创建OSS外部表 |
您所在的位置:网站首页 › oss原理 › 创建OSS外部表 |
创建OSS外部表
|
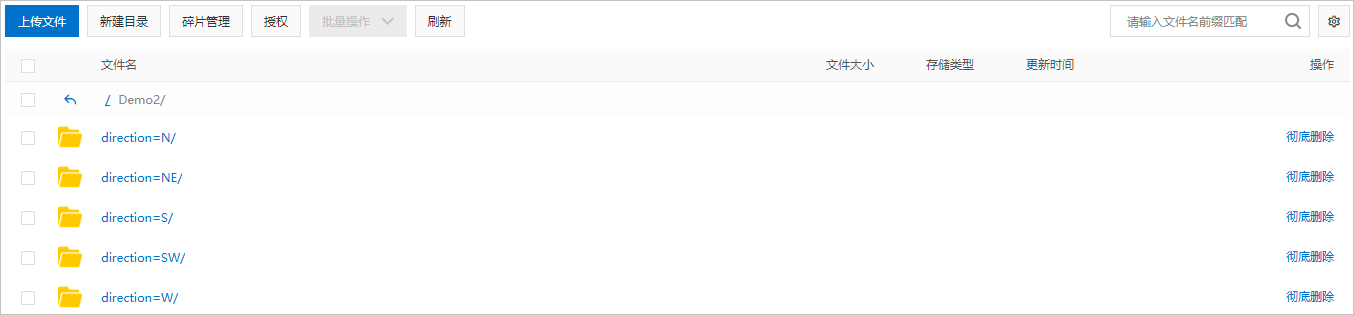
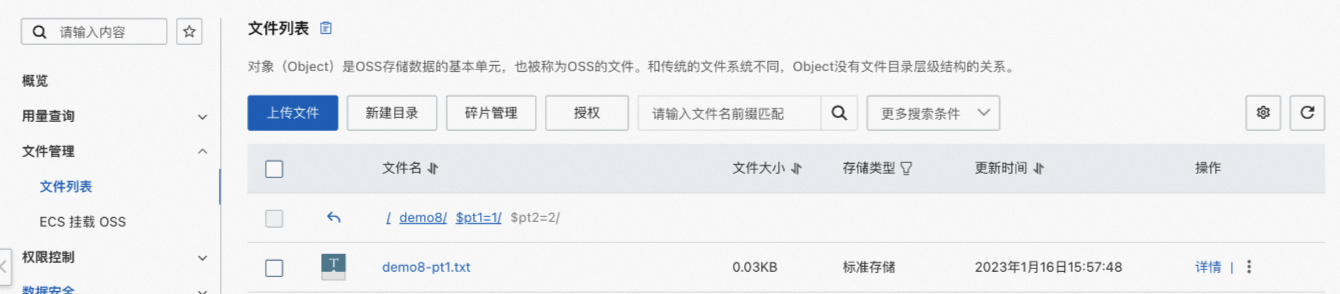
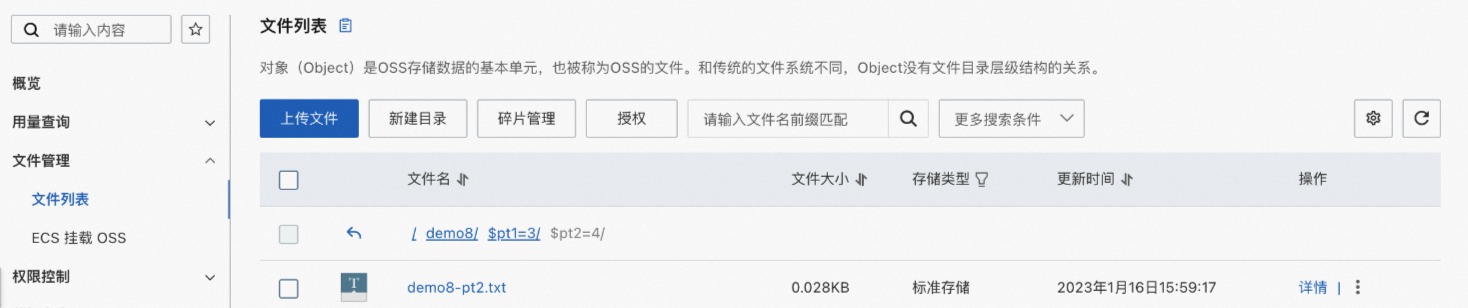
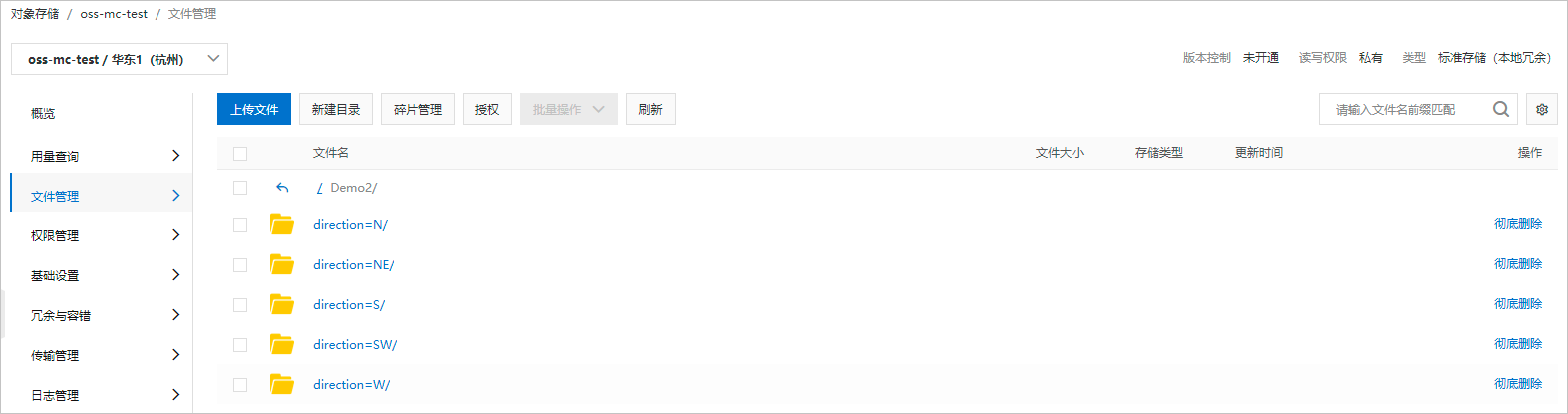
背景信息 对象存储服务OSS是一种海量、安全、低成本、高可靠的云存储服务,适合存放任意类型的数据文件。当您需要使用MaxCompute读取存储在OSS目录中的数据或需要将MaxCompute项目中的数据写入OSS目录时,可以在MaxCompute项目中创建OSS外部表建立与目录的映射关系。 OSS外部表包含分区表和非分区表两种类型,实际需要创建哪种类型的表,主要取决于OSS中数据文件的存储路径格式。当数据文件以分区路径方式存储时,需要创建分区表;否则创建非分区表。更多读取分区数据信息,请参见读取以分区方式存储的OSS数据。 前提条件在创建OSS外部表前,请确认执行操作的账号已满足如下条件: 已授予访问OSS的权限。 更多授权信息,请参见OSS的STS模式授权。 已具备在MaxCompute项目中创建表(CreateTable)的权限。 更多表操作权限信息,请参见MaxCompute权限。 注意事项在使用OSS外部表时,您需要注意: 对于不同格式的数据文件,创建OSS外部表语句仅个别参数设置有出入,请您仔细阅读创建OSS外部表语法及参数说明,确保创建符合实际业务需求的外部表,否则读取OSS数据或将数据写入OSS操作会执行失败。 OSS外部表只是记录与OSS目录的映射关系。当删除OSS外部表时,不会删除映射的OSS目录下的数据文件。 如果OSS数据文件类型为归档文件,需要先解冻文件。更多解冻操作,请参见解冻文件。 使用限制OSS外部表不支持cluster属性。 操作入口MaxCompute支持您在如下平台创建OSS外部表。 创建方式 平台 基于MaxCompute SQL创建OSS外部表 MaxCompute客户端 使用DataWorks连接 DataWorks控制台-ODPS SQL节点 MaxCompute Studio-SQL程序 以可视化方式创建OSS外部表 MaxCompute Studio-SQL程序 DataWorks控制台-外部表 创建OSS外部表语法创建OSS外部表的场景、相应语法格式及示例如下。详细语法参数及属性列表信息,请参见参考:语法参数说明、参考:with serdeproperties属性列表和参考:tblproperties属性列表。 场景 语法格式 支持读取或写入OSS的数据文件格式 示例 通过内置文本数据解析器创建外部表 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] stored by '' with serdeproperties ( [''='',...] ) location '';CSV 以GZIP方式压缩的CSV TSV 以GZIP方式压缩的TSV 示例:通过内置文本数据解析器创建OSS外部表-非分区表 示例:通过内置文本数据解析器创建OSS外部表-分区表 示例:通过内置文本数据解析器创建OSS外部表-压缩数据 通过内置开源数据解析器创建外部表 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] [row format serde '' [with serdeproperties ( [''='',...]) ] ] stored as location '' [using ''] [tblproperties (''='',...)];PARQUET 以SNAPPY、GZIP或LZO方式压缩的PARQUET TEXTFILE(JSON、TEXT) 以SNAPPY、LZO、BZ2、GZ、DEFLATE方式压缩的TEXTFILE ORC 以SNAPPY、ZLIB方式压缩的ORC RCFILE AVRO SEQUENCEFILE Hudi 示例:通过内置开源数据解析器创建OSS外部表 通过自定义解析器创建外部表 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] stored by '' with serdeproperties ( [''='',...] ) location '' using '';除上述格式外的数据文件。 示例:通过自定义解析器创建OSS外部表 示例:通过自定义解析器创建OSS外部表-非文本数据 说明如果您创建的OSS外部表为分区表时,需要在执行msck或alter命令后才可以使用,详情请参见补全OSS外部表分区数据语法。 更多示例请参见示例:创建OSS外部表并指定对应OSS文件的第一行为表头和示例:创建OSS外部表且外部表列数与OSS数据列数不一致。 补全OSS外部表分区数据语法当您创建的OSS外部表为分区表时,需要额外执行引入分区数据的操作。MaxCompute会根据您创建OSS外部表时指定的目录,自动补全OSS外部表的分区数据。语法格式如下。 (推荐)格式一:执行如下命令后,MaxCompute会自动解析OSS目录结构,识别分区,为OSS外部表添加分区信息。 msck repair table add partitions [ with properties (key:value, key: value ...)];格式二:手动执行如下命令为OSS外部表添加分区信息。 alter table add partition (=) [add partition (=) ...] [location URL];col_name和col_value的值需要与分区数据文件所在目录名称对齐。