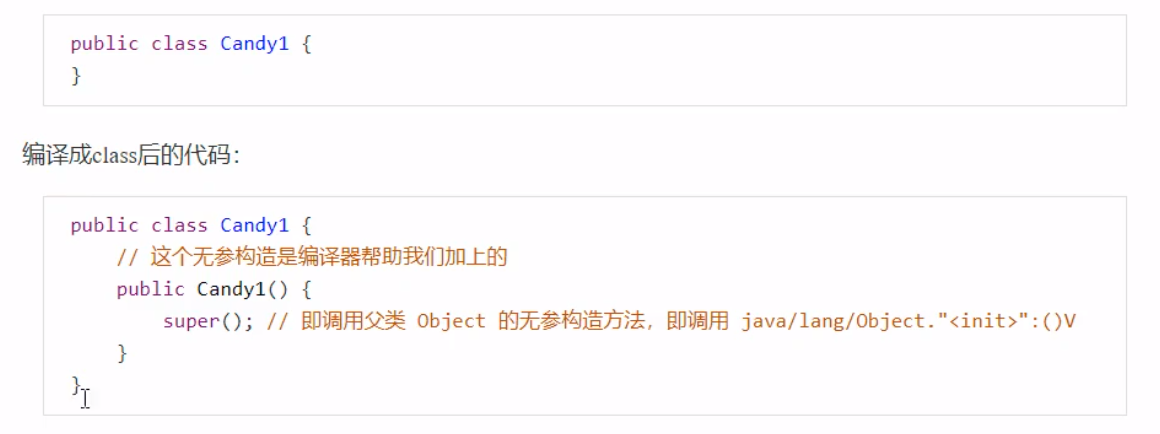
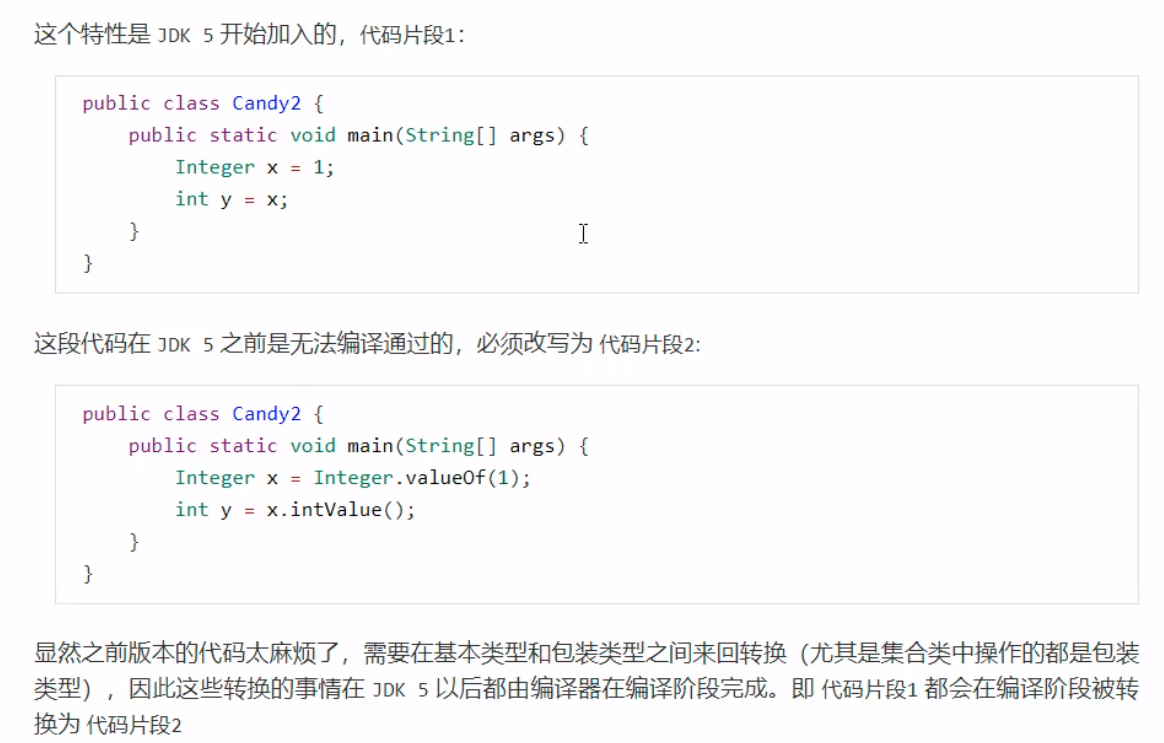
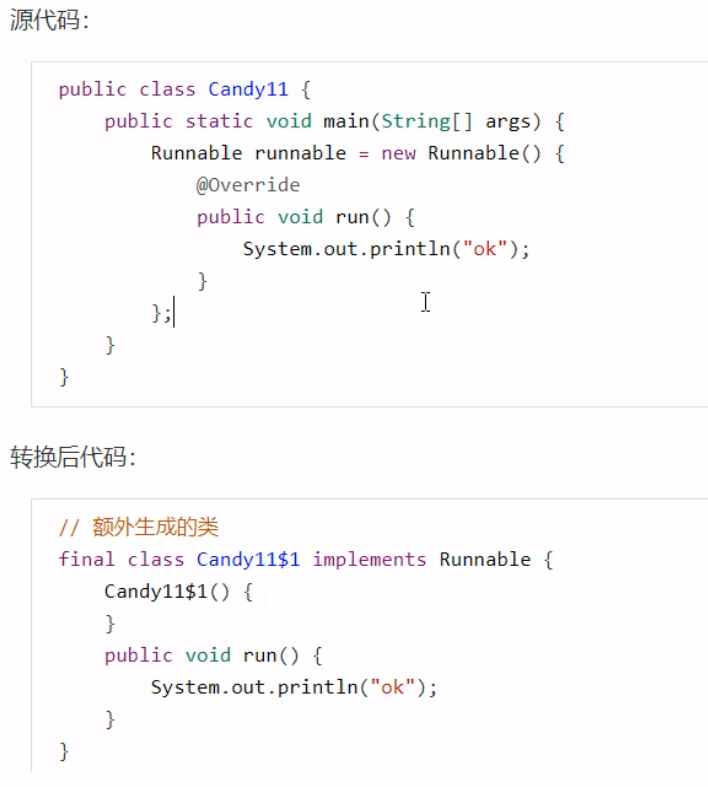
【Java】JVM |
您所在的位置:网站首页 › java溢出会导致运行时错误吗 › 【Java】JVM |
【Java】JVM
|
一、什么是JVM
定义:Java Virtual Machine - java程序的运行环境(java 二进制字节码的运行环境)好处:
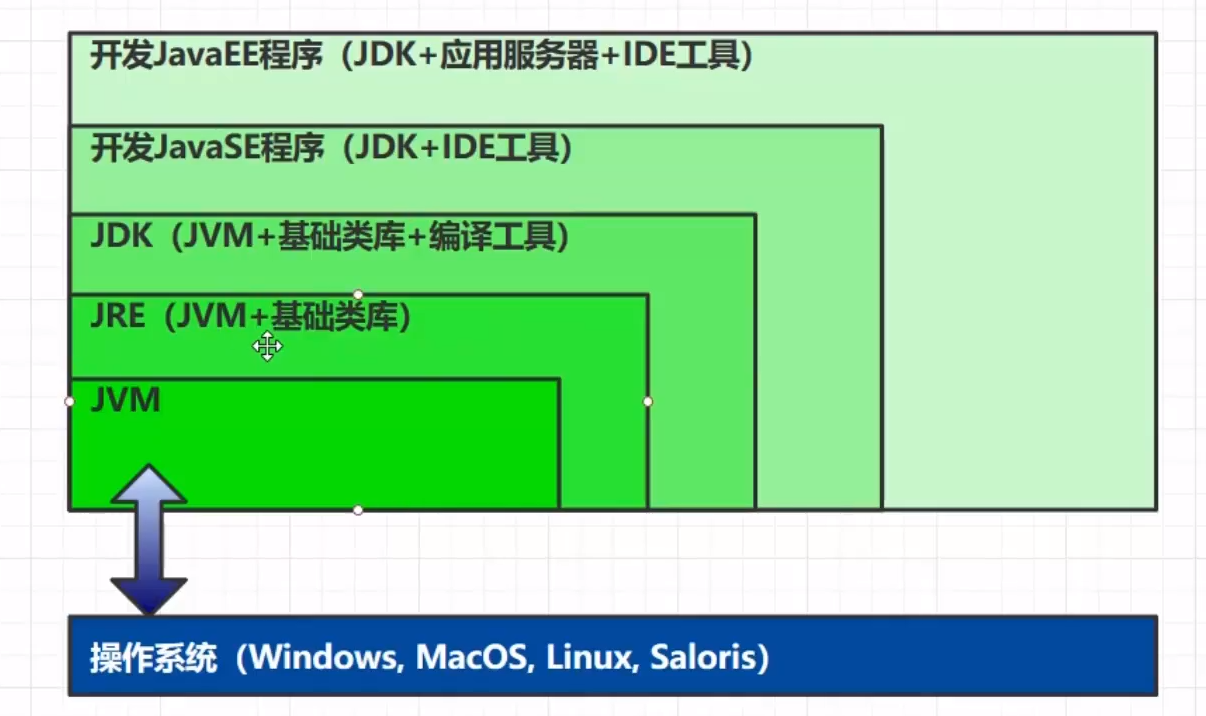
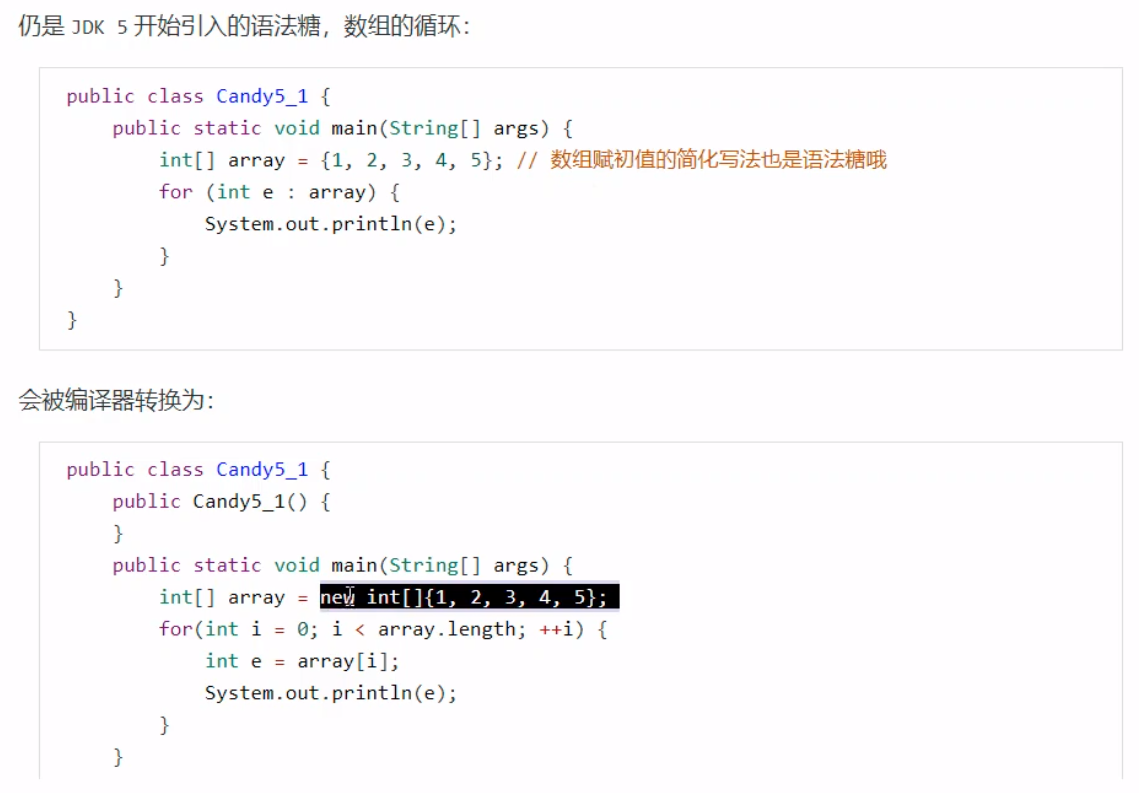
一次编写, 到处运行自动内存管理,垃圾回收功能数组下标越界越界检查多态 区别:JVM、JRE、JDK
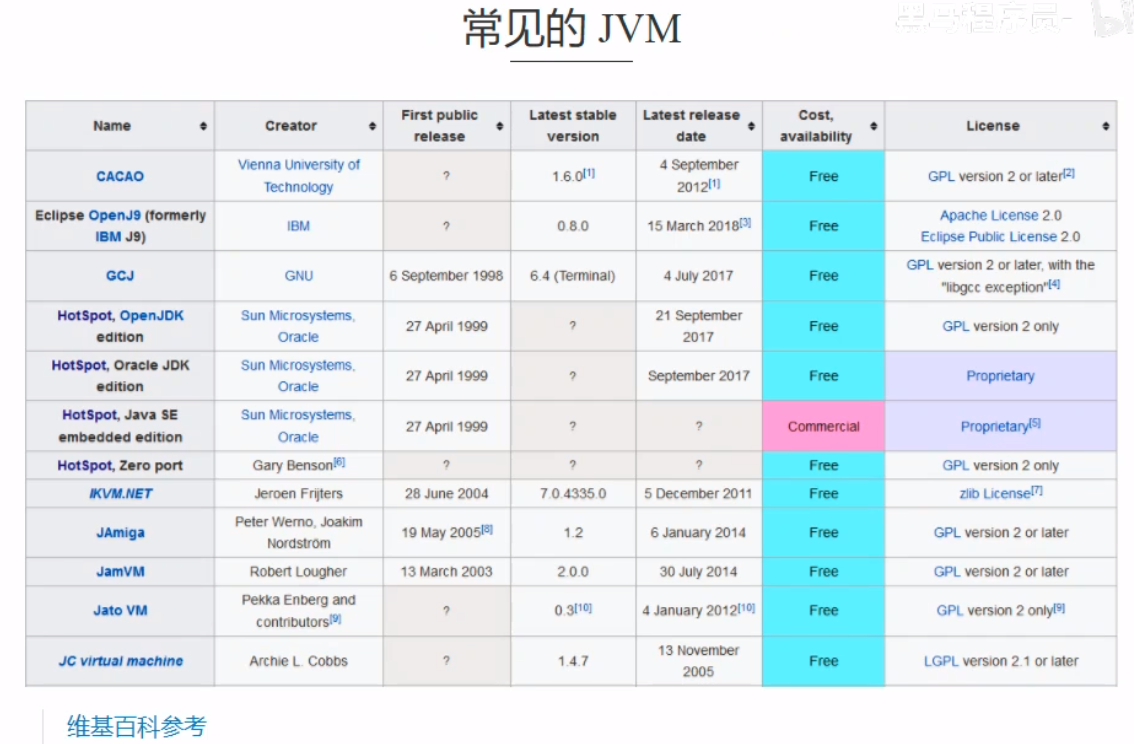
学习JVM的意义 面试理解底层的实现原理中高级程序员的必备技能常见的JVM
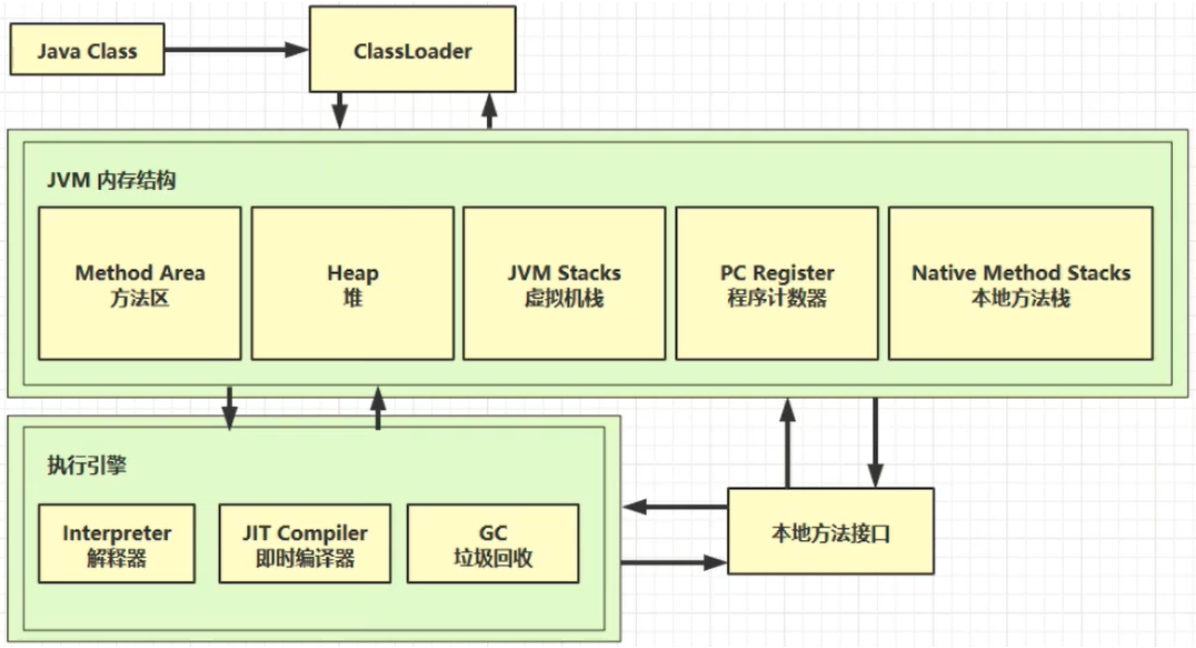
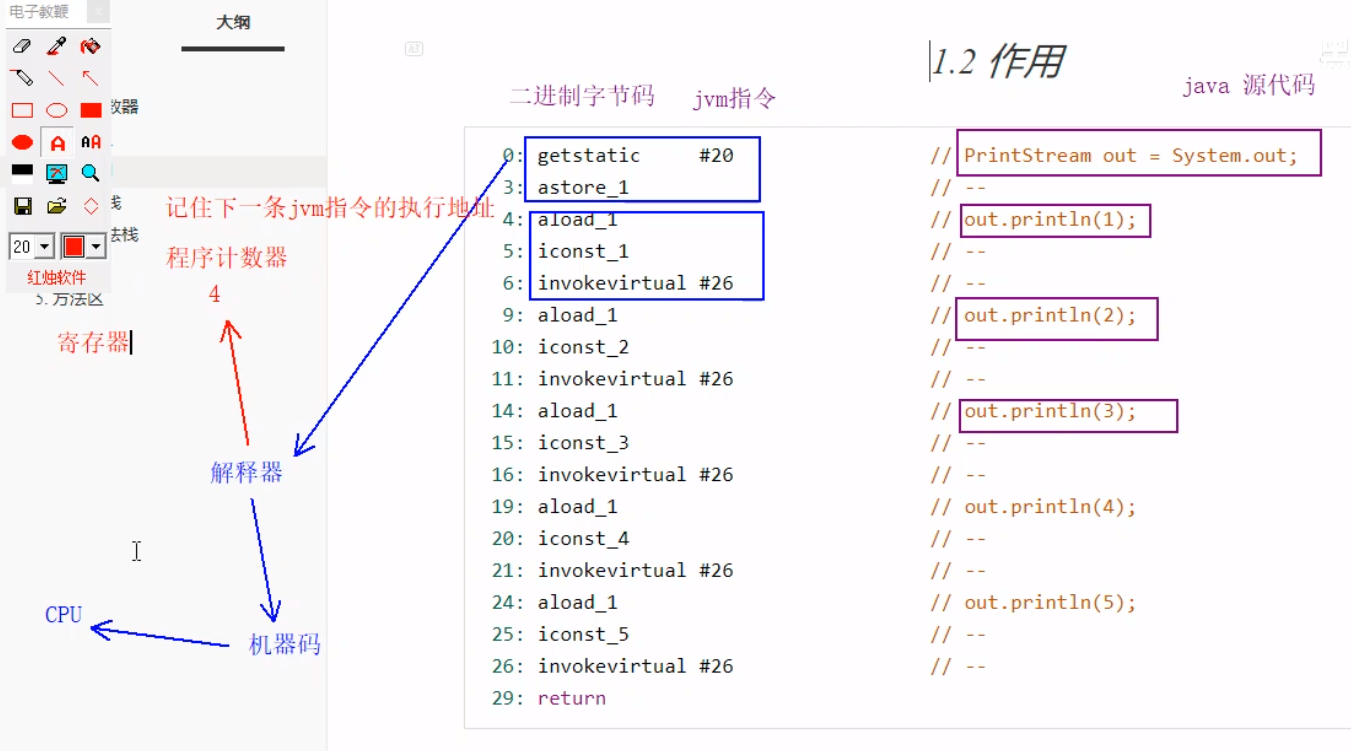
程序计数器是通过寄存器实现的,用来记住下一条JVM指令的执行地址。
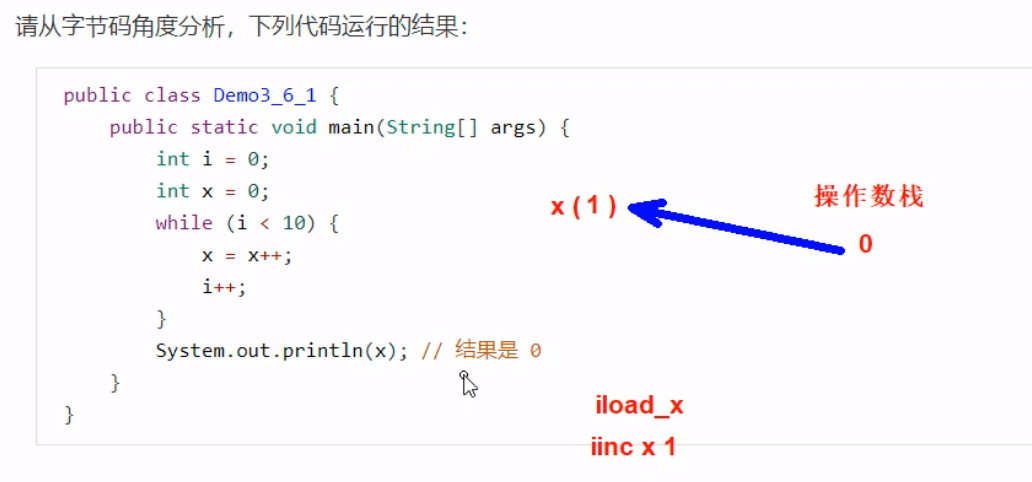
特点:①是线程私有的;②是JVM中唯一不会出现内存溢出的区域 虚拟机栈(JVM Stacks)栈:程序运行需要的内存空间 栈帧:程序运行时一次方法的调用,即每个方法运行时需要的内存 Java Virtual Machine Stacks(Java 虚拟机栈) 每个线程运行时所需要的内存,称为虚拟机栈每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存每个线程只能有一 个活动栈帧,对应着当前正在执行的那个方法问题 1.栈每次调用后会被弹出,故垃圾回收不涉及栈内存 2.栈内存分配不是越大越好,栈内存越大只是能够进行更多的方法调用,并不会使得程序运行变快 3.方法内的局部变量(非static)是线程私有的,不受到其他线程的干扰;若是线程共享的(static),需要考虑线程安全问题。总之,如果方法内局部变量没有逃离方法的作用范围,则是线程安全的;如果局部变量引用了对象,则逃离了方法的作用范围,则是线程不安全的。 栈内存溢出(java.lang.StackOverFlowError) 栈帧过多(比如方法的递归调用,若设置条件不正确陷入过多次循环;json数据转换也有可能出现,使用@jsonIgnore解决) 栈帧过大(单个栈帧的内存过大) 线程运行诊断 1.CPU占用过多 2.程序运行很长时间没有结果
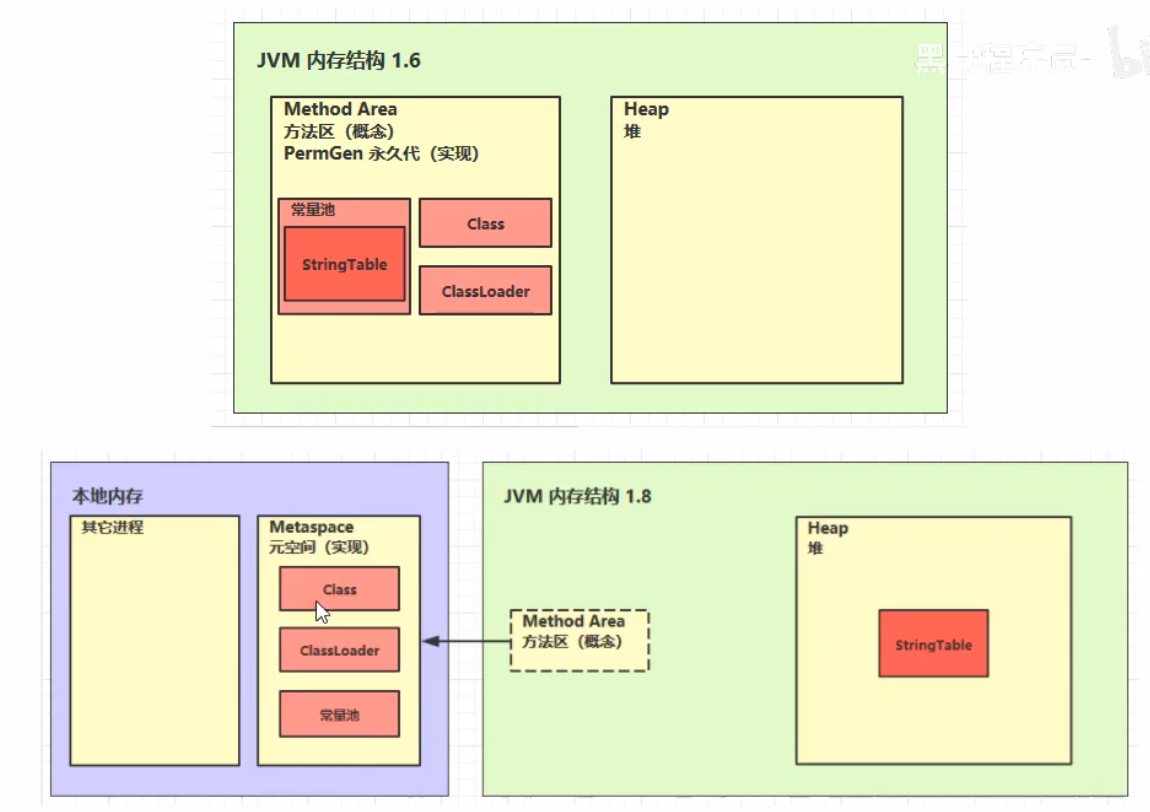
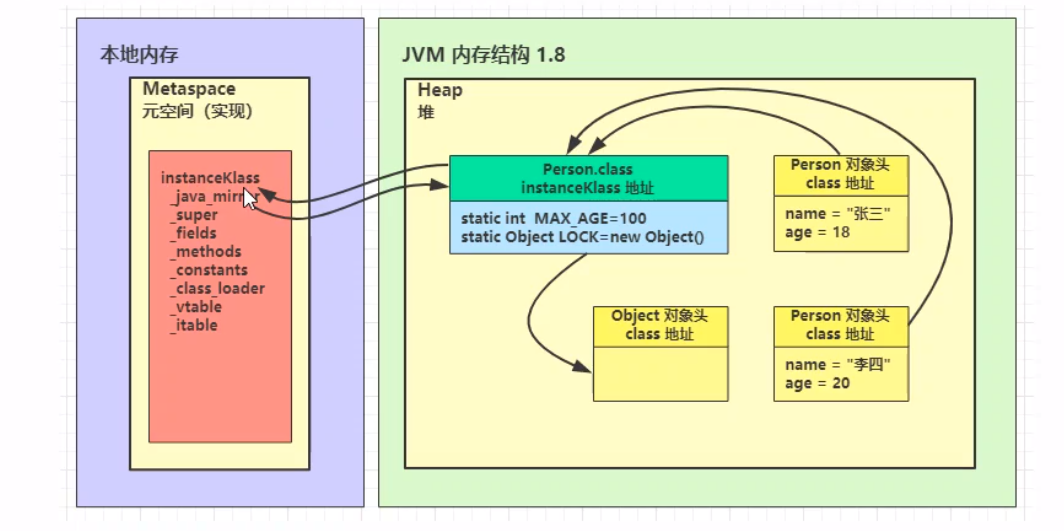
object中的一些方法无具体实现,是通过C/C++编写的,调用本地方法接口实现的,属于本地方法栈中的。 堆(Heap) Heap堆 通过new关键字,创建对象都会使用堆内存 特点 它是线程共享的,堆中对象都需要考虑线程安全的问题有垃圾回收机制堆内存溢出 java.lang.OutOfMemoryError: Java heap space 堆内存溢出的原因:不断往堆内存中添加新的对象 由于实际情况中,堆内存可能稍大,一时间无法看出堆内存的溢出隐患,但是随着时间的积累与程序的运行,可能最终导致堆内存溢出问题,这个时候需要调节VM Option 使用 -Xmx(内存大小)命令调节堆内存,及时调试得知。 堆内存诊断 jps工具 查看当前系统中有哪些java进程 jmap工具 查看堆内存占用情况 jconsole工具 图形界面的,多功能的监测工具,可以连续监测 方法区(Method Area) 方法区是在所有Java虚拟机线程中共享的存储了跟类相关的一些结构信息The Java Virtual Machine has a method area that is shared among all Java Virtual Machine threads. The method area is analogous to the storage area for compiled code of a conventional language or analogous to the “text” segment in an operating system process. It stores per-class structures such as the run-time constant pool, field and method data, and the code for methods and constructors, including the special methods (S2.9) used in class and instance initialization and interface initialization. 方法区创建于虚拟机启动的时候,逻辑上属于堆的一部分。 