Jetson Nano上部署PaddleDection 原生预测方法经验分享 |
您所在的位置:网站首页 › paddlex安装 › Jetson Nano上部署PaddleDection 原生预测方法经验分享 |
Jetson Nano上部署PaddleDection 原生预测方法经验分享
|
Jetson Nano上部署飞桨PaddleDection 原生预测方法经验分享 为了写好这篇经验分享,以下的所有步骤,我又“心情愉悦”地操作了一遍。步骤操作很简单,但是很耗费时间,所以同学们要有耐心。 一、环境准备(1)安装Jetson Nano官方系统Jetson Nano Developer Kit SD Card Image 版本JP 4.4.1,官方镜像已经预装了OpenCV、CUDA、CUDNN、TensorRT等依赖环境。(推荐迅雷下载,速度很快)。  (2)准备SD卡(至少32G,最好大于这个存储空间,因为编制Paddle之后,基本没有空间了) (3)将利用balenaEtcher软件将镜像烧写至SD卡,然后装上SD卡开始装系统吧。  #Apt源更改:https://zhuanlan.zhihu.com/p/69849653 #中文输入法配置:https://blog.csdn.net/u013617229/article/details/89645829 #Python源更改:https://blog.csdn.net/sinat_21591675/article/details/82770360 #jetson-stats:Jetson 状态查看工具,用于查看设备的资源占用情况以及许多软件的版本信息,例如OpenCV、CUDA、TensorRT。 安装方法: sudo apt-get install python3-pip sudo -H python3 -m pip install jetson-stats(需要重启) 使用指令:jtop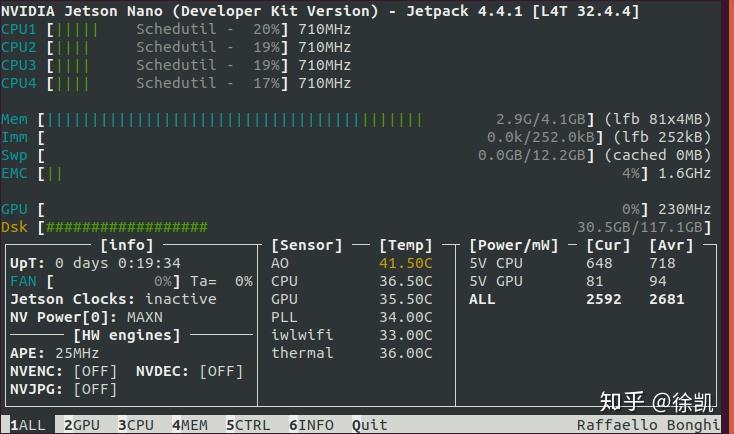 # 散热风扇:https://blog.csdn.net/qq_41063142/article/details/101158967 (不要执行wget获取博主提供的脚本,因为下载下来的是乱码) #开启jetson clock sudo nvpmodel -m 0 && sudo jetson_clocks二、源码编译1) 根据飞桨教程先编译安装nccl(https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/inference_deployment/inference/build_and_install_lib_cn.html),过程很缓慢,编译后会把编译生成的几个依赖文件自动拷贝到系统。编译结果有点像出错一样,怪怪的,如果没有出现“error”,请不要理会,进行下一步。 git clone https://github.com/NVIDIA/nccl.git cd nccl make -j4 sudo make install NCCL编译 NCCL编译2) 增加交换空间 sudo fallocate -l 10G /var/swapfile(大小自己确定,编译完成后可以删除释放,值得注意的是,32Gtf卡设置5G大小即可,因为编译后基本没有空间了。) sudo chmod 600 /var/swapfile sudo mkswap /var/swapfile sudo swapon /var/swapfile sudo bash -c 'echo "/var/swapfile swap swap defaults 0 0" >> /etc/fstab' 编译后可以通过以下方法删除释放: sudo swapoff /var/swapfile sudo rm sudo /var/swapfile 删除 /etc/fstab 中的"/var/swapfile swap swap defaults 0 0"3)准备Paddle源码 git clone -b release/2.0-beta https://gitee.com/paddlepaddle/Paddle.git(我使用码云的库,下载快) 非必须:源码依赖很多第三方库,详见Paddle/cmake/external/*.cmake。里面涉及的库大多来自github,需要把库导入码云平台,然后将*.cmake 库的链接替换掉。这样下载时就快的很多了 。可以先编译,遇到问题回来修改对应的cmake文件  4) 配置CUDA的环境变量 export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH5)编译工具链的准备 sudo apt-get install unrar swig patchelf (jetson nano 本身可能已经预装了)6) paddle 源码编译 cd Paddle mkdir build cd build cmake .. \ -DWITH_CONTRIB=OFF \ -DWITH_MKL=OFF \ -DWITH_MKLDNN=OFF \ -DWITH_TESTING=OFF \ -DCMAKE_BUILD_TYPE=Release \ -DON_INFER=ON \ -DWITH_PYTHON=OFF \ -DWITH_XBYAK=OFF \ -DWITH_NV_JETSON=ON sudo nvpmodel -m 0 && sudo jetson_clocks jtop (新终端打开状态监视器,实时观察资源利用情况) ulimit -n 2048 (建议每次编译前都执行一遍,用于设置支持同时打开的文件数量,编译最后阶段会打开很多文件) make -j4 或 make(因为编译时间很长。。。