李宏毅2020机器学习 |
您所在的位置:网站首页 › python语句分类 › 李宏毅2020机器学习 |
李宏毅2020机器学习
|
一、作业说明 1.本次数据集包括training_data,training_label和training_nolabel三个txt文件,训练集包括有标签(积极的还是消极的)的和没有标签的,测试集为索引和和句子内容。 2.需要完成的任务根据所给的数据集训练LSTM网络用来判断句子的情感类别。 参考链接:https://blog.csdn.net/iteapoy/article/details/105931612 二、作业思路 导入库函数: import torch import torch.nn as nn from gensim.models import Word2Vec from torch.utils.data import DataLoader, Dataset import torch.optim as optim from sklearn.model_selection import train_test_split1.导入数据 由于所给数据集不满足标准的X,y格式,需要对数据集内容进行筛选: def load_training_data(path='/ML/data11/hw4/training_label.txt'): data = open(path, encoding='utf-8') lines = data.readlines() # readlines()用来读取每一行的数据(直到EOF),返回列表 x_data = [] y_label = [] for line in lines: ad_line = line.strip('\n').split(' ') # 移除每行句子的换行符,同时对每一行中句子的单词按空格拆分, x_data.append(ad_line[2:]) y_label.append(ad_line[0]) return x_data, y_label def load_training_data1(path='/ML/data11/hw4/training_nolabel.txt'): data = open(path, encoding='utf-8') lines = data.readlines() x_data = [] for line in lines: ad_line = line.strip('\n').split(' ') x_data.append(ad_line) return x_data def load_testing_data(path='/ML/data11/hw4/testing_data.txt'): data = open(path, encoding='utf-8') lines = data.readlines() # 除去第一行的id,text,第一列的索引 x = ["".join(line.strip('\n').split(",")[1:]).strip() for line in lines[1:]] x = [sen.split(' ') for sen in X] # 将每个句子的单词分离出来,用以后面的W2V return x2.数据预处理 文本内容无法直接用于计算机计算,需要将文本转为向量。除了教程中用到的one-hot编码(矩阵庞大且过于稀疏,会浪费很大的内存),本次作业采用word-embedding(词嵌入)的方法,就是将单词变为向量 半监督学习(simi supervise learning): 简单来说,就是机器利用一部分有标注的数据(通常比较少) 和 一部分无标注的数据(通常比较多) 来进行训练。 半监督学习的方法有很多种,最容易理解、也最好操作的一种是Self-Training:把训练好的模型对无标签的数据( unlabeled data )做预测,将预测值作为该数据的标签(label),并加入这些新的有标签的数据做训练。可以通过调整阈值(threshold),或是多次取样来得 到比较可信的数据。 评估函数如下: def evaluation(outputs, labels): # outputs => 预测值,概率(float) # labels => 真实值,标签(0或1) outputs[outputs >= 0.5] = 1 # 大于等于 0.5 为正面 outputs[outputs < 0.5] = 0 # 小于 0.5 为负面 accuracy = torch.sum(torch.eq(outputs, labels)).item() return accuracy词嵌入: word2vec 即 word to vector 的缩写。把 training 和 testing 中的每个单词都分别变成词向量,这里用到了 Gensim 来进行 word2vec 的操作。没有 gensim 的可以用 conda install gensim 或者 pip install gensim 安装一下。 