The method area is created on virtual machine start-up. Although the method area is logically part of the heap, simple implementations may choose not to either garbage collect or compact it. This specification does not mandate the location of the method area or the policies used to manage compiled code. The method area may be of a fixed size or may be expanded as required by the computation and may be contracted if a larger method area becomes unnecessary. The memory for the method area does not need to be contiguous. JVM内存结构在1.6版本和1.8版本存在差异:
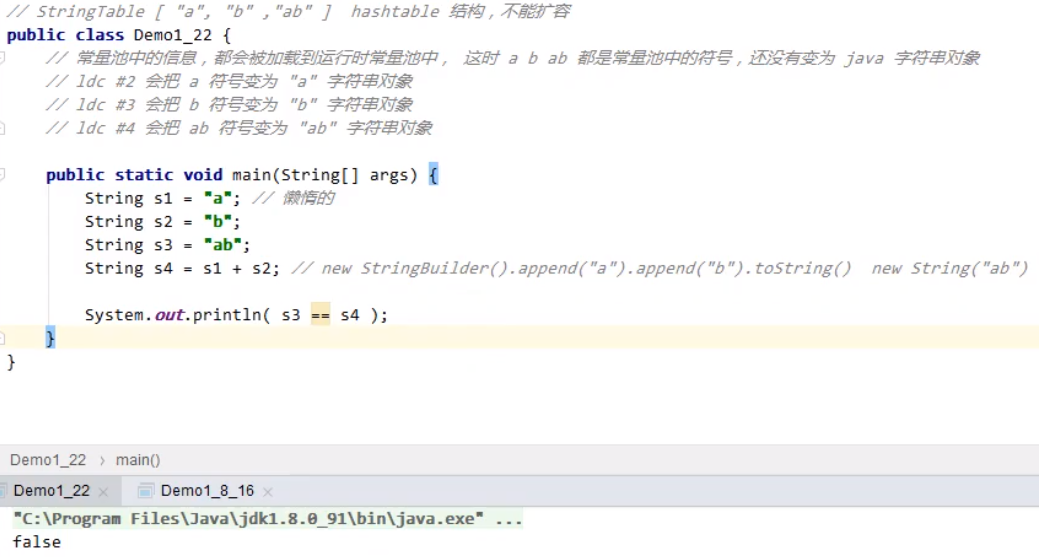
类加载器(Class Loader)用来加载类的二进制字节码 Class Writer 用来生成类的二进制字节码 JVM方法区内存溢出,jdk1.6版本时,提示的错误是永久代空间内存溢出java.lang.OutOfMemoryError: PermGen space jdk1.8版本时,提示的错误是 元空间内存溢出 java.lang.OutOfMemoryError: Metaspace 1.8以前会导致永久代内存溢出 永久代内存溢出java.lang.OutOfMemoryError: PermGen space -XX:MaxPermSize=8m1.8之后会导致元空间内存溢出 元空间内存溢出java.lang.OutOfMemoryError: Metaspace -XX:MaxMetaspaceSize=8m 方法区常量池(Constant Pool) 常量池,就是一张表。虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息运行时常量池,常量池是*.class文件中的。当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址 字符串池(String Table)常量池最初存在字节码文件中,当常量被运行时时,就会被加载到运行时常量池中,但是此时均为常量池中的一些符号,还没有成为Java中的对象。 直到运行到具体的字节码行数,才会把它放入字符串池中,变成真正的字符串对象。【用到的才会创建,否则不会创建】 字符串池是一个hashtable的结构,不能扩容。 针对创建的字符串池的问题,询问字符串创建的是否相等: 因为原有的s3是放入了字符串池中的,之后由于s4相当于new了一个新的字符串对象ab,存放的位置是堆空间。二者的地址不一样,实际上是相当于两个对象,所以不相等,输出false。s1、s2、s3都是用字符串常量创建的变量,“a”、“b”、“ab”都是创建之后放在堆内存中并加入到字符串常量池中的,而又s1和s2拼接而来的字符串s4并没有放在字符串常量池中 ,仅仅是放在堆内存中。
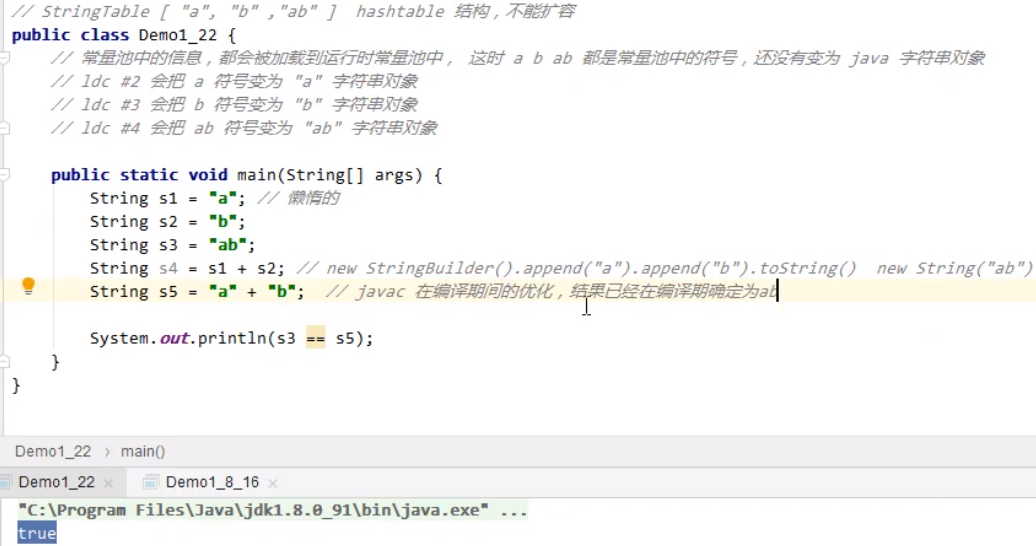
由于javac在编译期间能够确切地知道编译之后s5的结果,而不是像s4那样更改其他变量而导致新的结果,所以能够直接invoke virtual调用虚拟,使用常量池中已有的常量,所以s3==s5成立,输出true。s4的创建是使用变量创建,而s5则是通过字符常量直接拼接,所以二者有区别。【动态创建的字符串没有存放在字符串常量池中,比如s4就为动态创建】
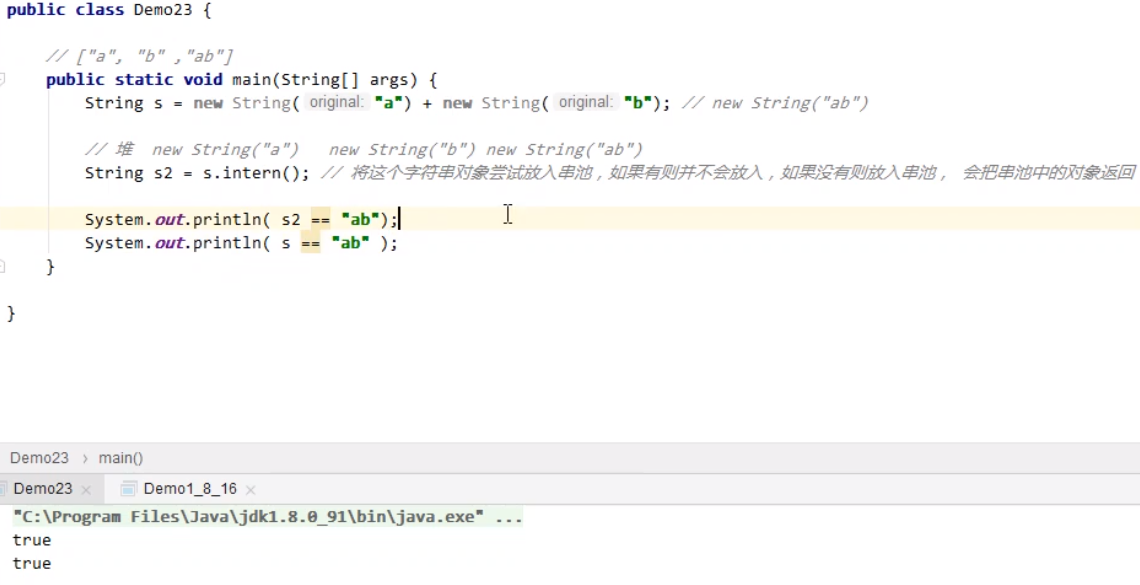
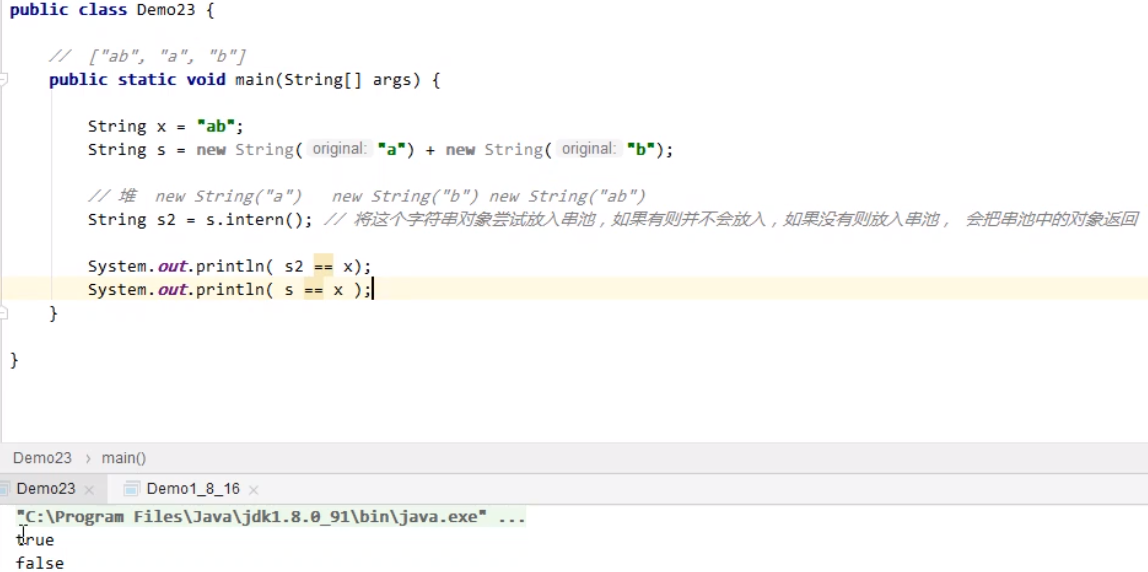
根据前面的知识,要想将动态创建的字符串对象放入字符串池,可以使用intern方法(如果有则不放入,如果没有则放入,并且该方法会返回串池中的对象)。【s.intern】
下面的案例中,x最先被放入串池中,所以s2返回的是串池中已有的对象“ab”,而s则是堆中的对象,调用intern方法的时候发现字符串池中已有“ab”,所以有则不会放入,此时“ab”是原有字符串池中,x对象放入的,并不是s经过intern方法调用后放入的,所以后面s==x输出false。
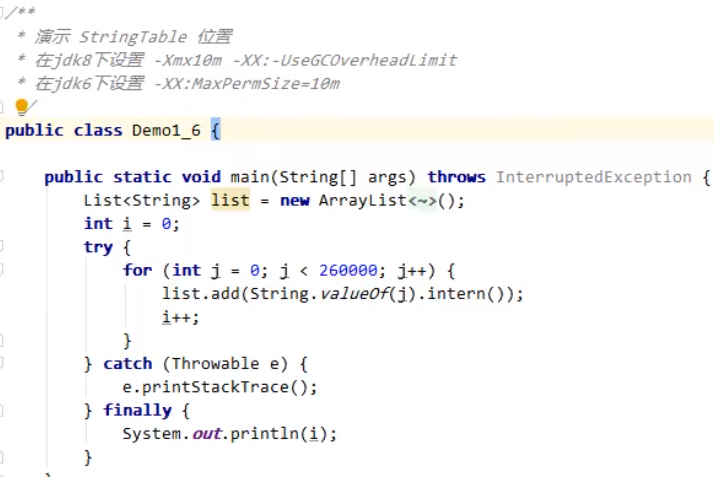
【intern方法在1.6和1.8版本的区别】 常量池中的字符串仅是符号,第一次用到时才变为对象利用串池的机制,来避免重复创建字符串对象字符串变量拼接的原理是StringBuilder(1.8)字符串常量拼接的原理是编译期优化可以使用intern方法,主动将串池中还没有的字符串对象放入串池 1.8将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回1.6将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象返回 StringTable位置当jdk版本为1.6时,StringTable位置在常量池中,并整体处于永久代(方法区Method Area)中;但是当jdk版本为1.8时,StringTable处于堆空间中。 做出改变的原因是:永久代的内存回收效率很低,触发垃圾回收的阈值较高(时间很晚)。 演示程序:当版本为jdk1.6时,将数字转换成字符串并进行intern如池操作,循环多次,设置jvm的永久代内存限制,最终导致的是永久代的内存不足,所以可以证明jdk1.6的时候,字符串池的位置处于永久代中。