假设,分区数据文件所在的OSS目录结构如下图,col_name对应direction,col_value对应N、NE、S、SW、W。一个add partition对应一个子目录,多个OSS子目录需要使用多个add partition。 示例 在OSS上创建目录demo8并分别在下面建立两个分区文件夹,分别放入对应的文件。 分区文件夹:$pt1=1/$pt2=2,文件名称:demo8-pt1.txt。 分区文件夹:$pt1=3/$pt2=4,文件名称:demo8-pt2.txt。 创建外部表并指定pt字段。 --创建外部表 create external table mf_oss_spe_pt (id int, name string) partitioned by (pt1 string, pt2 string) stored as TEXTFILE location "oss://oss-cn-beijing-internal.aliyuncs.com/mfoss*******/demo8/"; --指定分区字段 MSCK REPAIR TABLE mf_oss_spe_pt ADD PARTITIONS with PROPERTIES ('odps.msck.partition.column.mapping'='pt1:$pt1,pt2:$pt2'); --查询数据 select * from mf_oss_spe_pt where pt1=1 and pt2=2; --返回 +------------+------------+------------+------------+ | id | name | pt1 | pt2 | +------------+------------+------------+------------+ | 1 | kyle | 1 | 2 | | 2 | nicole | 1 | 2 | +------------+------------+------------+------------+ --查询数据 select * from mf_oss_spe_pt where pt1=3 and pt2=4; +------------+------------+------------+------------+ | id | name | pt1 | pt2 | +------------+------------+------------+------------+ | 3 | john | 3 | 4 | | 4 | lily | 3 | 4 | +------------+------------+------------+------------+当OSS外表中的分区列名与OSS的目录结构不一致时,需要指定目录。 --MaxCompute分区与OSS的目录对应如下: --pt1=8-->8 --pt2=8-->$pt2=8 --添加分区 alter table mf_oss_spe_pt add partition (pt1=8,pt2=8) location 'oss://oss-cn-beijing-internal.aliyuncs.com/mfosscostfee/demo8/8/$pt2=8/'; --需要关闭commit mode --插入数据 set odps.sql.unstructured.oss.commit.mode=false; insert into mf_oss_spe_pt partition (pt1=8,pt2=8) values (1,'tere'); --查询数据 set odps.sql.unstructured.oss.commit.mode=false; select * from mf_oss_spe_pt where pt1=8 and pt2=8; +------+------+-----+-----+ | id | name | pt1 | pt2 | +------+------+-----+-----+ | 1 | tere | 8 | 8 | +------+------+-----+-----+ 示例:数据准备为便于理解,为您提供示例数据如下: oss_endpoint:oss-cn-hangzhou-internal.aliyuncs.com,即华东1(杭州)。 Bucket名称:oss-mc-test。 目录名称:Demo1/、Demo2/、Demo3/和SampleData/。 上述四个目录下分别上传以下数据文件: Demo1/目录下上传的文件为vehicle.csv,用于和通过内置文本数据解析器创建的非分区表建立映射关系。文件中包含的数据信息如下。 1,1,51,1,46.81006,-92.08174,9/14/2014 0:00,S 1,2,13,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,3,48,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,4,30,1,46.81006,-92.08174,9/14/2014 0:00,W 1,5,47,1,46.81006,-92.08174,9/14/2014 0:00,S 1,6,9,1,46.81006,-92.08174,9/15/2014 0:00,S 1,7,53,1,46.81006,-92.08174,9/15/2014 0:00,N 1,8,63,1,46.81006,-92.08174,9/15/2014 0:00,SW 1,9,4,1,46.81006,-92.08174,9/15/2014 0:00,NE 1,10,31,1,46.81006,-92.08174,9/15/2014 0:00,NDemo2/目录下包含五个子目录direction=N/、direction=NE/、direction=S/、direction=SW/和direction=W/,分别上传的文件为vehicle1.csv、vehicle2.csv、vehicle3.csv、vehicle4.csv和vehicle5.csv,用于和通过内置文本数据解析器创建的分区表建立映射关系。