Scikit |
您所在的位置:网站首页 › load_digits最佳得分模型 › Scikit |
Scikit
|
文章目录
计算交叉验证度量`cross_validate`函数和多指标评估通过交叉验证获取预测结果
交叉验证迭代器适用于独立同分布数据的交叉验证迭代器K折交叉验证重复K折交叉验证留一法交叉验证(LOO)留 P 出法(LPO)随机排列交叉验证(Shuffle & Split)
基于类别标签的分层交叉验证迭代器分层 k 折交叉验证分层随机拆分
适用于分组数据的交叉验证迭代器分组 k 折交叉验证分层分组 k 折交叉验证留一组交叉验证留 P 组交叉验证组洗牌拆分
预定义的折叠拆分 / 验证集使用交叉验证迭代器拆分训练和测试集时间序列数据的交叉验证时间序列拆分
关于洗牌的说明交叉验证和模型选择排列测试分数
sklearn.model_selection
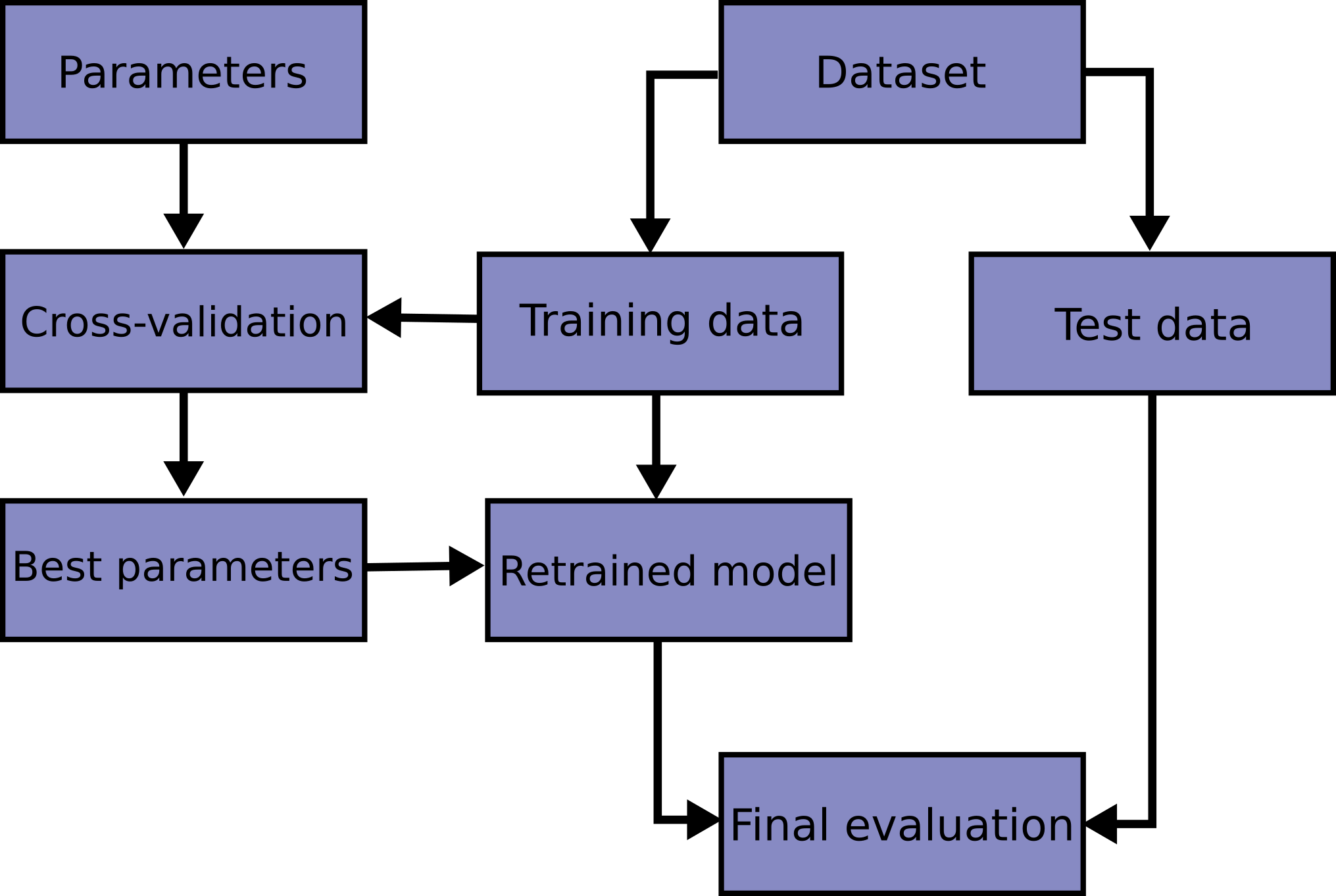
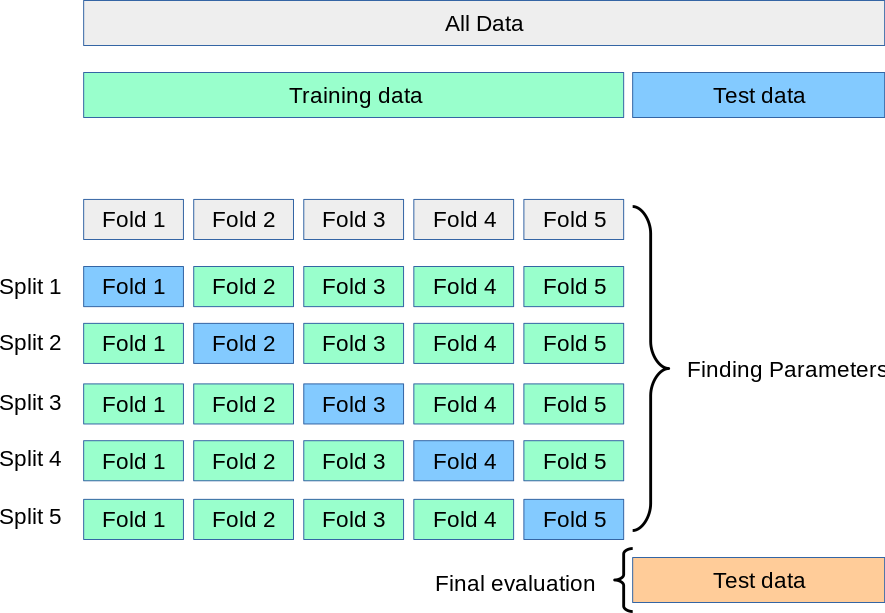
在同一数据上学习预测函数的参数并对其进行测试是一种方法上的错误:一个只会重复刚刚看到的样本标签的模型将具有完美的得分,但在尚未见过的数据上无法预测任何有用的信息。这种情况被称为过拟合。为了避免这种情况,在进行(监督)机器学习实验时,通常会将部分可用数据保留为测试集X_test, y_test。请注意,单词“实验”并不仅仅指学术用途,因为即使在商业环境中,机器学习通常也是从实验开始的。下面是模型训练中典型交叉验证工作流程的流程图。最佳参数可以通过网格搜索技术确定。
在scikit-learn中,可以使用train_test_split辅助函数快速计算训练集和测试集的随机拆分。让我们加载鸢尾花数据集,对其进行线性支持向量机拟合: >>> import numpy as np >>> from sklearn.model_selection import train_test_split >>> from sklearn import datasets >>> from sklearn import svm >>> X, y = datasets.load_iris(return_X_y=True) >>> X.shape, y.shape ((150, 4), (150,))现在,我们可以在保留40%的数据用于测试(评估)分类器的同时,快速抽样出一个训练集: >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, test_size=0.4, random_state=0) >>> X_train.shape, y_train.shape ((90, 4), (90,)) >>> X_test.shape, y_test.shape ((60, 4), (60,)) >>> clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train) >>> clf.score(X_test, y_test) 0.96...当评估估计器的不同设置(“超参数”)时,例如必须手动设置的SVM的C设置,仍然存在在测试集上过拟合的风险,因为可以调整参数直到估计器表现最佳。这样,关于测试集的知识就会“泄漏”到模型中,评估指标不再报告泛化性能。为了解决这个问题,可以将数据集的另一部分保留为所谓的“验证集”:训练在训练集上进行,然后在验证集上进行评估,当实验似乎成功时,可以在测试集上进行最终评估。 然而,通过将可用数据分成三组,我们大大减少了可用于学习模型的样本数量,并且结果可能取决于对(训练,验证)集对的特定随机选择。 解决这个问题的方法是一种称为交叉验证(CV)的过程。仍然应该保留一个测试集进行最终评估,但在进行CV时不再需要验证集。在基本方法中,称为k-fold CV,训练集被分成k个较小的集合(其他方法在下面描述,但通常遵循相同的原则)。对于k个“折叠”中的每一个,按照以下步骤进行: 使用k-1个折叠作为训练数据训练模型;使用剩余的部分数据验证生成的模型(即,将其用作测试集来计算性能度量,如准确率)。k-fold交叉验证报告的性能度量是循环中计算的值的平均值。这种方法可能计算成本高昂,但不会浪费太多数据(与固定任意验证集的情况相比),这在样本数量非常小的逆推问题中是一个重要优势。
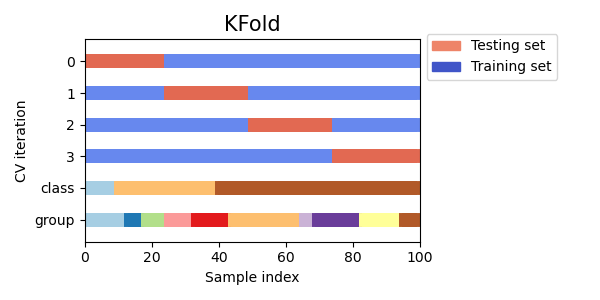