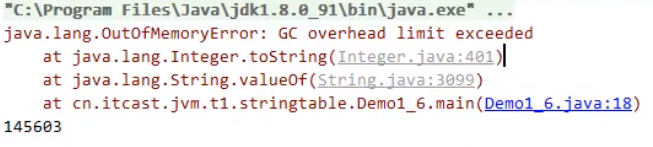
【演示程序】 设置内存限制之后,运行相同的上述程序,最终导致下面的错误:
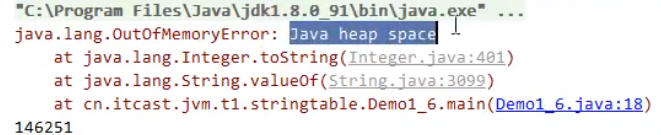
报错的解释意思是:当垃圾回收占用了98%以上的时间,却只回收了不到2%的内存。 -XX: +UseGCOverheadLimitEnables the use of a policy that limits the proportion of time spent by the JVM on GC before an OutOfMemoryError exception is thrown. This option is enabled, by default, and the parallel GC will throw an OutOfMemoryError if more than 98% of the total time is spent on garbage collection and less than 2% of the heap is recovered. When the heap is small, this feature can be used to prevent applications from running for long periods of time with lttle or no progress. To disable this option,specify the option -XX : -UseGCOverheadLimit. 最终解决方法,调试JVM,加上-XX后面的代码,关闭这个错误提示。最终运行程序,提示的是堆空间内存不足。 解决方法:在 jdk 8 下设置: -Xmx10m -XX:-UserGCOverheadLimit
由此,可以看出:jdk1.8中,串池用的是堆空间;1.6中,串池用的是永久代。 StringTable垃圾回收设置参数如下 // StringTable 垃圾回收 -Xmx10m -XX: +PrintStringTableStatistics -XX:+PrintGCDetaiIs -verbose:gc具体实现思路:设置循环,产生常量字符串,并进行intern入池操作。当分配的字符串数量过多时,会触发GC。 StringTable性能调优首先,StringTable是利用哈希表原理实现的。调优,①可以设置-Xx:StringTableSize=适当的桶个数,可以适当提高哈希查找的速度,避免哈希冲突,提高运行时间。②考虑是否将字符串对象入池,减少重复字符串的入池操作,选择性地进行入池操作。 程序演示
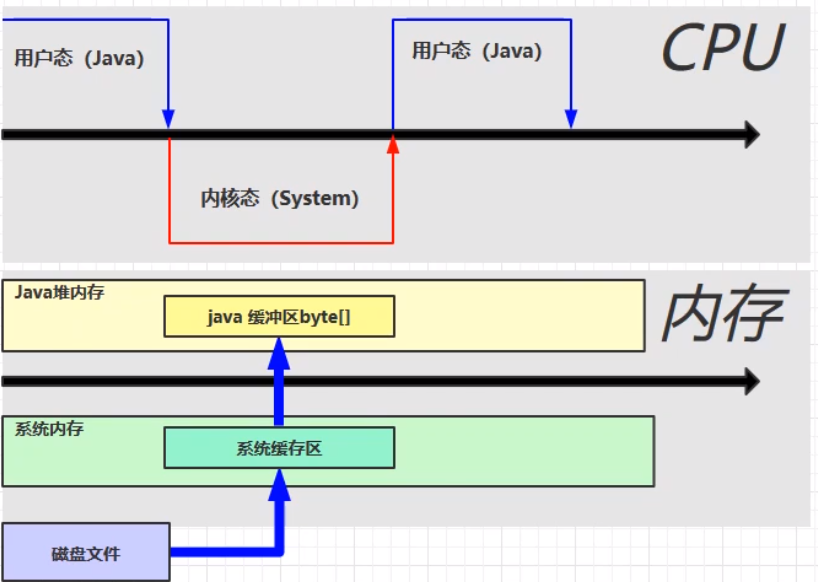
传统的文件读取方式,整个过程的流程图
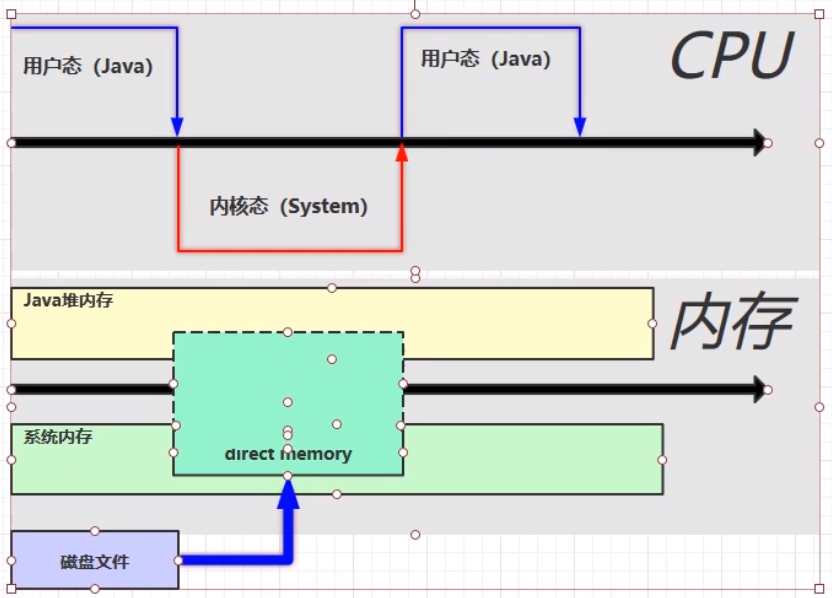
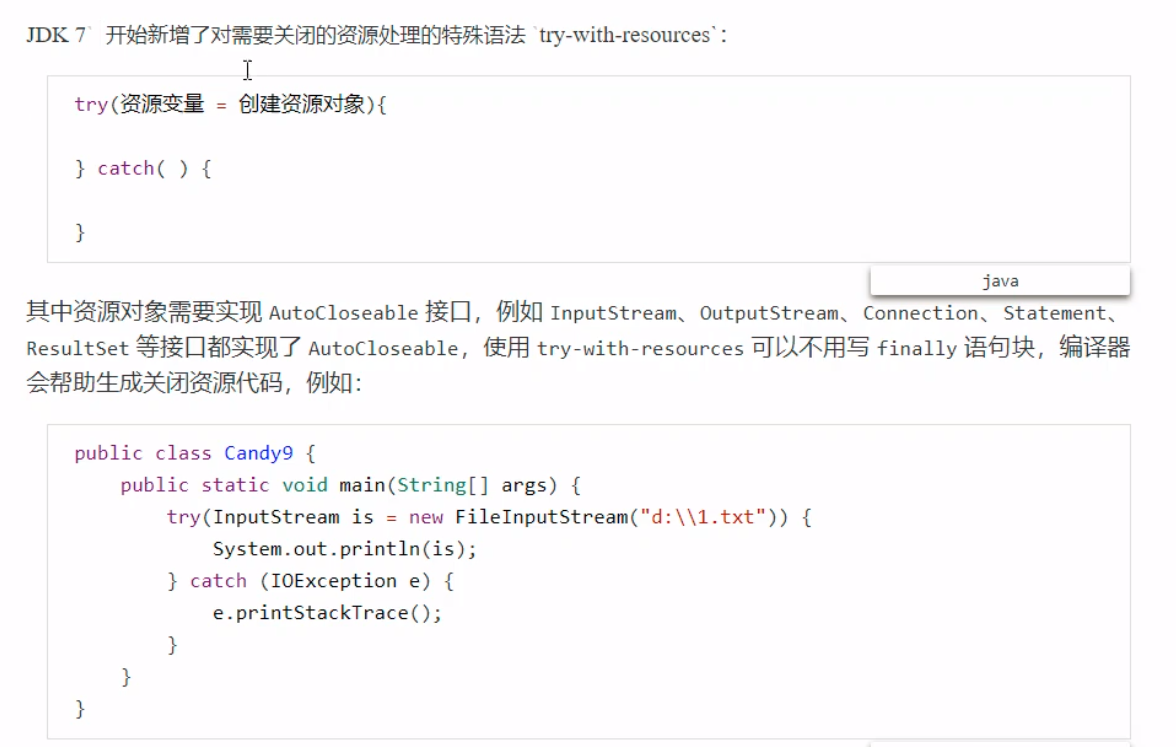
使用直接内存之后,文件的读取流程:
直接内存的使用,不受JVM内存回收管理,有可能导致内存溢出。
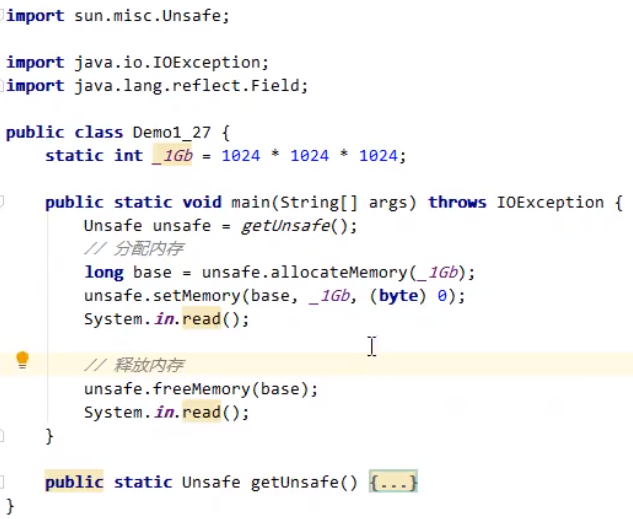
因为直接内存的使用,不受JVM内存回收管理,属于操作系统的内存。因此,想要观察直接内存的使用,需要使用到系统提供的内存管理器(任务管理器)。但是,创建的直接内存却可以通过调用unsafe对象来进行回收,不能直接使用GC算法对操作系统中的直接内存进行回收。直接内存释放需要主动调用unsafe对象的freeMemory()方法。演示程序:
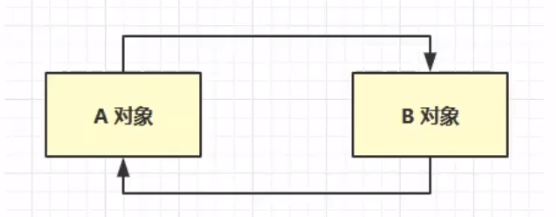
直接内存分配和回收原理: 使用了Unsafe对象完成直接内存的分配回收,并且回收需要主动调用freeMemory方法ByteBuffer的实现类内部,使用了Cleaner (虚引用) 来监测ByteBuffer对象。一旦ByteBuffer对象被垃圾回收,那么就会由ReferenceHandler线程通过Cleaner的clean方法调用freeMemory来释放直接内存 三、垃圾回收 如何判断对象可以回收 引用计数法判断对象被引用的次数,看对象是否可以被回收。但是根据下面的互相调用的情况,此时A、B两对象互相引用,且引用次数为1的话,则不能根据引用次数对其进行垃圾回收(因为互相引用),但是长时间不对这两者对象进行垃圾回收,则会导致内存泄漏,长时间存在内存得不到释放的情况,所以引用计数法存在一定的弊端。在实际的虚拟机中,一般需要采用下面的可达性分析算法。
在此算法中,我们将那些一定不能被垃圾回收的对象称之为“根对象”。在进行垃圾回收之前,会对类中所有的对象进行一次扫描,看看其中的对象是否会被其中的根对象直接或间接引用。如果有引用,则该对象不能被垃圾回收,由于根对象的绑定关系,会导致该对象有需要被引用的可能,故不能被垃圾回收;反之,如果对象没有被根对象直接或间接引用,则该对象存在被垃圾回收的可能性。 以上这个过程被称之为可达性分析算法。但是,如何确定根对象(GC Root)?
要找到GC Root对象,我们需要借助一个Eclipse提供的工具——Memory Analyzer,简称MAT。
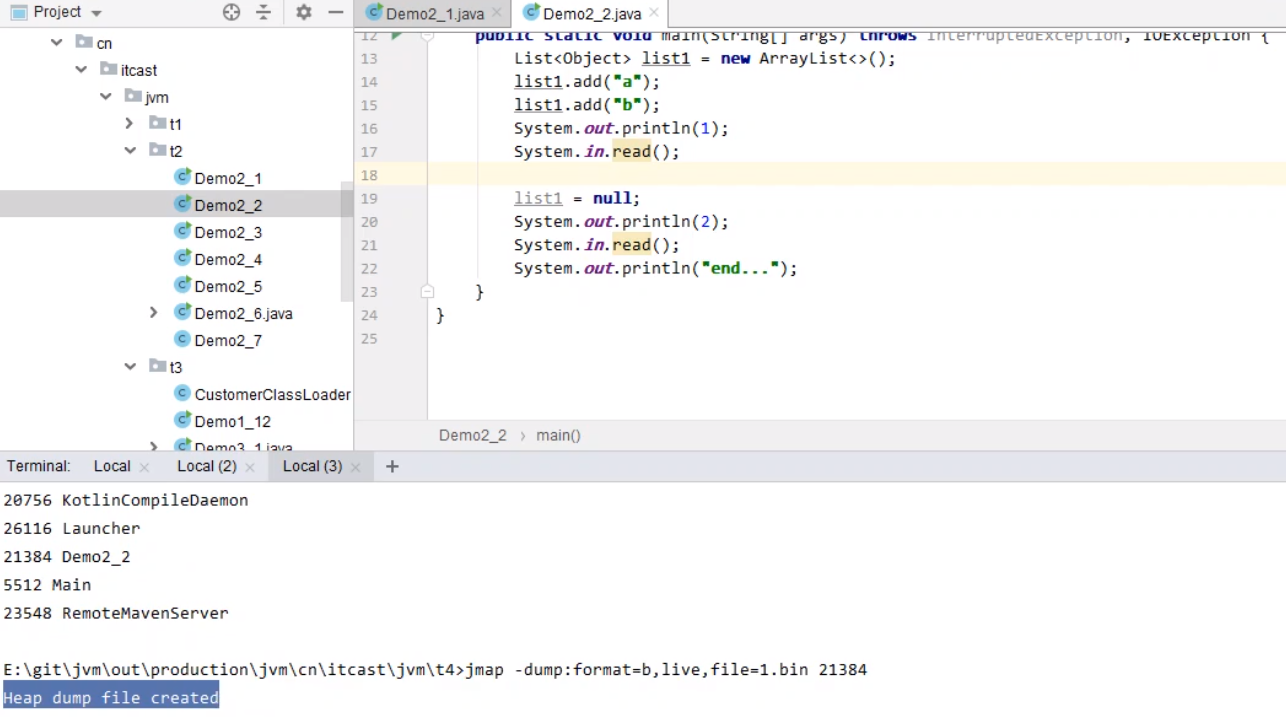
具体操作步骤: 先找出Java程序的进程ID,之后输入相关参数,生成二进制文件,抓取程序进程快照,之后利用工具打开生成的二进制文件 进行分析。
MAT工具打开文件之后,操作界面如下所示:
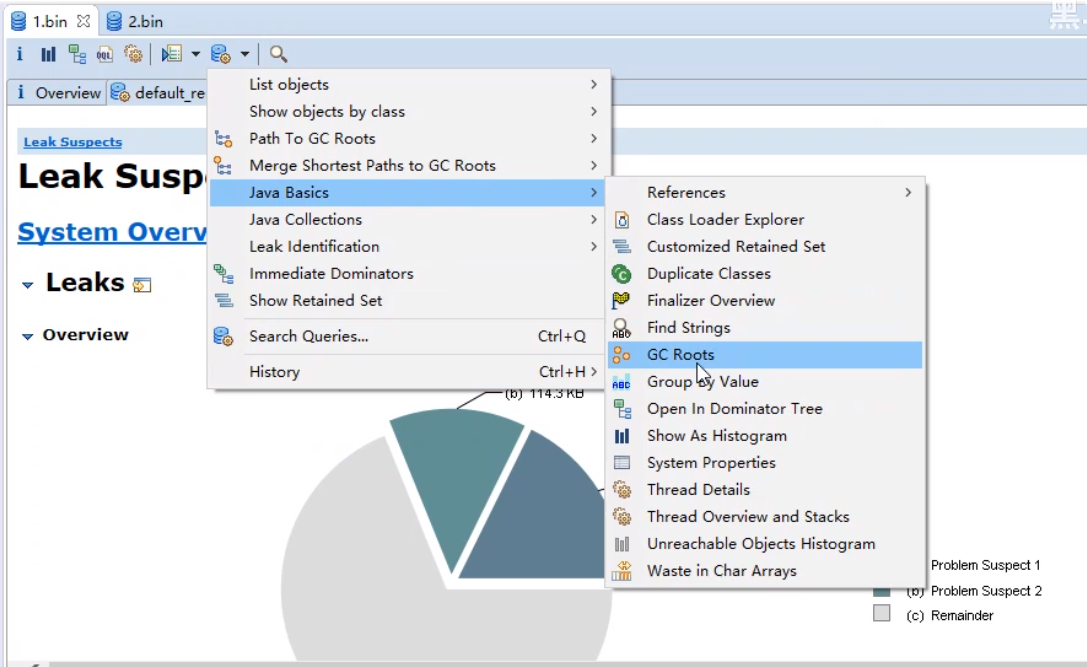
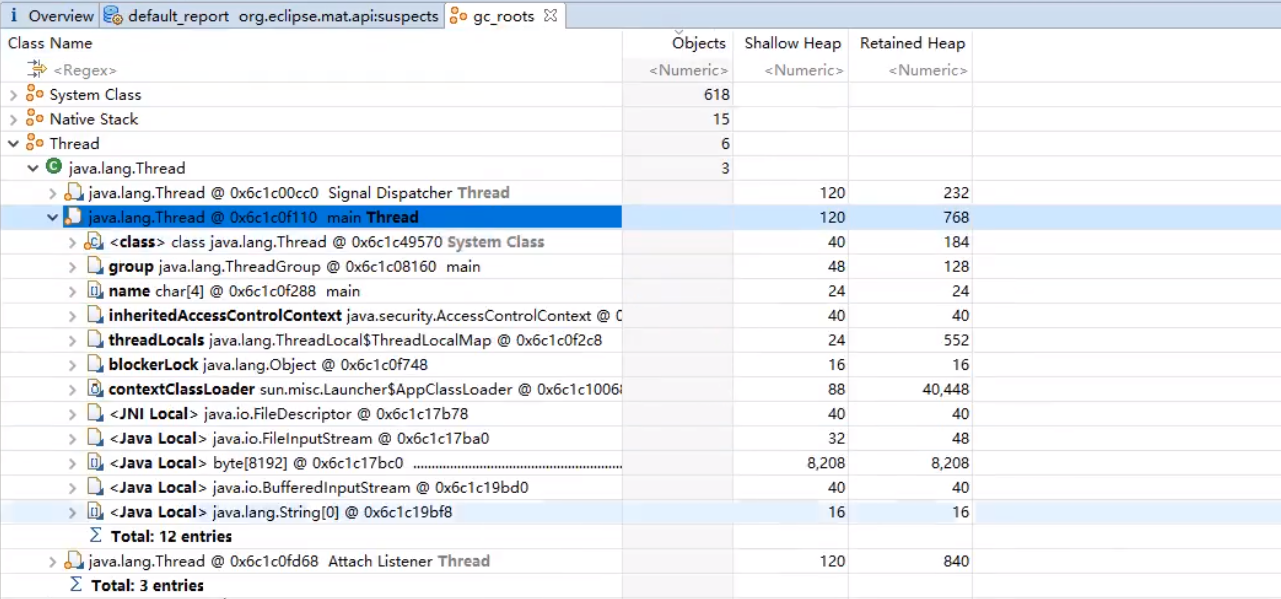
GC Roots显示的界面如下所示:
可知当前一共有641个对象。其中,System Class为系统核心类,不能被回收掉。 实际上的分析,只需要看主线程中的对象,查看哪些本地变量是GC Root对象,不能被回收。
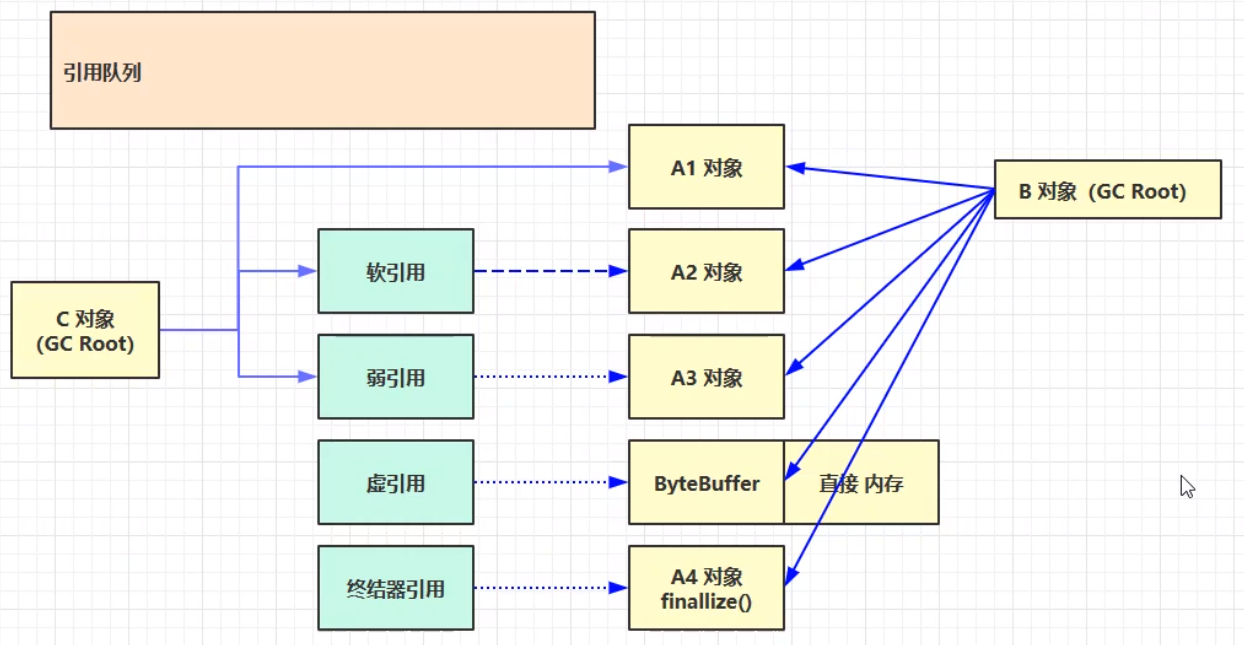
实际上常用的一共有五种引用。分别为:强引用、弱引用、软引用、虚引用、终结器引用。 引用示例图:(其中,实线表示强引用)
①只有当一个对象与其相连的所有强引用都断开,才能被垃圾回收。②当连接A2对象的强引用断开之后,若执行垃圾回收之后仍然发现内存不够用的时候,才会继续垃圾回收掉A2对象,也就是软引用的对象。③当指向A3对象的强引用断开之后,只要发生了垃圾回收,不管内存是都宽裕,A3(弱引用对象)都会被回收掉。④当软引用连接的对象(A2)被垃圾回收之后,软引用本身也已经成为了一个对象,这个时候会进入引用队列。同时,弱引用同理;二者在连接的对象被垃圾回收之后,都会进入引用队列。这是因为软引用和弱引用他们本身也需要占用一定的内存。如果想要对软引用和弱引用他们本身进行垃圾回收处理,可以借助引用队列找到他们,并做进一步的处理(遍历二者进行内存释放,相当于断开GC Root对象对他们的强引用,进行垃圾回收)。 虚引用和终结器引用 此两者必须配合引用队列使用。当虚引用引用的对象被垃圾回收之后,虚引用就会被放入引用队列,从而间接地用一个线程来调用虚引用的方法,使用 unsafe.freeMemory()来释放直接内存。
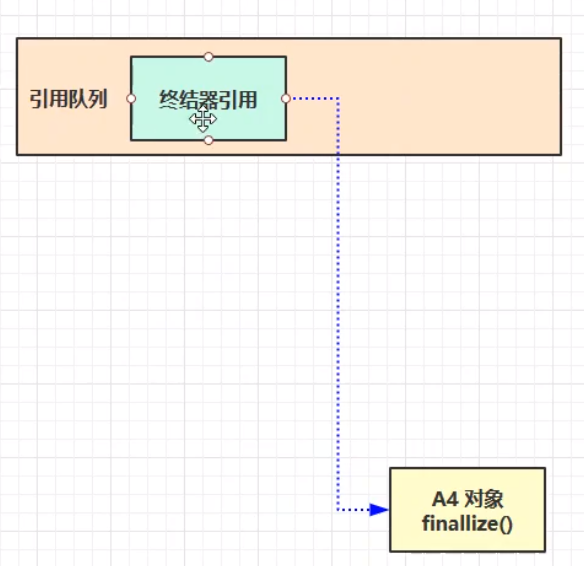
终结器引用:所有的Java对象都继承自Object父类,Object父类有一个finalize()方法。当A4对象的强引用被断开之后,将终结器引用放入引用队列中,然后由一个 优先级很低的线程去检查引用队列中是否存在终结器引用,如果存在终结器引用,则调用完A4的finalize方法,等调用结束,就可以等待下一次进行垃圾回收。其中,终结器引用效率很低:第一次回收时还不能真正的将其回收,需要二次进行回收;其次,要将终结器引用进行入队操作;再者,检测终结器引用的线程优先级很低,被执行的机会很少,可能会导致连接的方法的finalize方法迟迟得不到调用,无法结束自身的生命周期,所以导致该对象(A4)存在的生命周期中一直占用内存,短期内得不到释放。所以一般不推荐使用finalize方法释放内存。
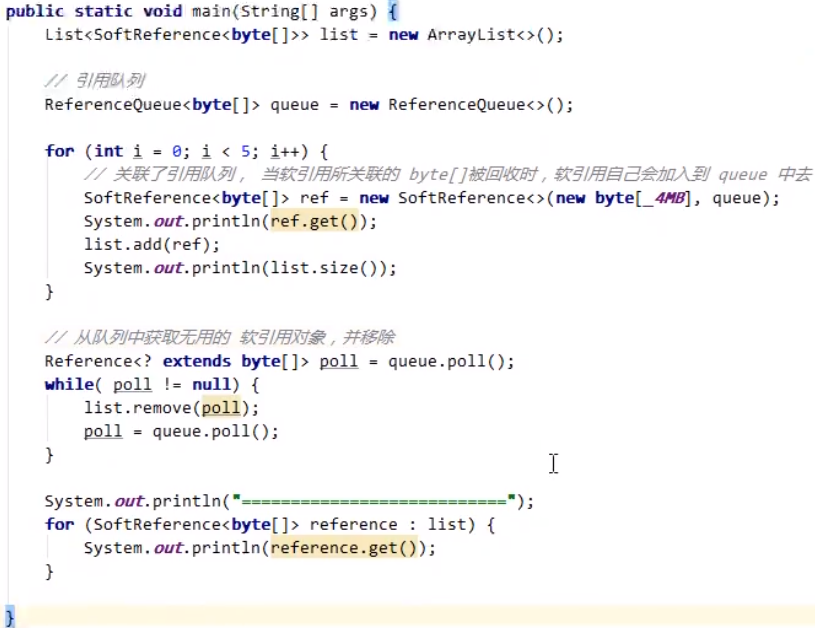
软引用(SoftReference) 强引用和软引用的代码案例区别:其中,注释的部分即强引用;其余部分为软引用。
当软引用使用不到的时候,需要使用引用队列对软引用实现释放。使用ReferenceQueue 创建引用队列对象,对其进行软引用释放内存。其中,引用队列的泛型需要和软引用的泛型一致。之后,再使用软引用的时候还需要关联引用队列,在上述代码对应位置改成new byte[_4MB], queue,关联之后,当软引用引用的对象被引用之后,对象需要回收时,会将软引用本身也加入到queue中去。整个过程,代码示例如下:
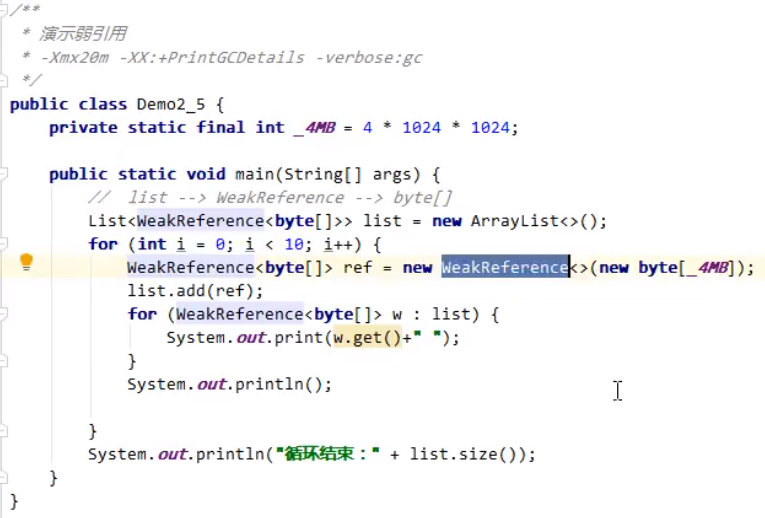
弱引用(WeakReference) 当弱引用连接的对象仅有弱引用时,垃圾回收时,无论内存是否充足,都会将弱引用所引用的对象进行垃圾回收。同样,也可以配合垃圾引用队列进行垃圾回收弱引用本身。
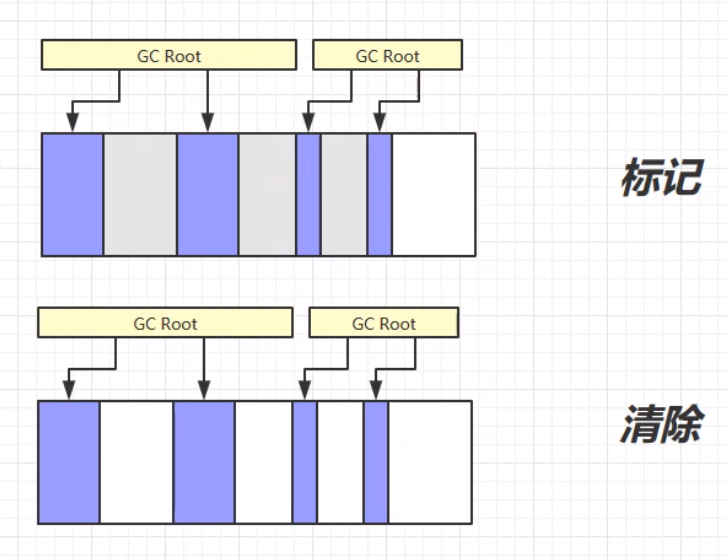
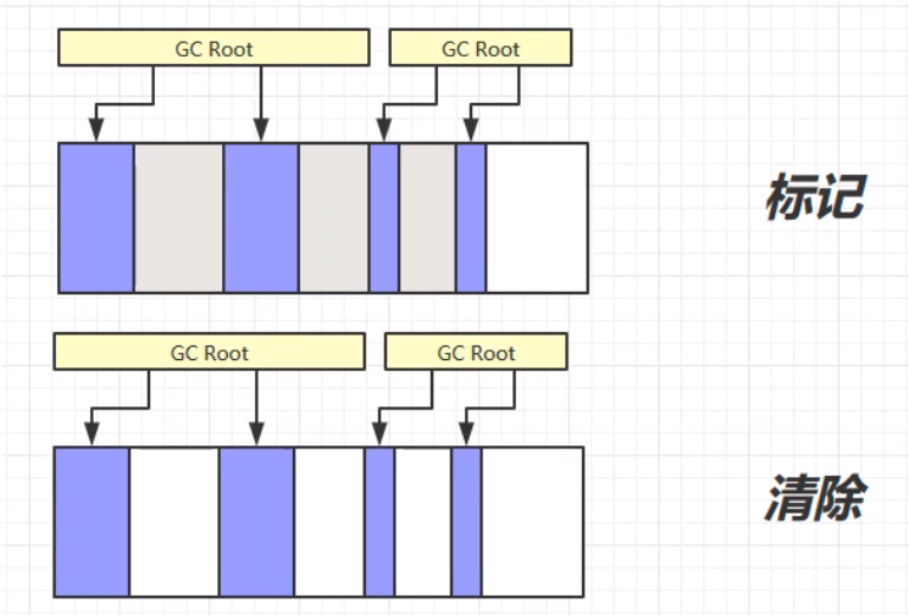
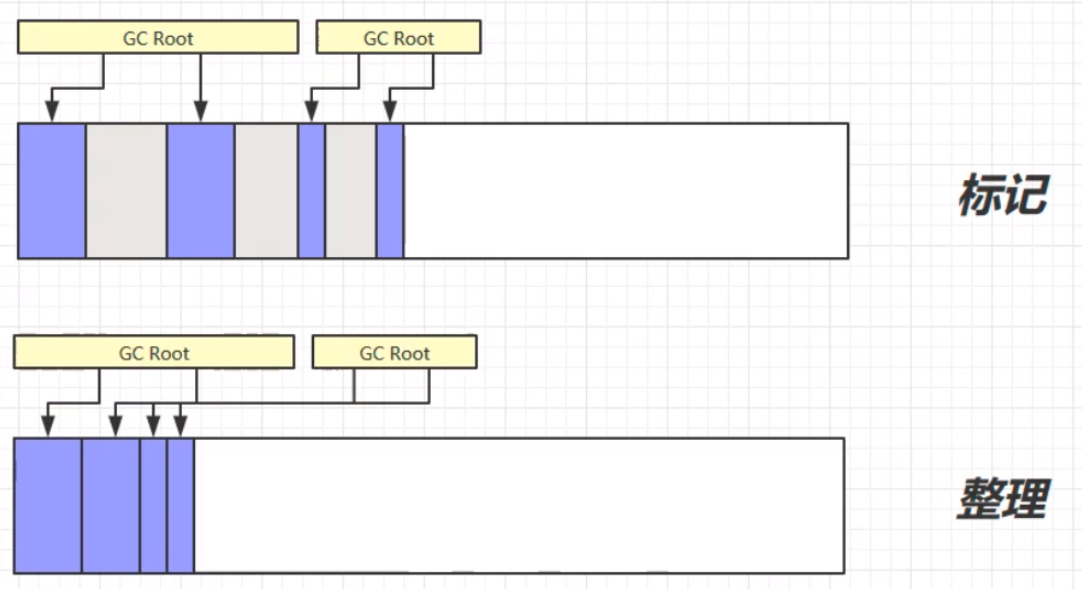
顾名思义,标记清楚就是标记和清除两个步骤。第一个步骤,先标记可以被垃圾回收的对象(或者说需要被垃圾回收的对象)。这个步骤的思路:沿着GC Root的对象,从头到尾遍历所有对象,连着GC Root的对象则为强引用,不可被垃圾回收,其余的则根据情况进行标记,等待下一个步骤——清除。第二个步骤,清除标记的对象,将所有被标记的、可以被回收的对象进行垃圾回收。 其中,实现的细节问题:清除的步骤不是将对象的每个字节进行清零操作,而是将对象占用内存的起始地址记录在一个空闲的地址链表中。下次分配新的对象时,可以直接从空闲的地址链表中找,如果有足够的地址空间容纳这个对象,则为该对象分配空闲的地址空间。
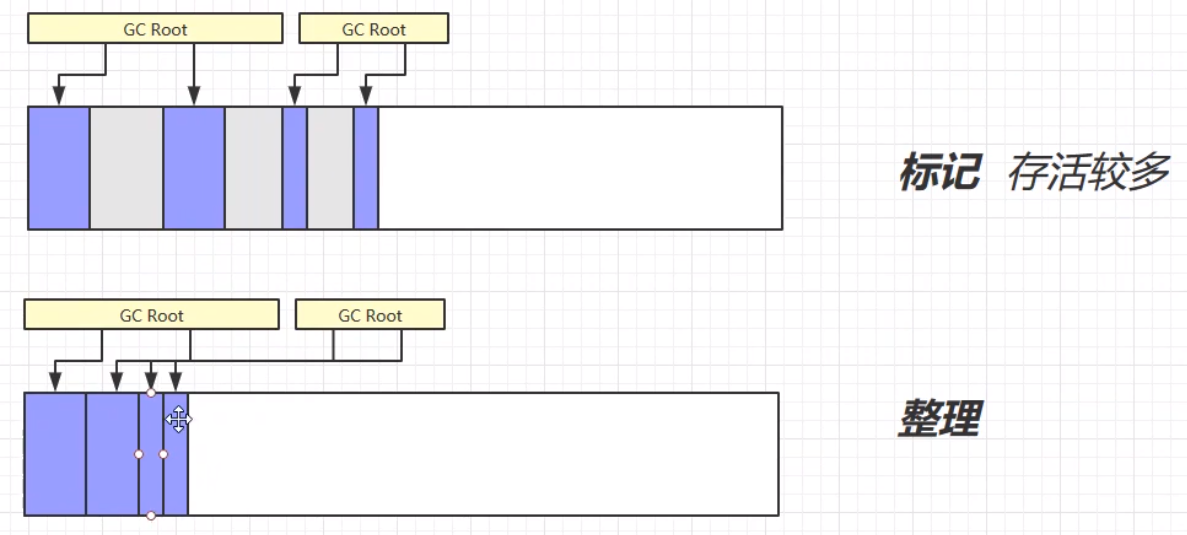
标记清除的优缺点: 优:标记清除的速度快,只需要对需要被垃圾回收的对象空间的起始地址做记录即可,所以标记清除的速度快。 缺:容易产生内存碎片。因为记录的是原对象的起始地址,原地址被标记记录之后,不会对地址空间进行整理,所以在对新对象进行地址分配的时候,容易造成内存的使用的不连续,导致大量空闲空间无法得到使用,造成内存使用的不充分不连贯。(页内碎片) 标记整理(Mark Compact)标记整理算法,相比于之前的标记清除算法,在第二个清除的步骤中,不只是简单的清除,而是将清除之后不连续的内存空间进行整理,最后使得余留下来的对象占据的还是连续的内存空间。 标记整理的优缺点: 优:相较于标记清除,不会产生内存碎片。 缺:由于涉及对象空间的移动,使得整个过程更加复杂繁琐。内存区块的拷贝移动、内存地址的改变等,这些问题更加复杂,需要更多的工作量,所以速度更慢。
