1.3python网页数据采集 |
您所在的位置:网站首页 › php采集网页数据流程图 › 1.3python网页数据采集 |
1.3python网页数据采集
|
目录:
前言:一,遍历单个域名二,采集整个网站三,通过互联网采集四,拓展:
前言:
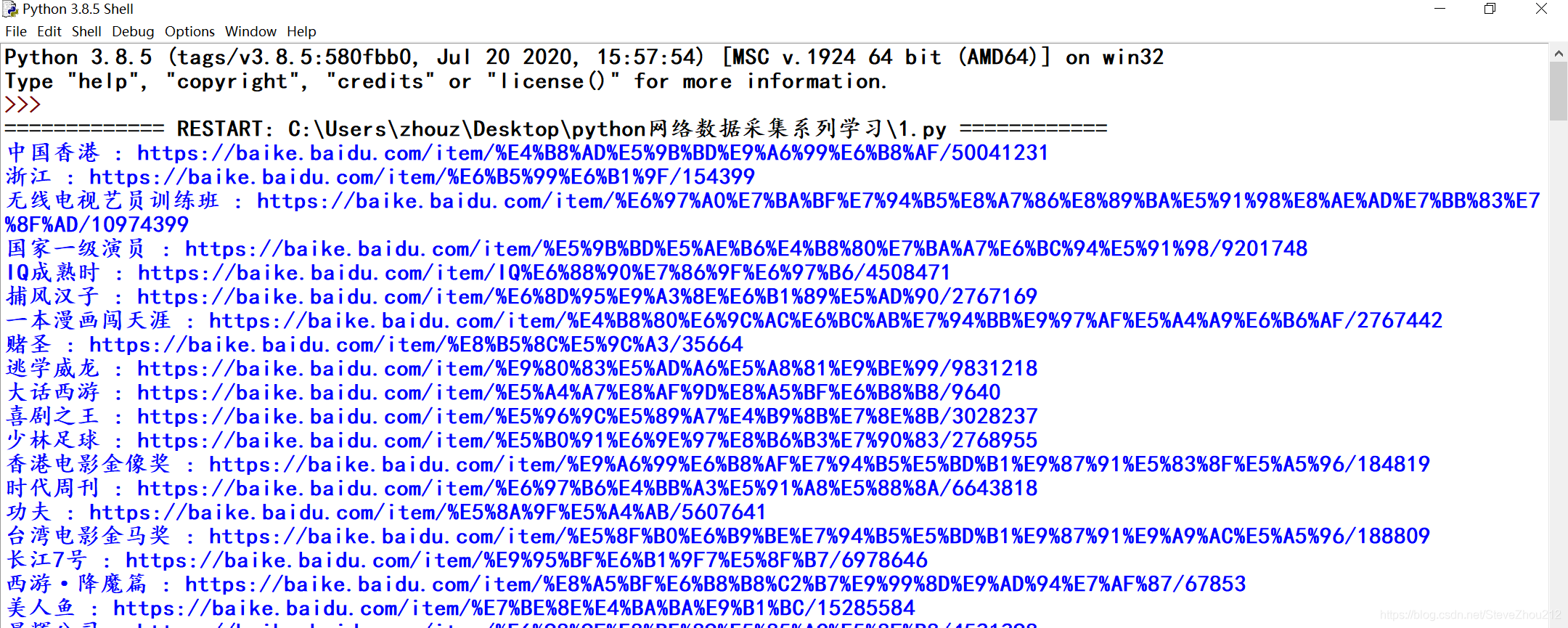
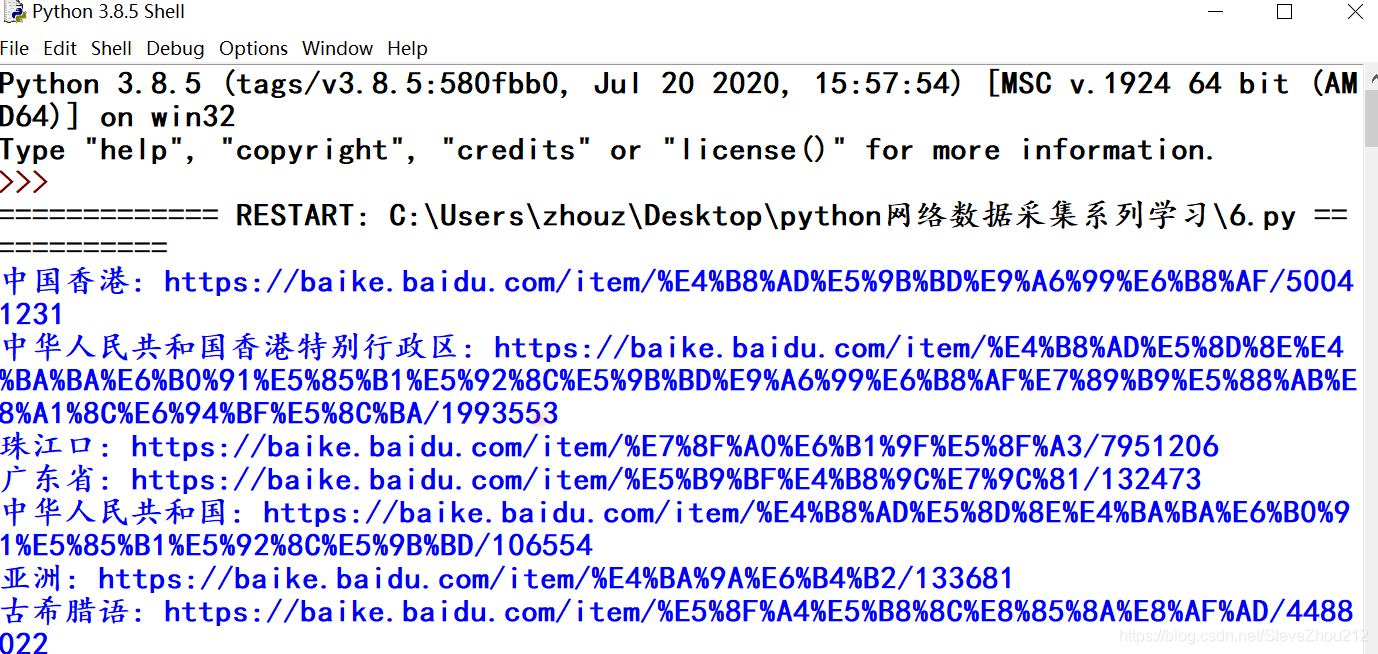
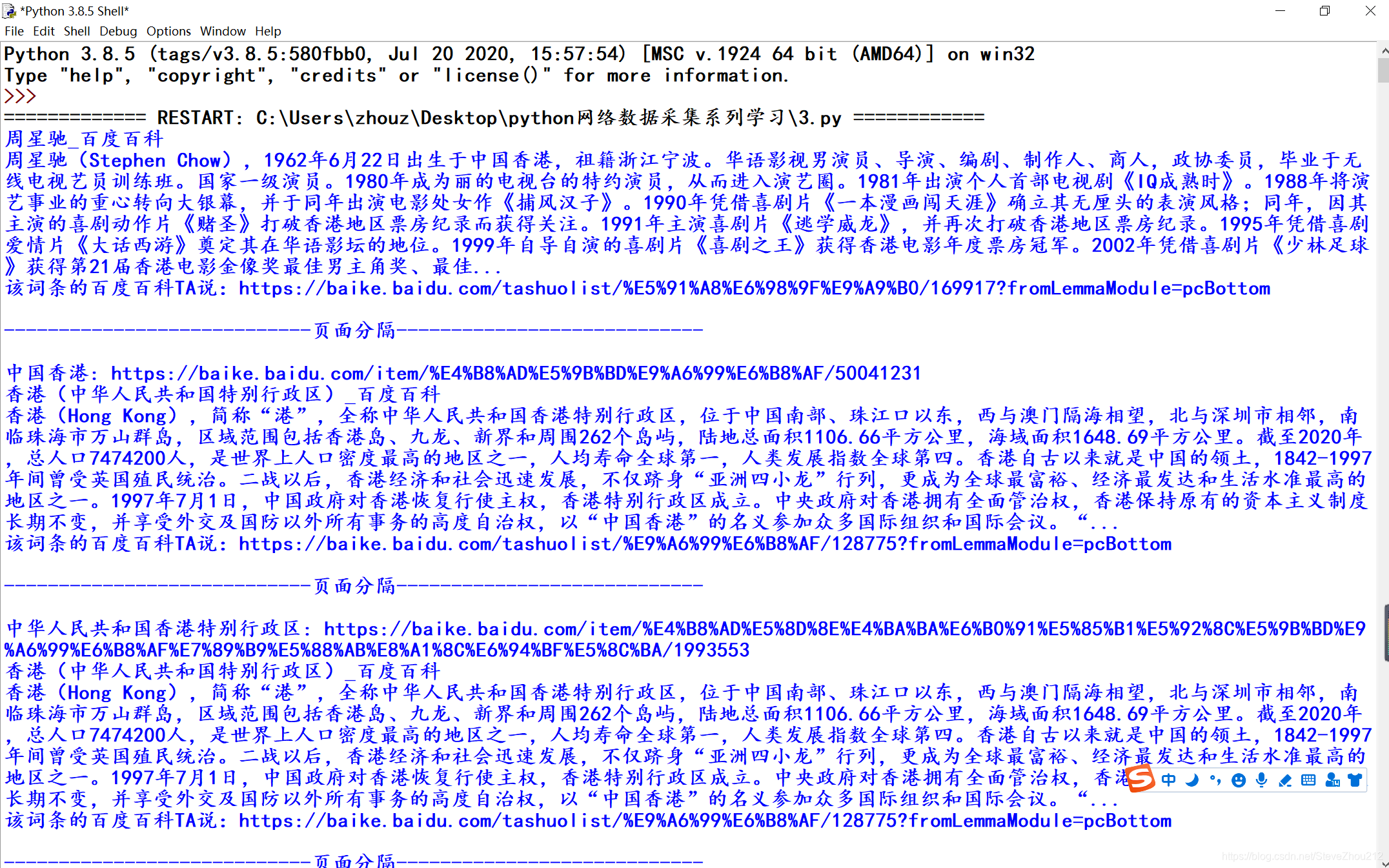
到目前为止,本分栏的例子都只是处理单个静态页面,只能算是人为简化的例子(使用作者专门编写的网站页面)。从现在开始,我们会看到一些现实问题,需要用爬虫遍历多个页面甚至多个网站。 之所以叫网络爬虫(Web crawler)是因为它们可以沿着网络爬行。它们的本质就是一种递归方式。为了找到 URL 链接,它们必须首先获取网页内容,检查这个页面的内容,再寻 找另一个 URL,然后获取 URL 对应的网页内容,不断循环这一过程。 可以重复采集网页,但并不意味着一直都应该这么做。如果爬虫在一个网页数据内,前面的爬虫都可以达到目的了。另外,使用网络爬虫的 时候,你必须非常谨慎地考虑需要消耗多少网络流量,还要尽力思考能不能让采集目标的 服务器负载更低一些。正所谓:网络爬虫,盗亦有道。 一,遍历单个域名即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文· 贝肯(Kevin Bacon) 的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条 之间的连接,凯文· 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一 个总数不超过六条的主题连接起来(包括原来的两个主题)。 比如,周星驰和吴孟达都出现在电影《少林足球》里,因此,根据这个条件,从周星驰到吴孟达的链条主题长度只有 2。 我们将在本节创建一个项目来实现“维基百科六度分隔理论”的查找方法。从实际出发,我们利用的是百度百科词条,也就是说,我们要实现从周星驰的词条页面(https://baike.baidu.com/item/%E5%91%A8%E6%98%9F%E9%A9%B0)开始,经过最少的链接点击次数找到吴孟达的词条页面(https://baike.baidu.com/item/%E5%90%B4%E5%AD%9F%E8%BE%BE/18269)。 准备工作: 从周星驰的百度百科词条的网页源代码(右键查看网页源代码),我们可以发现里面的链接有很多,像图片,广告链接和跳转到其他第三方的页面上(我们不需要的信息),所以我们需要查看(源代码中Crtl+F)所用到的链接与那些无用链接有什么区别和其中链接的特点,可以更好地帮助我们编写关键信息的正则表达式,这样,会过滤掉那些无用的信息,加快我们检索信息的速度,如果不是这样的话,会使我们的编写的过滤代码会很庞大。