使用交叉验证的最简单方法是在估计器和数据集上调用cross_val_score辅助函数。 以下示例演示了如何通过拆分数据集、拟合模型和计算得分来估计鸢尾花数据集上线性核支持向量机的准确性,每次连续进行5次(每次使用不同的拆分): >>> from sklearn.model_selection import cross_val_score >>> clf = svm.SVC(kernel='linear', C=1, random_state=42) >>> scores = cross_val_score(clf, X, y, cv=5) >>> scores array([0.96..., 1. , 0.96..., 0.96..., 1. ])因此,平均得分和标准差为: >>> print("%0.2f accuracy with a standard deviation of %0.2f" % (scores.mean(), scores.std())) 0.98 accuracy with a standard deviation of 0.02默认情况下,每次CV迭代计算的得分是估计器的score方法。可以通过使用scoring参数来更改这一点: >>> from sklearn import metrics >>> scores = cross_val_score( ... clf, X, y, cv=5, scoring='f1_macro') >>> scores array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])有关详细信息,请参见scoring_parameter。在鸢尾花数据集的情况下,样本在目标类之间平衡,因此准确率和F1分数几乎相等。 当cv参数是一个整数时,默认情况下,cross_val_score使用KFold或StratifiedKFold策略,如果估计器派生自ClassifierMixin,则使用后者。 还可以通过传递交叉验证迭代器来使用其他交叉验证策略,例如: >>> from sklearn.model_selection import ShuffleSplit >>> n_samples = X.shape[0] >>> cv = ShuffleSplit(n_splits=5, test_size=0.3, random_state=0) >>> cross_val_score(clf, X, y, cv=cv) array([0.977..., 0.977..., 1. ..., 0.955..., 1. ])另一种选择是使用可迭代对象,该对象生成作为索引数组的(训练,测试)拆分,例如: >>> def custom_cv_2folds(X): ... n = X.shape[0] ... i = 1 ... while i >> custom_cv = custom_cv_2folds(X) >>> cross_val_score(clf, X, y, cv=custom_cv) array([1. , 0.973...])使用留出数据进行数据转换 与在训练中保留数据进行测试一样重要的是,预处理(例如标准化、特征选择等)和类似的数据转换也应该从训练集中学习,并应用于保留数据进行预测: >>> from sklearn import preprocessing >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, test_size=0.4, random_state=0) >>> scaler = preprocessing.StandardScaler().fit(X_train) >>> X_train_transformed = scaler.transform(X_train) >>> clf = svm.SVC(C=1).fit(X_train_transformed, y_train) >>> X_test_transformed = scaler.transform(X_test) >>> clf.score(X_test_transformed, y_test) 0.9333...Pipeline 使得组合估计器更容易,在交叉验证下提供此行为: >>> from sklearn.pipeline import make_pipeline >>> clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1)) >>> cross_val_score(clf, X, y, cv=cv) array([0.977..., 0.933..., 0.955..., 0.933..., 0.977...])请参见combining_estimators。 cross_validate函数和多指标评估cross_validate函数与cross_val_score有两个不同之处: 它允许指定多个评估指标。 对于单指标评估,其中评分参数是字符串、可调用对象或None,键将是['test_score', 'fit_time', 'score_time']。对于多指标评估,返回值是一个带有以下键的字典 - ['test_', 'test_', 'test_', 'fit_time', 'score_time']。 return_train_score 默认设置为False,以节省计算时间。要评估训练集上的分数,您需要将其设置为True。您还可以通过设置return_estimator=True来保留每个训练集上拟合的估计器。类似地,您可以设置return_indices=True来保留用于将数据集拆分为训练集和测试集的训练和测试索引。 