Kafka、RabbitMQ、RocketMQ消息中间件的使用与比较、消息队列的应用 |
您所在的位置:网站首页 › kafka消费延迟原因 › Kafka、RabbitMQ、RocketMQ消息中间件的使用与比较、消息队列的应用 |
Kafka、RabbitMQ、RocketMQ消息中间件的使用与比较、消息队列的应用
|
一、为什么要使用消息队列
业务之间解耦合异步处理流量消峰填谷
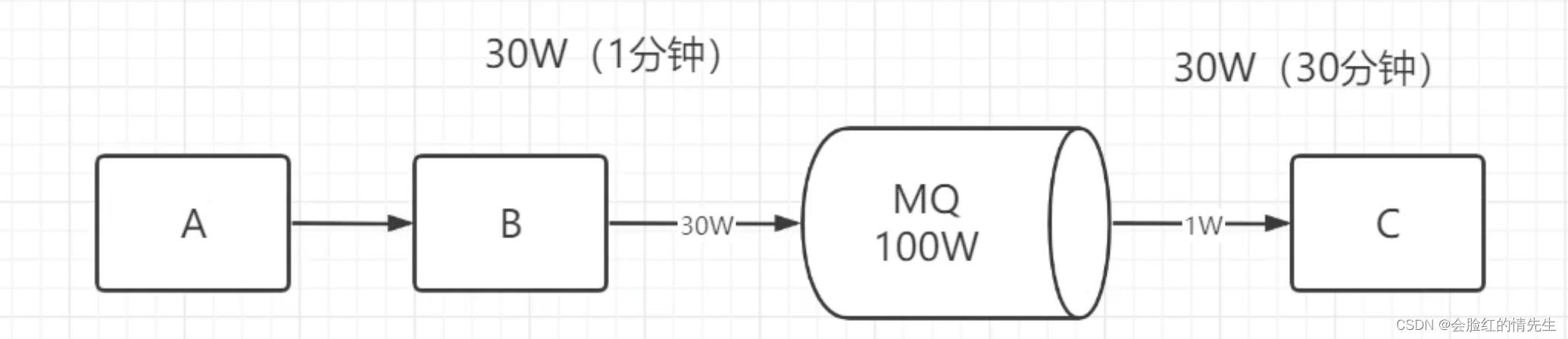
不能做限时订单 消息的延迟消费或者死信队列 六、 Kafka中可以不使用zookeeper吗在早期的kafka版本中(2.8之前)中是必须依赖zookeeper的 在后来的版本中去zk化,在自己内部创建了元数据主题。 七、为什么kafka不支持读写分离