,因为4G内存(不包含交换内存)实在不够,4线程编译会因内存不足卡死,约2-3次卡死,卡死后ctrl+c或reboot,然后换成make,跳过卡死的阶段) 编译完成后,预测库位于/Paddle/build/fluid_inference_install_dir目录下面,目录结构及version.txt内容如下:  三、PaddleDection-Deploy预测部署 三、PaddleDection-Deploy预测部署1) 准备模型 在AI-STUDIO中利用PaddleDection的模型导出工具tools/export_model.py导出模型(使用方法参见PaddleDection手册),此处以PPYOLO模型示例 。导出模型之前需要更改模型配置文件/configs/ppyolo/ppyolo_reader.yml中的TestReader:image_shape: [3, 608, 608] ,target_size: 608中的尺寸,为自己的目标输入尺寸。 python tools/export_model.py -c configs/ppyolo/ppyolo.yml \ --output_dir=./inference_model \ -o weights=https://paddlemodels.bj.bcebos.com/object_detection/ppyolo.pdparams 模型链接地址在gitthub上 模型链接地址在gitthub上2) jetson nano 上准备预测的demo 程序 (1)创建工程 mkdir paddle_project(将PaddleDetection/deploy/cpp/下所有文件拷贝到paddle_project)(2)修改脚本scripts/build.sh(可以完全替换,Opencv已经预装,在这里不要使用官方脚本,否则会重复安装Opencv。同时Opencv的路径在该脚本中也不必指出) # 是否使用GPU(即是否使用 CUDA) WITH_GPU=ON # 是否使用MKL or openblas,TX2需要设置为OFF WITH_MKL=OFF # 是否集成 TensorRT(仅WITH_GPU=ON 有效) WITH_TENSORRT=ON # TensorRT 的include路径 TENSORRT_INC_DIR=/usr/include/aarch64-linux-gnu # TensorRT 的lib路径 TENSORRT_LIB_DIR=/usr/lib/aarch64-linux-gnu # Paddle 预测库路径 PADDLE_DIR=/home/hanyun/Paddle/build/fluid_inference_install_dir # Paddle 的预测库是否使用静态库来编译 # 使用TensorRT时,Paddle的预测库通常为动态库 WITH_STATIC_LIB=OFF # CUDA 的 lib 路径 CUDA_LIB=/usr/local/cuda/lib64 # CUDNN 的 lib 路径 CUDNN_LIB=/usr/lib/aarch64-linux-gnu # 以下无需改动 rm -rf build mkdir -p build cd build cmake .. \ -DWITH_GPU=${WITH_GPU} \ -DWITH_MKL=${WITH_MKL} \ -DWITH_TENSORRT=${WITH_TENSORRT} \ -DTENSORRT_LIB_DIR=${TENSORRT_LIB_DIR} \ -DTENSORRT_INC_DIR=${TENSORRT_INC_DIR} \ -DPADDLE_DIR=${PADDLE_DIR} \ -DWITH_STATIC_LIB=${WITH_STATIC_LIB} \ -DCUDA_LIB=${CUDA_LIB} \ -DCUDNN_LIB=${CUDNN_LIB} \ make echo "make finished!"