多个指标可以指定为预定义评分器名称的列表、元组或集合: from sklearn.model_selection import cross_validate from sklearn.metrics import recall_score scoring = ['precision_macro', 'recall_macro'] clf = svm.SVC(kernel='linear', C=1, random_state=0) scores = cross_validate(clf, X, y, scoring=scoring) sorted(scores.keys()) # Output: ['fit_time', 'score_time', 'test_precision_macro', 'test_recall_macro'] scores['test_recall_macro'] # Output: array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])或者作为将评分器名称映射到预定义或自定义评分函数的字典: from sklearn.metrics import make_scorer scoring = {'prec_macro': 'precision_macro', 'rec_macro': make_scorer(recall_score, average='macro')} scores = cross_validate(clf, X, y, scoring=scoring, cv=5, return_train_score=True) sorted(scores.keys()) # Output: ['fit_time', 'score_time', 'test_prec_macro', 'test_rec_macro', # 'train_prec_macro', 'train_rec_macro'] scores['train_rec_macro'] # Output: array([0.97..., 0.97..., 0.99..., 0.98..., 0.98...])下面是使用单个指标的cross_validate的示例: scores = cross_validate(clf, X, y, scoring='precision_macro', cv=5, return_estimator=True) sorted(scores.keys()) # Output: ['estimator', 'fit_time', 'score_time', 'test_score'] 通过交叉验证获取预测结果cross_val_predict函数与cross_val_score具有类似的接口,但对于输入中的每个元素,它返回在该元素在测试集中时获得的预测结果。只能使用将所有元素分配给测试集一次的交叉验证策略(否则会引发异常)。 [!WARNING] 关于不适当使用cross_val_predict的注意事项 cross_val_predict的结果可能与使用cross_val_score获得的结果不同,因为元素的分组方式不同。cross_val_score函数对交叉验证折叠进行平均,而cross_val_predict仅返回几个不可区分的模型的标签(或概率)。因此,cross_val_predict不是衡量泛化误差的适当指标。 cross_val_predict函数适用于以下情况: 可视化来自不同模型的预测结果。模型混合:将一个监督学习器的预测用于训练集合另一个学习器的集成方法。可用的交叉验证迭代器在下一节中介绍。 示例 sphx_glr_auto_examples_model_selection_plot_roc_crossval.py,sphx_glr_auto_examples_feature_selection_plot_rfe_with_cross_validation.py,sphx_glr_auto_examples_model_selection_plot_grid_search_digits.py,sphx_glr_auto_examples_model_selection_plot_grid_search_text_feature_extraction.py,sphx_glr_auto_examples_model_selection_plot_cv_predict.py,sphx_glr_auto_examples_model_selection_plot_nested_cross_validation_iris.py。 交叉验证迭代器以下部分列出了可用于根据不同的交叉验证策略生成数据集拆分索引的实用程序。 适用于独立同分布数据的交叉验证迭代器假设一些数据是独立同分布(i.i.d.)的,是假设所有样本都来自同一生成过程,并且生成过程假定没有记忆过去生成的样本。 以下交叉验证器可用于这种情况。 [!NOTE] 虽然独立同分布数据是机器学习理论中的常见假设,但在实践中很少成立。如果知道样本是使用时间相关的过程生成的,使用时间序列感知的交叉验证方案更安全。同样,如果我们知道生成过程具有组结构(从不同主体、实验、测量设备收集的样本),使用分组交叉验证更安全。 