文件中包含的数据信息如下。 --vehicle1.csv 1,7,53,1,46.81006,-92.08174,9/15/2014 0:00 1,10,31,1,46.81006,-92.08174,9/15/2014 0:00 --vehicle2.csv 1,2,13,1,46.81006,-92.08174,9/14/2014 0:00 1,3,48,1,46.81006,-92.08174,9/14/2014 0:00 1,9,4,1,46.81006,-92.08174,9/15/2014 0:00 --vehicle3.csv 1,6,9,1,46.81006,-92.08174,9/15/2014 0:00 1,5,47,1,46.81006,-92.08174,9/14/2014 0:00 1,6,9,1,46.81006,-92.08174,9/15/2014 0:00 --vehicle4.csv 1,8,63,1,46.81006,-92.08174,9/15/2014 0:00 --vehicle5.csv 1,4,30,1,46.81006,-92.08174,9/14/2014 0:00
Demo3/目录下上传的文件为vehicle.csv.gz,压缩包内文件为vehicle.csv,与Demo1/目录下的文件内容相同,用于和携带压缩属性的OSS外部表建立映射关系。 SampleData/目录下上传的文件为vehicle6.csv,用于和通过开源数据解析器创建的OSS外部表建立映射关系。文件中包含的数据信息如下。 1|1|51|1|46.81006|-92.08174|9/14/2014 0:00|S 1|2|13|1|46.81006|-92.08174|9/14/2014 0:00|NE 1|3|48|1|46.81006|-92.08174|9/14/2014 0:00|NE 1|4|30|1|46.81006|-92.08174|9/14/2014 0:00|W 1|5|47|1|46.81006|-92.08174|9/14/2014 0:00|S 1|6|9|1|46.81006|-92.08174|9/14/2014 0:00|S 1|7|53|1|46.81006|-92.08174|9/14/2014 0:00|N 1|8|63|1|46.81006|-92.08174|9/14/2014 0:00|SW 1|9|4|1|46.81006|-92.08174|9/14/2014 0:00|NE 1|10|31|1|46.81006|-92.08174|9/14/2014 0:00|N示例:通过内置文本数据解析器创建OSS外部表-非分区表与示例:数据准备中的Demo1/目录建立映射关系。创建OSS外部表命令示例如下。 create external table if not exists mc_oss_csv_external1 ( vehicleId int, recordId int, patientId int, calls int, locationLatitute double, locationLongtitue double, recordTime string, direction string ) stored by 'com.aliyun.odps.CsvStorageHandler' with serdeproperties ( 'odps.properties.rolearn'='acs:ram::xxxxxx:role/aliyunodpsdefaultrole' ) location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/Demo1/';您可以执行desc extended mc_oss_csv_external1;命令查看创建好的OSS外部表结构信息。 示例:通过内置文本数据解析器创建OSS外部表-分区表与示例:数据准备中的Demo2/目录建立映射关系。创建OSS外部表并引入分区数据命令示例如下。 create external table if not exists mc_oss_csv_external2 ( vehicleId int, recordId int, patientId int, calls int, locationLatitute double, locationLongtitue double, recordTime string ) partitioned by ( direction string ) stored by 'com.aliyun.odps.CsvStorageHandler' with serdeproperties ( 'odps.properties.rolearn'='acs:ram::xxxxxx:role/aliyunodpsdefaultrole' ) location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/Demo2/'; --引入分区数据。 msck repair table mc_oss_csv_external2 add partitions; --等效于如下语句。 