数据分析建模之逻辑回归(Logistic Regression) |
您所在的位置:网站首页 › python逻辑回归模型简单案例分析题 › 数据分析建模之逻辑回归(Logistic Regression) |
数据分析建模之逻辑回归(Logistic Regression)
|
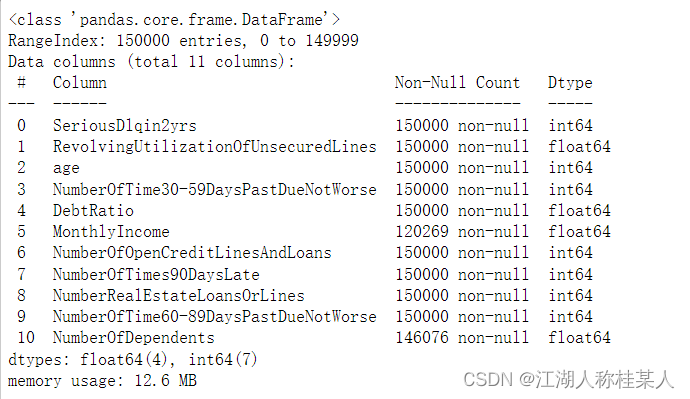
目录 0.引言 一、概念 二、工具 三、建模思路 四、代码 1.数据读取 2.数据集划分 3.特征计算 4.特征分箱 5.转换WOE值 6.特征选择 7.模型训练 8.模型评估 9.模型验证 10.分值转换 0.引言评分卡建模的目的是根据现有的数据对用户的好坏进行预测,比如一个人35岁左右,正值事业上升期,拥有高学历,薪资水平稳定,那么我们根据这些特点就可以断定,这个用户大概率是有还款能力的。反之一个18岁的精神小伙,没有经济能力,那么银行是不会给他进行贷款的。 当然,银行绝不可能根据简单的几个特征去判断用户的好坏,银行实际会根据成百上千个维度去进行判别,此时再使用人工来进行判断,不仅非常困难,还存在一定的主观性,不够准确。 下面我们通过一个案例来搞懂这个问题。 我们的目标是:通过银行给出的用户信息来判断用户的好坏,形成一套评分卡模型。 一、概念在金融风控领域,评分卡模型是非常常见的一种模型,主要分为三类: 1.申请评分卡(Application score card),称为A卡 2.行为评分卡(Behavior score card),称为B卡 3.催收评分卡(Collection score card),称为C卡 今天我们探讨的主要是A卡。 二、工具python作为一种面向对象的语言,拥有庞大的第三方库,上手简单。下面为大家介绍一个评分卡建模的第三方库-toad。 toad由国内一家金融公司进行开发维护,网址如下: Welcome to toad’s documentation! — toad 0.1.1 documentation 使用的数据集依然还是大家耳熟能详的德国信用卡数据,下面是kaggle的网址: https:www.kaggle.com/c/GiveMeSomeCredit/data 为了方便大家下载与学习,这里给大家提供一个经过预处理的数据集。 百度网盘下载: 链接:https://pan.baidu.com/s/1Sam9Utr6u7JR2EyGZeP9gQ?pwd=8ijj 提取码:8ijj 三、建模思路1.首先,拿到一份数据集(这里提供了经过预处理的版本),先要查看数据的分布情况以及数据的类型,对数据有个大概的了解,toad可以直接生成EDA(探索性分析,包括均值、中位数、最大最小值等信息)报告。 2.划分数据集,一个机器学习的模型训练,数据集通常分为三部分,包括训练集、测试集、验证集,可以根据自己的数据情况进行划分。 3.特征值计算。评分卡模型使用的指标包含IV值,GINI值等,这都是对于某个指标预测能力的一个量度,具体概念可以自己进行查阅。 4.特征选择与分箱。根据特征值,筛选一些有用的特征,在机器学习中并不是所有的数据都是可用的,往往几十个维度的数据筛选后只能保留十几个甚至几个特征。 分箱通俗的说,就是把数据进行分组,每一组数据中都包含好坏用户,比如100个数据,分为2组,每组50个,其中一组10个坏用户,40个好用户;另一组8个坏用户,42个好用户。分箱的主要目的是去噪,将连续数据离散化后,特征会更稳定。 5.模型训练与评估。 四、代码 1.数据读取这部分不用多说,就是查看一下数据的基本状况,主要看看是否有空值。 import numpy as np import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split import toad from toad.plot import badrate_plot,proportion_plot,bin_plot from toad.metrics import KS,F1,AUC #1.读入数据 data = pd.read_csv('E://cs-training1.csv') #数据描述 data.info() data.describe() data.head()
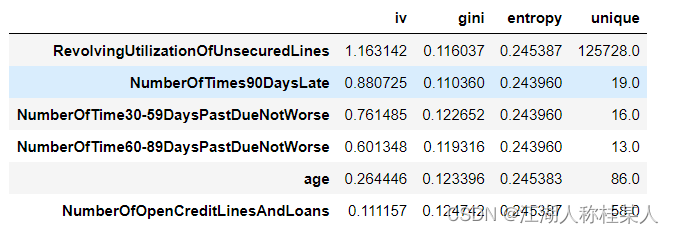
2.1 这部分有一个数据集划分的函数:train_test_split(train_data,train_target,test_size, random_state=0),参数从左到右依次是: 1.传入进行训练的特征数据(也就是除了好坏用户的所有数据,所以是drop('好坏用户'))2.结果数据(也就是好坏用户)3.样本划分比例,这里是3:1(0.75/0.25)4.随机数种子这个函数的返回值是四个:Xtr,Xts,Ytr,Yts,样本训练集(里面就是特征,比如年龄、固定资产等)、样本测试集、结果训练集(里面就是结果,也就是好坏用户)、结果测试集。 #2.