|
本篇博客通过分析泰坦尼克号事故中乘客的信息,从而得出一些相关关系的判断,并且使用Python可视化的手段更加具体的展现。
注:本篇博客参考资料: 1、kaggle入门–泰坦尼克号之灾(某书) 2、机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 3、缺失值填充的几种方法 4、关于Kaggle 数据挖掘比赛(某乎) 5、Kaggle官网 6、数据分析的小提琴图应该怎么看(某乎) 7、随机森林 n_estimators参数 max_features参数 8、关于pandas中crosstab的用法(某乎)
文章目录
一、数据的初步探索
二、数据的缺失值处理
三、使用随机森林处理年龄
四、分析数据之间的关系
1. 性别与生存率的关系
2.舱位等级与生存率的关系
3. 舱位等级,性别和年龄的关系
4. 不同年龄阶段的总体分析
5.称谓与存活的关系
6.名称长度与存活率的关系
7.亲属与存活率之间的关系
8.舱位类型与存活率之间的关系
9.对不同类型的船舱进行分析
10.出发港口与存活率之间的关系
一、数据的初步探索
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline # 有时候图片展示不出来可能是这个原因
plt.rcParams['font.sans-serif']=['Microsoft YaHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
from datetime import datetime
plt.figure(figsize=(16,10))
import pyecharts.options as opts
from pyecharts.charts import Line
from pyecharts.faker import Faker
from pyecharts.charts import Bar
import os
from pyecharts.options.global_options import ThemeType
from scipy import stats
import pandas_profiling
from autoviz.AutoViz_Class import AutoViz_Class
from IPython.display import display
from statsmodels.stats.weightstats import ztest
import nltk
import plotly.graph_objs as go
import plotly.express as px
# 安装第三方工具包
!pip install pandas_profiling
!pip install autoviz
!pip install ppscore
# 读入数据
df=pd.read_csv("titanic.csv")
display(df.head(10))
读入数据: 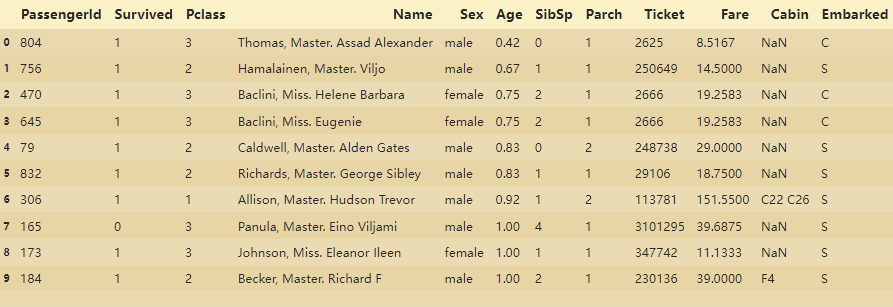
•PassengerID(ID)
•Survived(存活与否)
•Pclass(客舱等级,较为重要)
•Name(姓名,可提取出更多信息)
•Sex(性别,较为重要)
•Age(年龄,较为重要)
•Parch(直系亲友)
•SibSp(旁系)
•Ticket(票编号)
•Fare(票价)
•Cabin(客舱编号)
•Embarked(上船的港口编号)
使用Pandas profiling 库: Pandas profiling可以弥补pandas describe没有详细数据报告生成的不足。它为数据集提供报告生成,并为生成的报告提供许多功能和自定义。