目标标签形式如下: 吴孟达下面我们开始编写一个具有百度百科里面初步筛选出url链接的爬虫程序吧: from urllib.request import urlopen from bs4 import BeautifulSoup import re url="https://baike.baidu.com/item/%E5%91%A8%E6%98%9F%E9%A9%B0/169917?fr=aladdin" html=urlopen(url) soup=BeautifulSoup(html,"html.parser") for link in soup.findAll("a",{"data-lemmaid":re.compile("[0-9]*")}):#利用标签链接特性编写正则表达式; if "href" in link.attrs: print(link.text,": https://baike.baidu.com"+link.attrs["href"])#将初始数据加工,在前加入百科网址,变成可访问的链接; with open("网址导入.txt","a+") as f: f.write("".join(["https://baike.baidu.com",link.attrs["href"]])+"\n")#文件式储存数据;效果如下: 这就是你观察生成的链接,就会看到你想要的所有词条链接,像李力持” “钟丽缇”和“吴孟达”等等的其他跳转(因为有某些相同的主题条件)链接。 接下来,我们开始写个相对完整的代码,以函数体形式的: from urllib.request import urlopen from bs4 import BeautifulSoup import re import random import datetime random.seed(datetime.datetime.now())#用系统当前时间生成一个随机数生成器; def getLink(url):#爬取url对应网页中链接的函数; html=urlopen("https://baike.baidu.com"+url) soup=BeautifulSoup(html,"html.parser") link=soup.findAll("a",{"data-lemmaid":re.compile("[0-9]*")})#由目标标签特点写出正则表达式; return link #返回一个列表,包含页面所有链接; def printLink(links):#从已有的链接,随机取出一个链接,用前面的函数复用; while len(links)>0: new_url=links[random.randint(0, len(links)-1)].attrs["href"] links=getLink(new_url) for link in links: if "href" in link.attrs: text="".join([link.text,": https://baike.baidu.com",link.attrs["href"]])#用join连接个数据,并储存变量中(方便); print(text) with