Python实战 |
您所在的位置:网站首页 › lol脚本实战视频在线观看 › Python实战 |
Python实战
|
阅读本文需要 5.8 分钟。文章同步发于微信公众号 somenzz,欢迎订阅,使用Python打造效率工具。 时间是公平的,因为每个人的一分钟都是 60 秒;时间又是最不公平的,有人一年的收获顶得上别人十年,这取决于如何利用时间。 成年人的世界,一个字忙,忙得没有时间学习,没有时间健身,没有时间陪家人。其实解决忙这个问题很简单,那就是做减法,减去不必要的应酬、会议,减去不重要的事项,只保留那些重要的,有意义的,所谓永远只做那些重要不紧急的事情。另外节省时间的方法就是借助工具,提高效率。 这些年流行网络课程学习,在职人士尤其如此,有些课程,需要你花钱去用心学;有些课程,别人花了钱你也得学,什么学习积分,学习报表,积累学时等等,还与绩效、职称挂勾。后者大概率不许快进,这样就要花费时间点击播放,再点击再播放,直到看完完成任务。 如果你知道 Python,其实应对一些不得不看的在线课程,非常简单,可以写代码让它全部自动播放,最近就有个朋友让我帮助开发一个可以自动播放网课的工具,来缓解大量线上学习的压力,感觉这一过程应该有不少人需要,特些记录下来,可以帮助有同样需求的朋友。 如果对技术无感,想直接使用现成的工具,请稳步:https://t.zsxq.com/7yzF23R 如果手撸代码,请继续。 网址:http://jxjy.jxt.zj.gov.cn/iext/zgProject/index.jsp,请自行注册账号。 网站风格如下:  第一步:登陆。 第一步:登陆。登陆前,先打开开发者工具(Chrome浏览器的快捷键是F12),然后登陆,查看接口返回数据:  点击这个login的接口,查看详细信息如下: 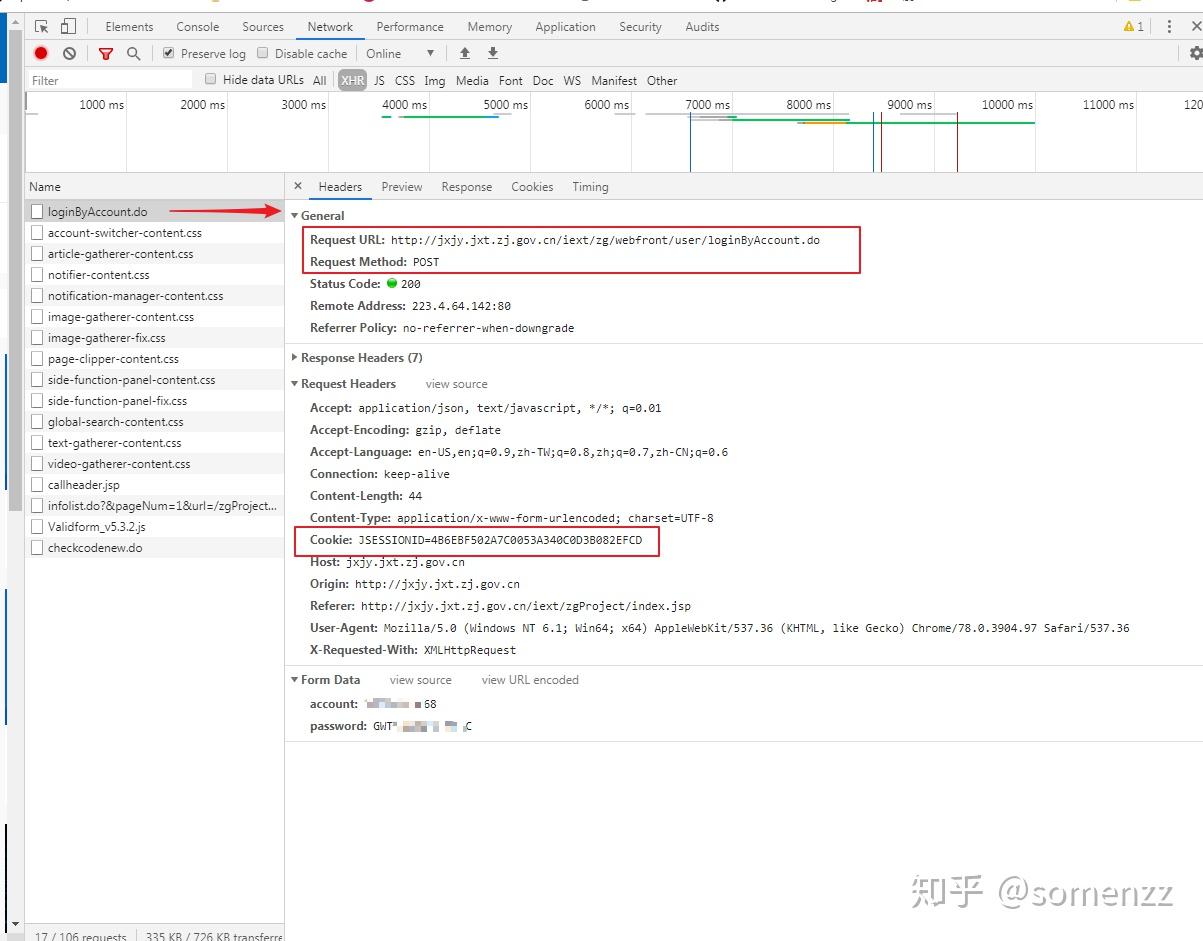 这点重点记录四个信息: 1、请求的接口地址,即图中的 Request URL 及请求的方法。 2、Cookie 中的信息,这里是 JSESSIONID。 3、传递的参数和返回的接口数据。 根据这些信息,使用 requests 库自带的 session 功能很容易写出登陆的代码,并且可以获取此处的 JSESSIONID,可以大致推测出后续的请求也是使用该 JSESSIONID。 import requests session = requests.Session() headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest', } def login(): params = { 'account': your_username, 'password': your_password, } r = session.post("http://jxjy.jxt.zj.gov.cn/iext/zg/webfront/user/loginByAccount.do", params=params,headers = headers) jsessionid = session.cookies.get('JSESSIONID') return jsessionid第二步:获取信息。