report=pandas_profiling.ProfileReport(df)
display(report)
# 通过不同的角度查看缺失值
 使用Python Autoviz,一行代码即可完成对数据集所有关系的探索: 使用Python Autoviz,一行代码即可完成对数据集所有关系的探索:
AV=AutoViz_Class()
report2=AV.AutoViz("titanic.csv")
初步的分析数据: 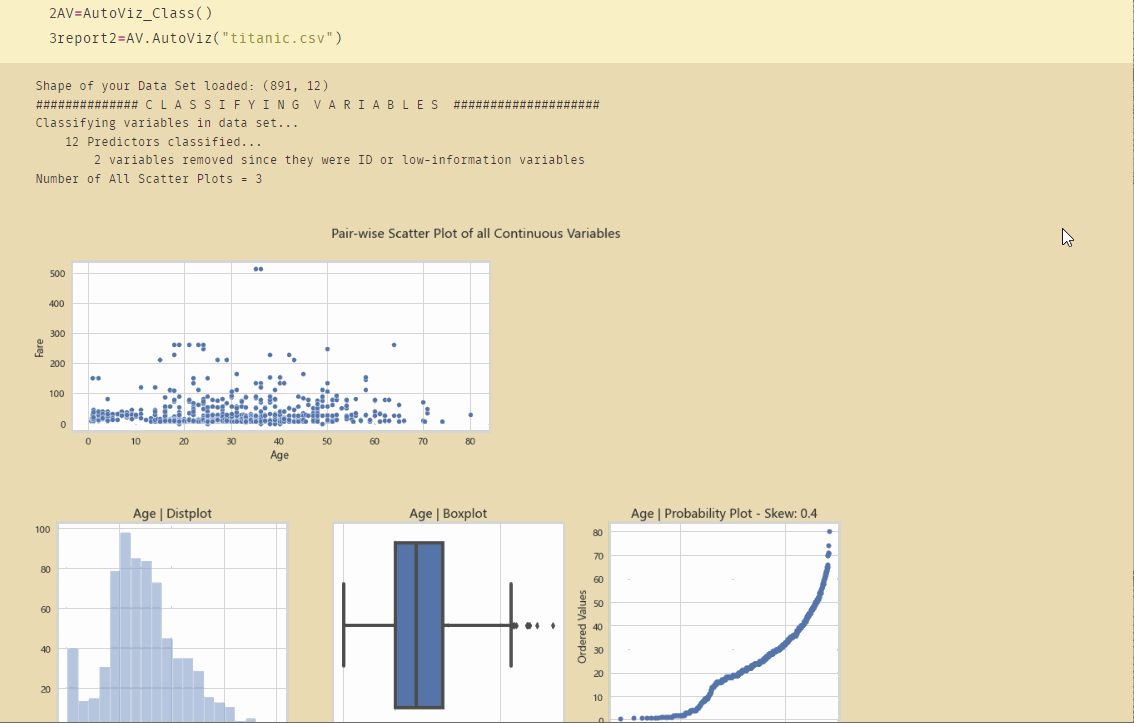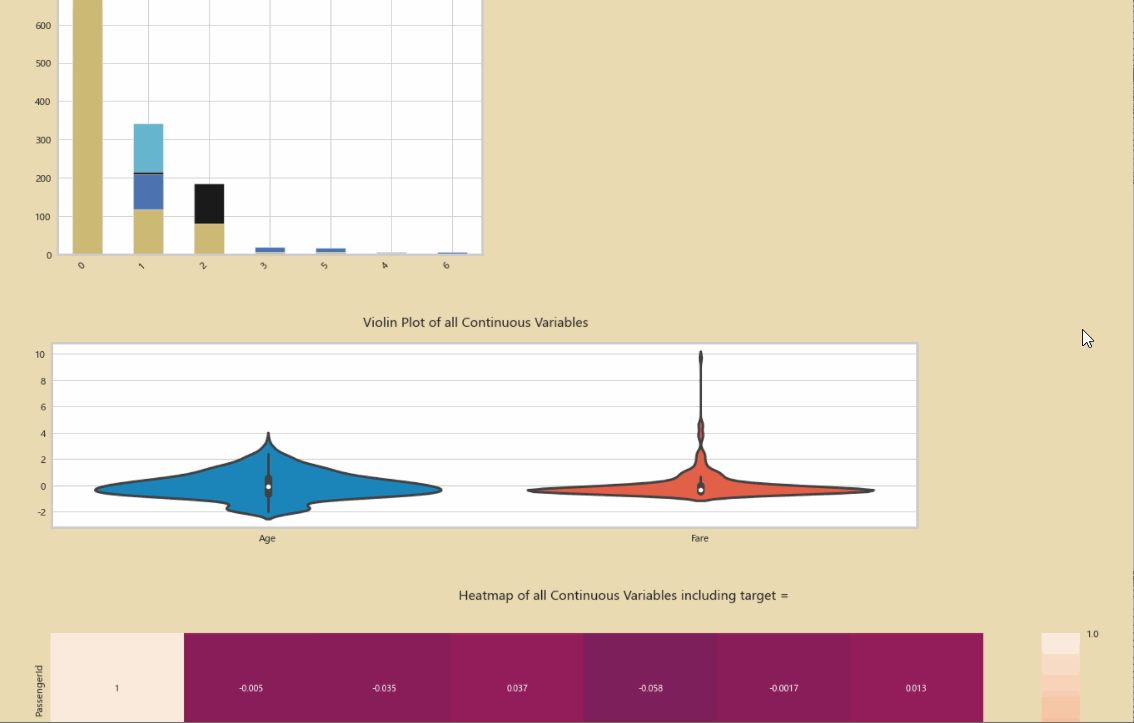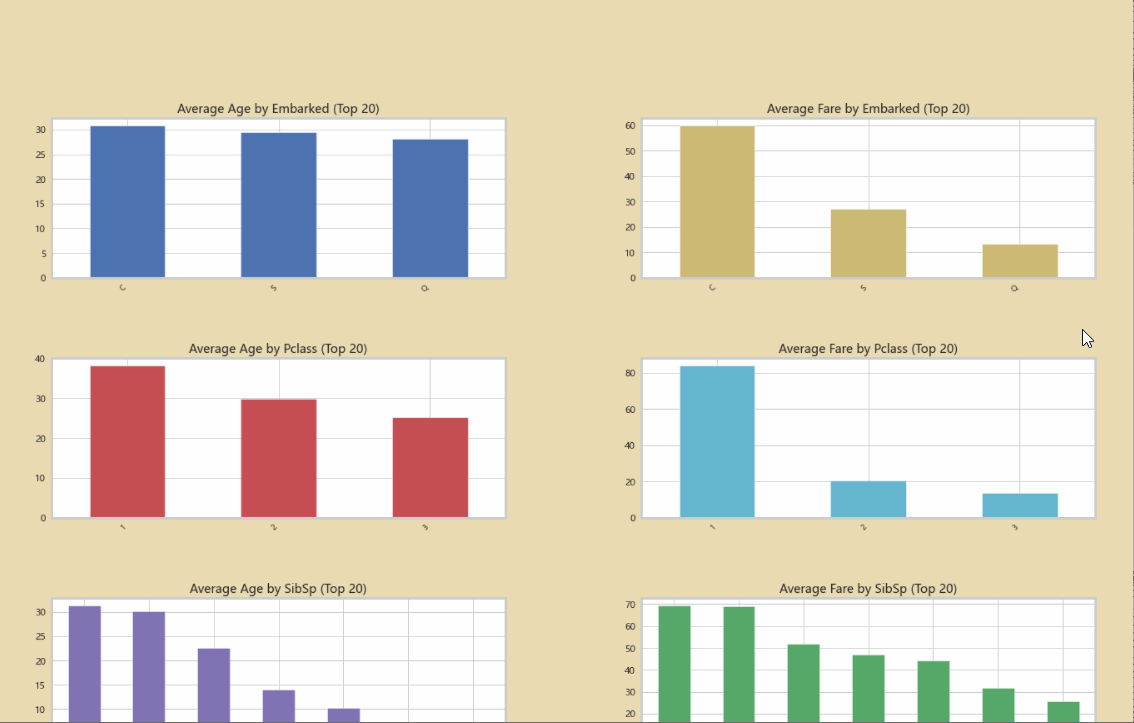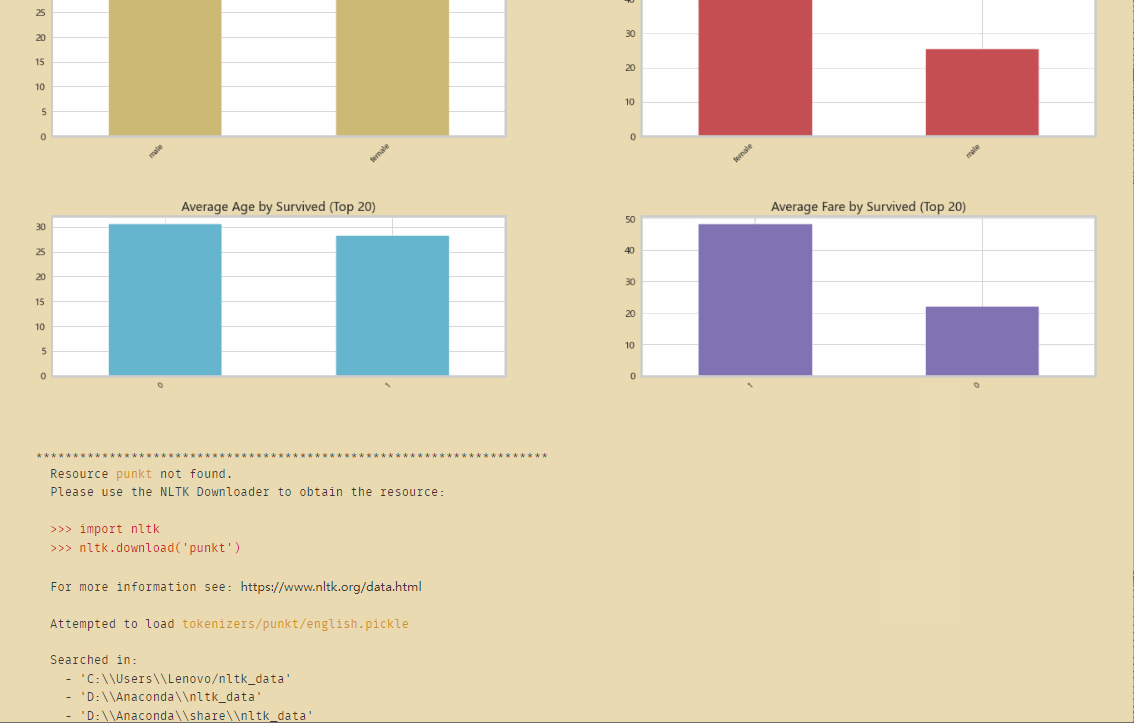
df_survivors=df[df['Survived']==1] # 幸存者
df_nonsurvivors=df[df['Survived']==0] # 遇难者
df_survivors.head()
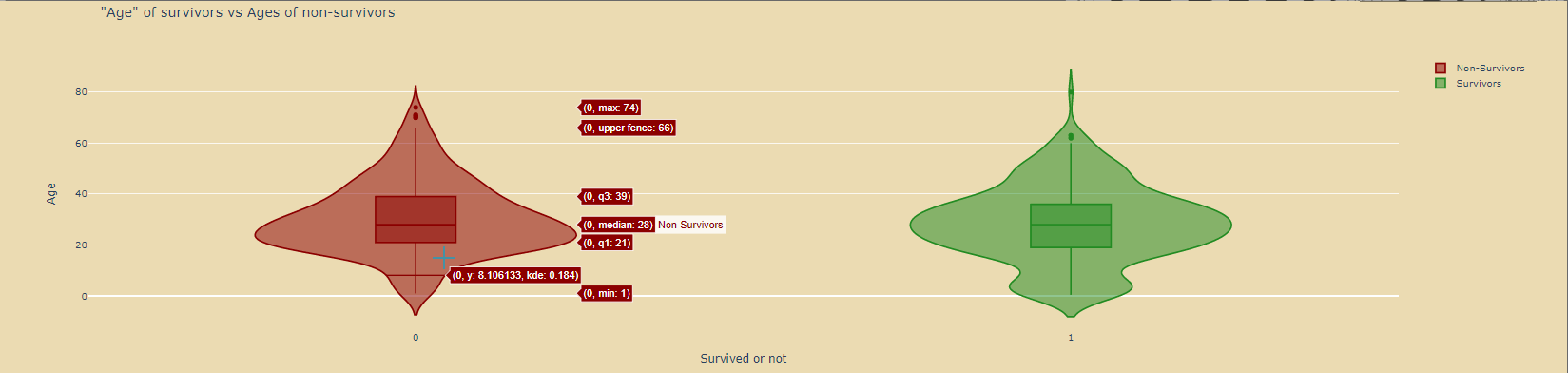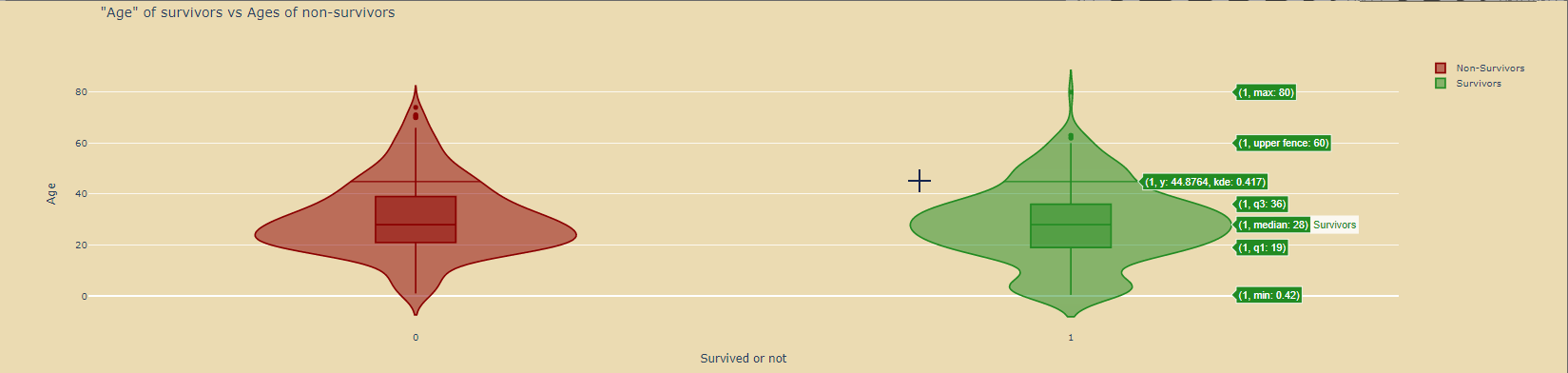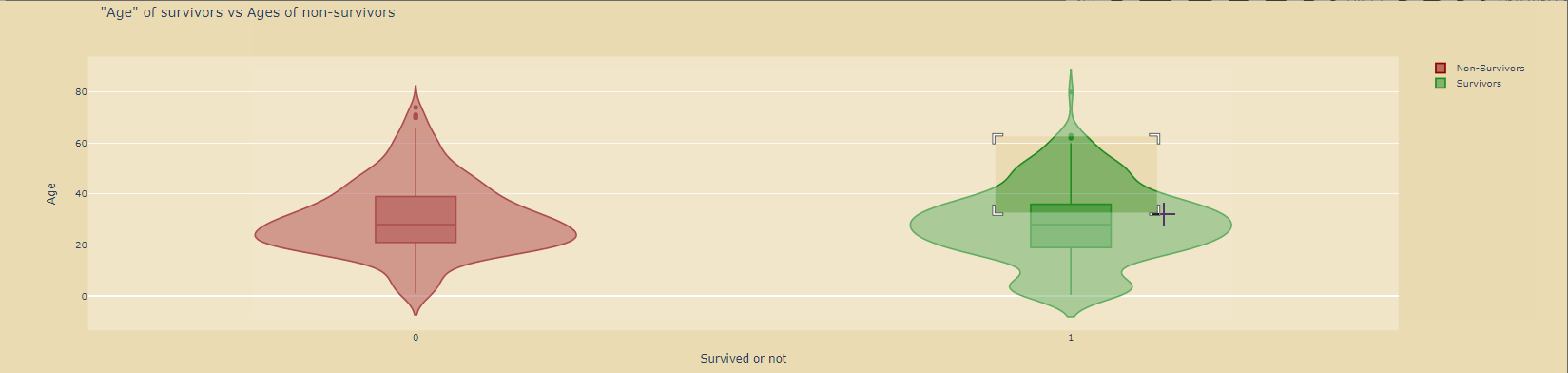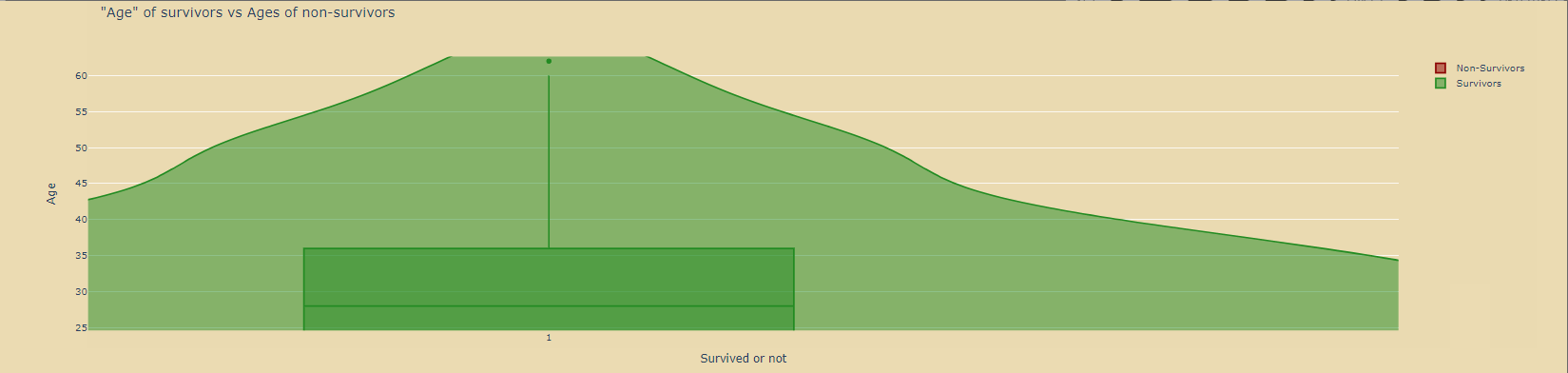
 绘制小提琴图: 绘制小提琴图:
violin_survivors=go.Violin(
y=df_survivors['Age'],
x=df_survivors['Survived'],
name='Survivors',
marker_color='forestgreen',
box_visible=True)
violin_nonsurvivors=go.Violin(
y=df_nonsurvivors['Age'],
x=df_nonsurvivors['Survived'],
name='Non-Survivors',
marker_color='darkred',
box_visible=True)
data=[violin_nonsurvivors,violin_survivors]
layout=go.Layout(
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)',
title='"Age" of survivors vs Ages of non-survivors',
xaxis=dict(
title='Survived or not'
),
yaxis=dict(
title='Age'
)
)
fig=go.Figure(data=data,layout=layout)
fig.show()
二、数据的缺失值处理
train_data=pd.read_csv("titanic.csv") # 学习数据
test_data=pd.read_csv("titanic.csv") # 测试数据
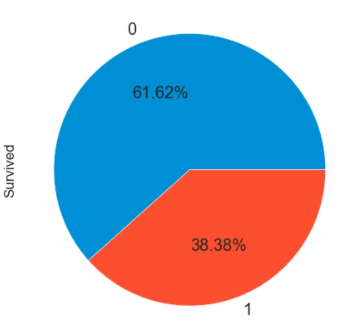
# 幸存者和遇难者的人数比率(0代表遇难者)
train_data['Survived'].value_counts().plot.pie(autopct='%1.2f%%',figsize=(10,7),fontsize=20)
train_data.Embarked[train_data.Embarked.isnull()]=train_data.Embarked.dropna().mode().values # 缺失值使用众数来填充
# 对缺失的舱位号进行填充
train_data['Cabin']=train_data.Cabin.fillna('U0')