(3)修改CMakeLists.txt (1)注释掉 #if (NOT DEFINED OPENCV_DIR OR ${OPENCV_DIR} STREQUAL "") #message(FATAL_ERROR "please set OPENCV_DIR with -DOPENCV_DIR=/path/opencv") #endif() (2)设置OpenCV路径 if (WIN32) include_directories("${PADDLE_DIR}/paddle/fluid/inference") include_directories("${PADDLE_DIR}/paddle/include") link_directories("${PADDLE_DIR}/paddle/fluid/inference") find_package(OpenCV REQUIRED PATHS ${OPENCV_DIR}/build/ NO_DEFAULT_PATH) else () find_package(OpenCV REQUIRED)# PATHS /usr/lib/aarch64-linux-gnu/cmake/opencv4 NO_DEFAULT_PATH if(OpenCV_FOUND OR OpenCV_CXX_FOUND) message(STATUS "OpenCV library status:") message(STATUS " version: ${OpenCV_VERSION}") message(STATUS " libraries: ${OpenCV_LIBS}") message(STATUS " include path: ${OpenCV_INCLUDE_DIRS}") else() message(FATAL_ERROR "Could not found OpenCV!") return() endif() include_directories("${PADDLE_DIR}/paddle/include") link_directories("${PADDLE_DIR}/paddle/lib") endif () (3)设置TensorRT路径 if (WITH_TENSORRT AND WITH_GPU) include_directories("${TENSORRT_INC_DIR}/") #link_directories("${TENSORRT_LIB_DIR}/lib") link_directories("${TENSORRT_LIB_DIR}/") endif()(4)更改yaml-cpp的编译,默认每次都会重新编译该插件,消耗时间很长。按照以下步骤更改后只会在初次编译。(可选步骤) CMakeLists.txt修改: include_directories("${CMAKE_SOURCE_DIR}/ext/yaml-cpp/src/ext-yaml-cpp/include")#CMAKE_CURRENT_BINARY_DIR link_directories("${CMAKE_SOURCE_DIR}/ext/yaml-cpp/lib")#CMAKE_CURRENT_BINARY_DIRcmake/yaml-cpp.cmake修改: URL /home/hanyun/myProject/yaml-cpp.zip #https://bj.bcebos.com/paddlex/deploy/deps/yaml-cpp.zip下载下来保存在本地 -DCMAKE_LIBRARY_OUTPUT_DIRECTORY=${CMAKE_SOURCE_DIR}/ext/yaml-cpp/lib #CMAKE_BINARY_DIR更改为CMAKE_SOURCE_DIR -DCMAKE_ARCHIVE_OUTPUT_DIRECTORY=${CMAKE_SOURCE_DIR}/ext/yaml-cpp/lib #CMAKE_BINARY_DIR更改为CMAKE_SOURCE_DIR PREFIX "${CMAKE_SOURCE_DIR}/ext/yaml-cpp" #CMAKE_BINARY_DIR更改为CMAKE_SOURCE_DIR3)更改源码 因为jetson nano默认安装的OpenCV版本为4.1.1,API接口与百度官方提供的接口不一样,需要做稍微的调整,否则编译报错,可根据下面进行替换。 mainc.c中, CV_CAP_PROP_FRAME_WIDTH - cv::CAP_PROP_FRAME_WIDTH CV_CAP_PROP_FRAME_HEIGHT - cv::CAP_PROP_FRAME_HEIGHT CV_CAP_PROP_FPS - cv::CAP_PROP_FPS CV_IMWRITE_JPEG_QUALITY - cv::IMWRITE_JPEG_QUALITYvoid PredictVideo(const std::string& video_path,PaddleDetection::ObjectDetector* det)中mp4文件的打开接口的输入参数修改如下: int codec=cv::VideoWriter::fourcc('m','p','4','v');//增加的 // Create VideoWriter for output cv::VideoWriter video_out; std::string video_out_path = "output.mp4"; video_out.open(video_out_path.c_str(), codec,//替换这里 0x00000021 video_fps, cv::Size(video_width, video_height), true);object_detector.cc,LoadModel函数中更改TensorRT的设置: config.EnableTensorRtEngine( 1 |
【本文地址】
今日新闻 |
推荐新闻 |