alter table mc_oss_csv_external2 add partition (direction = 'N') partition (direction = 'NE') partition (direction = 'S') partition (direction = 'SW') partition (direction = 'W');您可以执行desc extended mc_oss_csv_external2;命令查看创建好的外部表结构信息。 示例:通过内置文本数据解析器创建OSS外部表-压缩数据与示例:数据准备中的Demo3/目录建立映射关系。创建OSS外部表命令示例如下。 create external table if not exists mc_oss_csv_external3 ( vehicleId int, recordId int, patientId int, calls int, locationLatitute double, locationLongtitue double, recordTime string, direction string ) stored by 'com.aliyun.odps.CsvStorageHandler' with serdeproperties ( 'odps.properties.rolearn'='acs:ram::xxxxxx:role/aliyunodpsdefaultrole', 'odps.text.option.gzip.input.enabled'='true', 'odps.text.option.gzip.output.enabled'='true' ) location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/Demo3/';您可以执行desc extended mc_oss_csv_external3;命令查看创建好的外部表结构信息。 示例:通过内置开源数据解析器创建OSS外部表映射PARQUET数据文件 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] stored as parquet location ''; select ... from ...;映射TEXTFILE数据文件 关联TEXT数据建表示例 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] row format serde 'org.apache.hive.hcatalog.data.JsonSerDe' stored as textfile location ''; select ... from ...;建表时不支持自定义row format。row format默认值如下。 FIELDS TERMINATED BY :'\001' ESCAPED BY :'\' COLLECTION ITEMS TERMINATED BY :'\002' MAP KEYS TERMINATED BY :'\003' LINES TERMINATED BY :'\n' NULL DEFINED AS :'\N'关联CSV数据建表示例 --关闭native的text reader。 set odps.ext.hive.lazy.simple.serde.native=false; --创建OSS外部表。 create external table ( , ... ) row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde' with serdeproperties ( "separatorChar" = ",", "quoteChar"= '"', "escapeChar"= "\\" ) stored as textfile location '' tblproperties ( "skip.header.line.count"="1", "skip.footer.line.count"="1" ); select ... from ...;说明OpenCSVSerde只支持STRING类型。 关联JSON数据建表示例 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] row format serde 'org.apache.hive.hcatalog.data.JsonSerDe' stored as textfile location ''; select ... from ...;映射ORC数据文件 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] stored as orc location ''; select ... from ...;映射RCFILE数据文件 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] row format serde 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe' stored as rcfile location ''; select ... from ...;映射AVRO数据文件 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] stored as avro location ''; select ... from ...;映射SEQUENCEFILE数据文件 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] stored as sequencefile location ''; select ... from ...;映射Hudi格式数据文件 create external table [if not exists] ( , ... ) [partitioned by ( , ...)] ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' stored as INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' location ''; select ... from ...;示例:通过自定义解析器创建OSS外部表与示例:数据准备中的SampleData/目录建立映射关系。 操作流程如下: 使用MaxCompute Studio开发TextExtractor.java、TextOutputer.java、SplitReader.java和TextStorageHandler.java四个Java程序。 更多开发Java程序信息,请参见开发UDF。 通过MaxCompute Studio的一键式打包功能,将TextStorageHandler.java打包上传为MaxCompute资源。 假设,此处打包的资源名称为javatest-1.0-SNAPSHOT.jar。更多打包上传信息,请参见打包、上传及注册。 说明如果有多个依赖请分别打包后上传为MaxCompute资源。 执行如下命令创建OSS外部表。 create external table if not exists ambulance_data_txt_external ( vehicleId int, recordId int, patientId int, calls int, locationLatitute double, locationLongtitue double, recordTime string, direction string ) stored by 'com.aliyun.odps.udf.example.text.TextStorageHandler' with serdeproperties ( 'delimiter'='|', 'odps.properties.rolearn'='acs:ram::xxxxxxxxxxxxx:role/aliyunodpsdefaultrole' ) location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/SampleData/' using 'javatest-1.0-SNAPSHOT.jar';其中delimeter是OSS数据的分隔符名称。 您可以执行desc extended ambulance_data_txt_external;命令查看创建好的外部表结构信息。 说明对于自定义解析器,默认不会对数据分片,防止解析器出现正确性问题。如果您确认可以处理分片,需要使用如下命令允许进行数据分片,即启动多个mapper。 set odps.sql.unstructured.data.single.file.split.enabled=true;示例:通过自定义解析器创建OSS外部表-非文本数据与示例:数据准备中的SpeechSentence/目录建立映射关系。 操作流程如下: 使用MaxCompute Studio开发SpeechSentenceSnrExtractor.java、SpeechStorageHandler.java两个Java程序。 更多开发Java程序信息,请参见开发UDF。 通过MaxCompute Studio的一键式打包功能,将SpeechStorageHandler.java打包上传为MaxCompute资源。 假设,此处打包的资源名称为speechtest-1.0-SNAPSHOT.jar。更多打包上传信息,请参见打包、上传及注册。 执行如下命令创建OSS外部表。 create external table if not exists speech_sentence_snr_external ( sentence_snr double, id string ) stored by 'com.aliyun.odps.udf.example.speech.SpeechStorageHandler' with serdeproperties ( 'odps.properties.rolearn'='acs:ram::xxxxxxxxxxxxx:role/aliyunodpsdefaultrole', 'mlfFileName'='sm_random_5_utterance.text.label', 'speechSampleRateInKHz' = '16' ) location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/SpeechSentence/' using 'speechtest-1.0-SNAPSHOT.jar,sm_random_5_utterance.text.label';您可以执行desc extended speech_sentence_snr_external;命令查看创建好的外部表结构信息。 示例:创建OSS外部表并指定对应OSS文件的第一行为表头--创建外部表 create external table mf_oss_wtt ( id bigint, name string, tran_amt double ) STORED BY 'com.aliyun.odps.CsvStorageHandler' with serdeproperties ( 'odps.text.option.header.lines.count' = '1', 'odps.sql.text.option.flush.header' = 'true' ) location 'oss://oss-cn-beijing-internal.aliyuncs.com/mfosscostfee/demo11/'; --插入数据 insert overwrite table mf_oss_wtt values (1, 'val1', 1.1),(2, 'value2', 1.3); --查询数据 --在建表的时候可以把所有字段建成string,否则表头读取时会报错。 --或者在建表的时候需要加跳过表头的参数:'odps.text.option.header.lines.count' = '1' select * from mf_oss_wtt; +------------+------+------------+ | id | name | tran_amt | +------------+------+------------+ | 1 | val1 | 1.1 | | 2 | value2 | 1.3 | +------------+------+------------+打开外部表对应的OSS文件内容如下: 准备如下数据,保存为CSV格式上传至OSS的doc-test-01/demo目录下。 1,kyle1,this is desc1 2,kyle2,this is desc2,this is two 3,kyle3,this is desc3,this is three, I have 4 columns创建外部表。 指定对于列数不一致行的处理方式为truncate。 --删除表 drop table test_mismatch; --新建外部表 create external table if not exists test_mismatch ( id string, name string, dect string, col4 string ) stored by 'com.aliyun.odps.CsvStorageHandler' with serdeproperties ('odps.sql.text.schema.mismatch.mode' = 'truncate') location 'oss://oss-cn-shanghai-internal.aliyuncs.com/doc-test-01/demo/';指定对于列数不一致行的处理方式为ignore。 --删除表 drop table test_mismatch01; --新建外部表 create external table if not exists test_mismatch01 ( id string, name string, dect string, col4 string ) stored by 'com.aliyun.odps.CsvStorageHandler' with serdeproperties ('odps.sql.text.schema.mismatch.mode' = 'ignore') location 'oss://oss-cn-shanghai-internal.aliyuncs.com/doc-test-01/demo/';查询表数据。 select * from test_mismatch; --返回结果 +----+------+------+------+ | id | name | dect | col4 | +----+------+------+------+ | 1 | kyle1 | this is desc1 | NULL | | 2 | kyle2 | this is desc2 | this is two | | 3 | kyle3 | this is desc3 | this is three | +----+------+------+------+select * from test_mismatch01; --返回结果 +----+------+------+------+ | id | name | dect | col4 | +----+------+------+------+ | 2 | kyle2 | this is desc2 | this is two | +----+------+------+------+参考:语法参数说明上述语法中各参数的含义如下。 参数名称 可选/必填 说明 mc_oss_extable_name 必填 待创建的OSS外部表的名称。 表名大小写不敏感,在查询外部表时,无需区分大小写,且不支持强制转换大小写。 col_name 必填 OSS外部表的列名称。 在读取OSS数据场景,创建的OSS外部表结构必须与OSS数据文件结构保持一致,否则无法成功读取OSS数据。 data_type 必填 OSS外部表的列数据类型。 在读取OSS数据场景,创建的OSS外部表各列数据类型必须与OSS数据文件各列数据类型保持一致,否则无法成功读取OSS数据。 partitioned by ( , ...) 条件必填 当OSS中的数据文件是以分区路径方式存储时,需要携带该参数,创建分区表。 col_name:分区列名称。 data_type:分区列数据类型。 StorageHandler 条件必填 当您使用内置文本数据解析器或自定义解析器创建OSS外部表时,需要携带该参数。MaxCompute解析器主要分为如下两类: 内置文本数据解析器: com.aliyun.odps.CsvStorageHandler:读写CSV或以GZIP方式压缩的CSV数据文件。 com.aliyun.odps.TsvStorageHandler:读写TSV或以GZIP方式压缩的TSV数据文件。 自定义解析器:您通过编写MaxCompute UDF自定义的解析器。更多编写MaxCompute UDF信息,请参见开发UDF。 ''='' 必填 OSS外部表扩展属性。详细属性列表,请参见参考:with serdeproperties属性列表。 oss_location 必填 数据文件所在OSS路径。格式为oss://///。