# Cabin代表在泰坦尼克号当中的仓位,就类似于学校的宿舍号,C代表最底层的,A代表上层贵族
# 这里把缺失值使用U0填充,没有实际含义
三、使用随机森林处理年龄
# 随机森林算法
from sklearn.ensemble import RandomForestRegressor
# 对缺失年龄进行填充
# 关于年龄的缺失值填充:假设知道你的兄弟姐妹的年龄,但是你的年龄未知,就可以根据你兄弟姐妹的年龄来推算出你的年龄
# 对应Age数据是空值的:其后面有5个数据可以进行参考:'Survived','Fare','Parch','SibSp','Pclass'。
# 对于Age不是空值的数据:根据Age与后面的五个参数'Survived','Fare','Parch','SibSp','Pclass'来构建模型,找到之间的关联,从而预测Age为空值的数据应该是多少
age_df=train_data[['Age','Survived','Fare','Parch','SibSp','Pclass']]
age_df_notnull=age_df.loc[(train_data['Age'].notnull())]
age_df_isnull=age_df.loc[(train_data['Age'].isnull())]
train_data.loc[train_data['Age'].isnull()]
# 有177条数据当中的Age为空,需要我们根据模型填写

# 使用随机森林的方式对年龄数据进行处理
X=age_df_notnull.values[:,1:] # 不要第一行
Y=age_df_notnull.values[:,0]
RFR=RandomForestRegressor(n_estimators=1000,n_jobs=-1)
RFR.fit(X,Y)
predictAges=RFR.predict(age_df_isnull.values[:,1:])
train_data.loc[train_data['Age'].isnull(),['Age']]=predictAges#将年龄是空值的数据填充上对应的我们预测出来的predictAges数据
predictAges
# 177个年龄的预估值,但不是整数,是小数
#array([23.91012463, 33.5790667 , 18.45447222, 34.77706252, 22.82583206,
# 27.92451495, 35.95309143, 22.23480409, 16.72228333, 27.92451495,
# 31.85729512, 34.04484405, 22.23480409, 23.3894125 , 41.26658333,
# 39.41428929, 14.56655619, 27.92451495, 31.85729512, 24.00832619,
# 31.85729512, 31.85729512, 27.92451495, 22.90537022, 30.49815577,
# 31.85729512, 40.55413361, 15.40209733, 31.47466905, 30.98913824,
# 25.62094582, 11.03429057, 24.91276667, 58.21367204, 7.26481346,
# 11.03429057, 31.78719475, 58.8055 , 26.40346667, 40.55413361,
# 22.23480409, 11.03429057, 34.63207227, 27.92451495, 7.26481346,
# 35.81648333, 23.10360556, 26.40346667, 30.98913824, 33.65973333,