K折交叉验证KFold将所有样本分为 k k k组样本,称为折叠(如果 k = n k=n k=n,则等效于“留一法”策略),大小相等(如果可能)。使用 k − 1 k-1 k−1个折叠来学习预测函数,留下的折叠用于测试。 在具有4个样本的数据集上进行2折交叉验证的示例: import numpy as np from sklearn.model_selection import KFold X = ["a", "b", "c", "d"] kf = KFold(n_splits=2) for train, test in kf.split(X): print("%s %s" % (train, test)) # Output: # [2 3] [0 1] # [0 1] [2 3]以下是交叉验证行为的可视化。请注意,KFold不受类别或组的影响。
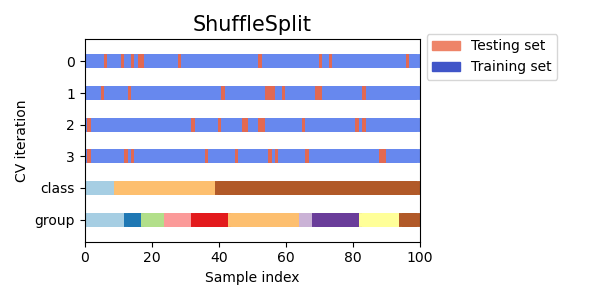
每个折叠由两个数组组成:第一个与训练集相关,第二个与测试集相关。因此,可以使用numpy索引创建训练/测试集: X = np.array([[0., 0.], [1., 1.], [-1., -1.], [2., 2.]]) y = np.array([0, 1, 0, 1]) X_train, X_test, y_train, y_test = X[train], X[test], y[train], y[test] 重复K折交叉验证RepeatedKFold重复K折交叉验证n次。当需要运行KFold n次,每次产生不同的拆分时,可以使用它。 2折K折交叉验证重复2次的示例: import numpy as np from sklearn.model_selection import RepeatedKFold X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) random_state = 12883823 rkf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=random_state) for train, test in rkf.split(X): print("%s %s" % (train, test)) # Output: # [2 3] [0 1] # [0 1] [2 3] # [0 2] [1 3] # [1 3] [0 2]类似地,RepeatedStratifiedKFold重复Stratified K-Fold n次,并在每次重复中进行不同的随机化。 留一法交叉验证(LOO)LeaveOneOut(或LOO)是一种简单的交叉验证方法。每个学习集是通过除一个样本之外的所有样本创建的,测试集是剩下的样本。因此,对于 n n n个样本,我们有 n n n个不同的训练集和 n n n个不同的测试集。这种交叉验证过程不会浪费太多数据,因为只有一个样本从训练集中删除: from sklearn.model_selection import LeaveOneOut X = [1, 2, 3, 4] loo = LeaveOneOut() for train, test in loo.split(X): print("%s %s" % (train, test)) # Output: # [1 2 3] [0] # [0 2 3] [1] # [0 1 3] [2] # [0 1 2] [3]使用LOO进行模型选择的潜在用户应权衡一些已知的注意事项。与 k k k折交叉验证相比,LOO从 n n n个样本中构建 n n n个模型,而不是 k k k个模型,其中 n > k n > k n>k。此外,每个模型都是在 n − 1 n-1 n−1个样本上训练,而不是 ( k − 1 ) n / k (k-1)n/k (k−1)n/k。在这两种方式中,假设 k k k不是太大且 k < n k < n k 1 时,测试集会有重叠。 以下是在具有 4 个样本的数据集上进行 Leave-2-Out 的示例: >>> from sklearn.model_selection import LeavePOut >>> X = np.ones(4) >>> lpo = LeavePOut(p=2) >>> for train, test in lpo.split(X): ... print("%s %s" % (train, test)) [2 3] [0 1] [1 3] [0 2] [1 2] [0 3] [0 3] [1 2] [0 2] [1 3] [0 1] [2 3] 随机排列交叉验证(Shuffle & Split)ShuffleSplit迭代器将生成用户定义数量的独立训练/测试数据集拆分。首先对样本进行洗牌,然后将其拆分为一对训练集和测试集。 可以通过显式设置random_state伪随机数生成器的种子来控制结果的随机性,以便重现结果。 以下是使用示例: >>> from sklearn.model_selection import ShuffleSplit >>> X = np.arange(10) >>> ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state=0) >>> for train_index, test_index in ss.split(X): ... print("%s %s" % (train_index, test_index)) [9 1 6 7 3 0 5] [2 8 4] [2 9 8 0 6 7 4] [3 5 1] [4 5 1 0 6 9 7] [2 3 8] [2 7 5 8 0 3 4] [6 1 9] [4 1 0 6 8 9 3] [5 2 7]以下是交叉验证行为的可视化。请注意,ShuffleSplit不受类别或分组的影响。