样本分区 Xtr,Xts,Ytr,Yts = train_test_split(data.drop('SeriousDlqin2yrs',axis=1), data['SeriousDlqin2yrs'], test_size=0.25, random_state=450) data_tr = pd.concat([Xtr,Ytr],axis=1) data_tr['type'] = 'train' data_ts = pd.concat([Xts,Yts],axis=1) data_ts['type'] = 'test'2.2 下面的pd.concat()用于拼接数据,将训练集与测试集分别拼接在一起,后续继续处理。 下面我们用到了主角toad,进行探索性分析: #3.数据EDA报告 toad.detector.detect(data_tr).to_excel(r'E:/数据EDA结果.xlsx')结果被保存在excel中,这里就不展示了,自己可以动手尝试一下,看看生成的内容是什么。 3.特征计算3.1 这就是toad包强大的地方,只需要传入数据,不需要经过复杂的预处理,就可以得到数据的特征值,得到的特征值都有各自合适的范围,并不是单纯的越大或者越小越好。 #4.数据特征分析计算特征IV、gini、entropy、unique quality = toad.quality(data,'SeriousDlqin2yrs') quality.head(6)
这里说明一下IV值的计算方式,这个是在特征选择中最重要的指标之一。计算IV值之前,还要理解WOE的计算方式,因为IV值的计算是以WOE为基础的。 对于一个分组后的变量,第i组的WOE计算公式如下: 那么对应的第i组的IV值计算公式如下: 再将所有的IV值求和: 3.2 特征预筛选。 selected_train,drop_lst = toad.selection.select(data_tr,target='SeriousDlqin2yrs', empty=0.5, corr=0.7, return_drop=True, exclude='type') 这里说一下toad.selection.select方法,用于筛选数据,传入的参数分别为: data_tr:训练用的特征数据 target:结果数据 empty:缺失值大于多少进行删除 corr:保留相关性大于多少的数据 return_drop: 若为True,function将返回被删去的变量列 exclude: 明确不被删去的列名,输入为list格式 返回的数据是筛选后的数据和删除的内容(格式为list),所以有两个返回值。 #5.特征预筛选 selected_train,drop_lst = toad.selection.select(data_tr,target='SeriousDlqin2yrs', empty=0.5, corr=0.7, return_drop=True, exclude='type') selected_test = data_ts[selected_train.columns] selected_train.shape drop_lst #删除的变量 4.特征分箱toad的分箱功能支持数值型数据和离散型分箱,默认分箱方法使用卡方分箱。 卡方分箱是自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。基本思想:对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
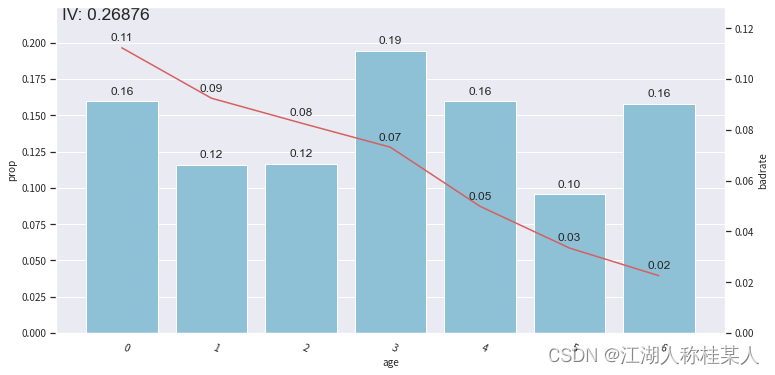
这篇文章我们主要讨论过程,就不叙述过多的概念了。 4.1 首先需要初始化一个Combiner类,这就是一个用作分箱的类。 #初始化一个combiner类 combiner = toad.transform.Combiner()4.2 训练分箱,其中method是分箱方法,类别有:’chi’ (卡方分箱), ‘dt’ (决策树分箱), ‘kmean’ , ‘quantile’ (等频分箱), ‘step’ (等步长分箱) #训练数据并制定分箱方法,需要分箱的变量共7个 combiner.fit(selected_train, y='SeriousDlqin2yrs', method='chi', min_samples=0.05, exclude='type')4.3 查看分箱结果: #以字典的形式保存分箱结果 bins = combiner.export()为了更直观的观察,还可以把特征的分箱图画出来,这里放几个图片,具体方法会在后面完整代码写出。
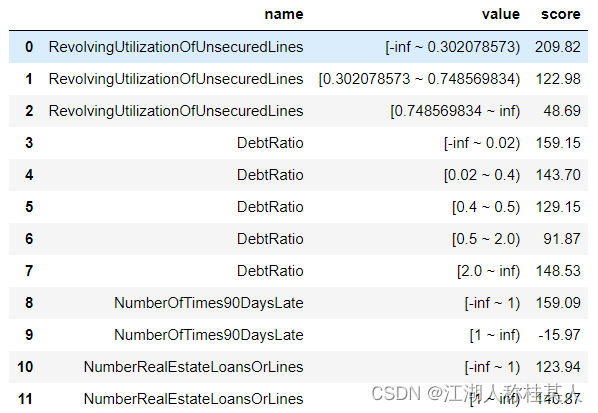
