【python数据分析】正态分布、正态性检验与相关性分析 |
您所在的位置:网站首页 › python计算两组数据的相关性分析 › 【python数据分析】正态分布、正态性检验与相关性分析 |
【python数据分析】正态分布、正态性检验与相关性分析
|
正态分布、正态性检验与相关性分析
1 正态分布2 正态性检验2.1 直方图初判2.2 QQ图2.3 K-S检验2.3.1 计算推导2.3.2 代码一步到位
3 相关性分析3.1 图示初判3.2 Pearson相关系数3.2.1 计算推导3.2.2 代码一步到位
3.3 Sperman秩相关系数3.3.1 计算推导3.3.2 代码一步到位
4 总结
手动反爬虫:
原博地址
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
如若转载,请标明出处,谢谢! 1 正态分布正态分布概念是由法国数学家和天文学家棣莫弗(Abraham de Moivre)于1733年首次提出的,后由德国数学家Gauss率先将其应用于天文学研究,故正态分布又叫高斯分布 若随机变量 X X X服从一个数学期望为 μ μ μ、方差为 σ 2 σ^{2} σ2的正态分布,记为 N ( μ , σ 2 ) N(μ,σ^{2}) N(μ,σ2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差 σ σ σ决定了分布的幅度。当 μ = 0 , σ = 1 μ = 0,σ = 1 μ=0,σ=1时的正态分布是标准正态分布 正态分布对应的概率密度函数:
f
(
x
)
=
1
2
π
σ
e
x
p
(
−
(
x
−
μ
)
2
2
σ
2
)
f(x) = \frac{1}{\sqrt{2\pi}σ}exp(-\frac{(x-μ)^{2}}{2σ^{2}})
f(x)=2π
σ1exp(−2σ2(x−μ)2)标准正态分布对应的概率密度函数:
f
(
x
)
=
1
2
π
e
(
−
x
2
2
)
f(x) = \frac{1}{\sqrt{2\pi}}e^{(-\frac{x^{2}}{2})}
f(x)=2π
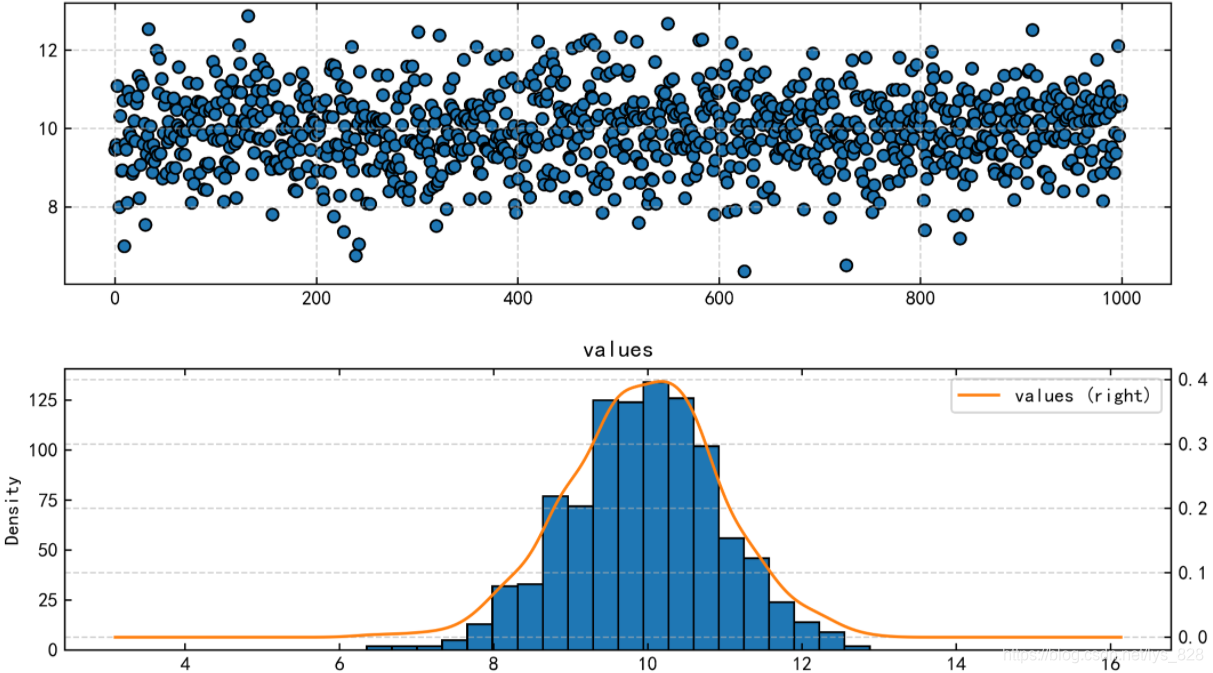
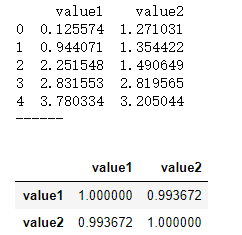
1e(−2x2)正态分布曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。 对于数据分析过程中的正态分布的理解: 并不是所有的数据都是满足正态分布(比如幂律分布)并不是必须满足正态分布才能作分析通过正态分布作为参考去理解事物规律可以通过多种方式进行正态性检验 2 正态性检验编程环境是在jupyter notebook中 2.1 直方图初判这里随机生成数据 import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline s = pd.DataFrame(np.random.randn(1000)+10, columns = ['values']) fig = plt.figure(figsize=(10,6),dpi = 500) ax1 = fig.add_subplot(2,1,1) ax1.scatter(s.index,s.values,edgecolor = 'black') ax2 = fig.add_subplot(2,1,2) s.hist(bins = 20,ax = ax2,edgecolor = 'black') s.plot(kind = 'kde', secondary_y = True, ax = ax2)输出结果为:(可以发现绘制的密度曲线满足正态分布的曲线样式) QQ图通过把测试样本数据的分位数与已知分布相比较,从而来检验数据的分布情况 QQ图是一种散点图,对应于正态分布的QQ图,就是由标准正态分布的分位数为横坐标,样本值为纵坐标的散点图 参考直线:四分之一分位点和四分之三分位点这两点确定,看散点是否落在这条线的附近 绘制思路: (1) 在做好数据清洗后,对数据进行排序(次序统计量:x(1)D(n,α) 