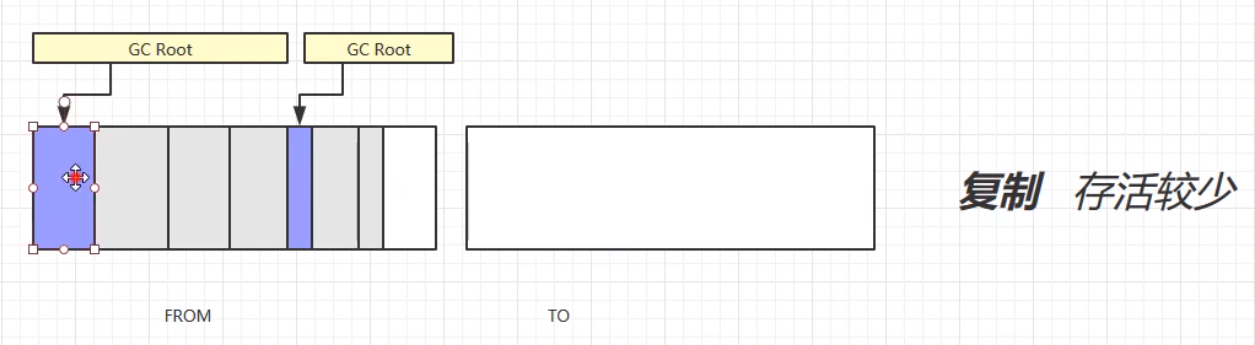
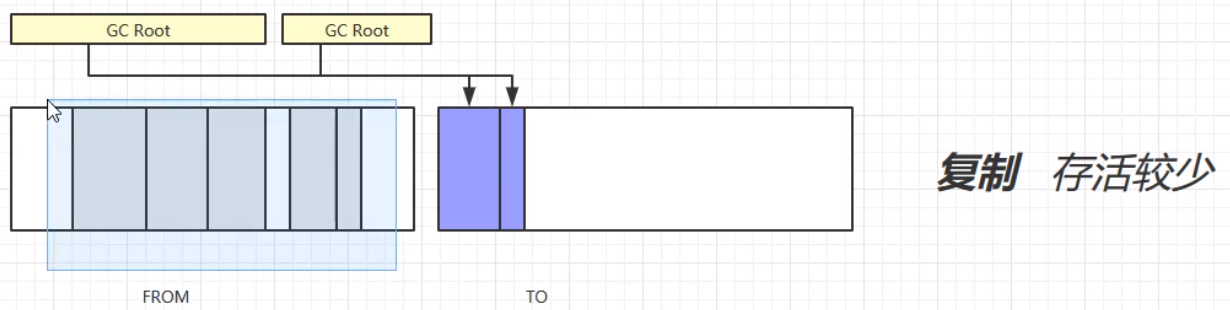
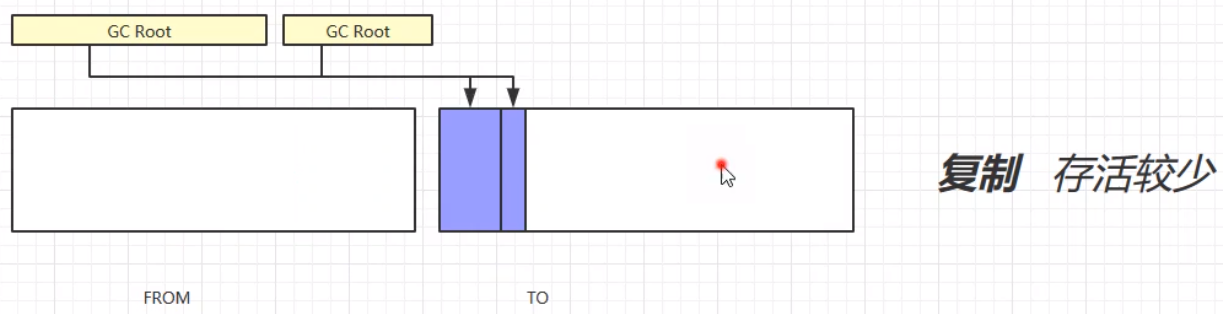
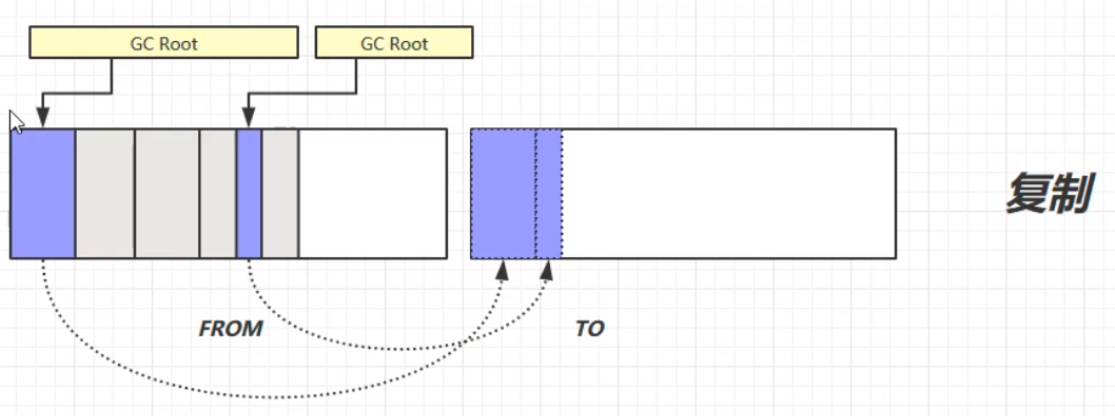
复制算法,首先将GC Root的强引用对象赋值到TO区域中;其次,将FROM中的所有需要垃圾回收的对象进行垃圾回收;之后,交换FROM和TO的位置;最终,垃圾回收完成。演示步骤如下:
复制算法的优缺点: 优:不会产生内存碎片,最终形成连贯的空闲空间。 缺:在进行垃圾回收的时候,会占用双倍的内存空间,且工作量也比较大。 总结标记清除算法(Mark Sweep) 速度较快会造成内存碎片
标记整理算法(Mark Compact) 速度慢没有内存碎片
复制算法(Copy) 不会有内存碎片需要占用双倍内存空间
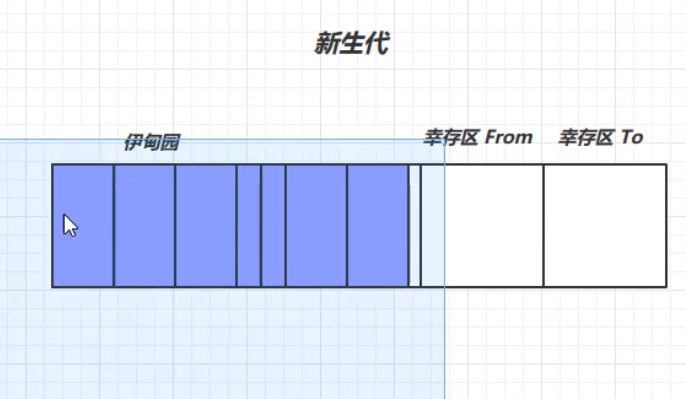
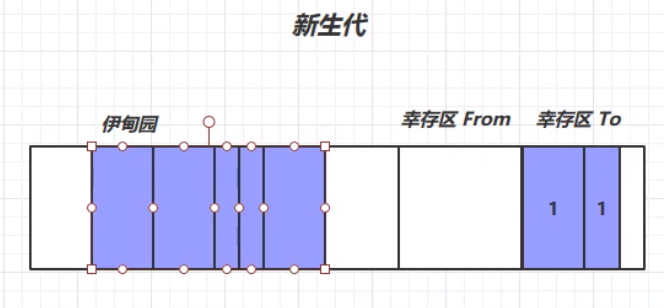
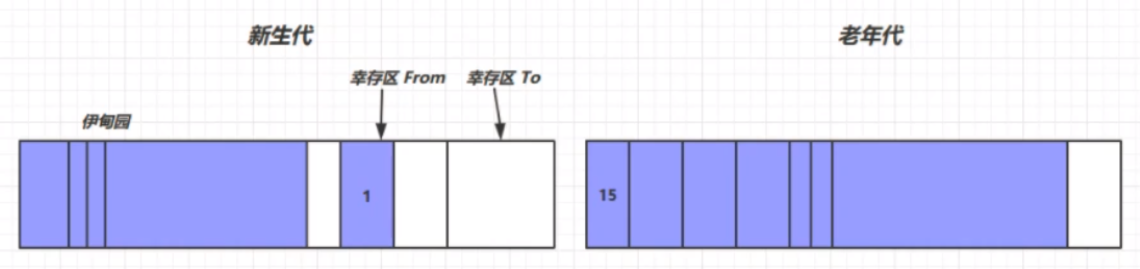
垃圾回收中,有新生代、老年代、伊甸园(Eden)、幸存区(FROM)、幸存区(TO)的概念。 我们一般将需要长时间使用的对象放在老年代中,把那些用完即丢的对象放在新生代中。针对不同对象的生命周期,为他们制定不同的垃圾回收策略。这就是创造分代回收的原因。 首先,新生代的结构如下所示:
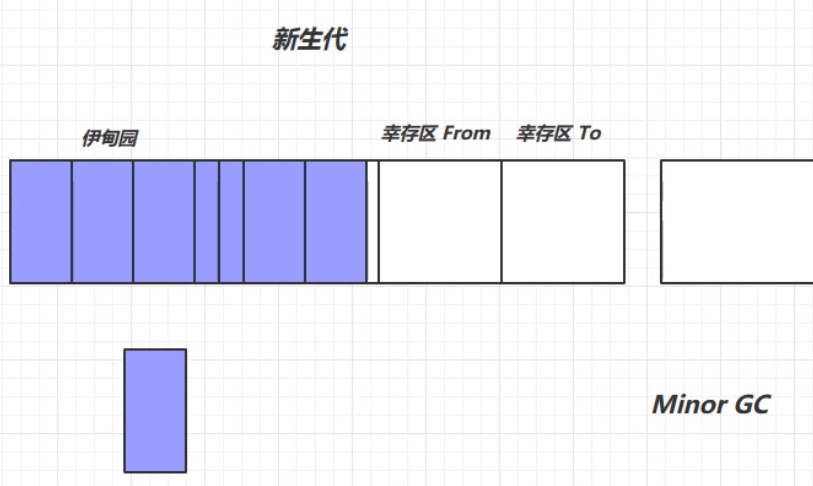
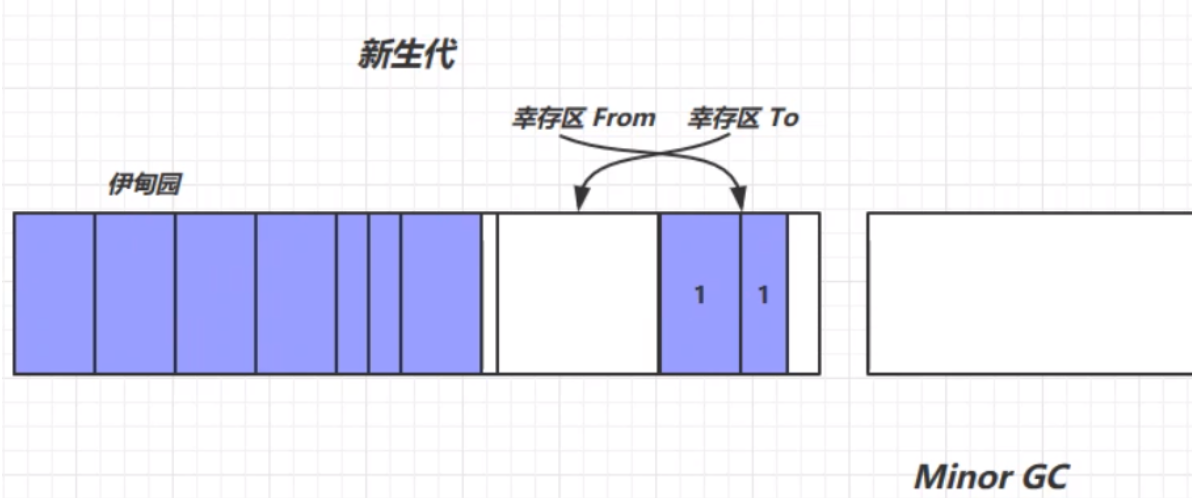
我们将每次新创建的对象存放在伊甸园中。但是,新生代中伊甸园的内存是有限的,当伊甸园的内存不够时,便会触发新生代的一次垃圾回收,回收处理伊甸园中的垃圾,此次垃圾回收称之为Minor GC。
此次垃圾回收,利用复制算法,将幸存的对象放入幸存区TO中,并将这些对象的生命周期进行+1的操作,表示这些对象已经经历了一次垃圾回收,但是幸存下来,并没有被回收掉。然后根据复制算法,将From和To的位置交换,完成一次垃圾回收。
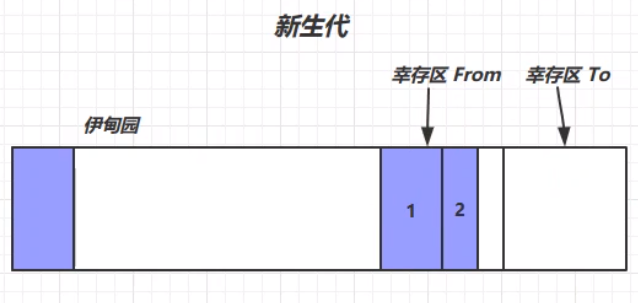
此时上图中被标记的对象就会被Minor GC回收掉。第二过程中,等到伊甸园中的对象再次内存不足时,就会再次出发Minor GC进行垃圾回收。但是,此次Minor GC不光要扫描伊甸园中的对象,还需要对之前幸存区From中的对象进行扫描,看是否存在需要被垃圾回收的对象。最终幸存的对象生命周期+1,放在幸存区From中。
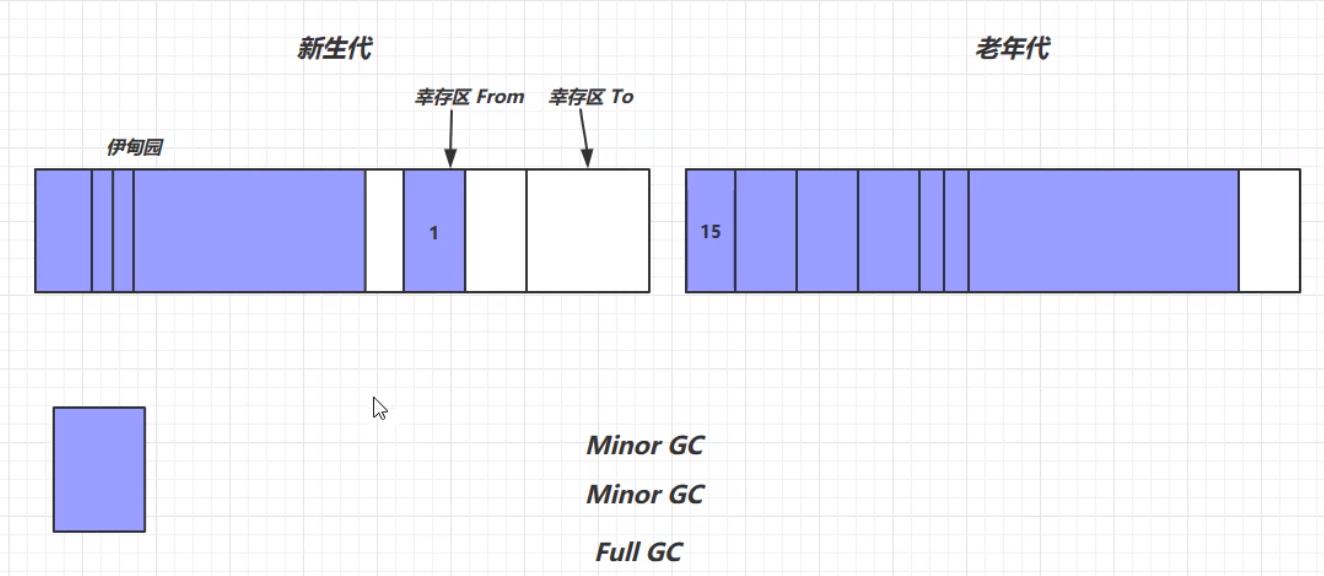
在经历了第二轮的Minor GC之后,可能的对象存活情况如下:
在经历多次Minor GC之后,可能存在一些对象的生命周期变得比较长(超过一定阈值),这个时候就出现了晋升——将这些生命周期较长的对象存放在老年代区(最大生命周期是15——4bit(1111))。因为老年代发生GC的频率相对新生代来说较低,所以生存周期更长的对象放在老年代区能够减少扫描的次数,提高一定的工作效率。 但是,当新生代的伊甸园以及From区、老年代区都无法存放下新生成的对象时,这个时候就会触发一次Full GC。
分代垃圾回收的一些特点:
三种垃圾回收器的特点 串行 单线程堆内存较小,适合个人电脑 吞吐量优先 多线程堆内存较大,多核cpu让单位时间内,STW的时间最短 响应时间优先 多线程堆内存较大,多核cpu尽可能让单次STW的时间最短 串行(Serial)使用串行垃圾回收器的代码:
在VM Options中设置的参数。前者Serial使用的是复制算法的新生代区,后者SerialOld表示的是老年代,使用的是标记整理算法。 因为串行回收器是单线程的,所以在使用串行回收器的时候,需要将其他的线程阻塞,只留下串行垃圾回收器线程在运行,确保垃圾回收的安全可靠。
使用吞吐量优先垃圾回收器,需要设置的参数如下: 其中,第一行的两个参数,在jdk1.8中是默认打开的。最后一个参数是控制GC的线程数。 第二行表示的采用一个大小自适应的策略,调整的是新生代的大小。第三行:GC时间比率;第四行:最大GC暂停耗时。 英文中文Parallel平行的; 同时发生的; 并行的;Ratio比率; 比例;Millis耗时
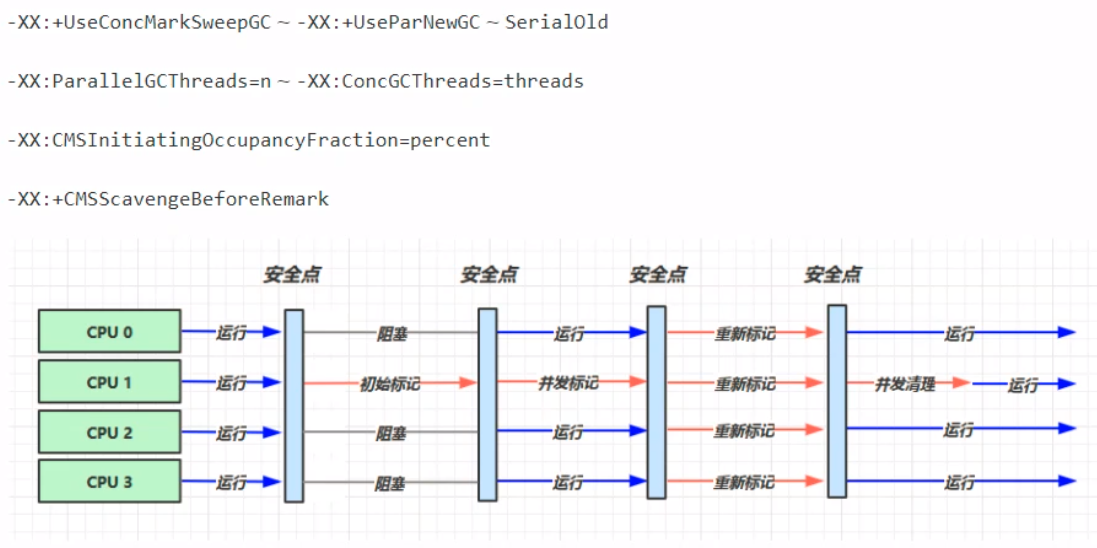
由于吞吐量优先的垃圾回收器算法是多线程的,所以在进行垃圾回收的时候,同时运行多个垃圾回收线程(一般线程数等于处理器核心数),降低单位内的STW时间。
第一个参数,UseConcMarkSweepGC——Concurrent,并发;意即”使用并发标记清除GC算法“。 第二行第二个参数,并发GC线程数,一般设置的线程数为CPU核心数的四分之一。如四核CPU需要使用三个核心留给用户线程,留下一个核心处理垃圾回收。这样就使得原来的用户线程只能使用四分之三的CPU线程,这样会对整个用户程序的吞吐量造成影响。 响应时间优先的垃圾回收中,由于是并发执行的垃圾回收,当垃圾回收时,其他的四分之三的用户线程在执行的时候,也会产生一定量的垃圾,这些垃圾我们叫做浮动垃圾,但是由于并发执行,这个时候浮动垃圾只能留到下一次的垃圾回收再进行清理。由于不像之前的垃圾回收一样是等到堆内存不足再进行垃圾回收,这个时候如果浮动垃圾产生导致堆内存空间不足,则会使得空间不足的情况产生,所以在垃圾回收之前还需要预留一些空间。 此时,第三行的参数则是设置这一预留的垃圾空间占比。比如设置80%,则当堆内存空间占用达到80%的时候,就会开始进行垃圾回收,预留20%的空间留给浮动垃圾。这一参数的缺省值在65%左右,如果这一参数设置的越小,那么CMS进行的时间就要越早。 第四行的参数是留给重新标记之前扫面新生代的垃圾,可以避免一些不需要的重复扫描。 CMS垃圾回收存在一些弊端:当新生代中内存碎片过多时,可能导致并发失败,退化成SerialOld。 G1垃圾回收器(Garbage First)