# 40.55413361, 40.55413361, 52.66521429, 22.23480409, 35.54409821,
# 58.79858871, 39.41428929, 37.03649841, 22.23480409, 25.87029836,
# 32.00298358, 31.85729512, 29.08850714, 11.03429057, 25.87029836,
# 32.05307143, 27.92451495, 26.5948 , 62.716 , 34.77706252,
# 22.82583206, 22.82583206, 34.04484405, 16.72228333, 22.23480409,
# 35.11293571, 27.92451495, 24.41736964, 7.26481346, 27.92451495,
# 21.30626245, 35.54409821, 31.85729512, 27.92451495, 30.98913824,
# 40.55413361, 26.5948 , 25.17773002, 22.60258333, 31.85729512,
# 42.61237738, 40.55413361, 31.85729512, 35.54409821, 24.41736964,
# 30.98913824, 45.41313571, 35.54409821, 7.26481346, 22.60258333,
# 18.9056746 , 23.70674167, 28.90627937, 42.82544497, 31.85729512,
# 33.46546111, 34.77706252, 26.165255 , 29.62294286, 26.165255 ,
# 7.78515 , 23.7626625 , 31.23990052, 25.67115572, 29.62294286,
# 40.55413361, 31.85729512, 31.85729512, 26.165255 , 22.23480409,
# 21.82594306, 25.97161052, 31.85729512, 29.88929564, 20.06259281,
# 34.77706252, 27.92451495, 38.348 , 27.88305165, 26.40346667,
# 40.55413361, 24.41736964, 39.10006349, 26.78347096, 29.82119675,
# 35.81648333, 27.92451495, 28.05354048, 27.92451495, 28.11530132,
# 41.56493214, 35.54409821, 24.06617853, 29.82119675, 18.21759491,
# 14.56655619, 58.16147475, 27.83794286, 18.21759491, 35.54409821,
# 27.92451495, 27.92451495, 41.32000913, 23.7626625 , 40.377 ,
# 33.01589387, 34.77706252, 40.55413361, 24.41736964, 24.9595 ,
# 40.55413361, 11.03429057, 53.75925 , 39.10006349, 38.86513205,
# 29.75600476, 22.23480409, 26.165255 , 31.85729512, 41.80075152,
# 11.03429057, 43.7314369 , 26.165255 , 11.03429057, 25.0000228 ,
# 27.92451495, 24.9595 ])
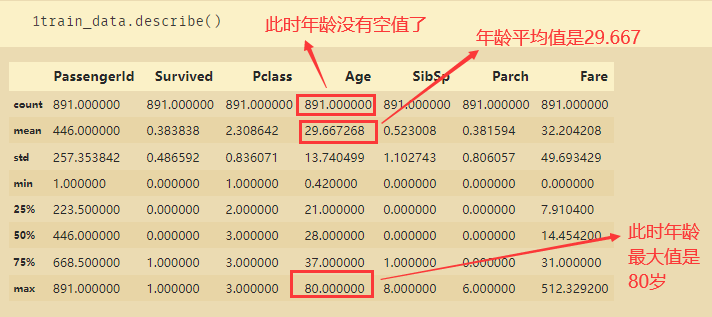