Gensim中的参数可见:Word2Vec的使用 def train_word2vec(x): # 训练 word to vector 的 word embedding # window:表示在一个句子中,当前词于预测词在一个句子中的最大距离 min_count:过滤掉语料中出现频率小于min_count的词 model = Word2Vec(x, size=250, window=5, min_count=5, workers=12, iter=10, sg=1) return model # 读取 training 数据 print("loading training data ...") train_x, y = load_training_data() train_x_no_label = load_training_data1() # 读取 testing 数据 print("loading testing data ...") test_x = load_testing_data() # 把 training 中的 word 变成 vector # model = train_word2vec(train_x + train_x_no_label + test_x) # w2v_all model = train_word2vec(train_x + test_x) # w2v # 保存 vector print("saving model ...") # model.save('w2v_all.model') model.save('w2v.model') # save后下次就不要再执行了得到的model如下,共16551个不同的单词,size表示每个单词的维度为250,alpha为学习率(Word2Vec要自己学习)
得到训练好的W2V的model后进行预处理函数的定义,预处理函数的作用是将model得到的16551个单词给上索引,加上和两种词。还有根据提前设置好的句子长度将所有句子通过增加和变成一样长的句子。 变量的相关定义: w2v_path:word2vec的存储路径sentences:句子sen_len:句子的固定长度idx2word 是一个列表,比如:self.idx2word[1] = ‘he’word2idx 是一个字典,记录单词在 idx2word 中的下标,比如:self.word2idx[‘he’] = 1embedding_matrix 是一个列表,记录词嵌入的向量,比如:self.embedding_matrix[1] = ‘he’ vector “”:Padding的缩写,把所有句子都变成一样长度时,需要用""补上空白符 “”:Unknown的缩写,凡是在 train_x 和 test_x 中没有出现过的单词,都用""来表示 # 数据预处理 class Preprocess(): def __init__(self, sentences, sen_len, w2v_path): self.w2v_path = w2v_path # word2vec的存储路径 self.sentences = sentences # 句子 self.sen_len = sen_len # 句子的固定长度 self.idx2word = [] self.word2idx = {} self.embedding_matrix = [] def get_w2v_model(self): # 读取之前训练好的 word2vec self.embedding = Word2Vec.load(self.w2v_path) self.embedding_dim = self.embedding.vector_size def add_embedding(self, word): # 这里的 word 只会是 "" 或 "" # 把一个随机生成的表征向量 vector 作为 "" 或 "" 的嵌入 vector = torch.empty(1, self.embedding_dim) torch.nn.init.uniform_(vector) # 它的 index 是 word2idx 这个词典的长度,即最后一个 self.word2idx[word] = len(self.word2idx) self.idx2word.append(word) self.embedding_matrix = torch.cat([self.embedding_matrix, vector], 0) def make_embedding(self, load=True): print("Get embedding ...") # 获取训练好的 Word2vec word embedding if load: print("loading word to vec model ...") self.get_w2v_model() else: raise NotImplementedError # 遍历嵌入后的单词 for i, word in enumerate(self.embedding.wv.vocab): print('get words #{}'.format(i+1), end='\r') # 新加入的 word 的 index 是 word2idx 这个词典的长度,即最后一个 self.word2idx[word] = len(self.word2idx) self.idx2word.append(word) self.embedding_matrix.append(self.embedding.wv[word]) print('') # 把 embedding_matrix 变成 tensor self.embedding_matrix = torch.tensor(self.embedding_matrix) # 将 和 加入 embedding self.add_embedding("") self.add_embedding("") print("total words: {}".format(len(self.embedding_matrix))) return self.embedding_matrix def pad_sequence(self, sentence): # 将每个句子变成一样的长度,即 sen_len 的长度 if len(sentence) > self.sen_len: # 如果句子长度大于 sen_len 的长度,就截断 sentence = sentence[:self.sen_len] else: # 如果句子长度小于 sen_len 