GAN,DCGAN,cGAN,pix2pix,CycleGAN,原理简单理解 |
您所在的位置:网站首页 › p2p技术原理简单理解 › GAN,DCGAN,cGAN,pix2pix,CycleGAN,原理简单理解 |
GAN,DCGAN,cGAN,pix2pix,CycleGAN,原理简单理解
|
GAN
GAN,Generative Adversarial Networks, 意为对抗生成网络,原始的GAN是一种无监督学习方法,通过使用‘对抗’的思想来学习生成式模型,一旦训练完成后可以全新的数据样本。 GAN原理 我们可以把GAN理解为一个生成数据的工具,实际GAN可以应用到任何类型的数据。 GAN包括连个网络,生成网络G(Generrater) 和 判别网络 D(Discriminator)。 G负责生成图片,它接收一个随机的噪声z,通过该噪声生成图片,将生成图片标记为G(z) D负责判别一张图片是不是‘真实的’。它的输入是x,x代表一张图片,输出D(x)表示x为真实图片的概率,如果为1,代表是真实图片的概率为100%,而输出为0,则代表图片不可能是真实的图片。 GAN基本思想:‘博弈’ 生成网络G的目标是尽可能生成真实的图片去欺骗判别网络D。而D的目标是尽量把G生成的图片和真实的图片区分开来。这就构成了‘博弈’的思想。 当我们训练过后,在最理想的状态下,生成网络G可以生成非常逼真的图片,以假乱真的程度。而判别网络很难判别G生成的图片是不是真实的。即D(G(z))=0.5。此时我们就得到了一个生成式的模型G,它可以用来生成图片。 用数学化的语言来描述‘博弈’的过程
真实的图片有着自己的数据分布。我们网络G学习的过程,可以理解为学习真实图片的数据的分布的过程。 我们输入一个随机的噪声z,通过网络G,生成一个图片G(z)。当这个图片的数据分布越接近真实的图片的分布的时候, 这个生成的图片G(z)就越像真实的图片。 损失函数 我们可以看到图片中的损失函数V(D,G)有两个部分,第一部分为判别网络D的部分,我们可以理解为从训练数据中我们取出一张真实的图片x,把x 输入到网络种。D(x)越大就代表D的判别能力越好。由此看出我们判别网络D期望我们的损失函数V(D,G)的值变大。 第二部分为生成网络的部分,我们在生成网络中输入一个随机的噪声z,网络生成一张图片G(z),D(G(z))为判别网络对生成图片的判别结果,当D(G(z))的值越大的时候,就表示我们G生成的图片越逼真,此时 ln(1-D(G(z)))越小,损失函数V(D,G)越小。这是我们生成网络期望的。 使用梯度下降法优化损失函数 1在优化的过程中我们可以,每对D更新一次参数,便接着再更新一次G。 有时也可以多次优化D的参数,再优化一次G的参数。 哪种方式要根据实际情况考虑。 2我们判别网络D期望损失函数更大所以在更新参数的时候是加上梯度的方式,生成网络G则与之相反。 3当我们训练完成后,生成网络G是一个生成式网络,可以输入噪声z来生成图片。 DCGANDCGAN意为深度卷积对抗网络。在GAN基础上增加深度卷积网络结构,专门生成图像样本。在GAN中并没有对D,C的具体结构做出任何限制,在DCGAN中对D和G采用了较为 特殊的结构,以便对图片进行有效的建模。 判别网络D和生成网络的结构都是卷积神经网络。 判别网络D,输入的是一张图片,输出的是这张图片是真实图片的概率。 生成网络G ,输入的是一个100维的噪声向量,输出的是一张图片。 DCGAN在有一些优化的细节 1不采用任何池化层,在D中用带有步长的卷积来代替池化层,避免了池化带来的数据上信息的丢失。 2使用Batch Normalization 加速收敛。 3生成网络G除了最后一层,每一层都使用了Relu激活函数。最后一层使用的激活函数是tanh函数。由于网络G最后一层输出的是图片。 图片的像素值是0~255,如果使用Relu激活函数,输出的数值会较大。而tanh函数的范围是(-1,1) 数值较小。 而且经过简单的变换就可以得到像素值。即加一后乘127.5。 4网络D都是用Leaky Relu作为激活函数。 可以看下面这个博客了解Leaky Relu https://blog.csdn.net/qq_23304241/article/details/80300149 DCGAN的一些应用 1生成图片