train_data.describe()
四、分析数据之间的关系
1. 性别与生存率的关系
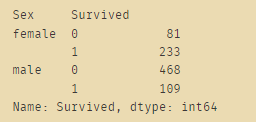
# 04.01 性别与生存率的关系
train_data.groupby(['Sex','Survived'])['Survived'].count()
plt.style.use('ggplot')
plt.title('性别与存活率的关系')
plt.ylabel('存活率')
plt.xlabel('性别')
plt.xticks(rotation=0)
train_data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(figsize=(10,8),fontsize=20)
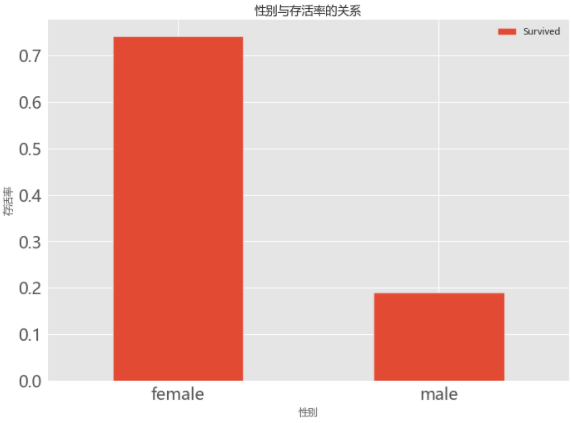
2.舱位等级与生存率的关系
# 04.02 舱位等级与生存率的关系
train_data.groupby(['Pclass','Survived'])['Pclass'].count()
train_data[['Pclass','Survived']].groupby(['Pclass']).mean().plot.bar(figsize=(10,8),fontsize=20)
plt.title('舱位等级与存活率的关系')
plt.ylabel('存活率')
plt.xlabel('1-头等舱 2-二等舱 3-三等舱')
plt.xticks(rotation=0)
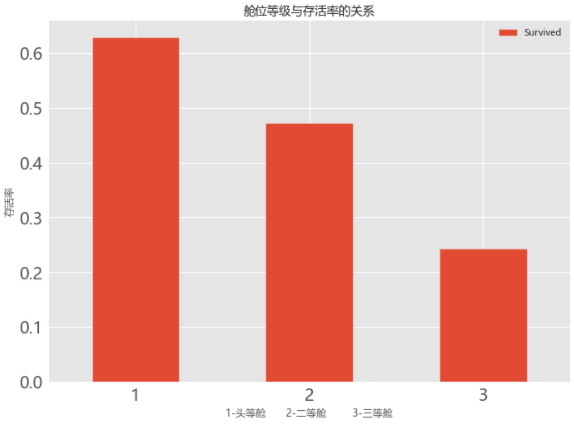
3. 舱位等级,性别和年龄的关系
# 04.03 结合舱位等级,性别和年龄分布的两张小提琴图
fig,ax=plt.subplots(1,2,figsize=(16,10))
sns.violinplot("Pclass","Age",hue="Survived",data=train_data,split=True,ax=ax[0])
ax[0].set_yticks(range(0,100,10))
sns.violinplot("Sex","Age",hug="Survived",data=train_data,split=True,ax=ax[1])
plt.show()
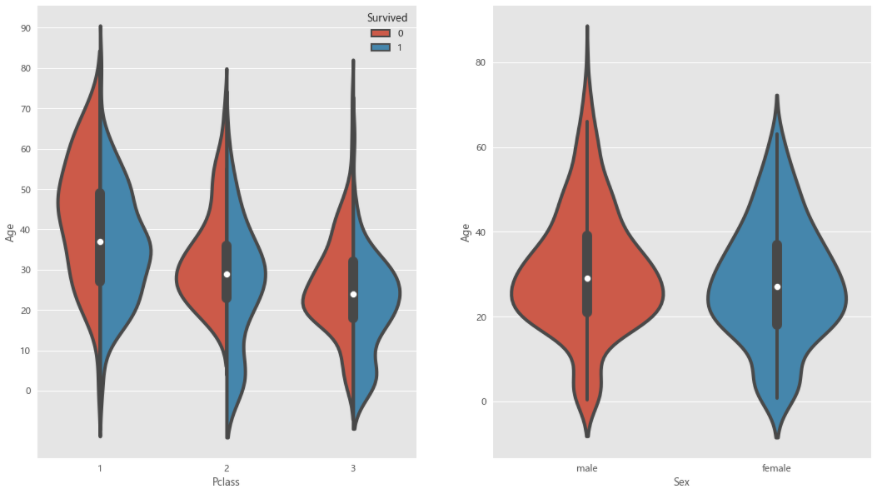
4. 不同年龄阶段的总体分析
# 04.04 年龄的总体分布
plt.figure(figsize=(10,8))
plt.subplot(121)
train_data['Age'].hist(bins=80)
plt.xlabel('年龄')
plt.ylabel('人数')
plt.subplot(122)
train_data.boxplot(column='Age',showfliers=True) # showfliers:显示是否有脱离的异常值
showfliers:显示是否有脱离的异常值 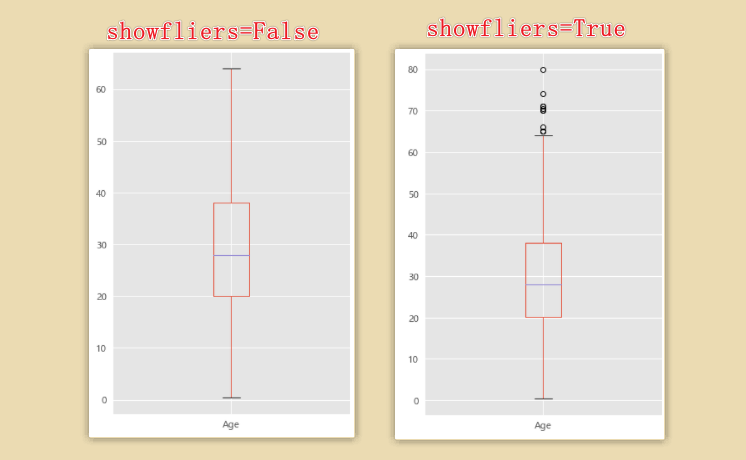 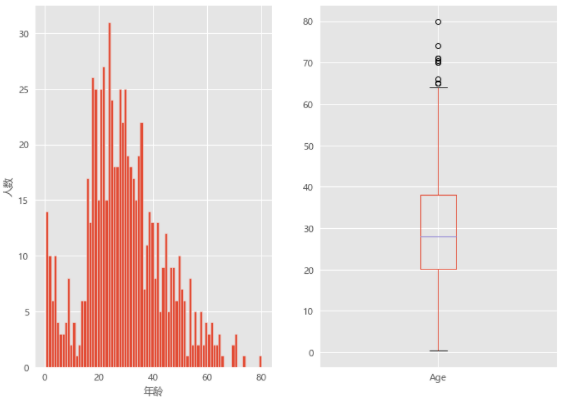
# 04.05 不同年龄下存活分布情况
facet=sns.FacetGrid(train_data,hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Age',shade=True)
facet.set(xlim=(0,train_data['Age'].max()))
facet.add_legend()