的长度,就补上 符号,缺多少个单词就补多少个 pad_len = self.sen_len - len(sentence) for _ in range(pad_len): sentence.append(self.word2idx[""]) assert len(sentence) == self.sen_len return sentence def sentence_word2idx(self): # 把句子里面的字变成相对应的 index sentence_list = [] for i, sen in enumerate(self.sentences): print('sentence count #{}'.format(i+1), end='\r') sentence_idx = [] for word in sen: if word in self.word2idx.keys(): sentence_idx.append(self.word2idx[word]) else: # 没有出现过的单词就用 表示 sentence_idx.append(self.word2idx[""]) # 将每个句子变成一样的长度 sentence_idx = self.pad_sequence(sentence_idx) sentence_list.append(sentence_idx) return torch.LongTensor(sentence_list) def labels_to_tensor(self, y): # label需要是LongTensor型,torch.Tensor默认为torch.FloatTensor是32位浮点类型数据,torch.LongTensor是64位整型数据 y = [int(label) for label in y] return torch.LongTensor(y)得到的字典word2idx结果为:
idx2word结果为:
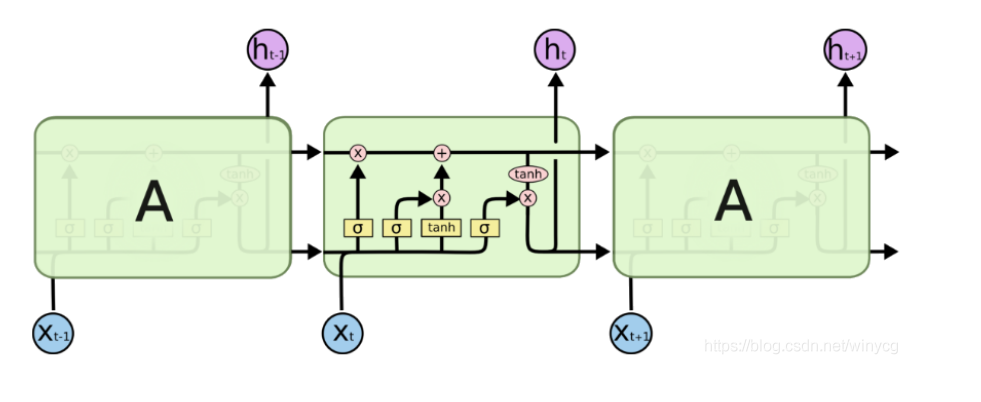
3.将带有标签的数据按比例分为训练集和验证集,train_test_split()函数中的参数可参见:https://blog.csdn.net/sinat_33231573/article/details/112174813,代码如下: X_train, X_val, y_train, y_val = train_test_split(train_x, y, test_size=0.3, random_state=1, stratify=y)4.利用Dataset和Dataloader对数据进行包装,上一次作业用到过,就是定义类函数dataset中的三个子函数。 class SenDataset(Dataset): def __init__(self, X, y): self.x_data = X self.y_label = y def __len__(self): return len(self.x_data) def __getitem__(self, idx): if self.y_label is None: return self.x_data[idx] else: return self.x_data[idx], self.y_label[idx] train_dataset = SenDataset(X=X_train, y=y_train) val_dataset = SenDataset(X=X_val, y=y_val)5.定义模型 因为LSTM(Long Short-Term Memory,长短期记忆网络)的效果比普通的RNN好,所以现在当我们说RNN的时候,一般都是指LSTM. 把句子丢到LSTM中,变成一个输出向量,再把这个输出丢到分类器classifier中,进行二元分类。 LSTM的内部结构:
关于Pytorch中的LSTM的使用可参见:https://zhuanlan.zhihu.com/p/41261640
参数列表 input_size:x的特征维度 hidden_size:隐藏层的特征维度 num_layers:lstm隐层的层数,默认为1 bias:False则bih=0和bhh=0. 默认为True batch_first:True则输入输出的数据格式为 (batch, seq, feature) dropout:除最后一层,每一层的输出都进行dropout,默认为: 0 bidirectional:True则为双向lstm默认为False 输入:input, (h0, c0) 输出:output, (hn,cn)输入数据格式:input(seq_len, batch, input_size)h0(num_layers * num_directions, batch, hidden_size)c0(num_layers * num_directions, batch, hidden_size) 输出数据格式:output(seq_len, batch, hidden_size * num_directions)hn(num_layers * num_directions, batch, hidden_size)cn(num_layers * num_directions, batch, hidden_size) 输入输出的三维数据的含义为:sequence(序列,每个句子的长度,包括几个单词)、batch(每次送入LSTM几个句子)、input_size(送入句子的单词对应的向量维数) class LSTM_Net(nn.Module): def __init__(self, embedding, embedding_dim, hidden_dim, num_layers, dropout=0.5, fix_embedding=True): super(LSTM_Net, self).