MySQL存储过程综述及如何使用Navicat创建存储过程 |
您所在的位置:网站首页 › mysql存储过程怎么调用函数 › MySQL存储过程综述及如何使用Navicat创建存储过程 |
MySQL存储过程综述及如何使用Navicat创建存储过程
|
一、什么是MySQL存储过程? 在大型项目中,有时候需要重复执行能够完成特定功能的SQL语句集,而MySQL为我们提供了存储过程的概念,存储过程是数据库中的一个重要对象,
它是存储在数据库中的一组完成特定功能的SQL语句集。它第一次编译后,只要没有修改,处处都可以直接调用且不用重新编译,用户通过指定存储过程的名字和参数(若该存储过程存在参数)来执行它。
二、存储过程的特点
1:能够完成复杂的判断和运算;
2:可编程性强,且使用灵活;
3:可重复使用SQL编程代码;
4:执行速度相对较快;
5:能够减少网络之间的传输开销
三、Navicat创建一个存储过程
(1):先选择某个数据库中的函数。
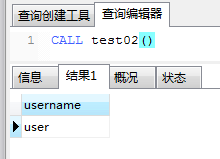
为了方便,接下来均使用SQL语句的方式创建存储过程。此外,文章中用到的数据表会在文末给出。 (1)创建存储过程的语法。 CREATE PROCEDURE 名称 (参数...) #若使用navicat工具,不需要该行 BEGIN ........ END;(2)创建一个存储过程。 CREATE PROCEDURE test01() BEGIN SELECT * from tsp_user; SELECT * from tsp_order; END;(3)调用存储过程。 call test01() (4)结果如下所示。 (1)利用以下例子来说明下变量的声明和赋值。 CREATE PROCEDURE test02() BEGIN # 使用declare语句声明一个变量 DECLARE username VARCHAR(32) DEFAULT ''; #使用set语句给变量赋值 set username='pretty_baby'; #将tsp_user表中id为1的记录的user赋值给username SELECT user INTO username FROM tsp_user where id='1'; #返回username变量 select username; END;(2)调用该存储过程,执行结果如下。
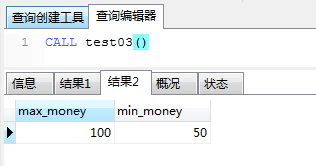
(3)变量的声明和赋值时的注意事项。 a)使用declare实现变量的声明,一句declare只能声明一个变量,变量必须先声明后使用; b)变量具有数据类型和长度,与MySQL的数据类型保持一致,所以还能指定默认值、字符集和排序规则等; c)可以使用set或select into的方式给变量赋值; d)若变量需要被返回,可以使用 select 变量名 的方式。 5.2、验证变量的作用域(1)关于变量的作用域。 a)变量作用域的范围在begin和end之间; b)若要在多个begin-end块之间传值,可以使用全局变量,即放在第一个所有代码块之前; c)形参的作用域是全局的,即在多个begin-end块中均是可访问的。 (2)验证变量的作用域。 a)实例。利用一个存储过程统计tsp_user表、tsp_order表的记录数以及tsp_order表的最大金额和最小金额。存储过程如下: CREATE PROCEDURE test03() BEGIN BEGIN DECLARE user_count INT DEFAULT 0; #声明变量user_count DECLARE order_count INT DEFAULT 0; #声明变量order_count SELECT count(*) INTO user_count FROM tsp_user; # 赋值 SELECT count(*) INTO order_count FROM tsp_order; # 赋值 SELECT user_count, order_count; #返回变量 END; # 一定要有分号,不然会报错 BEGIN DECLARE max_money INT DEFAULT 0; DECLARE min_money INT DEFAULT 0; SELECT MAX(money) INTO max_money FROM tsp_order; SELECT MIN(money) INTO min_money FROM tsp_order; SELECT max_money, min_money; END; # 一定要有分号,不然会报错 END;调用该存储过程,执行结果如下:
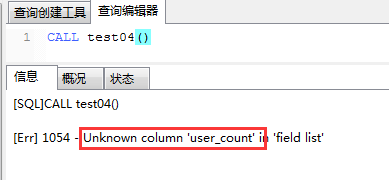
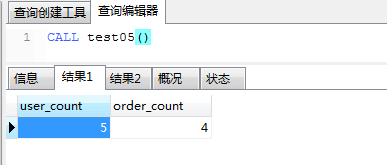
b)若将存储过程test03()做如下修改,在第二个begin-end块中访问user_count和order_count。 CREATE PROCEDURE test04() BEGIN BEGIN DECLARE user_count INT DEFAULT 0; #声明变量user_count DECLARE order_count INT DEFAULT 0; #声明变量order_count SELECT count(*) INTO user_count FROM tsp_user; # 赋值 SELECT count(*) INTO order_count FROM tsp_order; # 赋值 SELECT user_count, order_count; #返回变量 END; BEGIN DECLARE max_money INT DEFAULT 0; DECLARE min_money INT DEFAULT 0; SELECT MAX(money) INTO max_money FROM tsp_order; SELECT MIN(money) INTO min_money FROM tsp_order; # 在此处返回user_count, order_count,验证在另一个begin-end块中是否能被访问到 SELECT user_count, order_count, max_money, min_money; END; END 再次调用,结果如下: c)若将user_count和order_count改为全局变量。