MaxCompute默认会读取该路径下的所有数据文件。 oss_endpoint:OSS访问域名信息。您需要使用OSS提供的内网域名,否则将产生OSS流量费用。例如oss://oss-cn-beijing-internal.aliyuncs.com/xxx。更多OSS内网域名信息,请参见访问域名和数据中心。 说明建议数据文件存放的OSS地域与MaxCompute项目所在地域保持一致。由于MaxCompute只在部分地域部署,跨地域的数据连通性可能存在问题。 Bucket名称:OSS存储空间名称,即Bucket名称。更多查看存储空间名称信息,请参见列举存储空间。 目录名称:OSS目录名称。目录后不需要指定文件名。 --正确用法。 oss://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/ --错误用法。 http://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/ -- 不支持HTTP连接。 https://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/ -- 不支持HTTPS连接。 oss://oss-cn-shanghai-internal.aliyuncs.com/Demo1 -- 连接地址错误。 oss://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/vehicle.csv -- 不需要指定文件名。jar_name 条件必填 当您使用自定义解析器创建OSS外部表时,需要携带该参数。指定自定义解析器代码对应的JAR包。该JAR包需要添加为MaxCompute项目资源。 更多添加资源信息,请参见添加资源。 serde_class 条件可选 指定MaxCompute内置的开源数据解析器。如果数据文件格式为TEXTFILE,必须携带该参数,其他场景可以不配置。 MaxCompute支持的开源数据格式对应的serde_class如下: PARQUET:org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe TEXTFILE:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe、org.apache.hive.hcatalog.data.JsonSerDe、org.apache.hadoop.hive.serde2.OpenCSVSerde ORC:org.apache.hadoop.hive.ql.io.orc.OrcSerde AVRO:org.apache.hadoop.hive.serde2.avro.AvroSerDe SEQUENCEFILE:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe RCFILE:org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe ORCFILE:org.apache.hadoop.hive.ql.io.orc.OrcSerde file_format 条件必填 当OSS数据文件为开源格式时,需要携带该参数。指定OSS数据文件的格式。 说明单个文件大小不能超过3 GB,如果文件过大,建议拆分。 resource_name 条件可选 当您使用自定义的serde class时,需要指定依赖的资源。资源中包含了自定义的serde class。 serde class相关的JAR包需要添加为MaxCompute项目资源。 更多添加资源信息,请参见添加资源。 ''='' 条件可选 OSS外部表扩展属性。详细属性列表,请参见参考:tblproperties属性列表。 参考:with serdeproperties属性列表property_name 使用场景 说明 property_value 默认值 odps.properties.rolearn 使用STS模式授权时,请添加该属性。 指定RAM中Role(具有访问OSS权限)的ARN信息。 您可以通过RAM控制台中的角色详情获取。 无 delimiter 需要明确CSV或TSV数据文件的列分隔符时,请添加该属性。 MaxCompute基于设置的分隔符,正确读取OSS数据文件中的各列数据。 单个字符 英文逗号(,) odps.text.option.gzip.input.enabled 当需要读取以GZIP方式压缩的CSV或TSV文件数据时,请添加该属性。 CSV、TSV压缩属性。配置该参数值为True时,MaxCompute才可以正常读取压缩文件,否则会读取失败。 True False False odps.text.option.gzip.output.enabled 当需要将数据以GZIP压缩方式写入OSS时,请添加该属性。 CSV、TSV压缩属性。配置该参数值为True时,MaxCompute才能将数据以GZIP压缩方式写入OSS,否则不压缩。 True False False odps.text.option.header.lines.count 当OSS数据文件为CSV或TSV,且需要忽略OSS数据文件中的前N行时,请添加该属性。 MaxCompute读取OSS数据文件时,会忽略指定的行数。 非负整数 0 odps.text.option.null.indicator 当OSS数据文件为CSV或TSV,且需要定义OSS数据文件中NULL的解析规则时,请添加该属性。 通过该参数配置的字符串会被解析为SQL中的NULL。例如\N指代NULL,则a,\N,b会解析为a, NULL, b。 字符串 空字符串 odps.text.option.ignore.empty.lines 当OSS数据文件为CSV或TSV,且需要定义OSS数据文件中空行的处理规则时,请添加该属性。 