open("网页跳转链接完整版.txt","a+") as f: f.write(text+"\n")#文件式储存数据; def main(): link=getLink("/item/%E5%91%A8%E6%98%9F%E9%A9%B0")#初始链接(以/item后面的形式) printLink(link) if __name__ =='__main__': main()导入需要的 Python 库之后,程序首先做的是用系统当前时间生成一个随机数生成器。这样 可以保证在每次程序运行的时候,百度百科词条的选择都是一个全新的随机路径。 一个函数 getLink,可以用百度百科词条/item/< 词条名称 > 形式的 URL 链接作为参数, 然后以同样的形式返回一个列表,里面包含所有的词条 URL 链接。 一个函数printLink,以某个起始词条为参数调用 getLink,再从返回的 URL 列表里随机选择 一个词条链接,再调用 getLinks,直到我们主动停止,或者在新的页面上没有词条链接 了,程序才停止运行。 输出效果如下: 伪随机数和随机数种子: 在前面的示例中,为了能够连续地随机遍历百度百科,用 Python 的随机数生成器来 随机选择每一页上的一个词条链接。但是,用随机数的时候需要格外小心。 虽然计算机很擅长做精确计算,但是它们处理随机事件时非常不靠谱。大多数随机数算法都努力创造一种呈均匀分布且难以预测的数据序列, 但是在算法初始化阶段都需要提供随机数“种子”(random seed)。而完全相同的种子 每次将产生同样的“随机”数序列,因此我用系统时间作为随机数序列生成的起点。 这样做会让程序运行的时候更具有随机性。 其实,Python 的伪随机(pseudorandom number)生成器用的是梅森旋转(Mersenne Twister)算法(https://en.wikipedia.org/wiki/Mersenne_Twister),它产生的随机数很难 预测且呈均匀分布,就是有点儿耗费 CPU 资源。真正好的随机数可不便宜! 当然,这里只是简单地构建一个从一个页面到另一个页面的爬虫,要解决(百度百科)六度分隔理论”问题还有一点儿工作得做。我们还应该存储 URL 链接数据并分析数据。以后的内容会有所介绍。 异常处理: 这是我们爬取网站所经常提起的,虽然为了方便起见,我们在这些示例中忽略了大多数异常处理过程,但是要注意问题随时可能发生。例如,百度百科改变了 a 标签的名称而导致代码运行错误。 因此,这些脚本只是作为容易演示的示例而已,但是要真正成 为自动化产品代码,还需要增加更多的异常处理。 二,采集整个网站在前面的内容里,我们实现了在一个网站上随机地从一个链接跳到另一个链接(网页级别)。如果你需要系统地把整个网站按目录分类,或者要搜索网站上的每一个页面,那就 得采集整个网站(级别),那是一种非常耗费内存资源的过程,尤其是处理大型网站时,最合适的 工具就是用一个数据库来储存采集的资源。但是,我们可以掌握这类工具的行为,并不需 要通过大规模地运行它们。 深网和暗网介绍: 深网(deep Web)是网络的一部分,与浅网(surface Web)对立。