数据的归一化 |
您所在的位置:网站首页 › origin9归一化处理 › 数据的归一化 |
数据的归一化
|
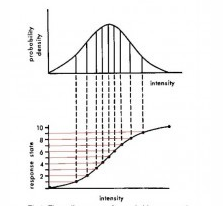
正常情况下,数据的处理用的都是线性归一化,但是如果实验的数据服从某种分布函数时,其中最多的就是正态分布了,假设实验数据是服从正态分布的,我们可以通过一个函数来对数据进行变换,这个函数选取的原则就是使得原有数据中的信息量最多,即信息熵最大。首先我说一下信息熵的计算方法:
可能这里讲熵的概念更难理解了,换句话说吧,你觉得所有分布函数中什么分布函数能让上述式子中l达到最大值,均匀分布是不是??这也是线性归一化最后数据服从均匀分布的原因。 综上所述,就是说我们需要将原有的数据x通过一个函数h转换为一个均匀分布的数据h(x),这样可以使得数据的信息量最大,这个函数怎么找到呢??我记得我曾经在求正态分布的随机数的时候证明过一个服从任何分布的随机数(http://blog.csdn.net/hxlove123456/article/details/78045391),其分布函数一定是一个均匀分布的函数,所以随机数的分布函数是一个很好的选择。 对于一个服从正态分布的随机数而言,其分布函数就是s函数。
所以在对数据进行归一化的时候s函数对数据进行归一化的方法用的很广泛,这是因为自然界中服从正态分布的随机数多而已,不是其本身的特性所决定。 对上面文章中有不懂的地方,可以参考一下下面这篇博客: https://www.tuicool.com/articles/uMraAb |
 :
:
【本文地址】
今日新闻 |
推荐新闻 |