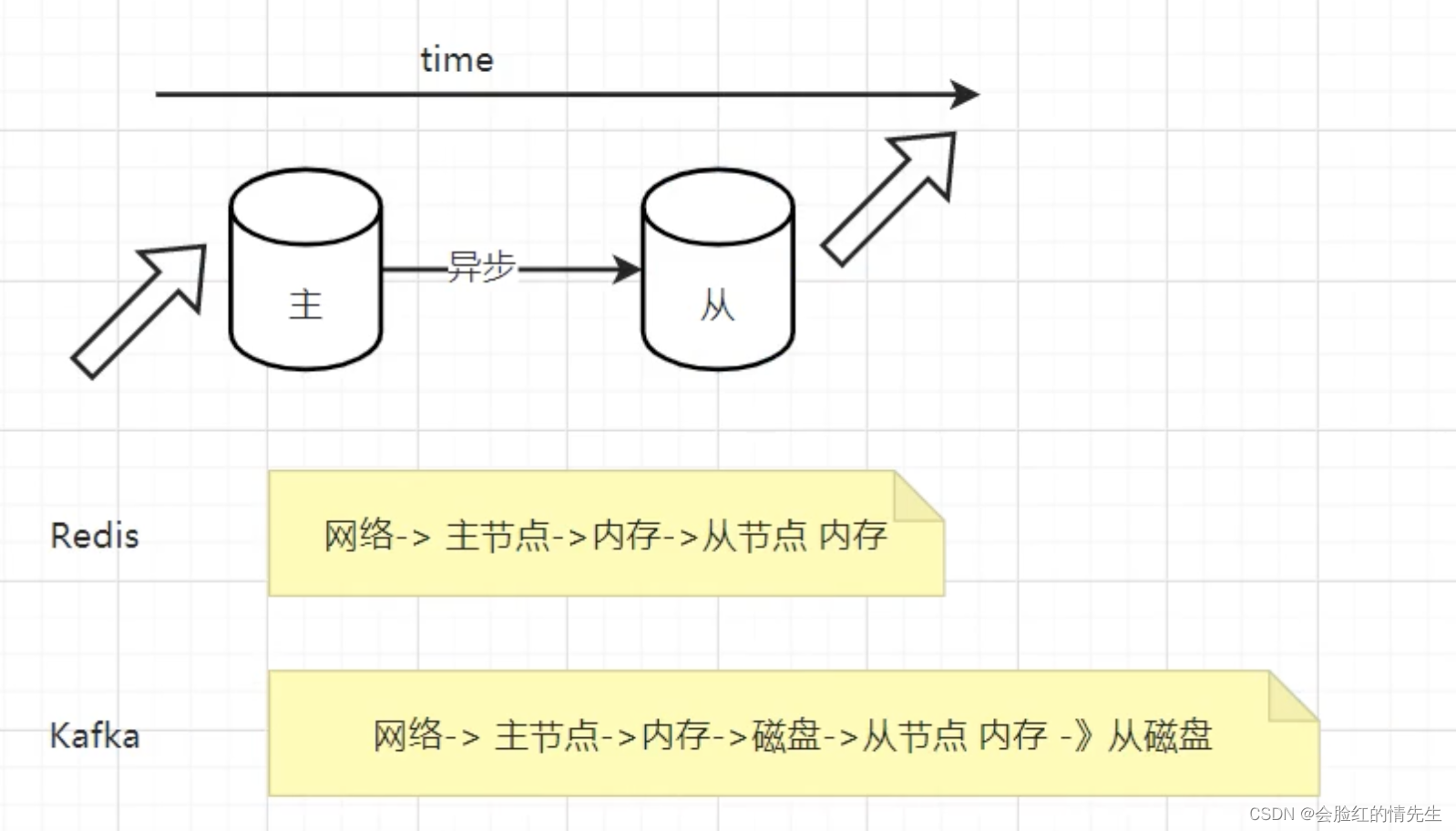
Kafka 并不支持主写从读,因为主写从读有 2 个很明 显的缺点: (1)数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。 (2)延时问题。类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经 历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比 Redis 更加耗时,它需要经历网络→主节点内存→主节点磁盘→网络→从节 点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。 八、 Kafka是怎么做到消息的有序性的