浅网是互联网上搜索引擎可以抓 到的那部分网络。据不完全统计,互联网中其实约 90% 的网络都是深网。因为谷歌不 能做像表单提交这类事情,也找不到那些没有直接链接到顶层域名上的网页,或者因 为有 robots.txt 禁止而不能查看网站,所以浅网的数量相对深网还是比较少的。 暗网,也被称为 Darknet 或 dark Internet,完全是另一种“怪兽”。它们也建立在已有 的网络基础上,但是使用 Tor 客户端,带有运行在 HTTP 之上的新协议,提供了一个 信息交换的安全隧道。这类暗网页面也是可以采集的,就像你采集其他网站一样,不 过这些内容超出了本书的范围。 和暗网不同,深网是相对容易采集的。实际上,该分栏的python程序都是在采集 那些 Google 爬虫机器人不能获取的深网信息。 遍历整个网站的网络数据采集有许多好处: 1.生成网站地图 ; 2.收集数据 (比如创建一个专业垂直领域的搜索平台,想收集一些文章(故事、博 文、新闻等)。可以创建一个爬虫递归地遍历每个网站,只收集那些 网站页面上的数据。); 一个常用的费时的网站采集方法: 从顶级页面开始(比如主页),然后搜索页面上的所 有链接,形成列表。再去采集这些链接的每一个页面,然后把在每个页面上找到的链接形 成新的列表,重复执行下一轮采集。 很明显,这是一个复杂度增长很快的情形。假如每个页面有 10 个链接,网站上有 5 个页 面深度(一个中等规模网站的主流深度),那么如果你要采集整个网站,一共得采集的网 页数量就是 105 ,即 100 000 个页面。不过,虽然“5 个页面深度,每页 10 个链接”是网 站的主流配置,但其实很少有网站真的有 100 000 甚至更多的页面。这是因为很大一部分 内链都是重复的。 解决方法: 为了避免一个页面被采集两次,链接去重是非常重要的。在代码运行时,把已发现的所有 链接都放到一起,并保存在方便查询的列表里同时,在一个空集合内不断添加元素进去。通过判断条件,只 有“新”链接才会被采集,之后再从页面中搜索其他链接: from urllib.request import urlopen from bs4 import BeautifulSoup import re pages=set()#用于链接去重 def getLink(url): global pages#全局声明 html=urlopen("https://baike.baidu.com"+url) soup=BeautifulSoup(html,"html.parser") for link in soup.findAll("a",{"data-lemmaid":re.compile("[0-9]*")}): if "href" in link.attrs: if link.attrs["href"] not in pages: newpage=link.attrs["href"] print("".join([link.text,": https://baike.baidu.com",newpage])) pages.add(newpage)#增加新的链接 getLink(newpage)#递归 getLink("/item/%E5%91%A8%E6%98%9F%E9%A9%B0/169917")#初始数据接入输出效果: 关于递归的警告 这个警告在软件开发书籍里很少提到,但是我觉得你应该注意:如果递归运 行的次数非常多,前面的递归程序就很可能崩溃。 