如下所示: CREATE PROCEDURE test05() BEGIN DECLARE user_count INT DEFAULT 0; #声明全局变量user_count DECLARE order_count INT DEFAULT 0; #声明全局变量order_count BEGIN SELECT count(*) INTO user_count FROM tsp_user; # 赋值 SELECT count(*) INTO order_count FROM tsp_order; # 赋值 SELECT user_count, order_count; #返回变量 END; BEGIN DECLARE max_money INT DEFAULT 0; DECLARE min_money INT DEFAULT 0; SELECT MAX(money) INTO max_money FROM tsp_order; SELECT MIN(money) INTO min_money FROM tsp_order; # 在此处返回user_count, order_count,验证在另一个begin-end块中是否能被访问到 SELECT user_count, order_count, max_money, min_money; END; END 执行结果如下:
(1)基本语法 CREATE PROCEDURE 存储过程名称([IN | OUT | INOUT] 参数名 参数的数据类型) BEGIN ....... END存储过程传参的参数类型有:IN、OUT、INOUT。 (2)传入参数IN 注意事项: a)传入参数:类型为IN,该参数必须在调用存储过程时事先指定,若不显式指定为IN,则默认为IN类型; b)IN类型的参数一般只用于传入,在调用过程中一般不作修改和返回; c)如果在调用存储过程中需要修改和返回值,可以使用OUT类型的参数。 实例。利用存储过程传入userId=2,并返回该userId值对应的name; CREATE PROCEDURE test06(userId int) BEGIN DECLARE username VARCHAR(30) DEFAULT ''; DECLARE order_count INT DEFAULT 0; select user INTO username from tsp_user where id = userId; SELECT username; END;
(3)传出参数OUT 注意事项: a)传出参数:在调用存储过程时,可以改变其值,并可返回; b)OUT是传出参数,不能用于传入参数值; c)调用存储过程时,OUT参数也需要指定,但必须是变量,不能是常量; d)当既需要传入,又需要传出,则可以使用INOUT类型参数 实例。利用存储过程传入userId=3,并使用传出参数username返回该userId对应的user; CREATE PROCEDURE test07(IN userId int, OUT username varchar(32)) BEGIN select user INTO username from tsp_user where id = userId; END;
(4)可变参数INOUT 注意事项: a)可变参数:调用时可传入值,在调用过程中,也可修改其值,同时可返回值; b)INOUT参数集合了IN和OUT类型的参数功能; c)INOUT调用时传入的是变量,而不是常量。 实例。利用存储过程传入userId和username,既是传入参数,也是传出参数 CREATE PROCEDURE test08(INOUT userId int, INOUT username varchar(32)) BEGIN set userId = 3; #可被修改 set username = ''; #可被修改 select id, user INTO userId, username from tsp_user where id = userId; END;执行结果如下所示:
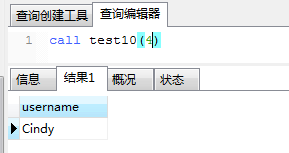
(1)基本语法。 a)条件语句基本结构: if(逻辑判断) then ... else ... end if;b)多条件判断语句: if(逻辑判断1) then ... else if(逻辑判断2) then ... else ... end if;(2)实例。 a)如果用户userId是偶数则返回username,否则返回userId。 CREATE PROCEDURE test10(IN userId int) BEGIN DECLARE username varchar(32) default ''; if(userId % 2 = 0) # 注意:只有一个 = then select user into username from tsp_user where id=userId; select username; else select userId; end if; END 执行结果如下所示:
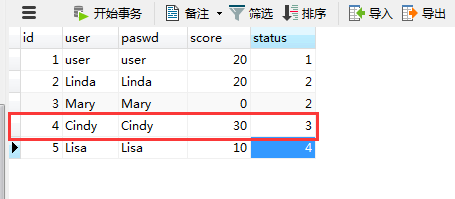
