.1,1:0.1},random_state=0) model.fit(x_train,y_train) model.coef_ results.params model.score(x_test,y_test) prob=model.predict_proba(x_test) prob[:,5] pred=model.predict(x_test) #pred=(pro[:,1]>=0.3) pred[:,5] confusion_matrix(y_test,pred) ##混淆矩阵又称为误差矩阵,用于衡量分类算法的准确程度
本文为个人学习总结,方方面面多有不妥还望批评指正 |
【本文地址】
今日新闻 |
推荐新闻 |