Python 默认的递归限制(程序递归地自我调用次数)是 1000 次。因为百度 百科的网络链接浩如烟海,所以这个程序达到递归限制后就会停止,除非你 设置一个较大的递归计数器,或用其他手段不让它停止。 对于那些链接深度少于 1000 的“普通”网站,这个方法通常可以正常运行, 一些奇怪的异常除外。另外,增加了一些条件,对可能导致无限循环的部分进行检查,确保那些 URL 不是这么荒谬。如果不去检查这些问题,爬虫很快就会崩溃。 收集整个网站数据 下面我们开始高级一点内容,就是采集网页上的一些数据,创建一个爬虫来收 集页面标题、正文的第一个段落,以及讨论页面的链接(如果有的话)这些信息。以百度百科词条里的内容作为要采集的数据: 首先,我们先打开几个百度百科词条页面,同时打开网页源代码页面,观察(用Ctrl+F搜寻相关信息)页面标题、正文的第一个段落,以及讨论(TA说)页面的链接的位置和标签规则特点: • 词条的标题:以title标签的文本形式储存标题; 周星驰_百度百科•词条的大概内容介绍:meta标签,并且有name="description"属性,content属性里的内容; •链接TA说:a标签,并且带有属性,class=“tashuo-more”,里面href属性里面的内容; 解读词条背后的知识调整前面的代码,我们就可以建立一个爬虫和数据收集(至少是数据打印)的组合程序: from urllib.request import urlopen from bs4 import BeautifulSoup import re pages=set() def getLink(url): global pages html=urlopen("https://baike.baidu.com"+url) soup=BeautifulSoup(html,"html.parser") try: print(soup.title.get_text())#BeautifulSoup对象标签类,用get_text()获得文本内容; print(soup.find("meta",{"name":"description"}).attrs["content"]) if soup.find("a",{"class":"tashuo-more"}).attrs["href"] !=None:#有些词条页面并没有,会返回None,要跳过出现该问题; print("".join(["该词条的百度百科TA说:https://baike.baidu.com",soup.find("a",{"class":"tashuo-more"}).attrs["href"],"\n"])) except AttributeError: print("页面某些属性缺失!