机器学习算法(7) |
您所在的位置:网站首页 › k近邻聚类中的k表示 › 机器学习算法(7) |
机器学习算法(7)
|
1、K-近邻算法(KNN)概述 (有监督算法,分类算法)
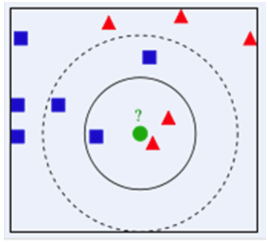
最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。 KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。 由此也说明了KNN算法的结果很大程度取决于K的选择。 在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离(城市街区距离(CityBlock distance)): 同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。 对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为: 1)计算测试数据与各个训练数据之间的距离; 2)按照距离的递增关系进行排序; 3)选取距离最小的K个点; 4)确定前K个点所在类别的出现频率; 5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。 from:http://www.cnblogs.com/ybjourney/p/4702562.html KNN的主要优点有:1) 理论成熟,思想简单,既可以用来做分类也可以用来做回归 2) 可用于非线性分类 3) 训练时间复杂度比支持向量机之类的算法低,仅为O(n) 4) 和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感 5) 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合 6)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分 KNN的不足:1、计算量大,分类速度慢 改进:浓缩训练样本集 ;加快K个最近邻的搜索速度 2、KNN在对属性较多的训练样本进行分类时,由于计算量大而使其效率大大降低效果。懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢 3、K值难以确定 · 目前没有很好的方法,一般采用先定一个初始值,然后根据实验测试的结果调整K值。 4、对不平衡样本集比较敏感 当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。改进:采用权值的方法(增大距离小的邻居样本的权值) Python实现: import numpy as np Dataset=np.array([[1.0,2.0],[1.2,0.1],[0.1,1.4],[0.3,3.5]]) labels=['A','A','B','B'] test=[1.1,0.3] k=3 #分类 diff=test-Dataset squaredist=np.sum(diff**2,axis=1) dist=squaredist**0.5 index=np.argsort(dist) dict={} for i in range(k): vote=labels[index[i]] dict[vote]=dict.get(vote,0)+1 max=0 for key,value in dict.items(): #以列表返回可遍历的(键, 值) 元组数组 if max |

【本文地址】
今日新闻 |
推荐新闻 |