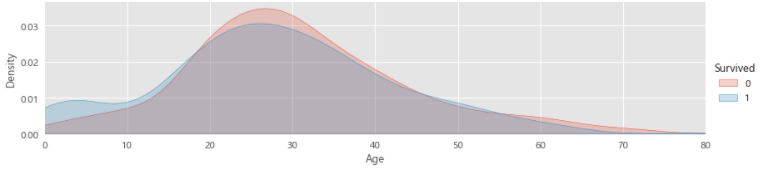
# 04.06 不同年龄下存活分布情况
fig,axis1=plt.subplots(1,1,figsize=(18,4))
train_data['Age_int']=train_data['Age'].astype(int) # 这里年龄出现小数,但是使用.astype(float).astype(int)也不行,会报错。直接使用.astype(int)也不行
average_age=train_data[['Age_int','Survived']].groupby(['Age_int'],as_index=False).mean()
sns.barplot(x='Age_int',y='Survived',data=average_age)
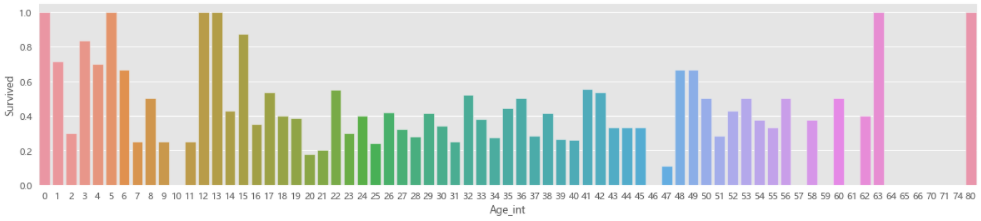
# 不同年龄段下存活情况(对数据的分类统计)
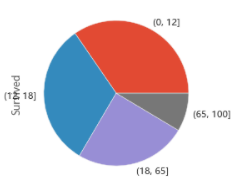
bins=[0,12,18,65,100]
train_data['Age_group']=pd.cut(train_data['Age'],bins)
by_age=train_data.groupby('Age_group')['Survived'].mean()
by_age
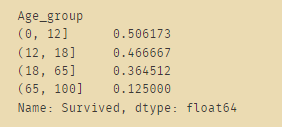
by_age.plot(kind='pie')
5.称谓与存活的关系
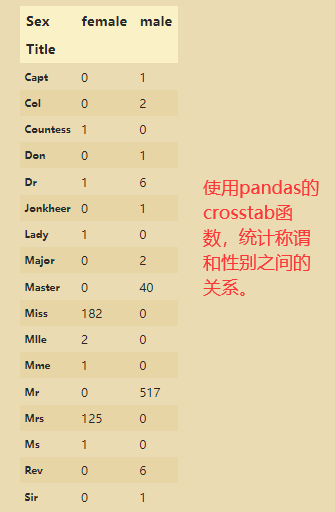
# 04.07 称呼与存活的关系
train_data['Title']=train_data['Name'].str.extract('([A-Za-z]+)\.',expand=False) # 正则表达式,表示把.前面的字母拿到
# str.extract(),可用正则从字符数据中抽取匹配的数据,只返回第一个匹配的数据。
# expand表示是否把series类型转化为DataFrame类型
train_data.Title

pd.crosstab(train_data['Title'],train_data['Sex'])
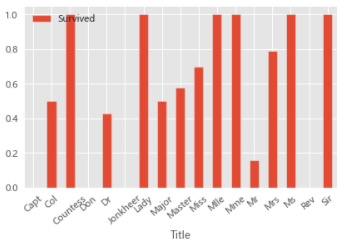
train_data[['Title','Survived']].groupby(['Title']).mean().plot.bar()
plt.xticks(rotation=40)
6.名称长度与存活率的关系
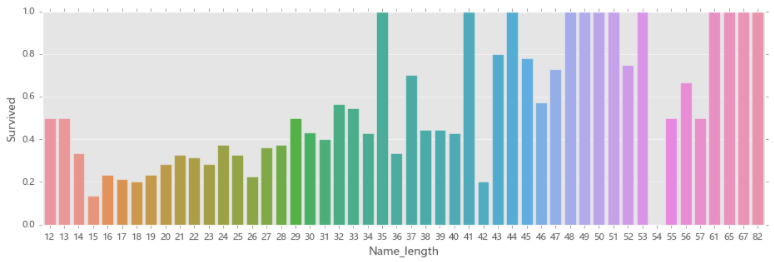
## 04.08 名称的长度对生存率的影响
fig,axis1=plt.subplots(1,1,figsize=(14,4))
train_data['Name_length']=train_data['Name'].apply(len) # 这里年龄出现小数,但是使用.astype(float).astype(int)也不行,会报错。直接使用.astype(int)也不行
name_length=train_data[['Name_length','Survived']].groupby(['Name_length'],as_index=False).mean()
sns.barplot(x='Name_length',y='Survived',data=name_length)
# 由图片知:总体来讲:名字越长的存活率越高,分界线是在35
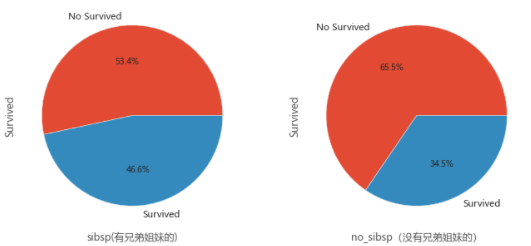
7.亲属与存活率之间的关系
这里涉及到直系亲属以及旁系亲属 •Parch(直系亲友,这里就认为是父母与孩子) •SibSp(旁系,这里就认为是兄弟姐妹)