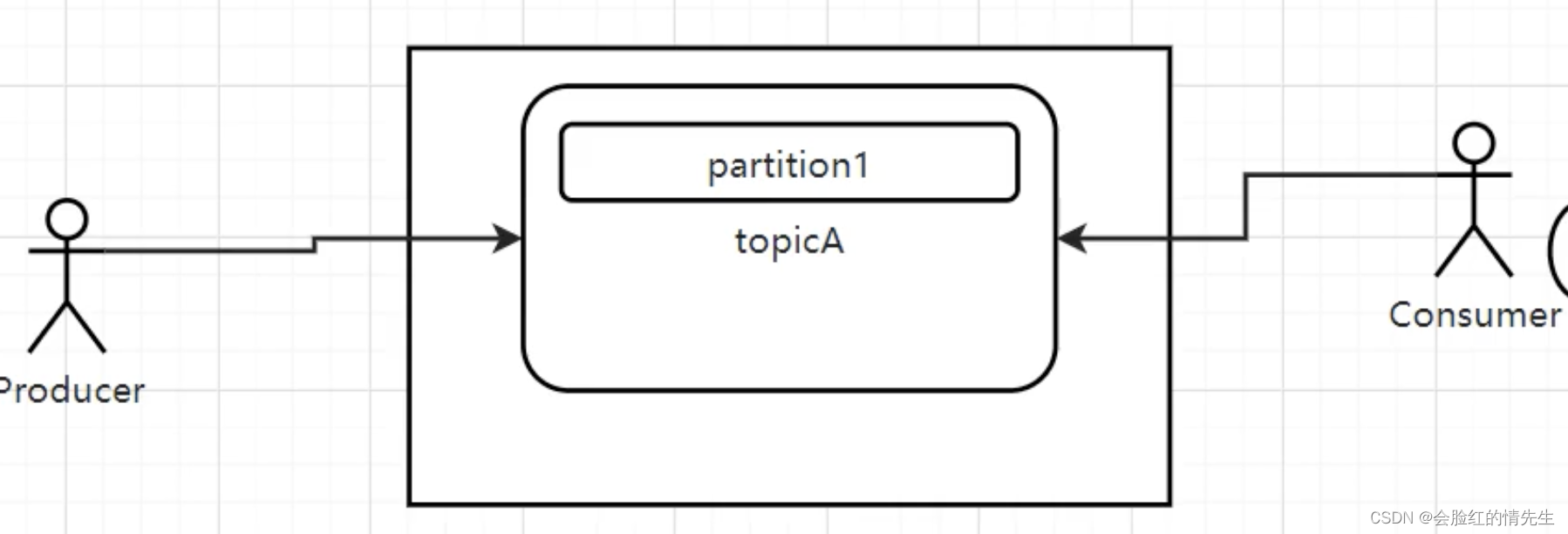
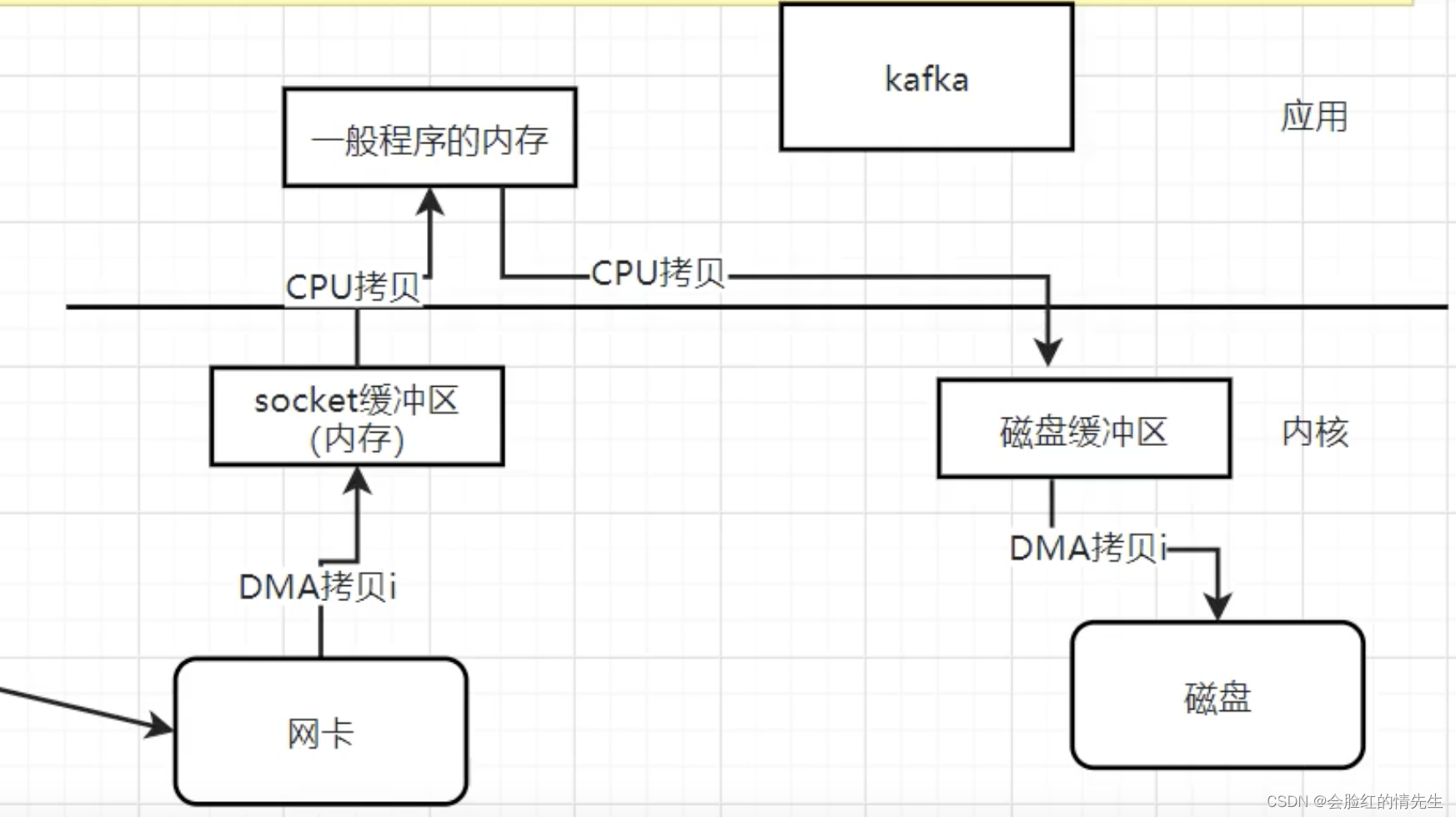
在一个主题中,只创建一个队列去实现消息的有序性。只有一个生产者、一个消费者。 九、Kafka为什么那么快 首先Kafka是利用文件方式进行存储,使用的是文件顺序读写操作,接近于内存。Kafka使用的零拷贝技术,传统的需要四次数据拷贝。大大降低消息的传递速度。sendfile技术。
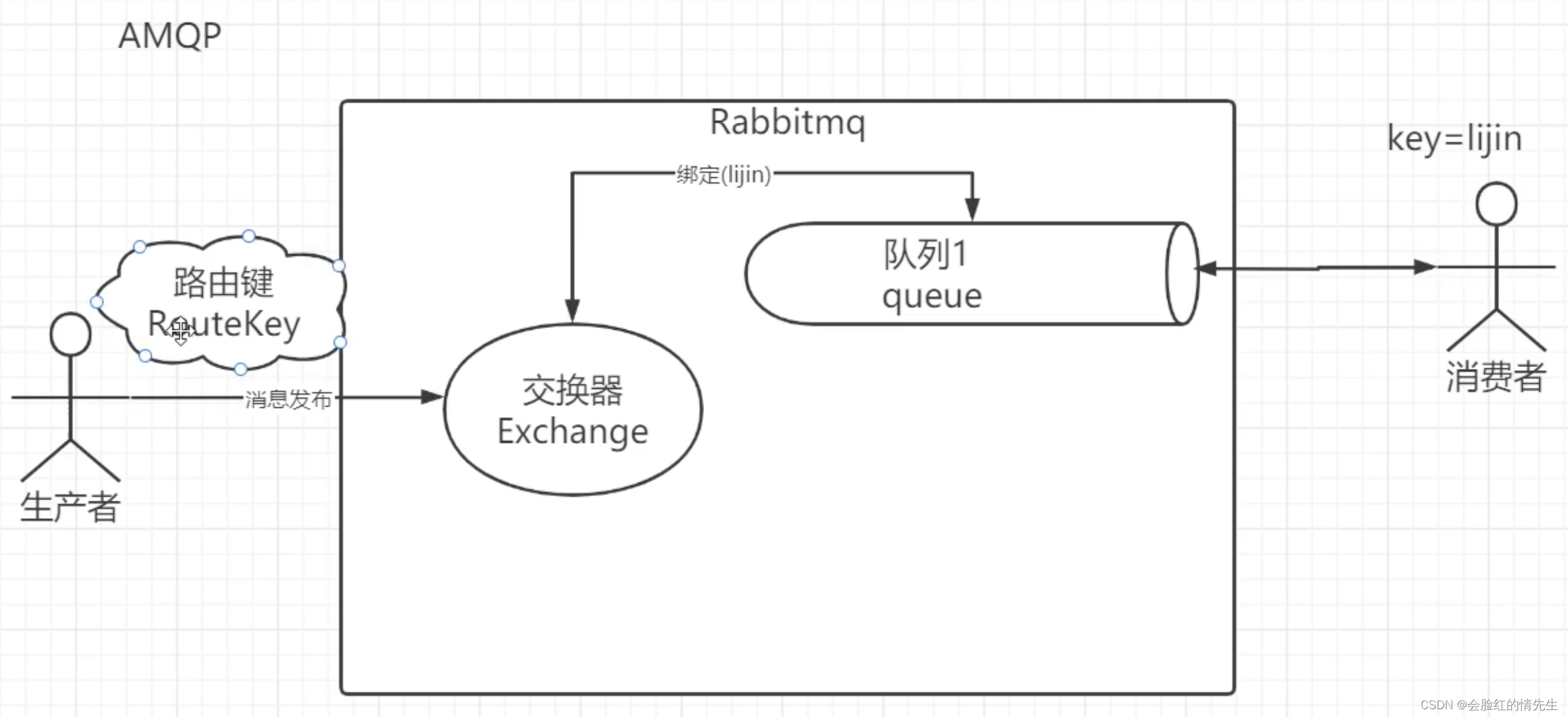
vhost可以理解为mini版的RabbitMQ,其内部均含有独立的交换机、绑定、队列,最 重要的是拥有独立的权限系统,可以做到vhost范围内的用户控制。