【Python例】利用 python 进行图片文字信息的提取 |
您所在的位置:网站首页 › python如何读取图片的定位信息 › 【Python例】利用 python 进行图片文字信息的提取 |
【Python例】利用 python 进行图片文字信息的提取
|
【Python例】利用 python 进行图片文字信息的提取 — OCR-EasyOCR 本文主要用于记录,并使用 python 脚本进行图片文字信息的生成。 什么是 OCR?
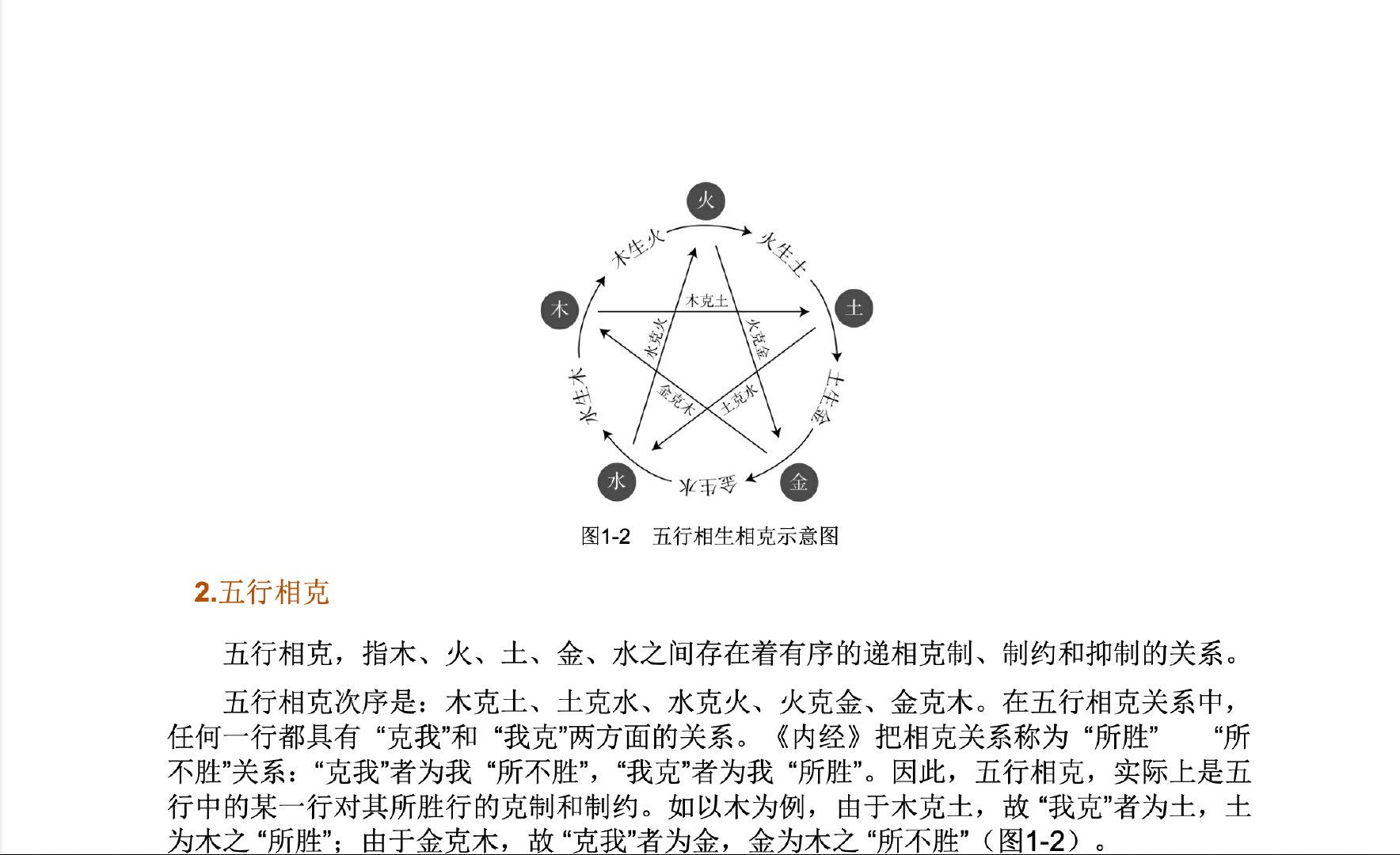
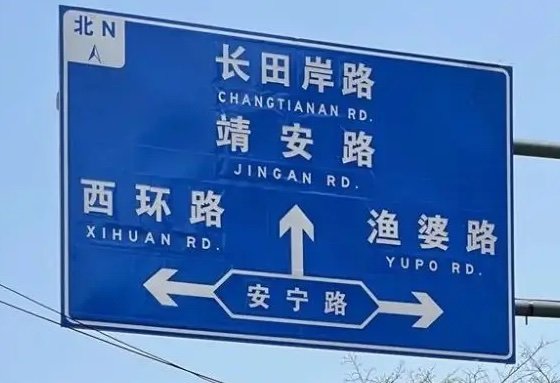
OCR(Optical character recognition,光学字符识别)是一种将图像中的手写字或者印刷文本转换为机器编码文本的技术。通过数字方式存储文本数据更容易保存和编辑,可以存储大量数据,比如 1G 的硬盘可以存储数百万本书。 OCR 技术可以将图片,纸质文档中的文本转换为数字形式的文本。OCR 过程一般包括以下步骤: 图像预处理文本定位字符分割字符识别后处理 使用 python 库实现 OCR对于 OCR 技术来说 python 实际上是一种对数据的交互接口,核心还是后端的一些数据处理,但是 python 的库实在是太多了,这里罗列一些 python 的 OCR 处理的功能库。 easyocrPaddleOCRpytesseract其他 Easyocr 安装这里使用 pip 工具进行 python 库构 easyocr 的安装, python3 -m pip install easyocr 测试例子 #!/usr/bin/env python3 # python3 -m pip install easyocr //使用pip工具进行easyocr的安装 import easyocr import os # print(os.getcwd()) current_path = os.path.dirname(__file__) # 设置相对路径 print(current_path) #视屏截图 test_images1 = (current_path+'/source/test_img1.jpg') #文本pdf截图 test_images2 = (current_path+'/source/test_img2.png') #路标图片 test_images3 = (current_path+'/source/test_img3.jpg') #书本拍照图片 test_images4 = (current_path+'/source/test_img4.jpg') #设置识别中英文两种语言 reader = easyocr.Reader(['ch_sim','en'], gpu = False) # need to run only once to load model into memory #对有视频截图图片进行测试 # result = reader.readtext((test_images1), detail = 0) # print(result) #对于普通pdf文本截图进行测试 # result = reader.readtext((test_images2), detail = 0) # print(result) #对于普通pdf文本截图进行测试 # result = reader.readtext((test_images3), detail = 0) # print(result) #对于书本的文本照片进行测试 result = reader.readtext((test_images4), detail = 0) print(result)运行脚本,运行时间有点长, 对比结果结果如下: 测试一:
测试二:
测试三:
测试四: [ easyocr 存在一些背景干扰的文字识别正确率的问题,可能需要一些调整,但是对于一些 pdf 等标准数字文档的截图还是可以识别并且进行内容提取的。 PaddleOCR 安装这里使用 pip 工具进行 python 库构的安装, python3 -m pip install并未进行测试 测试例子 #!/usr/bin/env python3 对比结果锟钅烤锟斤 序号参考描述结果表述测试 1视频截图照片锟钅烤锟斤测试 2PDF 文本截图锟钅烤锟斤测试 3交通路牌照片锟钅烤锟斤测试 4书本内容照片锟钅烤锟斤 结论锟钅烤锟斤 pytesseract 安装这里使用 pip 工具进行 python 库构的安装, python3 -m pip install并未进行测试 测试例子 #!/usr/bin/env python3 对比结果锟钅烤锟斤 序号参考描述结果表述测试 1视频截图照片锟钅烤锟斤测试 2PDF 文本截图锟钅烤锟斤测试 3交通路牌照片锟钅烤锟斤测试 4书本内容照片锟钅烤锟斤 结论锟钅烤锟斤 参考文档 适合小白的入门 OCR - CSDNPaddleOCR 文档说明 - GitHubEasyOCR 项目仓库地址 - GitHubEasyOCR 项目实践 - 知乎PaddleOCR 项目仓库地址 - GitHubpytesseract 项目 - CSDN |


 ]
]【本文地址】
今日新闻 |
推荐新闻 |