LSUN是关于卧室场景的图片,DCGAN训练完成后就可以生成图片了。 2利用DCGAN做图像表示的‘插值’
也可以利用DAGAN做图像表示的运算 cGANGAN的限制,GAN可以生成新的样本丹斯我们无法控制样本的类型,比如生成数字但是不能指定生成的是什么数字。这是由于我们输入的只有一个随机的噪声z。 cGAN就可以做到这点:可以指定生成新样本的类型。 cGAN即条件对抗生成网络,它为生成器,判别器,都额外加入了一个条件y,即我们希望生成的标签。 生成器G,输入一个噪声z,一个条件y,输出符合这个条件的图像G(z|y) 判别器D,输入一张图像x,一个条件y,输出该图像在该条件下的真实概率D(x|y) cGAN网络结构
cGAN损失函数
图像翻译 我们都知道机器翻译是把一段中文翻译成英文。在图像领域也有类似的图像翻译。比如把街景,建筑,文星图像的标示图转换成真实的图片。或者白天黑天的转换。轮廓转换为实物等。
pix2pix模型结构
1我们向生成器G输入一个鞋子轮廓图x,生成了一个鞋子图片G(x)。我们将生成的图片G(x)和输入的轮廓图x即标签。输入到判别器D中.判别器输出是真的鞋子图片的概率。 2我们输入一张真实的鞋子的图片y 和一个标签x D判别是不是真的鞋子图片。 3在这个机构中我们的网络G不会考虑噪声的存在,即使输入噪声也会被忽略,所以这里没有输入噪声。 4损失函数的改变 在实验中发现我们除了使用cGAN的损失函数,我们还可以生成图像与真实图像之间的损失,假设(x,y)是一个真实的图片对。这里假设x是真实的图片,而y是轮廓图。那么生成图片与真实图片之间的L1损失为 L1=||x-G(y)|| 5PatchGAN PatchGAN的思想是在判别一个图片是否是真实的图片时,不直接输入整张图片,而是把图片划分为N*N个小格子输入到判别网络中,我们平均这几次的输出结果作为判别的结果。 这样可以加快计算以及加快收敛。 6pix2pix的本质还是cGAN只是在图片翻译问题上面对D和G做了一些细节上面的调整。 CycleGAN在cGAN中我们可以通过把输入的条件的值设置为数字1来生成一个数字1的图片。 在pix2pix中我们输入鞋子的轮廓图 生成鞋子的图片,或者输入 一个房子的标注图 生成一个房子的图片。 但是再cGAN和pix2pix 的样本都是要求 严格成对的 比如 一个真实的鞋子图片 和 一个 鞋子的轮廓图。 pix2pix要求训练数据必须在X空间和Y空间严格成对。 然而现实中这样成对的样本往往是比较困难获得的。 CycleGAN不必使用成对的样本也可以进行图像翻译。 图像翻译可以理解为学习一个映射,这个映射可以将源空间X中的图片转换成目标空间Y空间中的图片。 CycleGAN原理 算法的目标是学习从空间X到空间Y的映射,设这个映射为F。它对应着GAN中的生成器。F可以将X空间的图片x 转化为Y空间中的图片F(x)。此外还需要使用GAN开判别生成图是否是真实图片。 到此一步,根据生成器和判别器构成是损失是与GAN损失是基本相同的。
添加循环损失一致性 但是只使用上面这个损失是无法训练的。原因在于没有成对的数据,映射F可以将所有x都映射为Y空间的同一张图片,是损失无效化。 对此,提出循环损失一致性。 我们假设一个映射G,可以把Y空间的图片y转换为X中的图片G(y)。Cycle同时学习F和G两个映射,并且要求 F(G(y))≈ y ,以及 G(F(x))≈ x。 这表示我们有空间X转换到空间Y的图片,还可以转换回来。 由此定义循环一致性损失为:
同时我们也使用GAN损失来判别生成的图片是否为真实。 则损失函数变为: 来源与《21个项目玩转深度学习》中GAN相关的知识,是知识的摘要和自己的理解,希望多多交流。 |





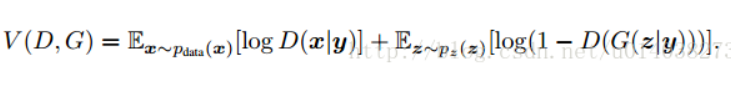


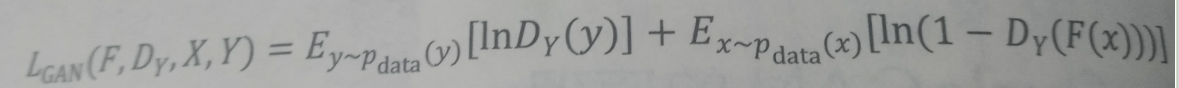
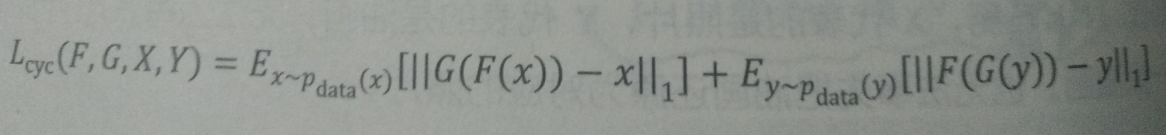
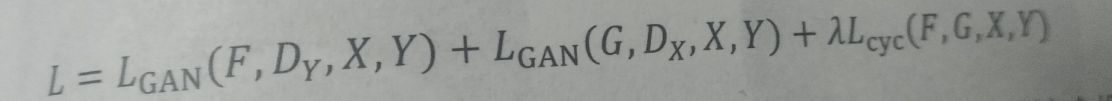
【本文地址】