|
KNN 聚类算法
交流学术思想,加入Q群 号:815783932
通俗定义,物以类聚,人以群分。将数据代入算法,距离较近的就是同一类,对真实的数据进行聚类。
KNN的算法原理: 欧几里得原理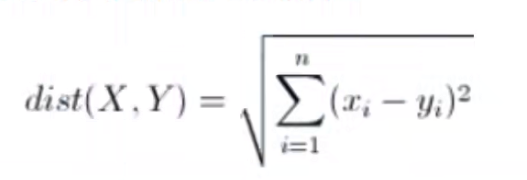 其实就是多维数据之间的绝对距离计算公式,距离近的话就会被划分为一个类别。 其实就是多维数据之间的绝对距离计算公式,距离近的话就会被划分为一个类别。
k值是可变的,表示投票权重,就是概率问题,算法根据概率做选择。
KNN 算法优缺点
缺点: 时间和空间复杂度太高了, 不适合训练数据过大的。
优点:理解起来很简单,入门就能学会使用。
代码实现简单一点的。  举一个简单的电影多分类问题根据特征。 举一个简单的电影多分类问题根据特征。
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
#将数据读入 划分成x为特征,y为label 标签类型
content=pd.read_excel(r'D:\Program Files\untitled3\venv\江苏银行比赛\KNN算法的演示.xlsx')
x =content[[ '血腥镜头', '恋爱镜头', '打架镜头']]
y =content['分类']
##下面直接调用KNN算法 这里的k的意思是 选取几个点聚合成为一类。
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(x,y)
接下来我们自己创建两条数据进行预测就能清楚的看到预测的结果
x_test = np.array([[50,0,4],[1,45,2]])
y_test=knn.predict(x_test)
print(y_test)
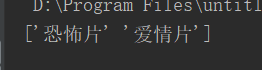 这种方法虽然很简单,但是处理起维度较大的数据是不能的,后期会更新如何调参,如果找到最优的分类结果,可以关注我会定期更新算法的合集。 这种方法虽然很简单,但是处理起维度较大的数据是不能的,后期会更新如何调参,如果找到最优的分类结果,可以关注我会定期更新算法的合集。 
|