## 04.09 兄弟姐妹与存活概率(涉及到家族)
sibsp_df=train_data[train_data['SibSp']!=0]
no_sibsp_df=train_data[train_data['SibSp']==0]
plt.figure(figsize=(10,5))
plt.subplot(121)
sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],autopct='%1.1f%%')
plt.xlabel('sibsp(有兄弟姐妹的)')
plt.subplot(122)
no_sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],autopct='%1.1f%%')
plt.xlabel('no_sibsp(没有兄弟姐妹的)')
plt.show()
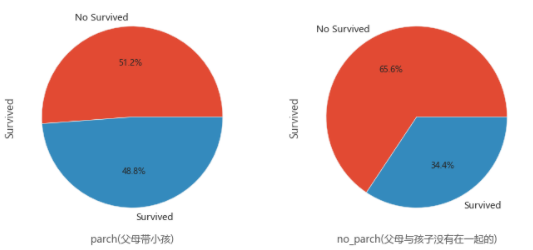
## 04.10 父母子女与存活概率(涉及到家族)
parch_df=train_data[train_data['Parch']!=0]
no_parch_df=train_data[train_data['Parch']==0]
plt.figure(figsize=(10,5))
plt.subplot(121)
parch_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],autopct='%1.1f%%')
plt.xlabel('parch(父母带小孩)')
plt.subplot(122)
no_parch_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],autopct='%1.1f%%')
plt.xlabel('no_parch(父母与孩子没有在一起的)')
plt.show()
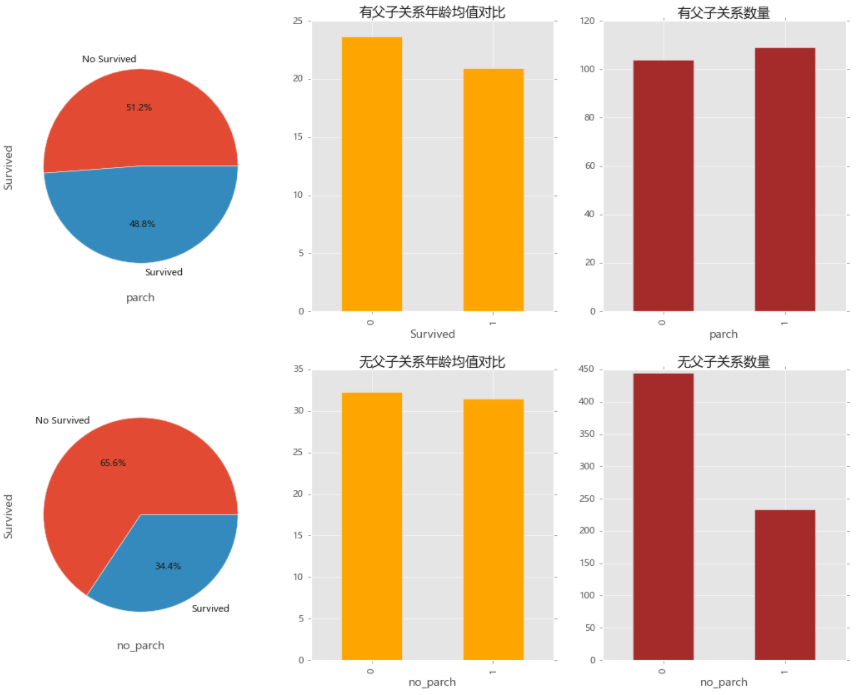
## 04.10 父母子女与存活概率(涉及到家族)
parch_df=train_data[train_data['Parch']!=0]
no_parch_df=train_data[train_data['Parch']==0]
# 父子关系平均年龄与有无父子关系的比例、数量与存活率关系的比较
plt.figure(figsize=(16,12))
plt.rcParams.update({
'font.family': "Microsoft YaHei"})
plt.subplot(2,3,1)
parch_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],autopct='%1.1f%%')
plt.xlabel('parch')
plt.subplot(2,3,2)
parch_df.groupby(['Survived'])['Age'].mean().plot.bar(color='orange',title='有父子关系年龄均值对比')
# plt.xlabel('parch')
plt.subplot(2,3,3)
parch_df.groupby(['Survived'])['PassengerId'].count().plot.bar(color='brown',title='有父子关系数量')
plt.xlabel('parch')
plt.subplot(2,3,4)
no_parch_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],autopct='%1.1f%%')