可以忽略该部分内容!") for link in soup.findAll("a",{"data-lemmaid":re.compile("[0-9]*")}): if "href" in link.attrs: if link.attrs["href"] not in pages: newpage=link.attrs["href"] print("页面分隔".center(60,"-")+"\n")#用于识别不同的页面内容 print("".join([link.text,": https://baike.baidu.com",newpage])) pages.add(newpage)#增加新的链接 getLink(newpage)#递归 getLink("/item/%E5%91%A8%E6%98%9F%E9%A9%B0/169917")输出效果: 因为我们不可能确保每一页上都有所有类型的数据,所以每个打印语句都是按照数据在页 面上出现的可能性从高到低排列的。也就是说, 标题标签会出现在每一页上(只要能 识别,无论哪一页都有),所以我们首先试着获取它的数据。正文内容会出现在大多数页 面上(除了文件页面),因此是第二个获取的数据。“TA说”按钮只出现在标题和正文内容 都已经获取的页面上,但不是所有这类页面上都有,所以我们最后打印这类数据。 不同模式应对不同需求 在一个异常处理语句中包裹多行语句显然是有点儿危险的。首先,你没法儿 识别出究竟是哪行代码出现了异常。其次,如果有个页面没有前面的标题内 容,却有其他按钮,那么由于前面已经发生异常,后面的按钮 链接就不会出现。但是,这种按照网站上信息出现(操作成功)的可能性高低进行排序的 方法对许多网站都是可行的,偶而会丢失一点儿数据,只要保存详细的日志 就不是什么问题了。 你可能还发现在到目前为止所有的例子中,我们都没有“收集”那些“打印”出来的数 据。显然,命令行里显示的数据是很难进一步处理的。需要用到后面的信息储存 和数据库创建的内容。 三,通过互联网采集爬虫案例: 谷歌在 1994 年成立的时候,就是两个斯坦福大学的毕业生用一个陈旧的服务器和一个 Python 网络爬虫。网络爬虫位于许多新式的网络技术领域彼此交叉的中心地带,而它 不需要一个大型数据仓库。要实现任何跨站的数据分析,只要构建出可以从互联网 上无数的网页里解析和储存数据的爬虫(一般的数据库也行或其他简易的数据存储方式)。 这次我们开始编写一个程序,采集和跳转页面上的所有链接(内链和外链)。相比 我们之前做的单个域名(网站)采集,互联网采集要难得多——不同网站的布局迥然不同。这就意 味着我们必须在要寻找的信息以及查找方式上都极具灵活性。 准备工作: • 我要收集哪些数据?这些数据可以通过采集几个已经确定的网站(永远是最简单的做法) 完成吗?或者我的爬虫需要发现那些我可能不知道的网站吗? • 当我的爬虫到了某个网站,它是立即顺着下一个出站链接跳到一个新网站,还是在网站 上呆一会儿,深入采集网站的内容? • 有没有我不想采集的一类网站?我对非英文网站的内容感兴趣吗? • 如果我的网络爬虫引起了某个网站网管的怀疑,我如何避免法律责任? 