配置该参数值为True时,MaxCompute会忽略数据文件中的空行,否则会读取空行。 True False True odps.text.option.encoding 当OSS数据文件为CSV或TSV,且OSS数据文件编码规则非默认编码规则时,请添加该属性。 确保此处配置的编码规则与OSS数据文件编码规则保持一致,否则MaxCompute无法成功读取数据。 UTF-8 UTF-16 US-ASCII GBK UTF-8 odps.text.option.delimiter 当需要明确CSV或TSV数据文件的列分隔符时,请添加该属性。 确保此处配置的列分隔符可以正确读取OSS数据文件的每一列,否则MaxCompute读取的数据会出现错位问题。 单个字符 英文逗号(,) odps.text.option.use.quote 当CSV或TSV数据文件中的字段包含换行(CRLF)、双引号或英文逗号时,请添加该属性。 当CSV某个字段中包含换行、双引号(需要在"前再加"转义)或英文逗号时,整个字段必须用双引号("")括起来作为列分隔符。该参数指定是否识别CSV的列分隔符"。 True False False mcfed.parquet.compression 当需要将PARQUET数据以压缩方式写入OSS时,请添加该属性。 PARQUET压缩属性。PARQUET数据默认不压缩。 SNAPPY GZIP 无 parquet.file.cache.size 在处理PARQUET数据场景,如果需要提升读OSS数据文件性能,请添加该属性。 指定读OSS数据文件时,可缓存的数据量,单位为KB。 1024 无 parquet.io.buffer.size 在处理PARQUET数据场景,如果需要提升读OSS数据文件性能,请添加该属性。 指定OSS数据文件大小超过1024 KB时,可缓存的数据量,单位为KB。 4096 无 separatorChar 当需要明确以TEXTFILE格式保存的CSV数据的列分隔符时,请添加该属性。 指定CSV数据列分隔符。 单个字符串 英文逗号(,) quoteChar 当以TEXTFILE格式保存的CSV数据中的字段包含换行、双引号或英文逗号时,请添加该属性。 指定CSV数据的引用符。 单个字符串 无 escapeChar 当需要明确以TEXTFILE格式保存的CSV数据的转义规则时,请添加该属性。 指定CSV数据的转义符。 单个字符串 无 mcfed.orc.schema.resolution 同一张OSS外部表中数据的Schema不一样。 用于设置ORC文件解析方式,name表示根据列名解析。 name 默认按列号解析,等价于 :mcfed.orc.schema.resolution'='position。 odps.sql.text.option.flush.header 在往OSS写数据的时候,文件块的第一行为表头。 只有针对CSV文件格式生效。 True False False odps.sql.text.schema.mismatch.mode 当读取的OSS文件的数据列数和外部表的Schema列数不一致时。 指定对于列数不一致行的处理方式。 error:报错。 truncate:超过外部表列数部分数据被截断;少于外部表列数部分数据则补null。 ignore:丢弃不一致的行。 error 参考:tblproperties属性列表property_name 使用场景 说明 property_value 默认值 skip.header.line.count 当需要忽略以TEXTFILE格式保存的CSV文件中的前N行数据时,请添加该属性。 MaxCompute读取OSS数据时,会忽略从首行开始指定行数的数据。 非负整数 无 skip.footer.line.count 当需要忽略以TEXTFILE格式保存的CSV文件中的后N行数据时,请添加该属性。 MaxCompute读取OSS数据时,会忽略从尾行开始指定行数的数据。 非负整数 无 mcfed.orc.compress 当需要将ORC数据以压缩方式写入OSS时,请添加该属性。 ORC压缩属性。指定ORC数据的压缩方式。 SNAPPY ZLIB 无 mcfed.mapreduce.output.fileoutputformat.compress 当需要将TEXTFILE数据文件以压缩方式写入OSS时,请添加该属性。 TEXTFILE压缩属性。配置该参数值为True时,MaxCompute才可以将TEXTFILE数据文件以压缩方式写入OSS,否则不压缩。 True False False mcfed.mapreduce.output.fileoutputformat.compress.codec 当需要将TEXTFILE数据文件以压缩方式写入OSS时,请添加该属性。 TEXTFILE压缩属性。设置TEXTFILE数据文件的压缩方式。 说明只支持property_value中的四种压缩方式。 com.hadoop.compression.lzo.LzoCodec com.hadoop.compression.lzo.LzopCodec org.apache.hadoop.io.compress.SnappyCodec com.aliyun.odps.io.compress.SnappyRawCodec 无 io.compression.codecs 当OSS数据文件为Raw-Snappy格式时,请添加该属性。 配置该参数值为True时,MaxCompute才可以正常读取压缩数据,否则MaxCompute无法成功读取数据。 com.aliyun.odps.io.compress.SnappyRawCodec 无 相关文档创建OSS外部表后,您可以通过外部表读取存储在OSS目录中的数据文件。具体操作请参见读取OSS数据。 |


【本文地址】