plt.xlabel('no_parch')
plt.subplot(2,3,5)
no_parch_df.groupby(['Survived'])['Age'].mean().plot.bar(color='orange',title='无父子关系年龄均值对比')
plt.xlabel('no_parch')
plt.subplot(2,3,6)
no_parch_df['Survived'].value_counts().plot.bar(color='brown',title='无父子关系数量')
plt.xlabel('no_parch')
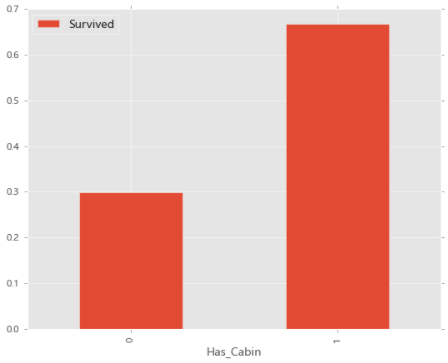
8.舱位类型与存活率之间的关系
Cabin若为空,也就是没有保存舱位信息,则填充为U0。这里可以推断出有舱位类型的存活率较高。对于乘客,我猜想如果是地位较高的人,他们的舱位信息应该能较好的保存。因为地位低的人可能出现逃票的情况,或者他们更不重视自己的船票号码(舱位信息),因此舱位信息保存率比较低。
# 04.11 舱位类型与存活率
train_data['Has_Cabin']=train_data['Cabin'].apply(lambda x:0 if x=='U0' else 1)
train_data[['Has_Cabin','Survived']].groupby(['Has_Cabin']).mean().plot.bar()
9.对不同类型的船舱进行分析
主要目的:练习pd.dummies和pd.factorize的用法
# 04.12 对不同类型的船舱进行分析(涉及到变量转换)主要目的:练习pd.dummies和pd.factorize的用法
import numpy as np
import re
train_data['CabinLetter']=train_data['Cabin'].map(lambda x:re.compile("([a-zA-Z]+)").search(x).group())
# search()可以从任意一个文本里搜索匹配的字符串,即从任何位置里搜索到匹配的字符串
# 从compile()函数的定义中,可以看出返回的是一个匹配对象,它单独使用就没有任何意义,需要和findall(), search(), match()搭配使用。
train_data
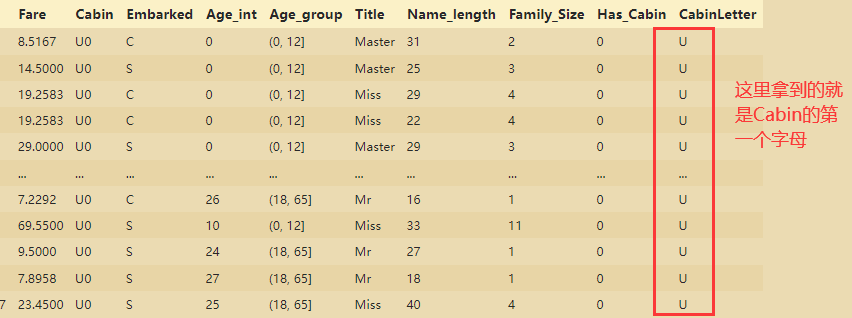
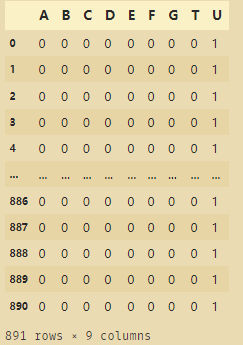
# pd.get_dummies方法
# 使用矩阵的方法显示舱位号
pd.get_dummies(train_data['CabinLetter'])
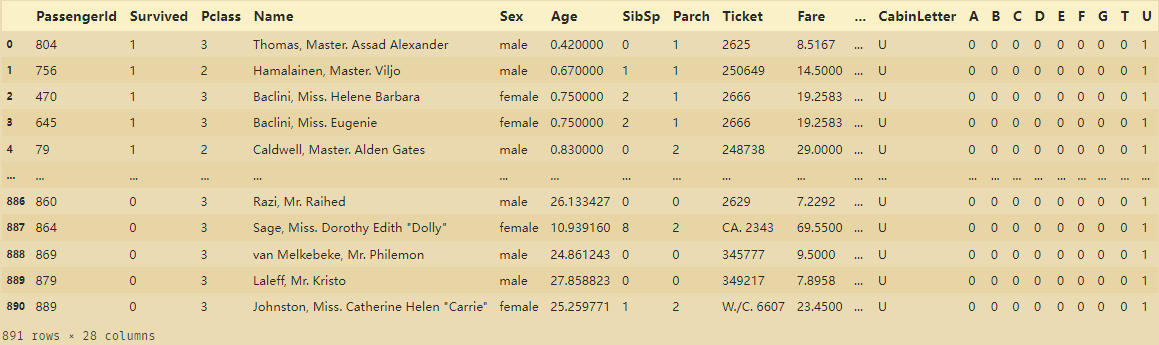
train_data=train_data.join(pd.get_dummies(train_data['CabinLetter'])) # 将两张表进行合并附加
# 这样可以方便哑变量(虚拟变量)与不同数据进行关系之间的探讨
train_data
train_data[['CabinLetter','Survived']].groupby(['CabinLetter']).mean().plot.bar()
不同舱位与存活率之间的关系 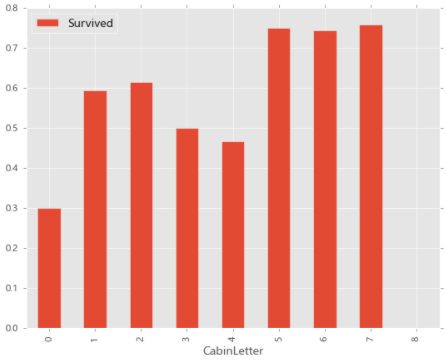
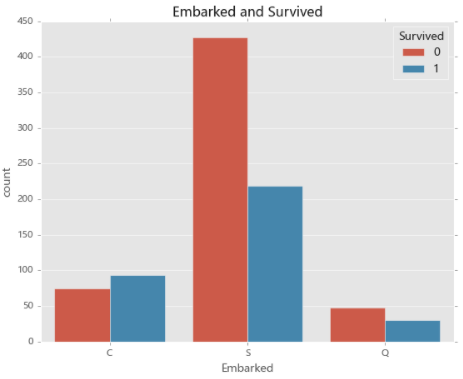
10.出发港口与存活率之间的关系
# 04.13 出发港口与存活率之间的关系
sns.countplot('Embarked',hue='Survived',data=train_data)
plt.title('Embarked and Survived')
|