4.5 调整合并分箱 对于离散型的数据可以进行手动分箱: #定义调整分箱 #调整分箱切分点 bins_adj=bins bins_adj["age"] = [22,35,45,60] bins_adj["NumberOfOpenCreditLinesAndLoans"] = [2] bins_adj["DebtRatio"] = [0.02,0.4,0.5,2] #定义分类合并器 combiner2 = toad.transform.Combiner() #定义分箱combiner combiner2.set_rules(bins_adj) #设置需要施加的分箱 #应用调整分箱 selected_train_binadj = combiner2.transform(selected_train)注意:这些变量其实是我们之前处理过的,为了更好的确定各箱的边界,所以单独再进行设置。 5.转换WOE值计算后的WOE值我们无法直接使用,需要进行转换: #设置分箱号 combiner.set_rules(bins_adj) #特征转化的值转化为分箱的箱号 selected_train_binadj = combiner.transform(selected_train) selected_test_binadj = combiner.transform(selected_test) #定义WOE转换器 WOETransformer = toad.transform.WOETransformer() #对WOE的值进行转化,映射到原数据集上,对训练集使用fit_transform()方法转化,对测试集使用transform()方法转化 data_tr_woe = WOETransformer.fit_transform(selected_train_binadj, selected_train_binadj['SeriousDlqin2yrs'], exclude=['SeriousDlqin2yrs','type']) data_ts_woe = WOETransformer.transform(selected_test_binadj)其实这部分就是很固定的一种写法,在使用自己数据集时把参数进行替换即可。 6.特征选择有的读者看到这里可能会问,为什么要进行两次的特征筛选,是因为我们之前筛选指标的量度只有缺失率和相关性,下面采用的是逐步回归的方法。 train_final = toad.selection.stepwise(data_tr_woe.drop('type',axis=1), target='SeriousDlqin2yrs', direction='both', criterion='aic' ) test_final = data_ts_woe[train_final.columns] print(train_final.shape) #7个特征减少为5个说一下toad.selection.stepwise()的参数: estimator: 用于拟合的模型,支持'ols', 'lr', 'lasso', 'ridge'direction: 逐步回归的方向,支持'forward', 'backward', 'both' (推荐)criterion: 评判标准,支持'aic', 'bic', 'ks', 'auc'max_iter: 最大循环次数return_drop: 是否返回被剔除的列名exclude: 不需要被训练的列名 7.模型训练调用逻辑回归进行训练。 #准备数据 Xtr = train_final.drop('SeriousDlqin2yrs',axis=1) Ytr = train_final['SeriousDlqin2yrs'] #逻辑回归模型拟合 lr = LogisticRegression() lr.fit(Xtr,Ytr) #打印模型拟合的参数 lr.coef_ lr.intercept_ 8.模型评估 #在训练集上的模型表现 EYtr_proba = lr.predict_proba(Xtr)[:,1] EYtr_proba = lr.predict(Xtr) print('train F1:',F1(EYtr_proba,Ytr)) print('train KS:',KS(EYtr_proba,Ytr)) print('train AUC:',AUC(EYtr_proba,Ytr)) #分值排序性 tr_bucket = toad.metrics.KS_bucket(EYtr_proba,Ytr,bucket=10,method='quantile') #等频分段 tr_bucket 9.模型验证 #在测试集上的模型表现 Xts = test_final.drop('SeriousDlqin2yrs',axis=1) Yts = test_final['SeriousDlqin2yrs'] EYtr_proba = lr.predict_proba(Xts)[:,1] EYts = lr.predict(Xts) print('train F1:',F1(EYtr_proba,Yts)) print('train KS:',KS(EYtr_proba,Yts)) print('train AUC:',AUC(EYtr_proba,Yts)) #基于分箱之后的数据,比较训练集、测试集变量稳定性分布是否有显著差异 psi = toad.metrics.PSI(train_final,test_final) psi.sort_values(0,ascending=False) 10.分值转换 scorecard = toad.scorecard.ScoreCard(combiner=combiner,transer=WOETransformer,C=0.1) scorecard.fit(Xtr,Ytr) scorecard.export(to_frame=True)