根据介绍可知,在jdk9中,已经默认使用G1垃圾回收器了,废弃了之前使用的CMS响应时间优先垃圾回收器。G1和CMS同属于并发的垃圾回收器,两者在堆内存空间小的情况下,暂停的时间几乎一致;但是若是堆空间超大的堆内存,则G1的垃圾回收时间更短。 第一个参数是打开G1的使用开关,在jdk9以及之后的版本则不需要使用这一参数了,因为是默认打开的。 其中,第二个参数的使用,size大小必须设置成1、2、4、8……这样的数字大小。 G1垃圾回收阶段
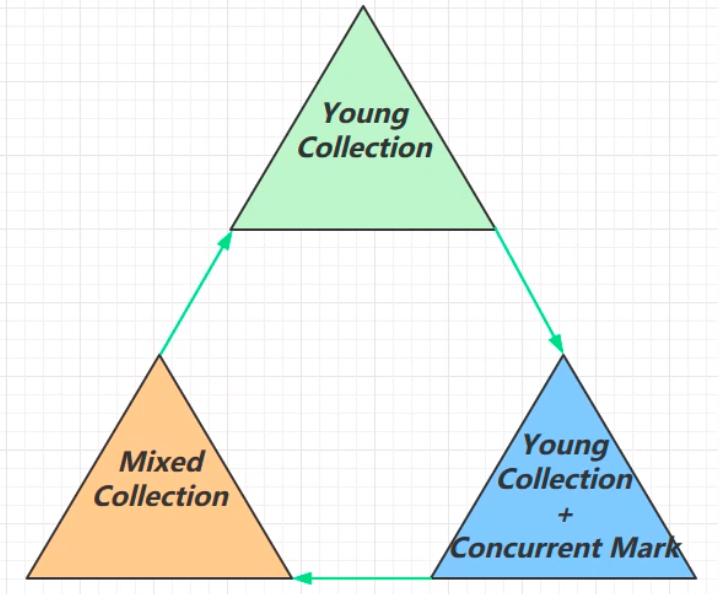
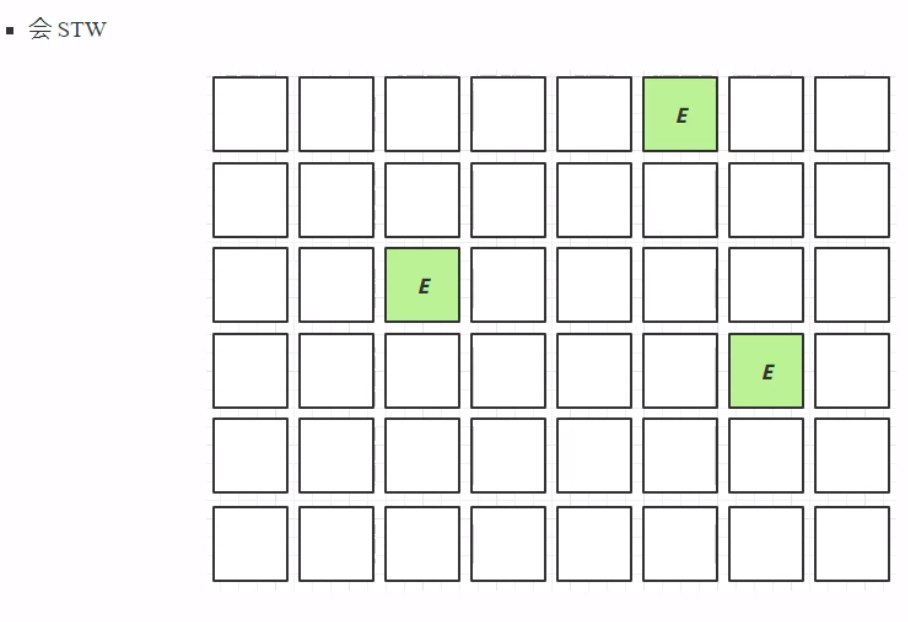
在G1回收器中,以上三个阶段是一个循环的过程。从新生代收集开始,之后进入新生代的收集和并发标记阶段,再进入混合收集阶段,这一阶段同时回收新生代和老年的垃圾。 Young Collection因为G1在使用的时候会将堆内存划分成一个个的Region区域,每一个区域都可以看作包含有老年代与包含Eden伊甸园、幸存区from、幸存区To的新生代。此阶段新生代的垃圾回收跟此前的垃圾回收一样,都会触发一次STW。
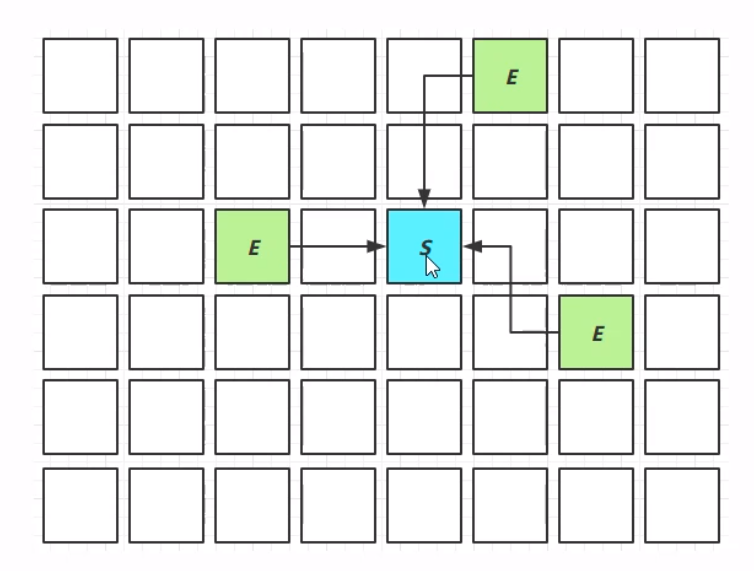
一段时间之后,会将新生代中的幸存对象通过复制算法复制到幸存区。
此后,在经历多轮的新生代垃圾回收之后,有一部分的幸存对象会晋升到老年区。
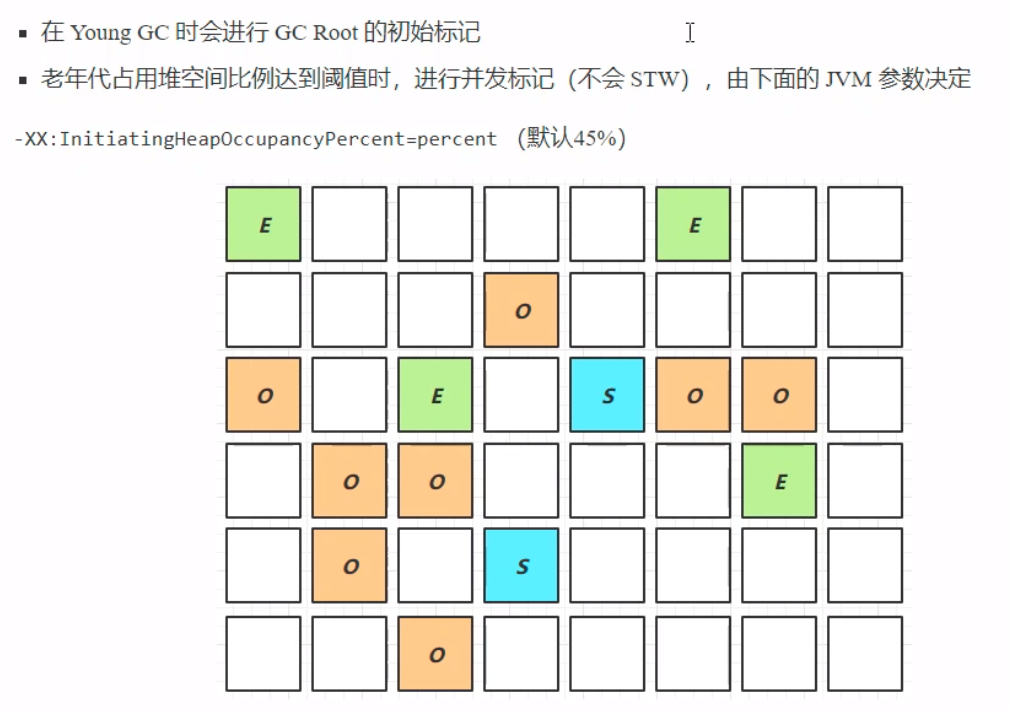
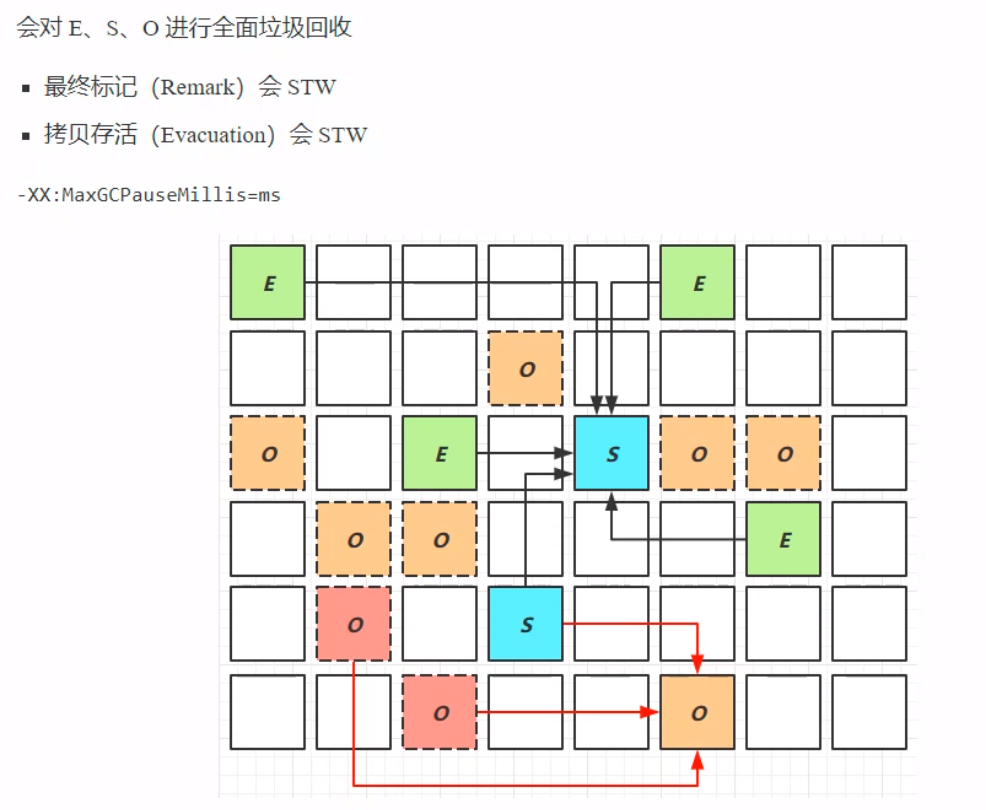
这个阶段相比于前一个Young Collection阶段多了个并发标记。当前一阶段的Serial幸存区对象晋升到老年代中,这个时候老年代内存空间开始累积。当老年代占用堆空间比例达到阈值时,开始进行并发标记(由于是并发标记,不会STW,参考之前的CMS),阈值可以由图中的参数决定。 Mixed Collection混合收集会对Eden伊甸园、Serial幸存区、Old老年区进行全面的垃圾回收。由于之前提到的最大暂停耗时缺省值是200ms,由于G1的使用场景复杂,为了达到最大暂停耗时的目标(不超出这个最大暂停耗时),使用复制算法的时候需要复制的对象过多时,这个时候就需要G1判断回收最有回收价值的老年区对象(意即回收之后能够获得更多的空闲空间——垃圾最多的区域——以及是否能够进行回收)。 此阶段的垃圾收集存在一个最终标记过程,由于之前在进行并发标记的时候,用户线程在使用,可能产生新的一写浮动垃圾或者改变对象的引用关系,这个时候垃圾回收的效果会受到影响,所以在进行最终标记的时候会出现STW。拷贝存货时候,会回收那些垃圾最多的老年代区域。
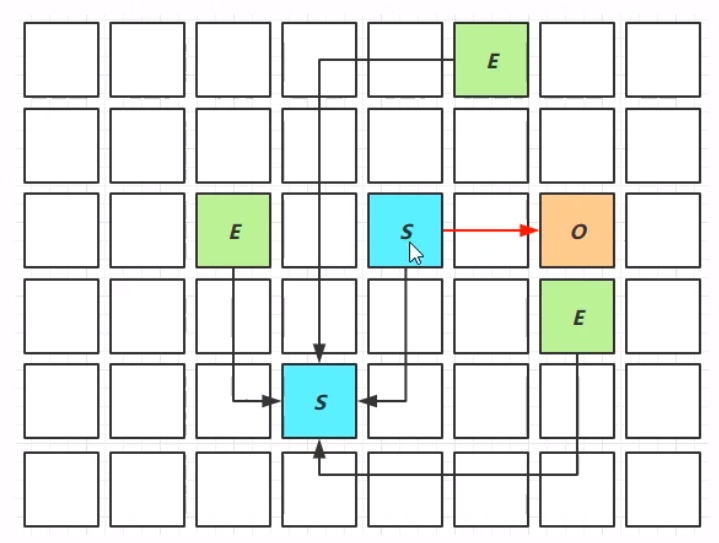
之前使用的垃圾回收器一共有四种:串行垃圾回收器——Serial GC;并行垃圾回收器——Parallel GC;相应时间优先——CMS;Garbage First垃圾回收器。但是只有在串行和并行的垃圾回收时,老年代空间不足触发的垃圾回收才能叫做full GC。 在G1垃圾回收中,当老年代内存空间占比达到阈值(默认时45%),会进入到一个并发标记的阶段以及混合收集的阶段。 ①当垃圾回收的速度大于用户线程产生的垃圾速度(只有在最终标记才会STW,而且这个STW时间非常短),这个时候触发的垃圾回收不叫full GC ②当垃圾回收的速度跟不上用户的垃圾产生速度了,这个时候并发收集就会失败,最终导致垃圾回收退化成Serial GC,触发Full GC 在CMS垃圾回收中,当并发失败了,才会进行Full GC。这个阶段,可以根据GC日志中的打印内容判断是否进行了一次Full GC。 GC分类 SerialGC 新生代内存不足发生的垃圾收集:minor gc老年代内存不足发生的垃圾收集:full gc ParallelGC 新生代内存不足发生的垃圾收集:minor gc老年代内存不足发生的垃圾收集:full gc CMS 新生代内存不足发生的垃圾收集:minor gc老年代内存不足 G1 新生代内存不足发生的垃圾收集:minor gc老年代内存不足 Young Collection跨代引用在新生代的垃圾回收中,整个过程是:①对新生代中的对象进行扫描,确定GC Root对象;②进行可达性分析,确定垃圾回收的对象和存活对象;③将存活对象复制到幸存区To;这一阶段,当From中存在的对象,会根据生命周期以及存活是否判断,是进行回收还是晋升到老年区中,没有达到阈值但是仍然存活的对象会被复制到To中。 幸存区中有两个区域,分别为From和To,比例为8:1 HotSpot默认Eden与Survivor的大小比例是8 : 1,也就是说Eden : Survivor From : Survivor To = 8:1:1。所以每次新生代可用内存空间为整个新生代容量的90%,而剩下的10%用来存放回收后存活的对象。 因为新生代中的对象大多是”朝生夕死“的,存活周期很短,只有非常少的对象才会需要长时间使用。 经过这一次的Minor GC之后,From的空间会被全部清空,这个时候就会交换From区域和To区域。这个时候Minor GC已经基本完成。在进行下一次的Minor GC之前(也就是GC刚开始的时候),幸存区To的空间是空的,因为要将Eden中的对象和From区域的对象进行复制到To区域。
