MySQL自增ID用完的几种解决方案 |
您所在的位置:网站首页 › mk2导弹用完了怎么办啊 › MySQL自增ID用完的几种解决方案 |
MySQL自增ID用完的几种解决方案
|
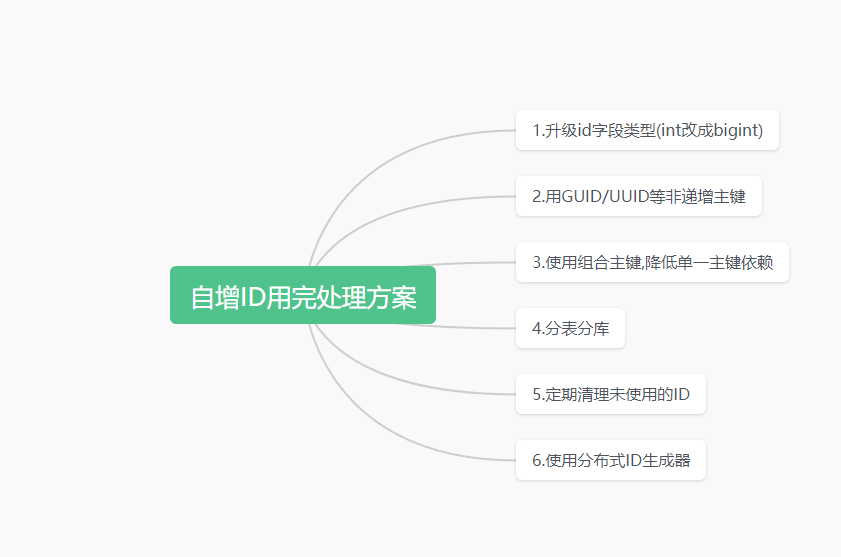
文章目录 简介处理准备检查当前自增ID的最大值确定使用的自增ID类型 处理方案升级自增ID类型用GUID/UUID等非递增主键分表分库使用组合主键,降低单一主键依赖定期清理未使用的ID使用分布式ID生成器 总结写在最后 简介
简介
MySQL的自增ID通常使用整数类型的列来实现,当达到最大值时(在大多数情况下是232-1或264-1),自增ID将循环并从新的最小值开始增长。 处理准备 检查当前自增ID的最大值可以使用以下SQL查询语句来获取当前最大的自增ID值: SELECT MAX(id) FROM your_table;假设表名为 your_table 和自增ID列名为 id。 确定使用的自增ID类型根据当前最大值来判断你使用的自增ID类型。如果当前最大值为达到类型极限,可能需要考虑升级到尚未达到极限的自增ID类型。 如果使用的是 INT 类型,最大值为 2147483647。如果使用的是 BIGINT 类型,最大值为 9223372036854775807。 处理方案
如果你的自增ID类型已经达到上限,在有备份的情况下, 1 可以通过以下步骤升级自增ID类型 1.1 创建一个新的带有更大范围的自增ID列,如 BIGINT 类型。 1.2 将所有数据从旧表复制到新表。 1.3 更新所有关联的外键和索引。 1.4 修改应用程序代码以适应新表结构。 1.5 停用旧表并删除它。 1.6 修改新表的名称,使其与旧表名称一致。 2 继续从最大ID值开始, circle回到最小ID值循环使用 设置自增主键为无符号整型,并调整最大值防止溢出: alter table tableName modify id int unsigned; alter table tableName change id id int unsigned AUTO_INCREMENT=1; 3 重置自增列,回到初始值重新开始 alter table tableName auto_increment=1; 用GUID/UUID等非递增主键可以使用GUID或UUID等非递增类型来作为主键,避免自增ID用尽的问题。使用UUID是通用唯一识别码,可以保证分布式环境下主键的唯一性。创建表时指定主键类型为CHAR(36),并default为UUID()函数: CREATE TABLE t ( id CHAR(36) PRIMARY KEY DEFAULT UUID(), name VARCHAR(50) );插入数据时会自动生成UUID: INSERT INTO t(name) VALUES ('小明');使用GUID也是一种唯一ID,长度可变。创建表时指定主键类型为CHAR(36),并default为UUID生成GUID: CREATE TABLE t ( id CHAR(36) PRIMARY KEY DEFAULT REPLACE(UUID(),'-',''), name VARCHAR(50) );插入数据时自动生成GUID: INSERT INTO t(name) VALUES ('小红');UUID和GUID都可以保证唯一性,并解决自增ID用尽问题。但查询效率可能下降。 分表分库可以通过分表分库的方式来避免单表自增ID用尽的问题: 1. 按范围分表 可以按照ID范围对表进行拆分,例如: table_1 (id 1-100000) table_2 (id 100001-200000) ...不同表各自维护一段自增ID,降低单表ID耗尽的概率。 2. 按时间分表 也可以按时间划分表,例如每月一个表: table_202001 table_202002 ...定期创建新表,保证单表ID足够用。 3. 多主库分库 部署多MySQL主库,不同库实例维护不同的ID段: master_1 (id 1-100000) master_2 (id 100001-200000) ...