后面的步骤比较粗略,有机会再补充。 欢迎批评指正! 完整源码: import numpy as np import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split import toad from toad.plot import badrate_plot,proportion_plot,bin_plot from toad.metrics import KS,F1,AUC #1.读入数据 data = pd.read_csv('E://cs-training1.csv') #数据描述 data.info() data.describe() data.head() #2.样本分区 Xtr,Xts,Ytr,Yts = train_test_split(data.drop('SeriousDlqin2yrs',axis=1), data['SeriousDlqin2yrs'], test_size=0.25, random_state=450) data_tr = pd.concat([Xtr,Ytr],axis=1) data_tr['type'] = 'train' data_ts = pd.concat([Xts,Yts],axis=1) data_ts['type'] = 'test' #3.数据EDA报告 toad.detector.detect(data_tr).to_excel(r'E:/数据EDA结果.xlsx') #4.数据特征分析计算特征IV、gini、entropy、unique quality = toad.quality(data,'SeriousDlqin2yrs') quality.head(6) #5.特征预筛选 selected_train,drop_lst = toad.selection.select(data_tr,target='SeriousDlqin2yrs', empty=0.5, corr=0.7, return_drop=True, exclude='type') selected_test = data_ts[selected_train.columns] selected_train.shape drop_lst #删除的变量 #6.特征分箱 #初始化一个combiner类 combiner = toad.transform.Combiner() #训练数据并制定分箱方法,需要分箱的变量共7个 combiner.fit(selected_train, y='SeriousDlqin2yrs', method='chi', min_samples=0.05, exclude='type') #以字典的形式保存分箱结果 bins = combiner.export() #查看每个特征的分箱结果 print('DebtRatio分箱cut:',bins['DebtRatio']) print('MonthlyIncome分箱cut',bins['MonthlyIncome']) print('NumberOfOpenCreditLinesAndLoans分箱cut',bins['NumberOfOpenCreditLinesAndLoans']) print('NumberRealEstateLoansOrLines分箱cut',bins['NumberRealEstateLoansOrLines']) print('NumberOfTimes90DaysLate分箱cut',bins['NumberOfTimes90DaysLate']) print('RevolvingUtilizationOfUnsecuredLines分箱cut',bins['RevolvingUtilizationOfUnsecuredLines']) print('age分箱cut',bins['age']) #使用combine.transform()方法对数据进行分箱转换 selected_train_bin = combiner.transform(selected_train) #画分箱图,使用bin_plot函数绘制双轨图和分箱占比、分箱坏账率关系图 proportion_plot(selected_train_bin['DebtRatio']) proportion_plot(selected_train_bin['MonthlyIncome']) proportion_plot(selected_train_bin['NumberOfOpenCreditLinesAndLoans']) proportion_plot(selected_train_bin['NumberRealEstateLoansOrLines']) proportion_plot(selected_train_bin['NumberOfTimes90DaysLate']) proportion_plot(selected_train_bin['RevolvingUtilizationOfUnsecuredLines']) proportion_plot(selected_train_bin['age']) badrate_plot(selected_train_