从RabbitMQ全局考虑,不同的应用可以跑在不同的vhost上,作为不同权限隔离的手段。 十一、RabbitMQ中queue存放的message是否有数量的限制理论上是没有限制的,取决于RabbitMQ内存的大小。 但是数量是可以配置的,存储的数据量越大,处理消息的性能就会有影响,所以也需要根据自己的业务场景去配置message的数量。 x-max-lenght 对队列中消息的条数限制 x-max-lenght-bytes 对队列中的总容量大小进行限制 十二、RabbitMQ中的AMQP协议
持久化可以选择队列持久化、绑定关系持久化、交换器持久化。如果单纯的持久化某个节点,宕机后再重启可能会丢失绑定关系,找不到队列。 持久化开启后因为有了IO的操作,性能会大打折扣,性能会降到原来的1/4-1/5. 十四、RabbitMQ中交换器的四种类型Direct直接交换器 绑定建和路由建直接匹配关系 匹配不上 消息丢失 fanout广播 每个队列中都有一份消息 topic主题 主题匹配 *是一段 以.隔开 *是ceshi . /ceshi.ceshi 还有#是所有 通配符 headers(Direct) 十五、如何解决重复消费避免MQ中消息的重复消费时做幂等性处理 MVCC多版本并发控制(生产消息的时候带上数据的版本号)。利用数据库主键ID唯一性做唯一校验。例如要修改库中A表ID为1的数据,维护一张表B,B表中只有一个主键ID,在修改表A时,先将ID 1 插入B表中,如果存在重复的ID会抛错,将报错catch掉。或者留存日志记录。 十六、怎样保证RocketMQ的高可用