同时配合分表可以进一步降低单表自增ID用尽概率。 使用组合主键,降低单一主键依赖可以通过使用组合主键来降低对单一自增主键的依赖,提高主键空间的利用率,避免自增ID用尽的问题。组合主键的做法是,在主键中除自增ID外,再加上一个业务字段,共同组成主键。例如,对于订单表,可以设计为: CREATE TABLE orders ( id INT AUTO_INCREMENT, order_no VARCHAR(20), order_time DATETIME, ... PRIMARY KEY (id, order_no) )这里的主键由自增ID和订单号order_no两部分组成。那么插入数据时,可以手动指定order_no,并配合自增ID使用: INSERT INTO orders (order_no, order_time) VALUES ('XN201900001', '2019-01-01'); INSERT INTO orders (order_no, order_time) VALUES ('XN201900002', '2019-01-02');这样可以大幅提高主键空间的利用率,降低单一自增ID耗尽的可能。当然,这需要业务系统准备好生成订单号这样的业务主键。 组合主键是提高MySQL主键灵活性的一个方法,值得在设计时考虑。 定期清理未使用的ID通过定期清理未使用的ID来回收空间,这也是一个有效的方法。主要步骤是: 通过自增ID字段建立索引,方便检索 CREATE INDEX id_index ON table(id); 定期查询检测存在"ID跳号"的情况,定位出未使用的ID SELECT * FROM table WHERE id > 100000 AND id NOT IN (SELECT id FROM table); 将自增ID重新排列,回填未使用的ID ALTER TABLE table AUTO_INCREMENT = 100000; 再次分配自增ID,填充使用过的ID通过定期执行以上步骤,可以回收未使用的ID,避免自增ID过快消耗。需要注意的是,这样会对现有的数据造成影响,需要谨慎操作。通常可以在业务低峰期才执行。整体来说,定期清理空闲ID可以约束自增ID的增长,但不应该作为主要解决方案。与扩容、分库分表等结合使用可以达到更好的效果。 使用分布式ID生成器可以考虑使用分布式ID生成器,实现全局唯一ID,避免单点自增ID的瓶颈。
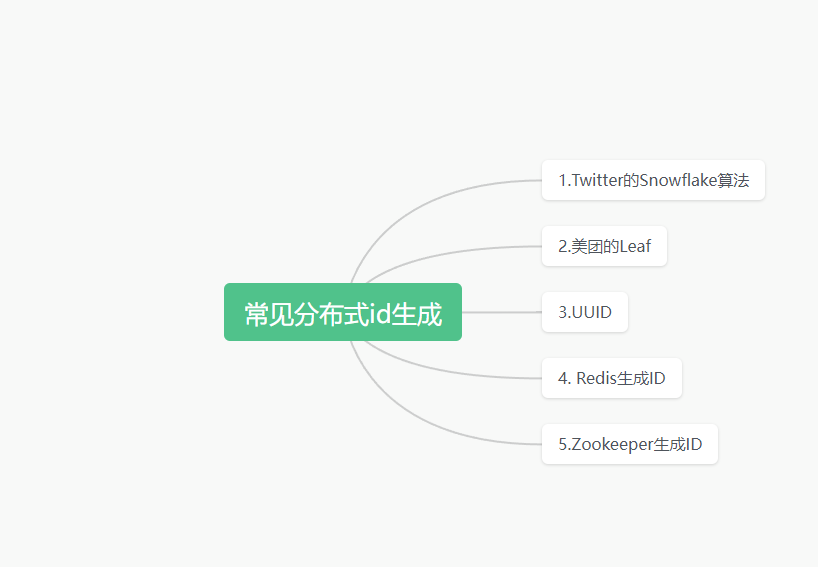
常见的分布式ID生成器方案包括: Twitter的Snowflake算法 Snowflake可以生成全局唯一的ID,依赖机器ID和进程ID来保证不同机器不同进程生成的ID不重复。美团的Leaf Leaf也是采用Snowflake改进的可扩展ID生成框架,支持指定数据中心ID。UUID 使用无序的UUID作为主键,缺点是主键索引效率低。Redis生成ID 利用Redis的原子INCR命令生成全局唯一ID。Zookeeper生成ID 也可以基于Zookeeper的顺序性实现分布式ID生成。 应用程序直接集成以上开源方案,即可抛弃MySQL的自增ID,实现水平扩展。 当然,这需要应用系统支持使用非连续自增的分布式ID,会增加部分复杂度。 整体来说,引入分布式ID生成器是非常可行的解决方案,可以避免MySQL自增ID的单点问题 总结选择合适的方案来防止和应对自增ID用尽的问题,保证系统运行稳定。 请注意,在执行之前,建议备份数据库以防止数据丢失或错误。此外,这些可能会涉及到一些复杂的操作,所以谨慎操作,并根据你的具体情况进行调整。最好在一个测试环境中先尝试这些步骤,以确保其适用于你的情况。 写在最后感谢您的支持和鼓励! 😊🙏 如果大家对相关文章感兴趣,可以关注公众号"架构殿堂",会持续更新AIGC,java基础面试题, netty, spring boot, spring cloud等系列文章,一系列干货随时送达! |
【本文地址】
今日新闻 |
推荐新闻 |