bin,target='SeriousDlqin2yrs',x='type',by='DebtRatio') badrate_plot(selected_train_bin,target='SeriousDlqin2yrs',x='type',by='MonthlyIncome') badrate_plot(selected_train_bin,target='SeriousDlqin2yrs',x='type',by='NumberOfOpenCreditLinesAndLoans') badrate_plot(selected_train_bin,target='SeriousDlqin2yrs',x='type',by='NumberRealEstateLoansOrLines') badrate_plot(selected_train_bin,target='SeriousDlqin2yrs',x='type',by='NumberOfTimes90DaysLate') badrate_plot(selected_train_bin,target='SeriousDlqin2yrs',x='type',by='RevolvingUtilizationOfUnsecuredLines') badrate_plot(selected_train_bin,target='SeriousDlqin2yrs',x='type',by='age') bin_plot(selected_train_bin,x='DebtRatio',target='SeriousDlqin2yrs') bin_plot(selected_train_bin,x='MonthlyIncome',target='SeriousDlqin2yrs') bin_plot(selected_train_bin,x='NumberOfOpenCreditLinesAndLoans',target='SeriousDlqin2yrs') bin_plot(selected_train_bin,x='NumberRealEstateLoansOrLines',target='SeriousDlqin2yrs') bin_plot(selected_train_bin,x='NumberOfTimes90DaysLate',target='SeriousDlqin2yrs') bin_plot(selected_train_bin,x='RevolvingUtilizationOfUnsecuredLines',target='SeriousDlqin2yrs') bin_plot(selected_train_bin,x='age',target='SeriousDlqin2yrs') #7.调整合并分箱 #定义调整分箱 #调整分箱切分点 bins_adj=bins bins_adj["age"] = [22,35,45,60] bins_adj["NumberOfOpenCreditLinesAndLoans"] = [2] bins_adj["DebtRatio"] = [0.02,0.4,0.5,2] #定义分类合并器 combiner2 = toad.transform.Combiner() #定义分箱combiner combiner2.set_rules(bins_adj) #设置需要施加的分箱 #应用调整分箱 selected_train_binadj = combiner2.transform(selected_train) #画分箱坏账率图 proportion_plot(selected_train_binadj['DebtRatio']) proportion_plot(selected_train_binadj['MonthlyIncome']) proportion_plot(selected_train_binadj['NumberOfOpenCreditLinesAndLoans']) proportion_plot(selected_train_binadj['NumberRealEstateLoansOrLines']) proportion_plot(selected_train_binadj['NumberOfTimes90DaysLate']) proportion_plot(selected_train_binadj['RevolvingUtilizationOfUnsecuredLines']) proportion_plot(selected_train_binadj['age']) badrate_plot(selected_train_binadj,target="SeriousDlqin2yrs",x='type',by='DebtRatio') badrate_plot(selected_train_binadj,target='SeriousDlqin2yrs',x='type',by='MonthlyIncome') badrate_plot(selected_train_binadj,target='SeriousDlqin2yrs',x='type',by='NumberOfOpenCreditLinesAndLoans') badrate_plot(selected_train_binadj,target='SeriousDlqin2yrs',x='type',by='NumberRealEstateLoansOrLines') badrate_plot(selected_train_binadj,target='SeriousDlqin2yrs',x='type',by='NumberOfTimes90DaysLate') badrate_plot(selected_train_binadj,target='SeriousDlqin2yrs',x='type',by='RevolvingUtilizationOfUnsecuredLines') badrate_plot(selected_train_binadj,target='SeriousDlqin2yrs',x='type',by='age') #8. 转换WOE值 #设置分箱号 combiner.set_rules(bins_adj) #特征转化的值转化为分箱的箱号 selected_train_binadj = combiner.transform(selected_train) selected_test_binadj = combiner.transform(selected_test) #定义WOE转换器 WOETransformer = toad.transform.WOETransformer() #对WOE的值进行转化,映射到原数据集上,对训练集使用fit_transform()方法转化,对测试集使用transform()方法转化 data_tr_woe = WOETransformer.fit_transform(selected_train_binadj, selected_train_binadj['SeriousDlqin2yrs'], exclude=['SeriousDlqin2yrs','type']) data_ts_woe = WOETransformer.transform(selected_test_binadj) #9.特征选择,使用stepwise()方法选择变量 train_final = toad.selection.stepwise(data_tr_woe.drop('type',axis=1), target='SeriousDlqin2yrs', direction='both', criterion='aic' ) test_final = data_ts_woe[train_final.columns] print(train_final.shape) #7个特征减少为5个 #10.模型训练 #准备数据 Xtr = train_final.drop('SeriousDlqin2yrs',axis=1) Ytr = train_final['SeriousDlqin2yrs'] #逻辑回归模型拟合 lr = LogisticRegression() lr.fit(Xtr,Ytr) #打印模型拟合的参数 lr.coef_ lr.intercept_ #11.模型评估 #在训练集上的模型表现 EYtr_proba = lr.predict_proba(Xtr)[:,1] EYtr_proba = lr.predict(Xtr) print('train F1:',F1(EYtr_proba,Ytr)) print('train KS:',KS(EYtr_proba,Ytr)) print('train AUC:',AUC(EYtr_proba,Ytr)) #分值排序性 tr_bucket = toad.metrics.KS_bucket(EYtr_proba,Ytr,bucket=10,method='quantile') #等频分段 tr_bucket #12.模型验证 #在测试集上的模型表现 Xts = test_final.drop('SeriousDlqin2yrs',axis=1) Yts = test_final['SeriousDlqin2yrs'] EYtr_proba = lr.predict_proba(Xts)[:,1] EYts = lr.predict(Xts) print('train F1:',F1(EYtr_proba,Yts)) print('train KS:',KS(EYtr_proba,Yts)) print('train AUC:',AUC(EYtr_proba,Yts)) #基于分箱之后的数据,比较训练集、测试集变量稳定性分布是否有显著差异 psi = toad.metrics.PSI(train_final,test_final) psi.sort_values(0,ascending=False) #13.分值转换 scorecard = toad.scorecard.ScoreCard(combiner=combiner,transer=WOETransformer,C=0.1) scorecard.fit(Xtr,Ytr) scorecard.export(to_frame=True) |

【本文地址】
今日新闻 |
推荐新闻 |