登陆后, 获取到了 JSESSIONID。接下来,我们看到登陆后,还有一个接口,返回的是视频课程的列表,此接口使用的 JSESSIONID 和登陆是一致的,可以推断出 JSESSIONID 是后续接口请求的凭证,不过这个凭证是记录在 cookie 中的,requests 的 session 功能可以自带 cookie 请求,因此不需要单独处理。这里就是着重要分析的地方: 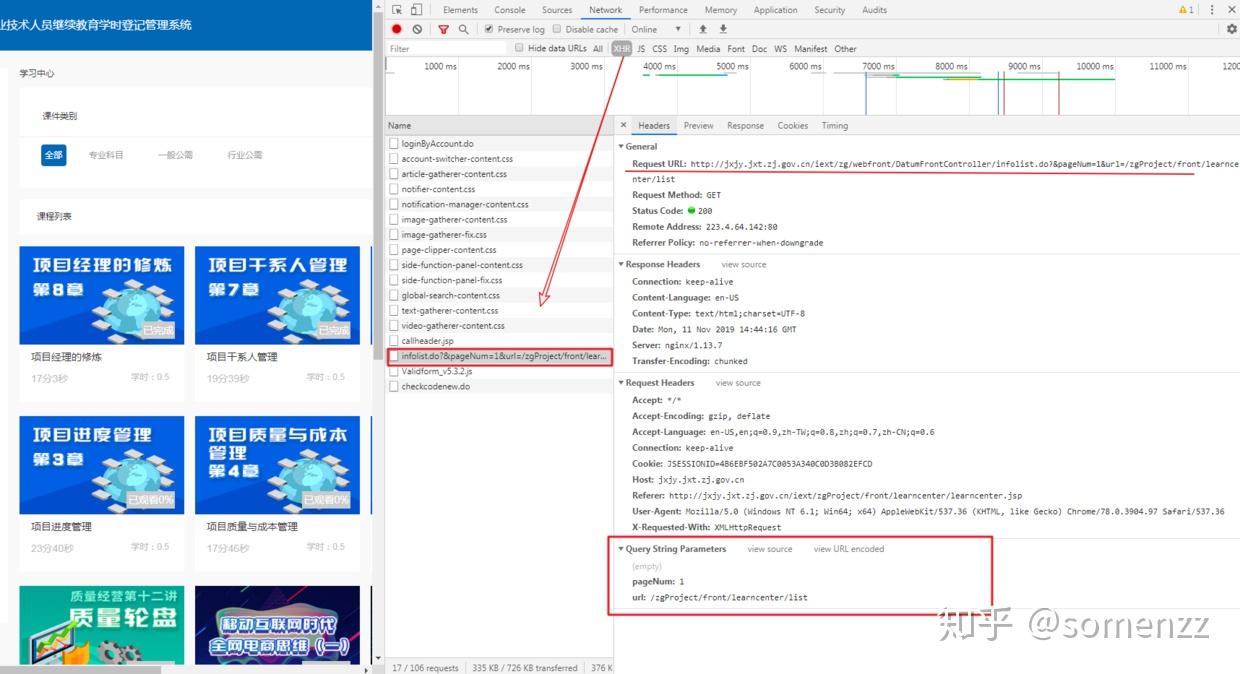 我们可以从这里获取课程的名称,持续时间,学习进度,编号等信息,有了这些信息,就可以为后续接口的请求提供参数了。方法有很多,正则表达式,BeautifulSoup,Selenium 喜欢哪个就用哪个吧,我这里使用 BeautifulSoup。参考代码如下: def get_play_list_info(): video_list = [] for i in range(4): params = { 'pageNum': i + 1, 'url': '/zgProject/front/learncenter/list' } r = session.get("http://jxjy.jxt.zj.gov.cn/iext/zg/webfront/DatumFrontController/infolist.do", params, headers ) soup = BeautifulSoup(r, "html.parser") for el in soup.findAll("div", {'onclick': re.compile("skip(.*)")}): video_name = el.find("div", {'class': 'clearfix'}).get('title') function_name = el.get('onclick') video_id = function_name.split(",")[0].split('(')[1].strip() progress = el.find("span", {'class': 'baif'}).get_text() durationTime = el.find("span", {'class': 'durationTime'}).get_text() if progress != '已完成': video_list.append({'video_name': video_name, 'video_id': video_id, 'progress': progress, 'durationTime': int(durationTime)}) logger.info(f"共 {len(video_list)} 个待播放的课程,将依次播放:") for video in video_list: logger.info(f"{video['video_name']},总时长:{video['durationTime']}秒") return video_list 第三步:分析视频播放进度保存逻辑。 第三步:分析视频播放进度保存逻辑。以上步骤,可以获取所有未完成的课程列表,包括名称、ID,持续时长,当前进度等信息。