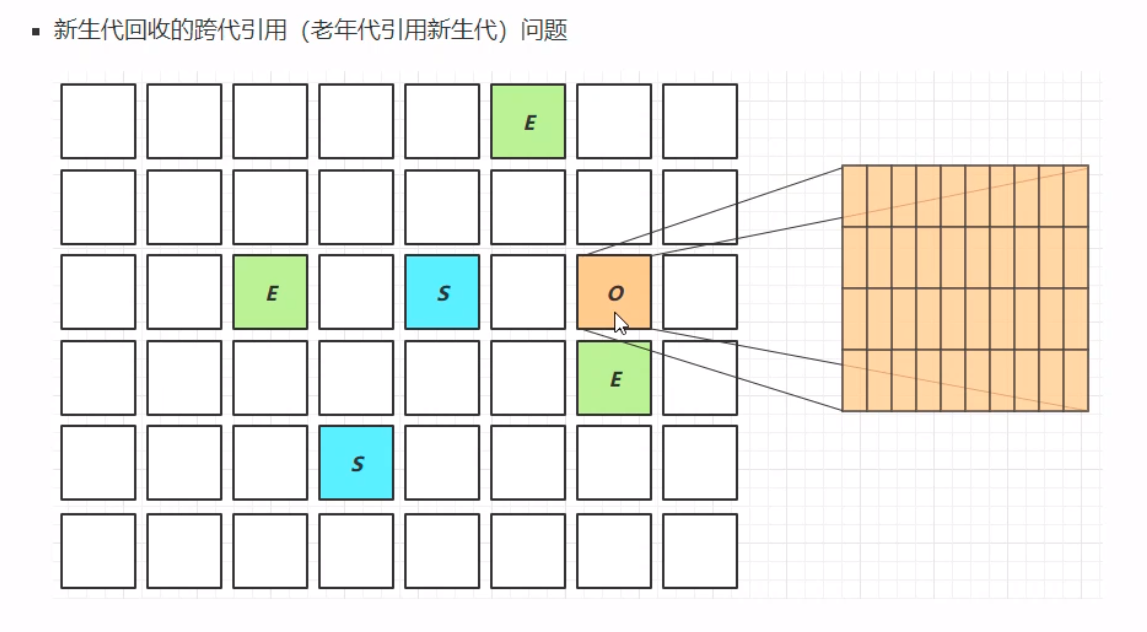
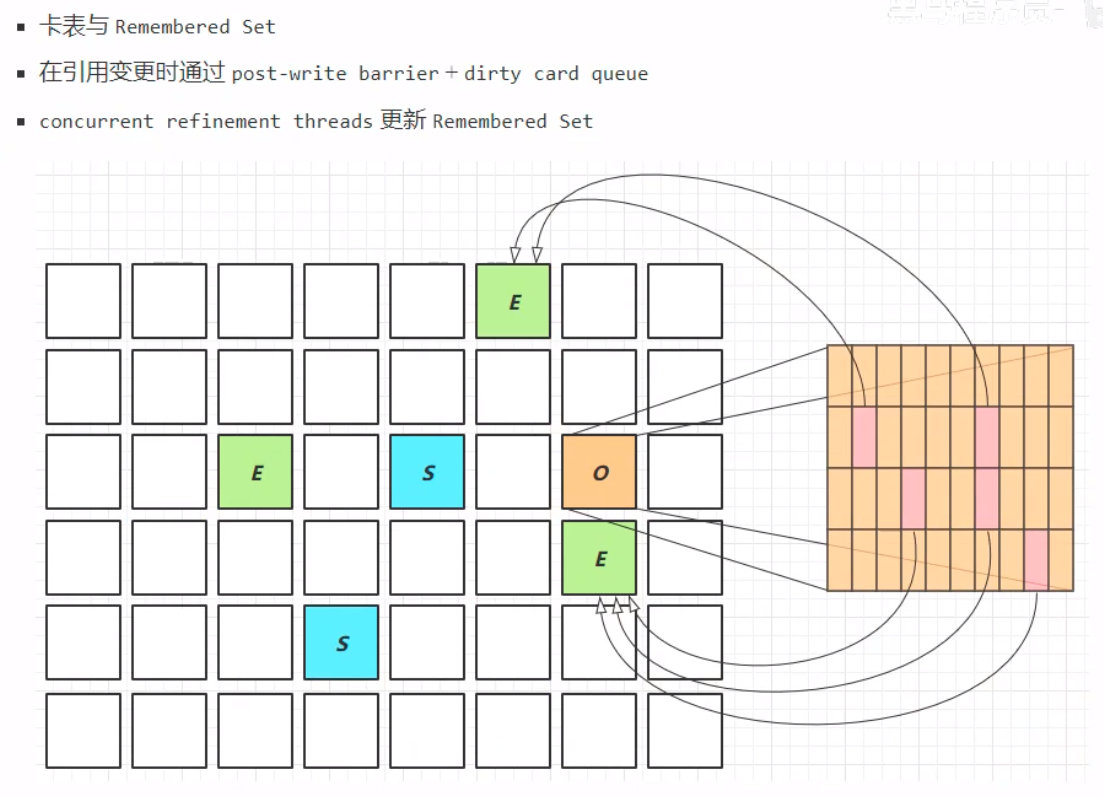
整个过程中,那么在寻找GC Root对象的时候,就会产生问题:GC Root中有一些对象是老年区的,老年代引用新生代中的对象时,需要怎么处理呢?这个时候如果遍历整个老年代的话,会产生非常高的消耗。这个时候我们采取”卡(card)表(table)“的方式,将老年代区域划分成多个细块——卡。其中有引用新生代对象的卡,称之为”脏卡“。脏卡引用的新生代对象是不能够被直接垃圾回收的。
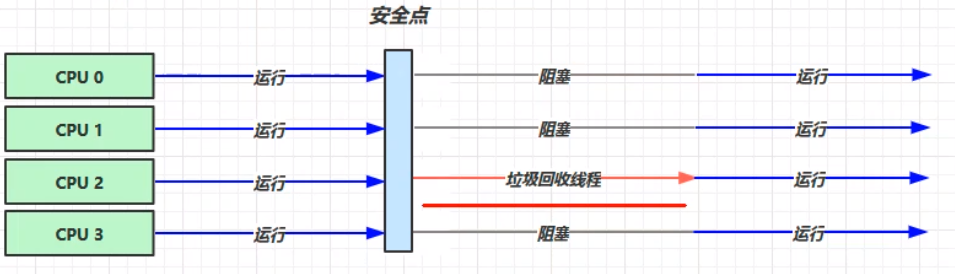
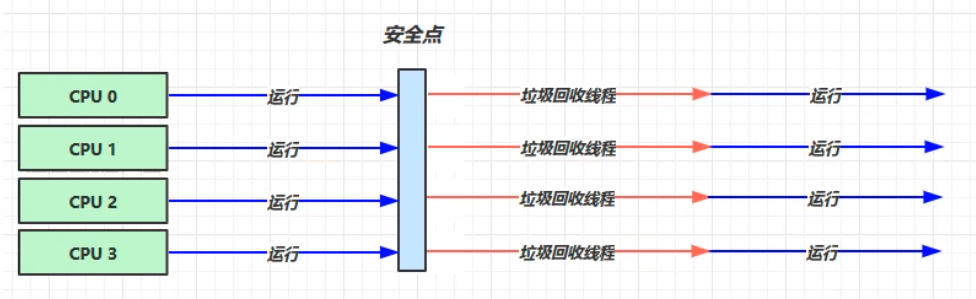
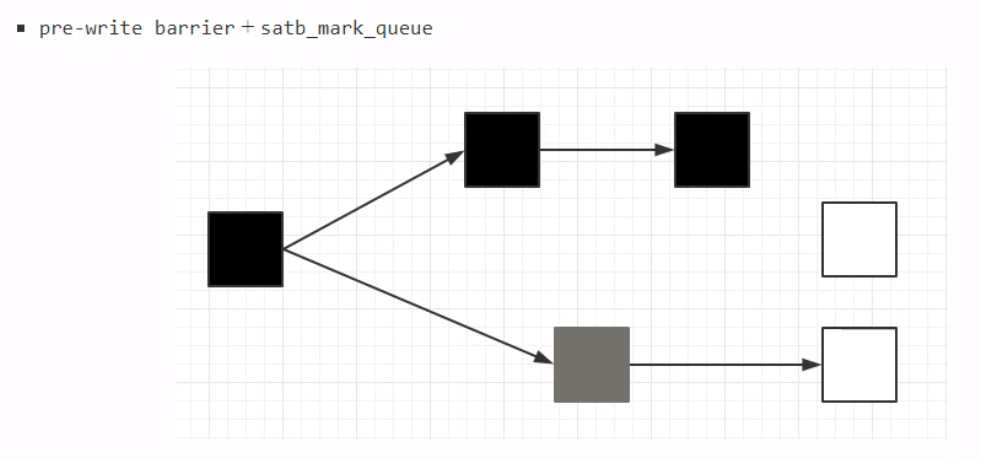
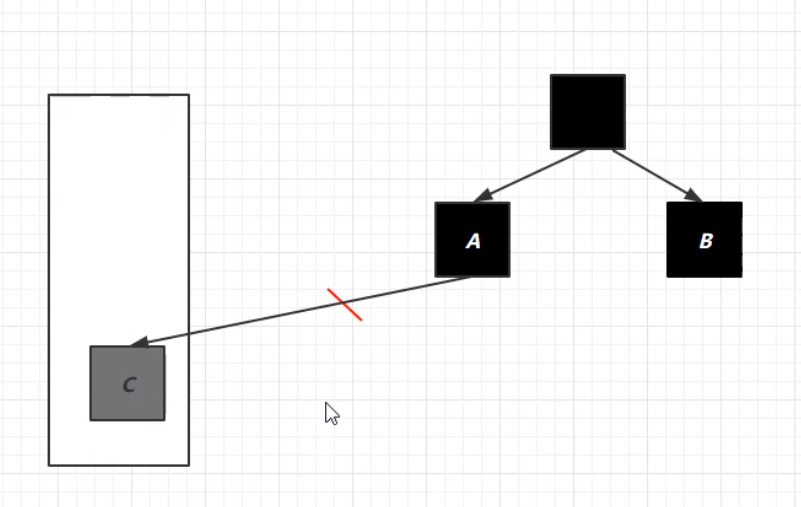
其中,黑色表示已经处理完成的;灰色表示尚在处理当中的;白色表示尚未处理的。此图中,当灰色的处理完成,因为强引用(直线箭头),灰色最终会变成黑色;而连接着灰色的白色最终也会变成黑色。独立的白色最终会被当成垃圾进行回收。 但是在实际的垃圾回收中,情况往往更加复杂。当对象的引用在标记进行的时候发生改变,原本可能可以回收的却不能被回收,但是在标记之后仍为“白色”状态,这个时候就不能对这个对象进行垃圾回收,但是标记的状态却没被更改,如何处理? 这个过程的实际处理中,JVM加入了一种写屏障——pre-write-barrier。当该对象的引用关系发生改变,写屏障就会得知状态改变,而将该对象加入到一个特定的队列(stab_mark_queue)中。 在原本的处理中,下列的对象的处理中,将C对象(原本是白色状态)转变为处理中的状态(灰色)。这个时候就会进入重新标记的状态,重新标记会发生STW,并将队列中的对象重新取出来做检查
这个字符串去重开关为默认开启的。具体开启方法参看下图中的开启参数。因为该过程发生于新生代的垃圾回收,所以占用更多的CPU时间,但是相比于带来的内存空间收益,这个时间上的些微更多的花费更加划算。
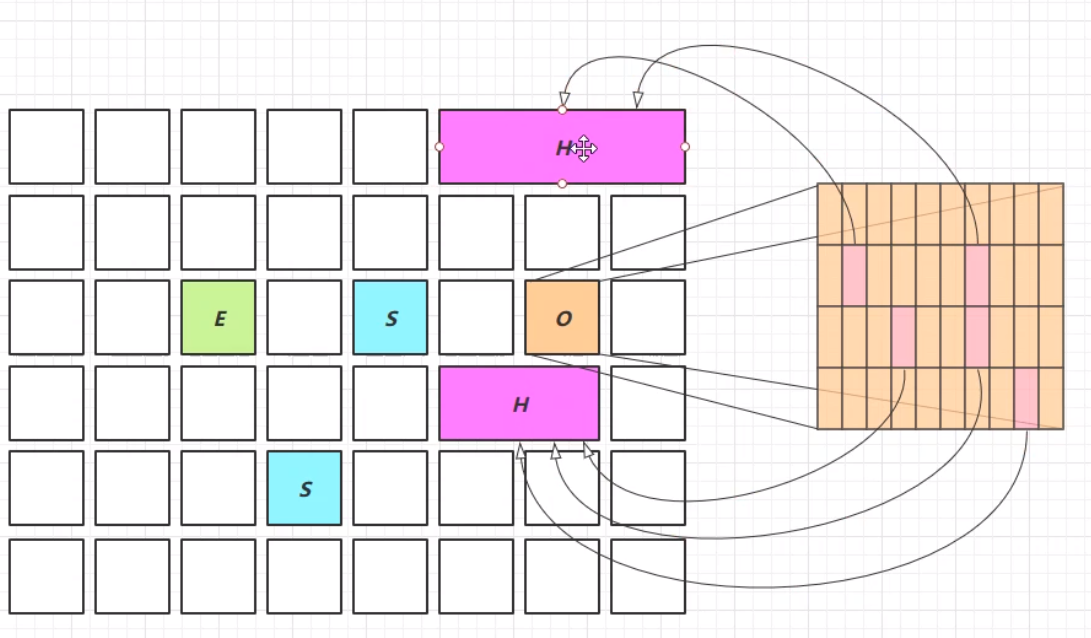
所有对象都经过并发标记后,就能知道哪些类不再被使用。当一个类加载器的所有类都不再被使用,就卸载它所加载的所有类,此功能默认开启。 -Xx:+ClassUnloadingWithConcurrentMark JDK 8u60 回收巨型对象 一个对象大于 region 的一半时,称之为巨型对象G1 不会对巨型对象进行拷贝回收时被优先考虑G1 会跟踪老年代所有 incoming 引用,这样老年代 incoming 引用为 0 的巨型对象就可以在新生代垃圾回收时处理掉巨型对象的内存占用情况,是指占用的区域超过region的一半。 当老年代中的卡表对于巨型对象的引用变为0的时候,巨型对象在新生代的时候就能够被垃圾回收。 根据内存占用情况以及垃圾回收所得的效益来看,垃圾回收的时候会优先回收掉巨型对象。
根据之前的G1回收的情况,G1在垃圾回收时会经历三个阶段:Young Collection、Young Collection+CM、Mixed Collection。这个时候由第一个阶段进入到第二个阶段,开始并发标记,这个阶段会产生一个阈值(即何时开始进行并发标记)。这个时候可以通过调整上述的参数得以调整堆内存的占比设定开始并发标记的时机,此参数的缺省值是45%。而在jdk 9的版本中,该值可以动态调整以达到最好的效果。 如果参数过大,会导致退化成Full GC如果参数过小,会导致频繁进行并发标记,降低效率 JDK 9更高效的回收 250+ 增强、180+ bug 修复文档:https://docs.oracle.com/en/java/javase/12/gctuning 垃圾回收调优 掌握 GC 相关的 VM 参数,会基本的空间调整掌握相关工具明白一点:调优跟应用、环境有关,没有放之四海而皆准的法则 调优领域调优领域一般包括:内存、锁竞争、CPU占用、IO 确定目标根据具体的需求,确定调优的目标。第二行的垃圾回收器针对的是低延迟、快速响应;第三行的垃圾回收器是针对高吞吐量。 其中,ZGC是jdk 12中的一个尚处于体验阶段的GC。此外还有Zing垃圾回收器,没有STW时间。 最后,如果发现没有合适的垃圾回收器选项,可以选择HotSpot之外的其他虚拟机的垃圾回收器。 【低延迟】还是【高吞吐量】,选择合适的回收器CMS,G1,ZGCParallelGC 最快的GC是不发生GC 查看 Full GC 前后的内存占用,考虑下面几个问题 数据是不是太多:resultSet = statement. executeQuery(“select * from 大表 limit n”) 数据表示是否太臃肿: 对象图对象大小 16 Integer 24 int 4 是否存在内存泄漏: static Map map = … 静态变量软引用弱引用第三方缓存实现 新生代调优 新生代的特点 所有的 new 操作的内存分配非常廉价:TLAB thread-local allocation buffer死亡对象的回收代价是零大部分对象用过即死Minor GC 的时间远远低于 Full GC以上的特点,说明了新生代优化空间大。在实际情况中,我们一般通过预设新生代的堆内存大小(预设堆内存),达到调优新生代的目的。