如果p>0.05则接受H0,p'value1':data1.values, 'value2':data2.values}) print(data.head()) print('------') # 创建样本数据 u1,u2 = data['value1'].mean(),data['value2'].mean() # 计算均值 std1,std2 = data['value1'].std(),data['value2'].std() # 计算标准差 print('value1正态性检验:\n',stats.kstest(data['value1'], 'norm', (u1, std1))) print('value2正态性检验:\n',stats.kstest(data['value2'], 'norm', (u2, std2))) print('------') # 正态性检验 → pvalue >0.05 data['(x-u1)*(y-u2)'] = (data['value1'] - u1) * (data['value2'] - u2) data['(x-u1)**2'] = (data['value1'] - u1)**2 data['(y-u2)**2'] = (data['value2'] - u2)**2 print(data.head()) print('------') # 制作Pearson相关系数求值表 r = data['(x-u1)*(y-u2)'].sum() / (np.sqrt(data['(x-u1)**2'].sum() * data['(y-u2)**2'].sum())) print('Pearson相关系数为:%.4f' % r) # 求出r # |r| > 0.8 → 高度线性相关输出结果为:(先检验正态性,然后按照公式求解即可) 使用pandas的.corr()方法 data1 = pd.Series(np.random.rand(100)*100).sort_values() data2 = pd.Series(np.random.rand(100)*50).sort_values() data = pd.DataFrame({'value1':data1.values, 'value2':data2.values}) print(data.head()) print('------') # 创建样本数据 data.corr() # pandas相关性方法:data.corr(method='pearson', min_periods=1) → 直接给出数据字段的相关系数矩阵 # method默认pearson输出结果为:(0.9937,很明显具有相关性) 皮尔逊相关系数主要用于服从正态分布的连续变量,不服从正态分布的变量,分类的关联性可以采用Sperman秩相关系数,也称等级相关系数
输出结果为:(可以看出每周看电视的小时数和智商没有太大相关性) 参数中有个method,换一下即可 data = pd.DataFrame({'智商':[106,86,100,101,99,103,97,113,112,110], '每周看电视小时数':[7,0,27,50,28,29,20,12,6,17]}) print(data) print('------') # 创建样本数据 data.corr(method='spearman') # pandas相关性方法:data.corr(method='pearson', min_periods=1) → 直接给出数据字段的相关系数矩阵 # method默认pearson输出结果为:(可以发现最后的结果和上面的计算推导是一致的) (1)正态分布直接先通过柱状图和密度曲线查看 (2)正态性检验:stats.kstest(df['value'], 'norm', (u, std)) (3)Pearson相关系数:前提是正态分布,data.corr() (4)Sperman秩相关系数:不要求是正态分布,data.corr(method='spearman') |


 计算逻辑:
计算逻辑: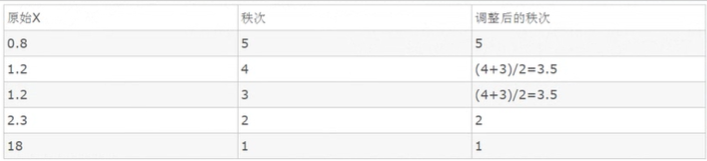


【本文地址】
今日新闻 |
推荐新闻 |