接下来,我们点击一个视频播放,然后看看接口处有什么信息:  这里我们发现请求的参数中有两个,一个是 time,值是 110,一个是 zgcid,可以猜测,time 是秒数,zgcid 是对应的是视频课程的编号。过一会时间,发现又发送了请求:  此时 time 为 226,发现间隔了约 120 秒钟,继续观察: 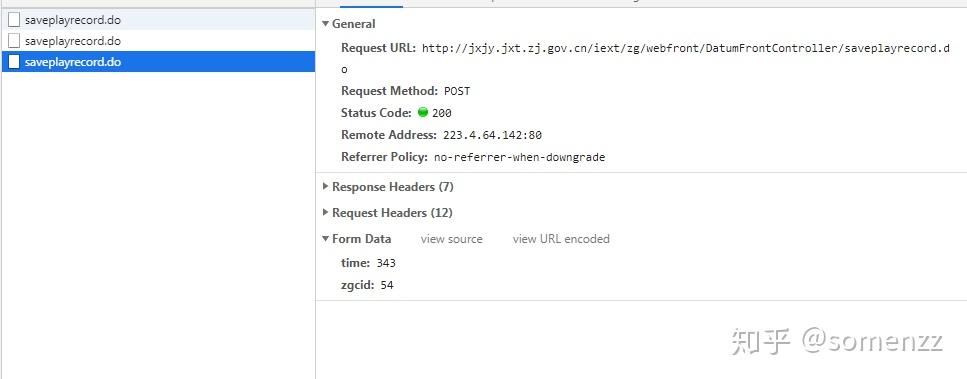 接口名称叫 saveplayrecord,很容易猜测到,每隔 120 秒发送向服务器一次这样的请求,就代表向服务汇报,我当前已经观看到了这个位置,当 time 为视频的总持续时长时,视频播放的状态会显示为已完成。 def play_video(video): logger.info(f"{video['video_name']} 开始播放..." ) params = { 'url': '/zgProject/front/learncenter/videocast2', 'zgcid': video['video_id'] } session.get("http://jxjy.jxt.zj.gov.cn/iext/zg/webfront/DatumFrontController/detail.do", params, headers) percent = float(video['progress'].replace("已观看","").replace("%","").strip()) cnt = int(video['durationTime']*percent/100) logger.info(f"当前进度:{percent:0.2f}%") while cnt video['durationTime']: cnt = video['durationTime'] params = {'time':cnt, 'zgcid':video['video_id'] } r = session.post("http://jxjy.jxt.zj.gov.cn/iext/zg/webfront/DatumFrontController/saveplayrecord.do", params,headers) if r.json()['success'] == 1: logger.info(f"播放进度为: {cnt*100/video['durationTime']:0.2f}%") logger.info(f"{video['video_name']} 播放完成。" )到这里,我们发现播放视频的过程中,每隔两分钟,网站会向服务器发送一次请求,保存当前视频的播放进度。此时已经豁然开朗。接下来就是组装代码的事情了。 用代码小结login() videos = get_play_list_info() for video in videos: play_video(video) print("视频播放完毕")爬虫的本质在于获取信息,获取信息的前提是知道信息发送和接收的方式,因此如果本文看不太懂的朋友,建义先花费 1 - 2 个小时看下 HTTP 协议,再学习下非常适合人类使用的 Python 第三方库 requests,之后再看此文,就十分简单。 (完) |
【本文地址】