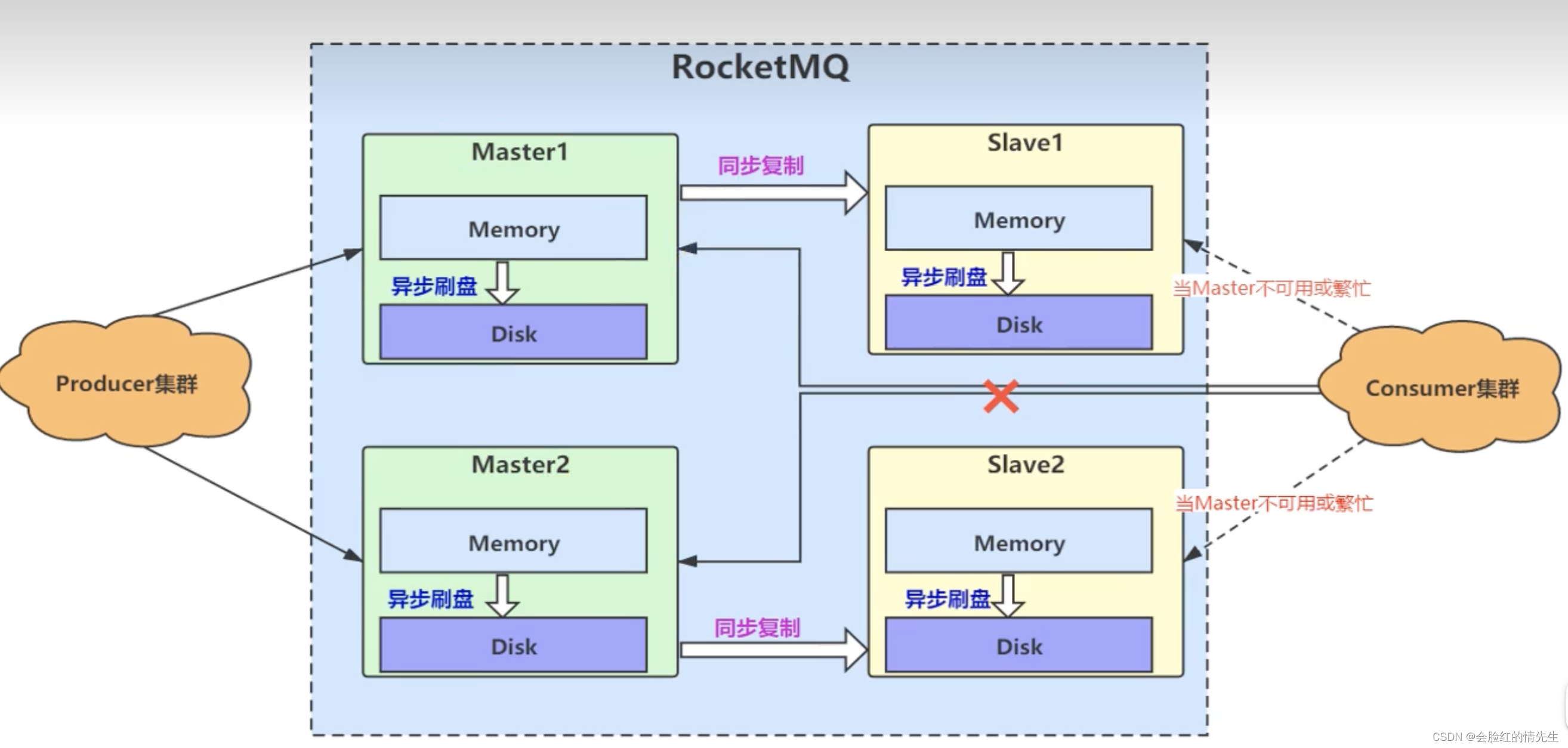
可以搭建基于同步复制、异步刷盘、多主多从的集群服务。 当消息生产者将消息推送到主节点,主节点将消息同步复制到从节点才会返回成功,这是一条完整的流程,且在内存间交互,效率相对较高。当消息推送到主节点无需等待消息刷到磁盘,就可直接返回。降低等待时间。异步刷盘。当主节点处于宕机或不可用的情况下,从节点还可以继续消费消息。多主节点,保证消息的可生产性。 十七、RocketMQ为什么那么快Netty 高效的NIO框架 RocketMQ大量使用多线程、异步 采用零拷贝技术优化 (MMAP) 性能 50%采用 文件存储,顺序读写 锁优化(CAS机制无锁化) 存储设计: 读写分离 |
【本文地址】
今日新闻 |
推荐新闻 |