b)根据用户传入的uid参数判断。若用户状态status为1,则给用户score加10分;若用户状态status为2,则给用户score加20分;其他则情况加30分 CREATE PROCEDURE test11(IN userId int) BEGIN DECLARE my_status int default 0; select status into my_status from tsp_user where id = userId; if (my_status = 1) then update tsp_user set score=score+10 where id = userId; elseif (my_status = 2) then update tsp_user set score=score+20 where id = userId; else update tsp_user set score=score+30 where id = userId; end if; END 调用存储过程之前: 调用之后:
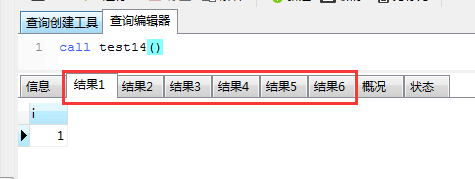
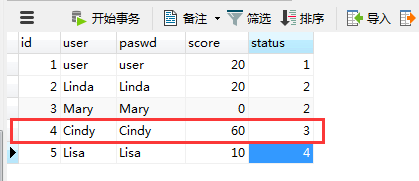
7.2.1 while语句 (1)基本语法。 while(表达式) do ...... end while;(2)实例。使用循环语句,向tsp_testId表连续插入5条记录。 CREATE PROCEDURE test12() begin declare i int default 0; while(i 5 END REPEAT; END 执行结果如下: 7.3 流程控制 (1)基本语法。 case... when...then.... when...then.... else... end case;(2)实例。根据userId获取status值,如果status为1,则修改score为10;如果status为2,则修改为20,如果status3,则修改为30;否则修改为40 CREATE PROCEDURE test14() begin declare my_status int default 0; select status into my_status from tsp_user where id = userId; case my_status when 1 then update tsp_user set score = 10 where id = userId; when 2 then update tsp_user set score = 20 where id = userId; when 3 then update tsp_user set score = 30 where id = userId; else update tsp_user set score = 40 where id = userId; end case; end 调用存储过程之前: 调用之后:
(1)游标的定义:游标是用于保存结果的临时区域。 (2)实例。结合游标,利用存储过程逐一更新id为偶数的user。 BEGIN DECLARE stop int DEFAULT 0; # 声明停止标识 DECLARE username VARCHAR(32); # 创建一个游标变量username_cur,语法:declare 变量名 cursor ... # 利用游标保存查询的临时结果,本质上是一个结果集 DECLARE username_cur cursor for SELECT user FROM tsp_user WHERE id % 2 = 0; # 当游标变量中保存的结果都遍历一遍, # 到达结尾,将变量stop设置为1,用于判断循环是否结束 DECLARE CONTINUE HANDLER FOR NOT FOUND set stop = 1; open username_cur; # 打开游标 FETCH username_cur INTO username; # 游标向前走一步,取出一条记录放到变量username中 while(stop = 0) DO # 如果游标还没有结尾,则继续 BEGIN # 利用concat函数进行字符串拼接 UPDATE tsp_user set user = CONCAT(username,'_cursor') WHERE user = username; # 游标向前走一步,取出一条记录放到变量username中 FETCH username_cur INTO username; END; END WHILE; # 结束循环 CLOSE username_cur; # 关闭游标 END 执行结果如下: (1)自定义函数与存储过程最大的区别是,自定义函数必须要有返回值,否则会报错。 (2)注意事项: a)创建函数的基本语法:create function 函数名(参数) returns 返回类型; b)函数体放在begin和end之间; c)returns指定函数的返回值; d)调用函数的基本语法:select 函数名(参数)。 (3)实例。实现一个简单的自定义函数,将id、user、passwd组合成UUID作为用户的唯一标识。 create function testFunction(userid int) returns varchar(64) reads sql data # 从数据库中读取数据,但不修改数据,不需要加分号 BEGIN DECLARE UUID VARCHAR(64) DEFAULT ''; select CONCAT(id, '_', user, '_', passwd) INTO UUID from tsp_user WHERE id = userId; RETURN UUID; # 返回变量UUID END navicat中: (1)定义:触发器与函数、存储过程一样,触发器是一种对象,它能根据对表的操作时间,触发一些动作,这些动作可以是insert,update,delete等修改操作。 (2)注意事项: a)创建触发器的基本语法:create trigger 触发器名 b)触发时机。如after insert on tsp_user,除了after还有before,表示在对表操作之前(before)或者之后(after)触发该动作。 c)对什么操作事件触发? 如after insert on users,操作事件包括insert、update、delete等修改操作; (3)实例。在执行插入操作时,记录该操作插入的id、user、action和插入时间。 #创建一个触发器,在插入记录到tsp_user时,触发该触发器 CREATE TRIGGER testTrigger after INSERT on tsp_user for EACH ROW # 作用范围,每一条记录 BEGIN INSERT INTO tsp_operlog(id, user, action, oper_date) VALUES (NEW.id, NEW.user, 'insert', NOW()); END此时插入一条记录到tsp_user表: insert into tsp_user (id, user, passwd, score, status ) values(6, 'Sweet','123456', 60 , 3); 执行insert语句之后,查看tsp_operLog表。如下所示: (1)利用存储过程+event事件的方式,实现彩票的3D开奖。 步骤如下: a)规定每3分钟开一次奖,先编写存储过程open_lucky,用于产生3个随机数,并生成一条开奖记录。 b)编写一个时间调度器,每3分钟调用一次这个过程 开奖的存储过程open_lucky() create procedure open_lucky() begin insert into tsp_lucky(num1, num2, num3, ctime) select FLOOR(rand()*9)+1,FLOOR(rand()*9)+1,FLOOR(rand()*9)+1,now(); end;定时事件lucky_event create event if not exists lucky_event # 创建一个事件 on schedule every 3 second# on schedule 什么时候来执行,每3s执行一次 on completion preserve do call open_lucky; 执行结果如下所示: (2)深入解析event事件的创建 create event[IF NOT EXISTS] event_name -- 创建使用create event ON SCHEDULE schedule -- on schedule 什么时候来执行 [ON COMPLETION [NOT] PRESERVE] -- 调度计划执行完成后是否还保留 [ENABLE | DISABLE] -- 是否开启事件,默认开启 [COMMENT 'comment'] -- 事件的注释 DO sql_statement; -- 这个调度计划要做什么?此处可调用存储过程(3)执行时间的实例 1.单次计划任务示例 在2020年5月20日5点20分执行一次 on schedule at '2020-05-20 05:20:00' 2. 重复计划执行 on schedule every 1 second 每秒执行一次 on schedule every 1 minute 每分钟执行一次 on schedule every 1 day 每天执行一次 3.指定时间范围的重复计划任务 每天在20:00:00执行一次 on schedule every 1 day starts '2020-05-20 20:00:00' 十二、本文中所用到的数据表 (1)tsp_lucky |
 (2):点击新建函数,选择过程。
(2):点击新建函数,选择过程。  (3):输入该存储过程要传入的参数。
(3):输入该存储过程要传入的参数。  (4):点击完成,并做个简单的测试,但是会报错,如下所示。
(4):点击完成,并做个简单的测试,但是会报错,如下所示。  报如下错误:
报如下错误:  这是因为存储过程的参数是要设定长度的。而以向导的方式添加参数是没有设定长度的,所以才会报错,一定要手动添加长度。如下所示。到这里就完成了使用navicat创建存储过程。
这是因为存储过程的参数是要设定长度的。而以向导的方式添加参数是没有设定长度的,所以才会报错,一定要手动添加长度。如下所示。到这里就完成了使用navicat创建存储过程。 



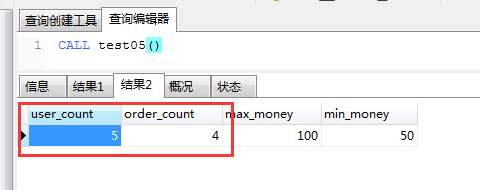
 执行结果如下所示:
执行结果如下所示: 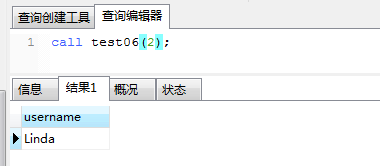
 执行结果如下所示,使用set @变量名定义一个变量:
执行结果如下所示,使用set @变量名定义一个变量: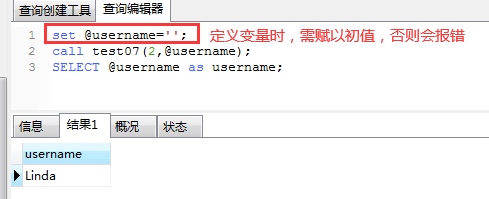

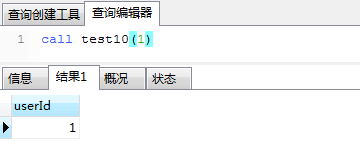


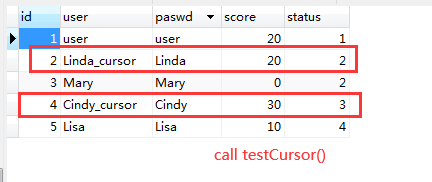
 执行结果如下所示:
执行结果如下所示: 
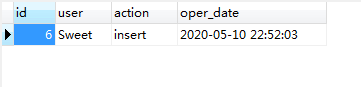
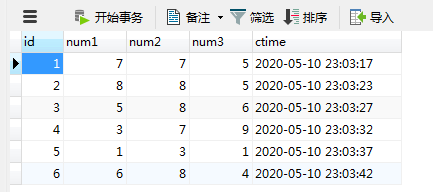
 (2)tsp_operLog
(2)tsp_operLog  (3)tsp_order
(3)tsp_order  (4)tsp_testId
(4)tsp_testId  (5)tsp_user
(5)tsp_user 
【本文地址】
今日新闻 |
推荐新闻 |