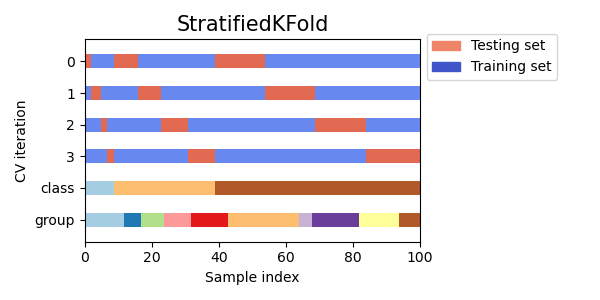
因此,ShuffleSplit是对于需要对迭代次数和训练/测试拆分的样本比例进行更精细控制的KFold交叉验证的良好替代方法。 基于类别标签的分层交叉验证迭代器某些分类问题可能在目标类别的分布上存在严重不平衡:例如,负样本可能比正样本多几倍。在这种情况下,建议使用分层抽样,即StratifiedKFold和StratifiedShuffleSplit,以确保每个训练和验证折中的目标类别的相对频率大致保持一致。 分层 k 折交叉验证StratifiedKFold是k折的一种变体,它返回分层的折叠:每个集合中的样本百分比与完整集合中的每个目标类别的样本百分比大致相同。 以下是在具有两个不平衡类别的 50 个样本的数据集上进行分层 3 折交叉验证的示例。我们显示了每个类别中的样本数量,并与KFold进行比较。 >>> from sklearn.model_selection import StratifiedKFold, KFold >>> import numpy as np >>> X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5)) >>> skf = StratifiedKFold(n_splits=3) >>> for train, test in skf.split(X, y): ... print('train - {} | test - {}'.format( ... np.bincount(y[train]), np.bincount(y[test]))) train - [30 3] | test - [15 2] train - [30 3] | test - [15 2] train - [30 4] | test - [15 1] >>> kf = KFold(n_splits=3) >>> for train, test in kf.split(X, y): ... print('train - {} | test - {}'.format( ... np.bincount(y[train]), np.bincount(y[test]))) train - [28 5] | test - [17] train - [28 5] | test - [17] train - [34] | test - [11 5]我们可以看到,StratifiedKFold在训练集和测试集中保持了类别比例(大约为 1/10)。 以下是交叉验证行为的可视化。
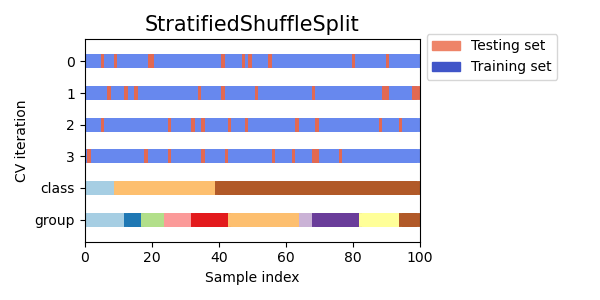
RepeatedStratifiedKFold可用于在每次重复中使用不同的随机化重复 Stratified K-Fold n 次。 分层随机拆分StratifiedShuffleSplit是ShuffleSplit的一种变体,它返回分层拆分,即创建的拆分保持与完整集合中每个目标类别的相同百分比。 以下是交叉验证行为的可视化。
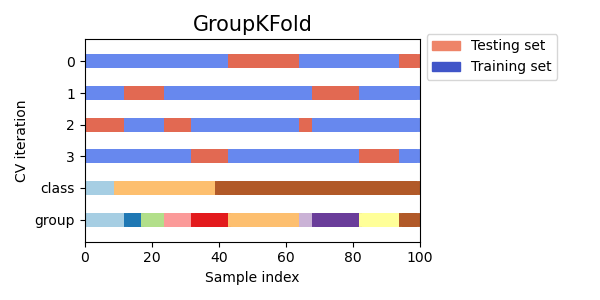
如果底层生成过程产生依赖样本的组,则独立同分布(i.i.d.)假设将被打破。 这种数据的分组是特定于领域的。例如,当从多个患者收集医学数据时,每个患者可能会采集多个样本。这样的数据很可能依赖于个体组。在我们的示例中,每个样本的患者 ID 将是其组标识符。 在这种情况下,我们希望知道在特定组的训练集上训练的模型是否能很好地推广到未见过的组。为了衡量这一点,我们需要确保验证折中的所有样本都来自于在配对的训练折中根本没有代表的组。 以下交叉验证分割器可用于实现此目的。样本的分组标识符通过groups参数指定。 分组 k 折交叉验证GroupKFold是确保相同组在测试和训练集中均不出现的 k 折的变体。例如,如果数据来自不同的主题,每个主题有几个样本,并且如果模型足够灵活以从高度个人化的特征中学习,它可能无法推广到新的主题。GroupKFold使得能够检测到这种过拟合情况。 