__init__() # embedding layer self.embedding = torch.nn.Embedding(embedding.size(0), embedding.size(1)) self.embedding.weight = torch.nn.Parameter(embedding) # 是否将 embedding 固定住,如果 fix_embedding 为 False,在训练过程中,embedding 也会跟着被训练 self.embedding.weight.requires_grad = False if fix_embedding else True self.embedding_dim = embedding.size(1) self.hidden_dim = hidden_dim self.num_layers = num_layers self.dropout = dropout self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, batch_first=True) self.classifier = nn.Sequential( nn.Dropout(dropout), nn.Linear(hidden_dim, 1), nn.Sigmoid() ) def forward(self, inputs): inputs = self.embedding(inputs) x, _ = self.lstm(inputs, None) # x 的 dimension batch, seq_len, hidden_size) # 取用 LSTM 最后一层的 hidden state 丢到分类器中 x = x[:, -1, :] x = self.classifier(x) return x6.训练数据 nn.BCELoss与nn.CrossEntropyLoss的区别: 1.使用nn.BCELoss前需要加上Sigmoid函数,即二元交叉熵
2.使用nn.CrossEntropyLoss会自动加上Softmax层,
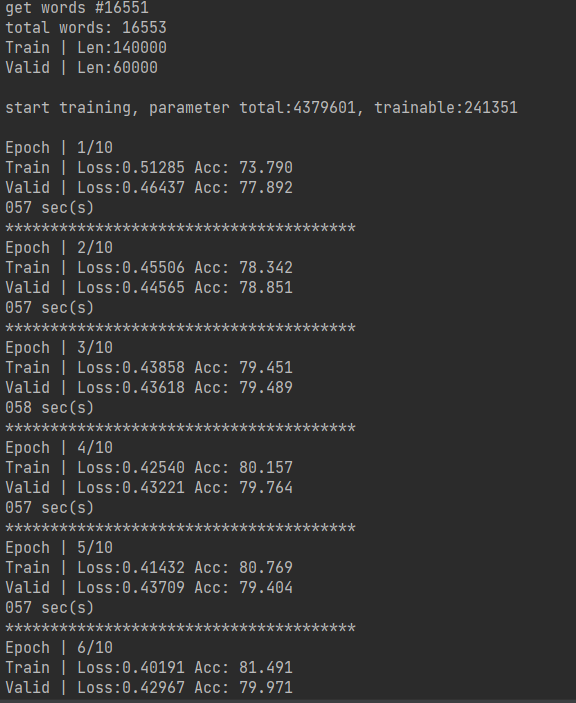
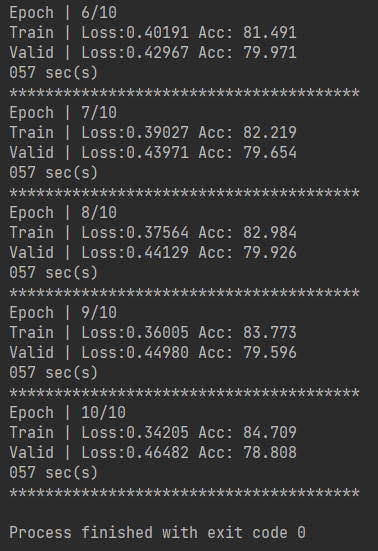
def training(batch_size, n_epoch, lr, train, valid, model, device): # 输出模型总的参数数量、可训练的参数数量 total = sum(p.numel() for p in model.parameters()) trainable = sum(p.numel() for p in model.parameters() if p.requires_grad) print('\nstart training, parameter total:{}, trainable:{}\n'.format(total, trainable)) loss = nn.BCELoss() # 定义损失函数为二元交叉熵损失 binary cross entropy loss t_batch = len(train) # training 数据的batch size大小 v_batch = len(valid) # validation 数据的batch size大小 optimizer = optim.Adam(model.parameters(), lr=lr) # optimizer用Adam,设置适当的学习率lr total_loss, total_acc, best_acc = 0, 0, 0 for epoch in range(n_epoch): total_loss, total_acc = 0, 0 # training model.train() # 将 model 的模式设为 train,这样 optimizer 就可以更新 model 的参数 for i, (inputs, labels) in enumerate(train): inputs = inputs.to(device, dtype=torch.long) # 因为 device 为 "cuda",将 inputs 转成 torch.cuda.LongTensor labels = labels.to(device, dtype=torch.float) # 因为 device 为 "cuda",将 labels 转成 torch.cuda.FloatTensor,loss()需要float optimizer.zero_grad() # 由于 loss.backward() 的 gradient 会累加,所以每一个 batch 后需要归零 outputs = model(inputs) # 模型输入Input,输出output outputs = outputs.squeeze() # 去掉最外面的 dimension,好让 outputs 可以丢进 loss()******没看懂!!!!!! batch_loss = loss(outputs, labels) # 计算模型此时的 training loss batch_loss.backward() # 计算 loss 的 gradient optimizer.step() # 更新模型参数 accuracy = evaluation(outputs, labels) # 计算模型此时的 training accuracy total_acc += (accuracy / batch_size) total_loss += batch_loss.item() print('Epoch | {}/{}'.format(epoch + 1, n_epoch)) print('Train | Loss:{:.5f} Acc: {:.3f}'.format(total_loss / t_batch, total_acc / t_batch * 100)) # validation model.eval() # 将 model 的模式设为 eval,这样 model 的参数就会被固定住 with torch.no_grad(): total_loss, total_acc = 0, 0 for i, (inputs, labels) in enumerate(valid): inputs = inputs.to(device, dtype=torch.long) # 因为 device 为 "cuda",将 inputs 转成 torch.cuda.LongTensor labels = labels.to(device, dtype=torch.float) # 因为 device 为 "cuda",将 labels 转成 torch.cuda.FloatTensor,loss()需要float outputs = model(inputs) # 模型输入Input,输出output outputs = outputs.squeeze() # 去掉最外面的 dimension,好让 outputs 可以丢进 loss() batch_loss = loss(outputs, labels) # 计算模型此时的 training loss accuracy = evaluation(outputs, labels) # 计算模型此时的 training accuracy total_acc += (accuracy / batch_size) total_loss += batch_loss.item() print("Valid | Loss:{:.5f} Acc: {:.3f} ".format(total_loss / v_batch, total_acc / v_batch * 100)) if total_acc > best_acc: # 如果 validation 的结果优于之前所有的結果,就把当下的模型保存下来,用 于之后的testing best_acc = total_acc torch.save(model, "ckpt.model") print('***************************************') 定义好参数并利用上面定义好的函数进行训练, # 通过 torch.cuda.is_available() 的值判断是否可以使用 GPU ,如果可以的话 device 就设为 "cuda",没有的话就设为 "cpu" device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 定义句子长度、要不要固定 embedding、batch 大小、要训练几个 epoch、 学习率的值、 w2v的路径 sen_len = 20 fix_embedding = True # fix embedding during training batch_size = 128 epoch = 10 lr = 0.001 w2v_path = 'w2v.model' # 对 input 跟 labels 做预处理 preprocess = Preprocess(train_x, sen_len, w2v_path=w2v_path) embedding = preprocess.make_embedding(load=True) train_x = preprocess.sentence_word2idx() y = preprocess.labels_to_tensor(y) # 定义模型 model = LSTM_Net(embedding, embedding_dim=250, hidden_dim=150, num_layers=1, dropout=0.5, fix_embedding=fix_embedding) model = model.to(device) # device为 "cuda",model 使用 GPU 来训练(inputs 也需要是 cuda tensor) # 把 data 分为 training data 和 validation data(将一部分 training data 作为 validation data) X_train, X_val, y_train, y_val = train_test_split(train_x, y, test_size=0.3, random_state=1, stratify=y) print('Train | Len:{} \nValid | Len:{}'.format(len(y_train), len(y_val))) # 把 data 做成 dataset 供 dataloader 取用 train_dataset = SenDataset(X=X_train, y=y_train) val_dataset = SenDataset(X=X_val, y=y_val) # 把 data 转成 batch of tensors train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=0) # 开始训练 training(batch_size, epoch, lr, train_loader, val_loader, model, device)得到的结果如下,
|



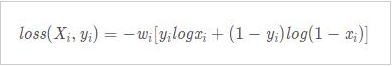

【本文地址】
今日新闻 |
推荐新闻 |