我们可以把几个灵活的 Python 函数组合起来就可以实现不同类型的网络爬虫,用不超过 50 行代码就 可轻松地写出来: from urllib.request import urlopen from urllib.parse import urlparse from bs4 import BeautifulSoup import re import datetime import random import urllib.request pages = set()#定义空集合,为后面程序拓展功能:链接去重 random.seed(datetime.datetime.now()) def inLink(soup,url): inurl = urlparse(url).scheme + "://" + urlparse(url).netloc inlinks=[] for link in soup.findAll("a",href=re.compile("^(/|.*"+inurl+")")):#找出内链,但是条件还不完整; if link.attrs['href'] is not None: if link.attrs['href'] not in inlinks: if (link.attrs['href'].startswith("/")):#判断链接开头是否有“/”,如果有,返回True; inlinks.append(inurl + link.attrs['href'])#拼凑出完整的内链链接; else: inlinks.append(link.attrs['href']) return inlinks def outLink(soup,outurl):#外链处理函数 outlinks=[] for link in soup.findAll("a",href=re.compile("^(http|www)((?!"+outurl+").)*$")):#找出以http/www开头,不含outurl的链接; if link.attrs['href'] is not None: if link.attrs['href'] not in outlinks:#判断是否为新链接 outlinks.append(link.attrs['href']) return outlinks def getLink(url):#爬虫链接处理函数:对外链和内链分别处理,并获取对应链接 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}#由于网站有反爬,要添加请求头; a=urllib.request.Request(url=url, headers=headers) html= urlopen(a).read() soup=BeautifulSoup(html,"html.parser") outlinks=outLink(soup,urlparse(url).netloc)#先对网页中的外链处理,注意变量outlink和函数outLink的命名区别; if len(outlinks) == 0: print("外链采集为空!!!") inlinks = inLink(soup,url) return random.choice(inlinks) else: return random.choice(outlinks) def processLink(url):#爬虫处理主体函数 links=getLink(url) print("通过互联网随机爬取的链接:"+links)#打印获取的链接; processLink(links)#通过爬取网页得到的链接再处理,递归; processLink("https://www.zb06.com/")#调用,并赋予初始链接
网站首页上并不能保证一直能发现外链。这时为了能够发现外链,就需要用一种类似前面 案例中使用的采集方法,即递归地深入一个网站直到找到一个外链才停止。 总结: 其实,利用互联网来采集数据,还是比较难的,首先,我们的程序代码还比较初级,但是还能爬取到我们可以想要的内链和外链(假定网站包含的话);其次,网站数据结构以及数据形式有所不同,导致我们不能有效的检索到像内链里还包含域名的情况下,我们还与网站域名拼接,会造成爬取崩溃;另外,网络连接和环境复杂;还有,我们为了入门需要省略了不少检查语句,其实,检查语句很多时候是网络爬虫的重中之重,我们在实际开发中不能忽略他。值得注意的是,本人挑选几个初始网站来做测试,由于爬取频繁,被当成黑客攻击了,所以测试时,不要过多爬取,以免造成网站服务器困扰和触碰相关法律限制。 我们还可以再在该代码的基础上增加更好地检索和匹配功能,使得爬虫运行出错的情况更少,后面会更新的,敬请关注! 写代码之前拟个大纲或画个流程图是很好的编程习惯,这么做不仅可以为你后期处理节省 很多时间,更重要的是可以防止自己在爬虫变得越来越复杂时乱了分寸。 处理网页重定向: 重定向(redirect)允许一个网页在不同的域名下显示。重定向有两种形式: 1.服务器端重定向,网页在加载之前先改变了 URL; 2.客户端重定向,有时你会在网页上看到“10 秒钟后页面自动跳转到……”之类的消息, 表示在跳转到新 URL 之前网页需要加载内容。 本节处理的是服务器端重定向的内容。更多关于客户端重定向的细节,通常用 JavaScript 或 HTML 来实现,请看后面的内容。 服务器端重定向,你通常不用担心。如果你在用 Python 3.x 版本的 urllib 库,它会自 动处理重定向。不过要注意,有时候你要采集的页面的 URL 可能并不是你当前所在页 面的 URL。 四,拓展:urlparse解析url 正则表达式中如何添加变量 startsWith()方法 网络爬虫urllib.error.HTTPError: HTTP Error 403: Forbidden的问题方法 最后,文中如有不足,敬请批评指正!!! |


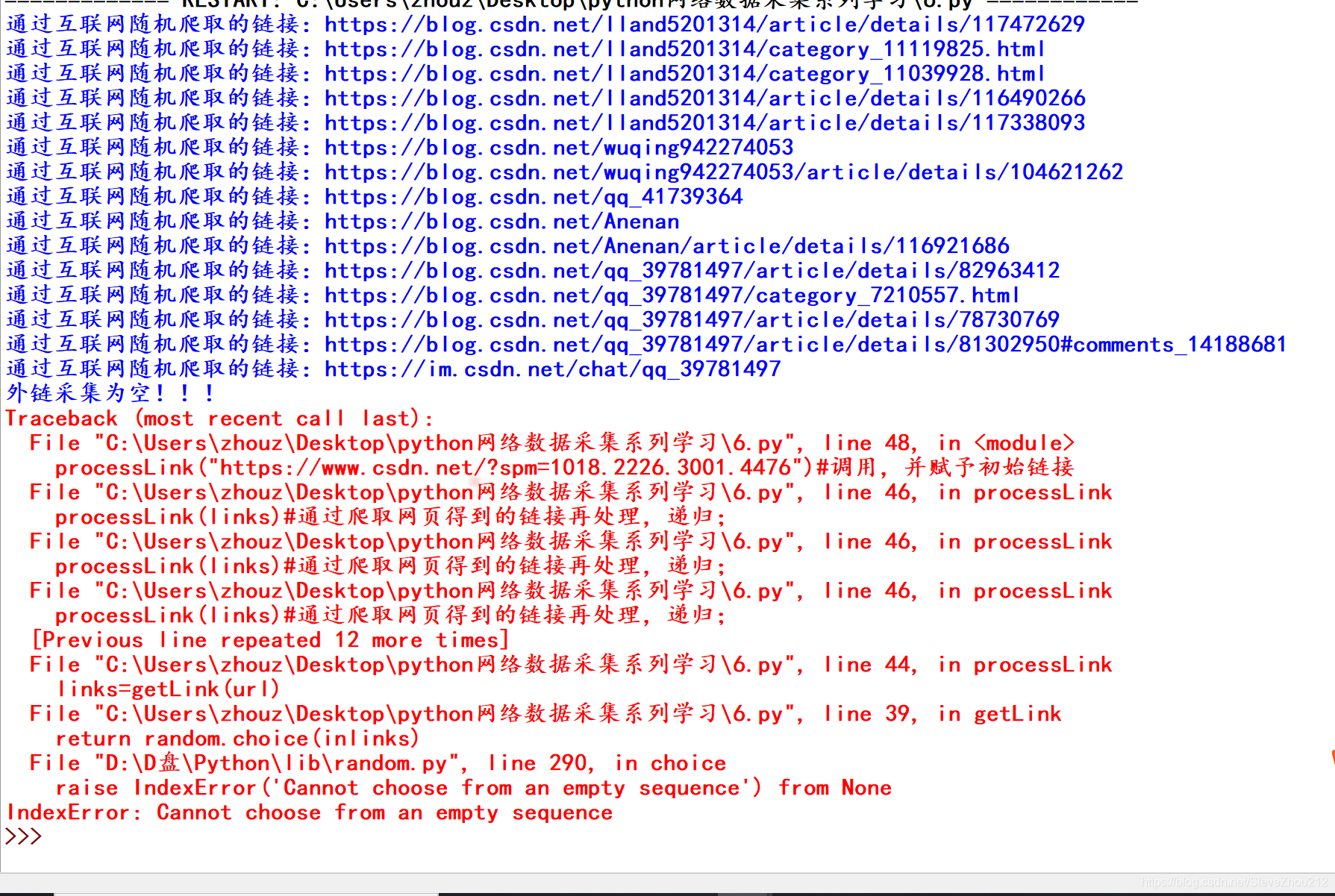
 但是运行最后,出现了递归次数警告限制,停止了程序运行,如下所示:
但是运行最后,出现了递归次数警告限制,停止了程序运行,如下所示: 


【本文地址】
今日新闻 |
推荐新闻 |