假设有三个主题,每个主题都有从 1 到 3 的关联编号: >>> from sklearn.model_selection import GroupKFold >>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10] >>> y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"] >>> groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3] >>> gkf = GroupKFold(n_splits=3) >>> for train, test in gkf.split(X, y, groups=groups): ... print("%s %s" % (train, test)) [0 1 2 3 4 5] [6 7 8 9] [0 1 2 6 7 8 9] [3 4 5] [3 4 5 6 7 8 9] [0 1 2]每个主题在不同的测试折中,同一个主题既不在测试集中也不在训练集中。请注意,由于数据不平衡,折叠的大小不完全相同。如果必须在折叠之间平衡类别比例,则StratifiedGroupKFold是更好的选择。 以下是交叉验证行为的可视化。
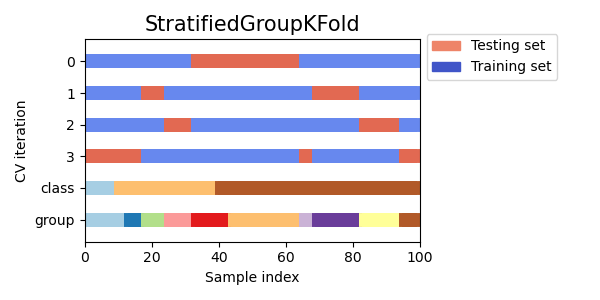
与KFold类似,GroupKFold的测试集将形成所有数据的完整分区。与KFold不同的是,GroupKFold完全不随机化,而KFold在shuffle=True时是随机化的。 分层分组 k 折交叉验证示例: >>> from sklearn.model_selection import StratifiedGroupKFold >>> X = list(range(18)) >>> y = [1] * 6 + [0] * 12 >>> groups = [1, 2, 3, 3, 4, 4, 1, 1, 2, 2, 3, 4, 5, 5, 5, 6, 6, 6] >>> sgkf = StratifiedGroupKFold(n_splits=3) >>> for train, test in sgkf.split(X, y, groups=groups): ... print("%s %s" % (train, test)) [ 0 2 3 4 5 6 7 10 11 15 16 17] [ 1 8 9 12 13 14] [ 0 1 4 5 6 7 8 9 11 12 13 14] [ 2 3 10 15 16 17] [ 1 2 3 8 9 10 12 13 14 15 16 17] [ 0 4 5 6 7 11]实现说明: 在当前实现中,大多数情况下无法进行完全洗牌。当 shuffle=True 时,会发生以下情况: 所有组都被洗牌。使用稳定排序按类别的标准差对组进行排序。对排序后的组进行迭代,并将其分配给折叠。这意味着只有具有相同类别分布标准差的组才会被洗牌,这在每个组只有一个类别时可能很有用。 该算法贪婪地将每个组分配给 n_splits 个测试集之一,选择使得测试集中类别分布的方差最小的测试集。组分配按类频率方差从高到低的顺序进行,即首先分配具有峰值在一个或几个类别上的大组。 这种分割在某种意义上是次优的,即使可以实现完美的分层。如果每个组中的类别分布相对接近,请使用 GroupKFold。 下图是不均匀组的交叉验证行为的可视化效果:
LeaveOneGroupOut 是一种交叉验证方案,其中每个拆分保留属于一个特定组的样本。组信息通过一个数组提供,该数组编码了每个样本的组。 因此,每个训练集由除了特定组相关样本之外的所有样本组成。这与 LeavePGroupsOut(n_groups=1)和 GroupKFold(n_splits 等于传递给 groups 参数的唯一标签数)相同。 例如,在多个实验的情况下,可以使用 LeaveOneGroupOut 基于不同实验创建交叉验证:我们使用除一个实验之外的所有实验的样本创建一个训练集: >>> from sklearn.model_selection import LeaveOneGroupOut >>> X = [1, 5, 10, 50, 60, 70, 80] >>> y = [0, 1, 1, 2, 2, 2, 2] >>> groups = [1, 1, 2, 2, 3, 3, 3] >>> logo = LeaveOneGroupOut() >>> for train, test in logo.split(X, y, groups=groups): ... print("%s %s" % (train, test)) [2 3 4 5 6] [0 1] [0 1 4 5 6] [2 3] [0 1 2 3] [4 5 6]另一个常见的应用是使用时间信息:例如,组可以是样本的收集年份,从而允许针对基于时间的拆分进行交叉验证。 留 P 组交叉验证LeavePGroupsOut 类似于 LeaveOneGroupOut,但是对于每个训练/测试集,它会删除与 P P P 组相关的样本。对于 P > 1 P>1 P>1,会留下 P P P 组的所有可能组合,这意味着测试集将重叠。 Leave-2-Group Out 的示例: >>> from sklearn.model_selection import LeavePGroupsOut >>> X = np.arange(6) >>> y = [1, 1, 1, 2, 2, 2] >>> groups = [1, 1, 2, 2, 3, 3] >>> lpgo = LeavePGroupsOut(n_groups=2) >>> for train, test in lpgo.split(X, y, groups=groups): ... print("%s %s" % (train, test)) [4 5] [0 1 2 3] [2 3] [0 1 4 5] [0 1] [2 3 4 5] 组洗牌拆分GroupShuffleSplit 迭代器的行为类似于 ShuffleSplit 和 LeavePGroupsOut 的组合,它为每个拆分保留一部分组。每个训练/测试拆分是独立进行的,因此连续测试集之间没有保证的关系。 以下是一个用法示例: >>> from sklearn.model_selection import GroupShuffleSplit >>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001] >>> y = ["a", "b", "b", "b", "c", "c", "c", "a"] >>> groups = [1, 1, 2, 2, 3, 3, 4, 4] >>> gss = GroupShuffleSplit(n_splits=4, test_size=0.5, random_state=0) >>> for train, test in gss.split(X, y, groups=groups): ... print("%s %s" % (train, test)) ... [0 1 2 3] [4 5 6 7] [2 3 6 7] [0 1 4 5] [2 3 4 5] [0 1 6 7] [4 5 6 7] [0 1 2 3]下图是交叉验证行为的可视化效果。
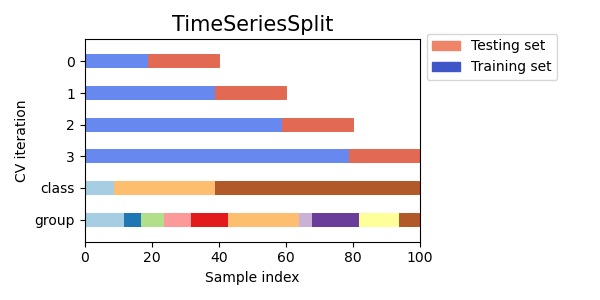
当希望实现 LeavePGroupsOut 的行为,但是组的数量足够大,以至于生成所有可能的留下 P P P 组的分区将变得非常昂贵时,GroupShuffleSplit 类提供了一个解决方案。在这种情况下,GroupShuffleSplit 提供了 LeavePGroupsOut 生成的训练/测试拆分的随机样本(带替换)。 预定义的折叠拆分 / 验证集对于某些数据集,已经存在将数据拆分为训练和验证折叠或多个交叉验证折叠的预定义拆分。使用 PredefinedSplit 可以在搜索超参数时使用这些折叠。 例如,当使用验证集时,将 test_fold 设置为所有属于验证集的样本的值为 0,其他样本的值为 -1。 使用交叉验证迭代器拆分训练和测试集上述组交叉验证函数也可以用于将数据集拆分为训练和测试子集。请注意,方便函数 train_test_split 是 ShuffleSplit 的包装器,因此仅允许分层拆分(使用类标签)并且不能考虑组。 要执行训练和测试拆分,请使用交叉验证拆分器的 split() 方法生成的生成器输出的训练和测试子集的索引。例如: >>> import numpy as np >>> from sklearn.model_selection import GroupShuffleSplit >>> X = np.array([0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001]) >>> y = np.array(["a", "b", "b", "b", "c", "c", "c", "a"]) >>> groups = np.array([1, 1, 2, 2, 3, 3, 4, 4]) >>> train_indx, test_indx = next( ... GroupShuffleSplit(random_state=7).split(X, y, groups) ... ) >>> X_train, X_test, y_train, y_test = \ ... X[train_indx], X[test_indx], y[train_indx], y[test_indx] >>> X_train.shape, X_test.shape ((6,), (2,)) >>> np.unique(groups[train_indx]), np.unique(groups[test_indx]) (array([1, 2, 4]), array([3])) 时间序列数据的交叉验证时间序列数据的特点是接近时间的观测之间的相关性(自相关)。然而,经典的交叉验证技术(如 KFold 和 ShuffleSplit)假设样本是独立和同分布的,并且在时间序列数据上会导致训练和测试实例之间不合理的相关性(导致对泛化误差的估计不准确)。因此,在时间序列数据上评估模型的时候,非常重要的是使用“未来”观测来评估模型,这些观测与用于训练模型的观测最不相似。为了实现这一点,TimeSeriesSplit 提供了一种解决方案。 时间序列拆分TimeSeriesSplit 是 k-fold 的一种变体,它将前 k k k 个折叠作为训练集,第 ( k + 1 ) (k+1) (k+1) 个折叠作为测试集。请注意,与标准交叉验证方法不同,连续的训练集是前面的训练集的超集。此外,它将所有多余的数据添加到第一个训练分区,该分区始终用于训练模型。 该类可用于交叉验证以固定时间间隔观察的时间序列数据样本。 在具有 6 个样本的数据集上进行 3 折时间序列交叉验证的示例: >>> from sklearn.model_selection import TimeSeriesSplit import numpy as np from sklearn.model_selection import TimeSeriesSplit X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]]) y = np.array([1, 2, 3, 4, 5, 6]) tscv = TimeSeriesSplit(n_splits=3) print(tscv) for train, test in tscv.split(X): print("%s %s" % (train, test))下面是交叉验证行为的可视化。
如果数据的顺序不是任意的(例如,具有相同类别标签的样本是连续的),那么首先进行洗牌可能是获得有意义的交叉验证结果的关键。然而,如果样本不是独立同分布的,则相反的情况可能成立。例如,如果样本对应于新闻文章,并按照它们的发布时间排序,那么洗牌数据很可能会导致过拟合的模型和膨胀的验证分数:它将在与训练样本人工相似(时间上接近)的样本上进行测试。 一些交叉验证迭代器,如 KFold,在拆分数据之前具有内置的洗牌选项。请注意: 这比直接洗牌数据消耗更少的内存。默认情况下,不进行洗牌,包括通过将 cv=some_integer 指定给 cross_val_score、网格搜索等执行的(分层)K折交叉验证。请记住,train_test_split 仍然返回一个随机拆分。random_state 参数的默认值为 None,这意味着每次迭代 KFold(..., shuffle=True) 时,洗牌都会有所不同。然而,GridSearchCV 将对其 fit 方法验证的每组参数使用相同的洗牌。要获得每次拆分的相同结果,请将 random_state 设置为一个整数。有关如何控制 cv 分割器的随机性并避免常见陷阱的更多详细信息,请参见 randomness。 交叉验证和模型选择交叉验证迭代器还可以直接用于使用网格搜索为模型的最佳超参数执行模型选择。这是下一节“grid_search”的主题。 排列测试分数~sklearn.model_selection.permutation_test_score 提供了另一种评估分类器性能的方法。它提供了基于排列的 p 值,表示分类器观察到的性能是通过偶然机会获得的可能性。这个测试的零假设是分类器无法利用特征和标签之间的任何统计依赖关系来对留出数据进行正确预测。~sklearn.model_selection.permutation_test_score 通过计算数据的 n_permutations 种不同的排列来生成一个空分布。在每个排列中,标签被随机洗牌,从而消除特征和标签之间的任何依赖关系。p 值的输出是模型使用原始数据获得的交叉验证分数优于模型使用原始数据的交叉验证分数的排列的比例。为了获得可靠的结果,n_permutations 通常应大于 100,cv 应在 3-10 折之间。 低的 p 值提供了数据集中存在特征和标签之间的真实依赖关系的证据,以及分类器能够利用这一点获得良好结果。高的 p 值可能是由于特征和标签之间缺乏依赖关系(类别之间的特征值没有差异)或者因为分类器无法利用数据中的依赖关系。在后一种情况下,使用能够利用数据结构的更合适的分类器将导致较低的 p 值。 交叉验证提供了有关分类器泛化能力的信息,特别是分类器的预期错误范围。然而,在高维数据集上训练的分类器如果没有结构可能仍然比交叉验证预期的表现要好,仅仅是由于偶然性。这通常会发生在少于几百个样本的小数据集中。~sklearn.model_selection.permutation_test_score 提供了关于分类器是否找到了真实的类结构的信息,并有助于评估分类器的性能。 重要的是要注意,即使数据中只有弱结构,这个测试也被证明会产生低的 p 值,因为在相应的排列数据集中绝对没有结构。因此,该测试只能显示模型可靠地优于随机猜测的情况。 最后,~sklearn.model_selection.permutation_test_score 是使用蛮力计算的,并在内部拟合了 (n_permutations + 1) * n_cv 个模型。因此,它只适用于拟合单个模型非常快的小数据集。 示例 sphx_glr_auto_examples_model_selection_plot_permutation_tests_for_classification.py参考文献: Ojala 和 Garriga. Permutation Tests for Studying Classifier Performance。 10. Mach. Learn. Res. 2010. |

【本文地址】