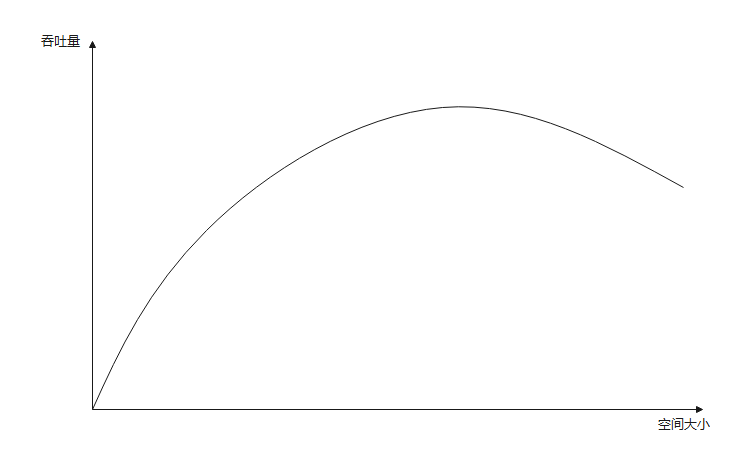
根据Oracle的官方建议,新生代的内存预设最好控制在整个堆内存的25%-50%之间。 吞吐量和新生代空间大小的关系大致如下所示:
新生代需要能容纳所有【并发量*(请求-响应)】的数据。其中,新生代中的幸存区需要能满足保留【当前活跃对象+需要晋升对象】的空间大小。
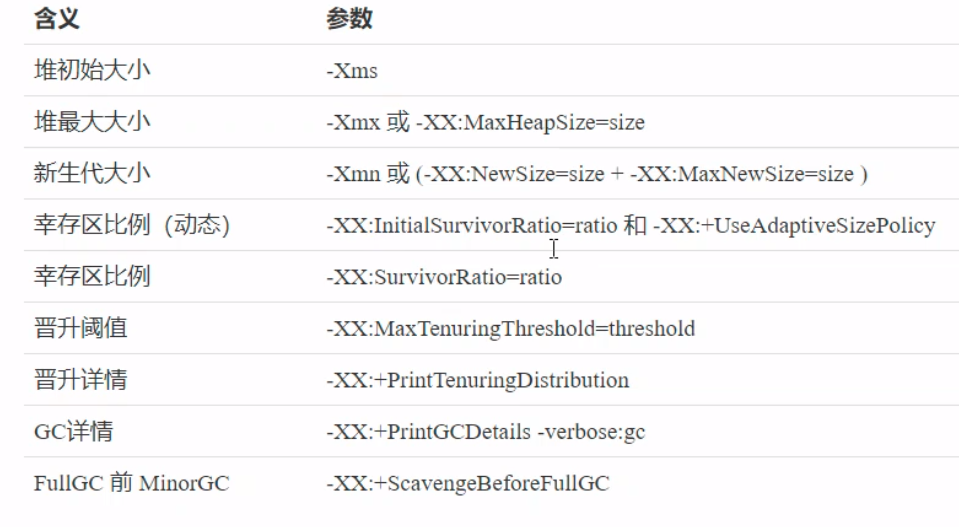
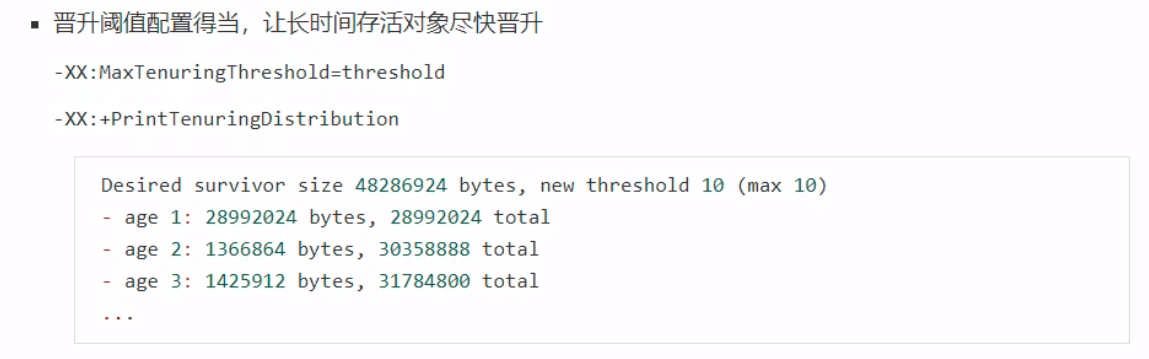
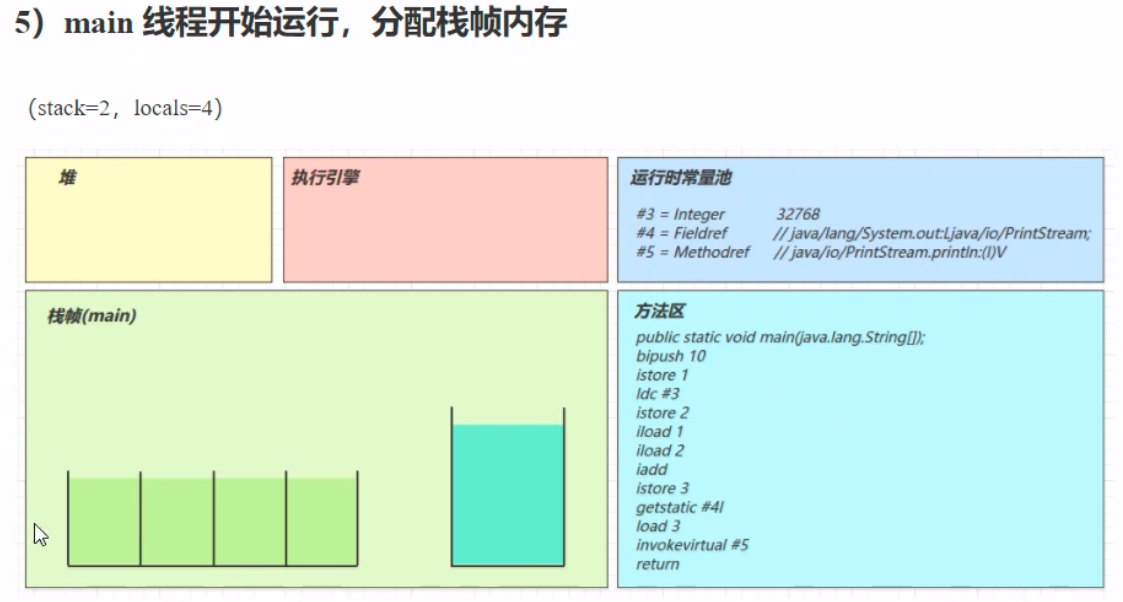
其中,第一个参数是设置新生代晋升为老年代的阈值;第二个参数是打印相关的参数信息,参数信息例如存活周期、内存大小、总内存。 老年代调优以 CMS 为例: CMS的老年代内存越大越好先尝试不做调优,如果没有 Full GC 那么已经… ,否则先尝试调优新生代观察发生 Full GC 时老年代内存占用,将老年代内存预设调大 1/4 ~ 1/3-XX:CMSInitiatingOccupancyFraction=percent 案例根据调优相关的问题,分析几个案例。 案例 1:Full GC 和 Minor GC 频繁案例 2:请求高峰期发生 Full GC ,单次暂停时间特别长(CMS)案例 3:老年代充裕情况下,发生 Full GC(1.7)这些案例中,需要先了解到GC过程中的一些流程。 初始标记:仅仅标记GC Roots的直接关联对象,并触发STW 并发标记:使用GC Roots Tracing算法,进行跟踪标记,不触发STW 重新标记:因为并发标记的缘故,其他用户线程不暂停,可能产生浮动垃圾,所以这一阶段产生STW 案例三中,JDK1.7版本使用的是元空间以及永久代,当元空间不足的时候,就会触发一次Full GC。解决方案就是增大元空间的初始值和最大值。 四、类加载和字节码技术 类文件结构
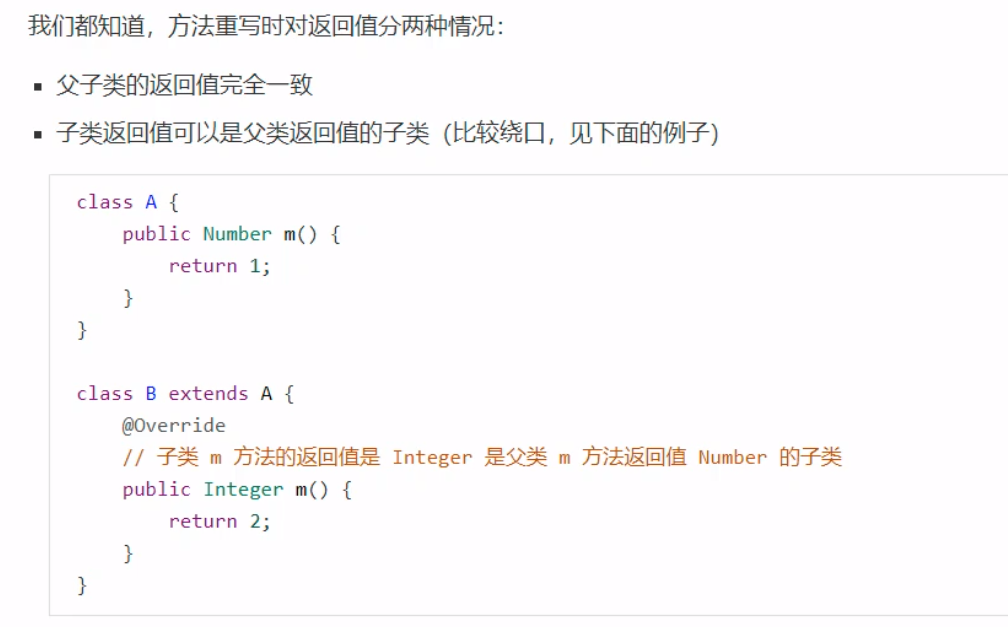
多态的原理
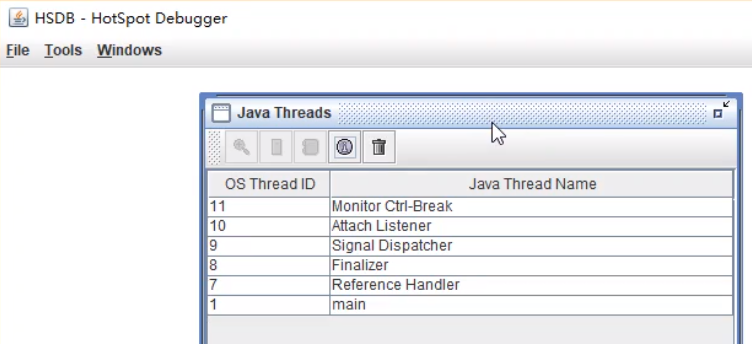
用HSDB工具,利用进程ID获取进程相关信息。
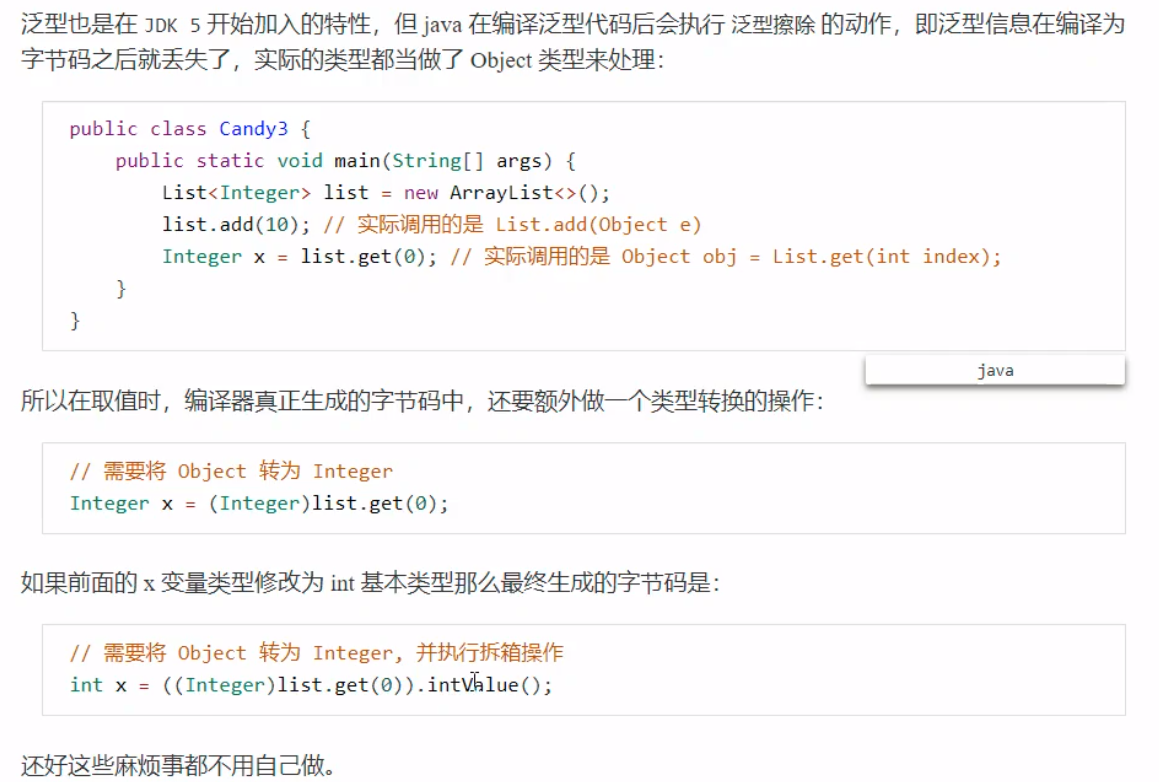
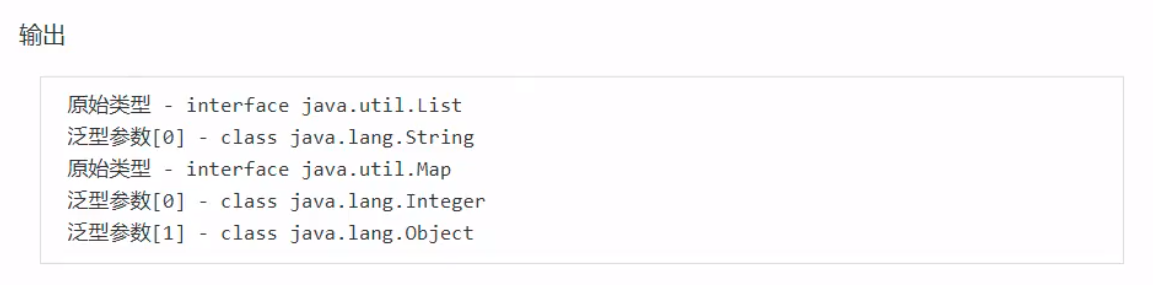
在字节码文件中,在第十四行中,调用接口,这一步做到了擦除泛型的操作。将泛型统一使用Object对象来操作,最后在27行的时候用checkcast执行了类型转换,转换回Integer。 擦除的是字节码上的泛型信息,可以看到LocalVariableTypeTable(局部变量类型表)仍然保留了方法参数泛型的信息。
如果hashcode相等,将会进一步利用equals方法进行比较。
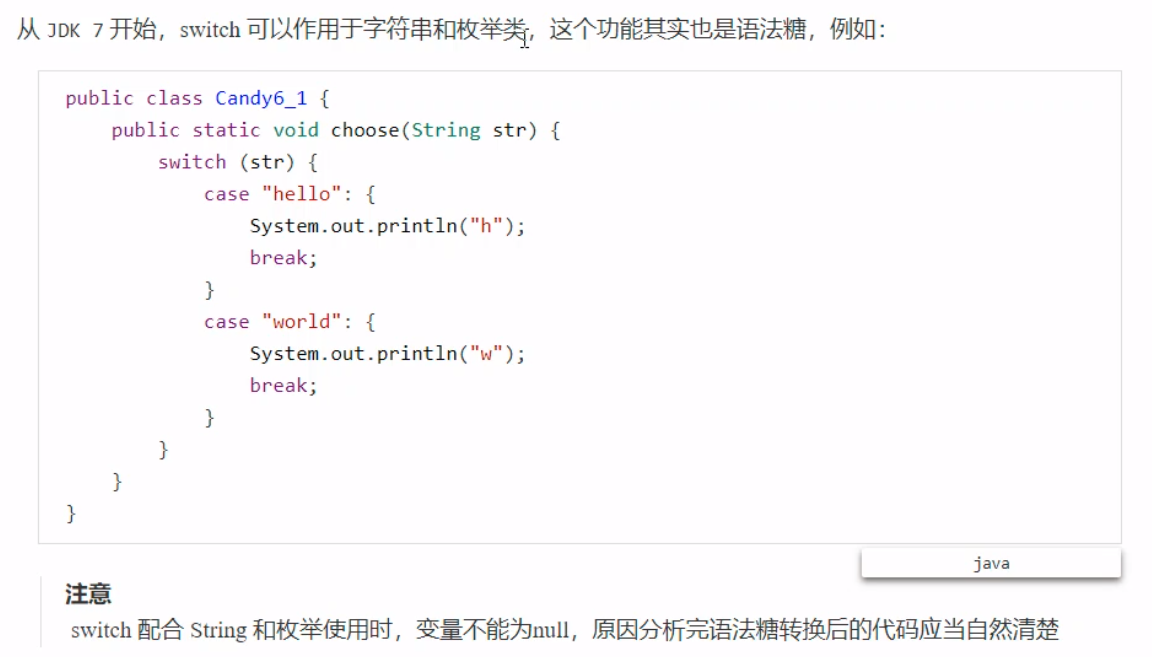
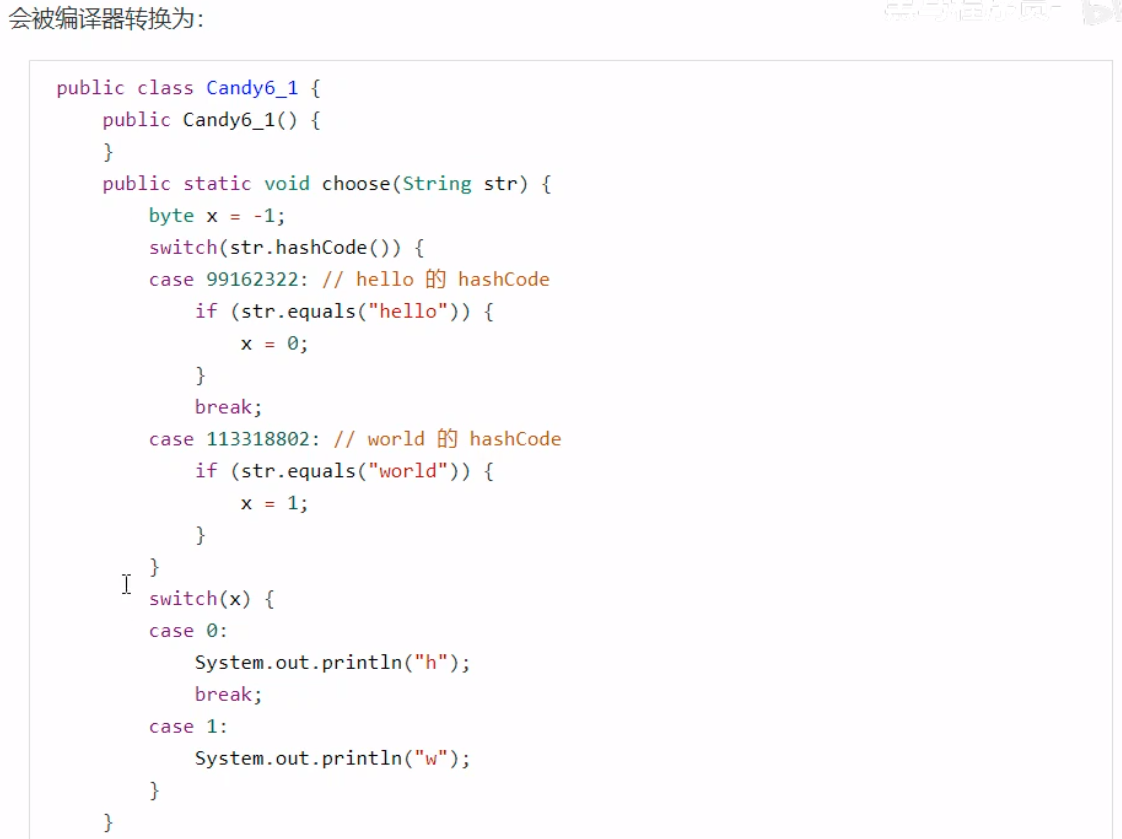
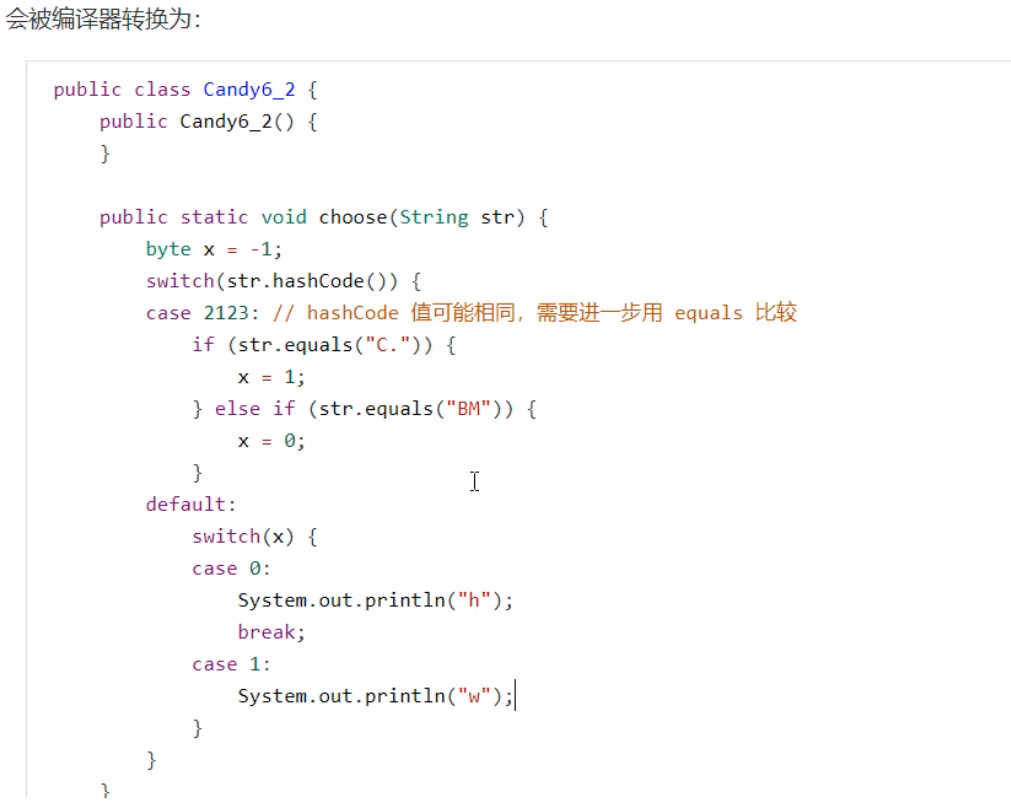
Switch枚举类在转换成字节码之后,会生成一个静态合成类。
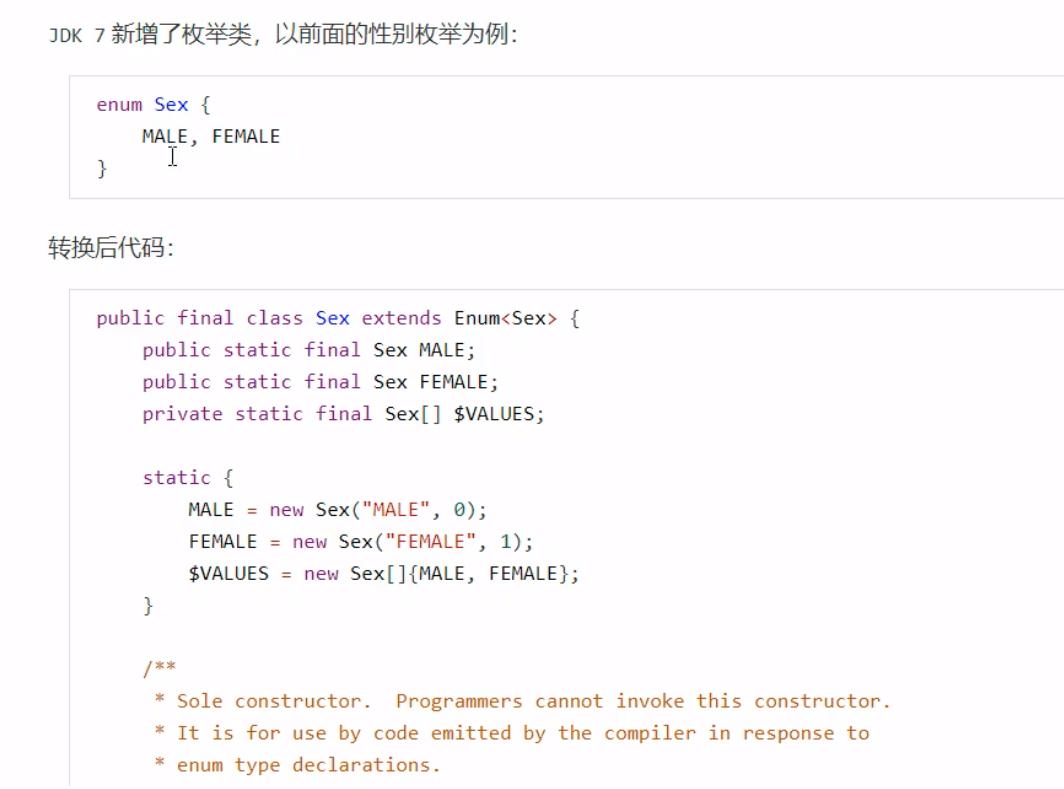
在这样的结构中,实际上是根据合成类的数组下标的值找到对应的case项。 枚举类枚举类的字节码生成,与上述的Switch枚举类类似,会生成静态类。
上述的代码在经过字节码转换后,会被转换为:
链接阶段分为三个步骤:验证、准备、解析 验证阶段:验证类是否符合JVM规范,安全性检查 准备阶段:当static变量是final的基本类型或者String字符串常量,则赋值操作就在准备阶段完成 解析阶段:将常量池中的符号解析为直接引用 验证:验证类是否符合JVM规范,安全性检查 用UE等支持二进制的编辑器修改HelloWorld.class的魔数,在控制台运行准备:为static量分配空间,设置默认值 static 变量在JDK 7之前存储于instanceKlass末尾,从JDK 7开始,存储于_ java_ mirror末尾static 变量分配空间和赋值是两个步骤,分配空间在准备阶段完成,赋值在初始化阶段完成如果static变量是final的基本类型,那么编译阶段值就确定了,赋值在准备阶段完成如果static变量是final的,但属于引用类型,那么赋值也会在初始化阶段完成
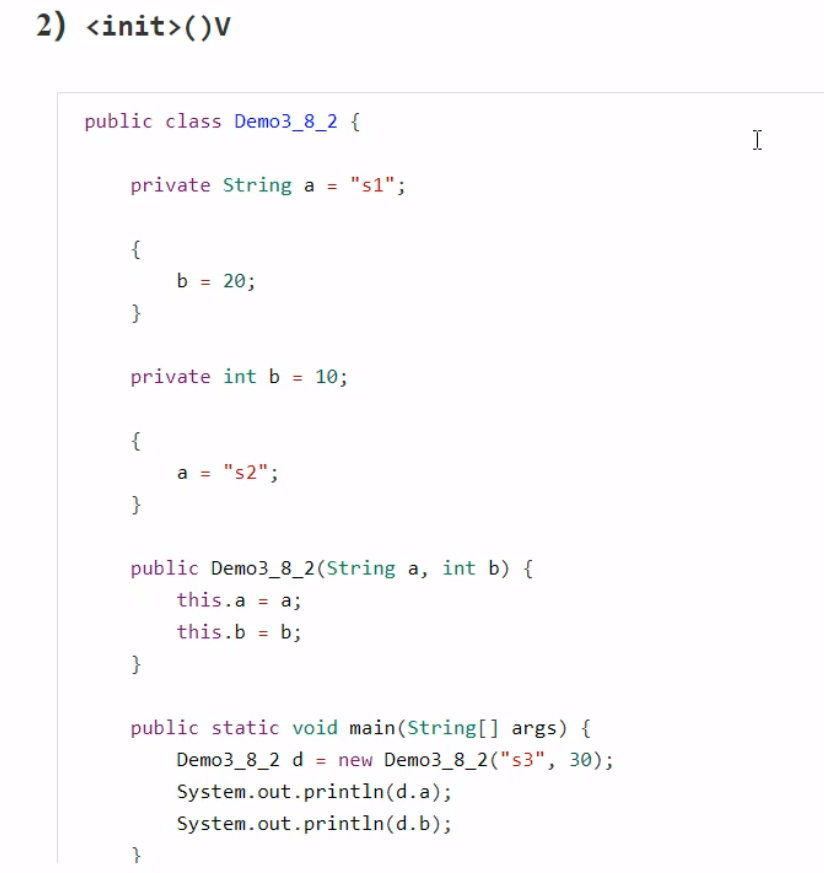
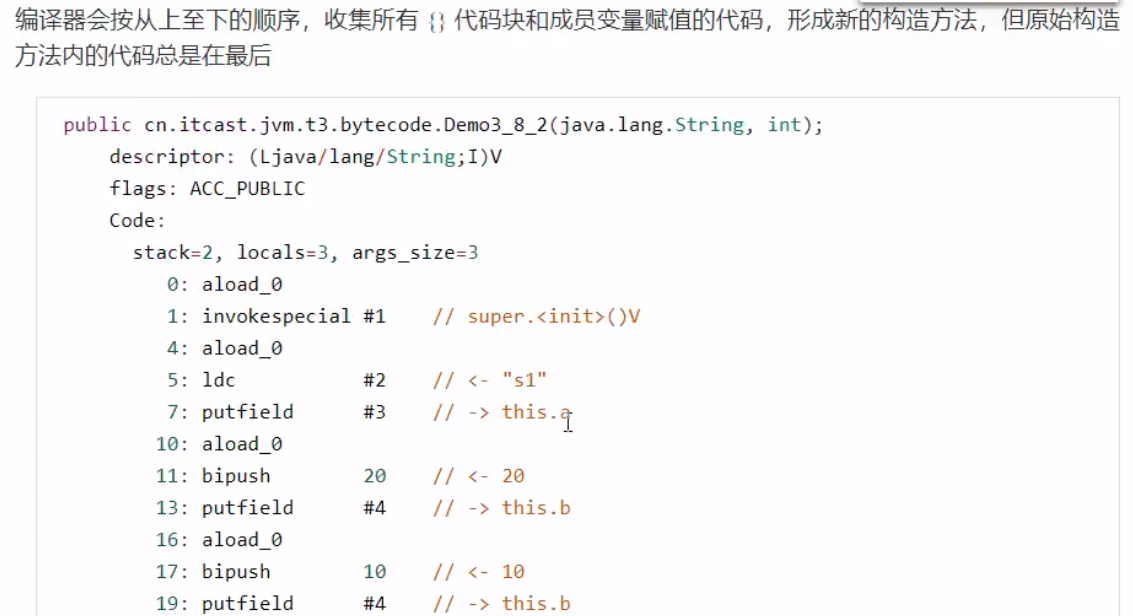
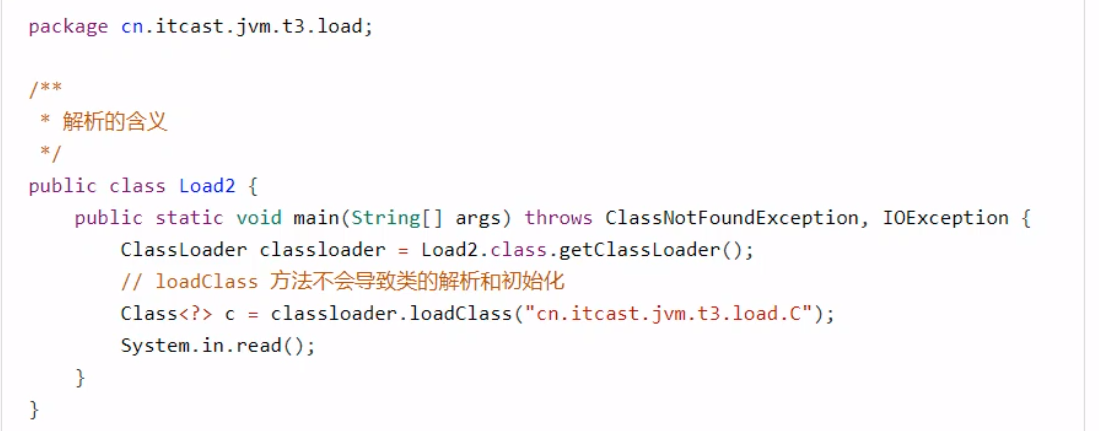
()V方法 初始化即调用()V,虚拟机会保证这个类的【构造方法】的线程安全。 发生的时机 概括得说,类初始化是【懒惰的】 main 方法所在的类,总会被首先初始化首次访问这个类的静态变量或静态方法时子类初始化,如果父类还没初始化,会引发子类访问父类的静态变量,只会触发父类的初始化Class.forNamenew会导致初始化不会导致类初始化的情况 访问类的static final静态常量(基本类型和字符串)不会触发初始化类对象.class 不会触发初始化创建该类的数组不会触发初始化类加载器的loadClass方法Class.forName的参数2为false时 类加载器
用getClassLoader方法得到类加载器,并且根据参数指定类交由特定的类加载器。
上述代码的执行结果:
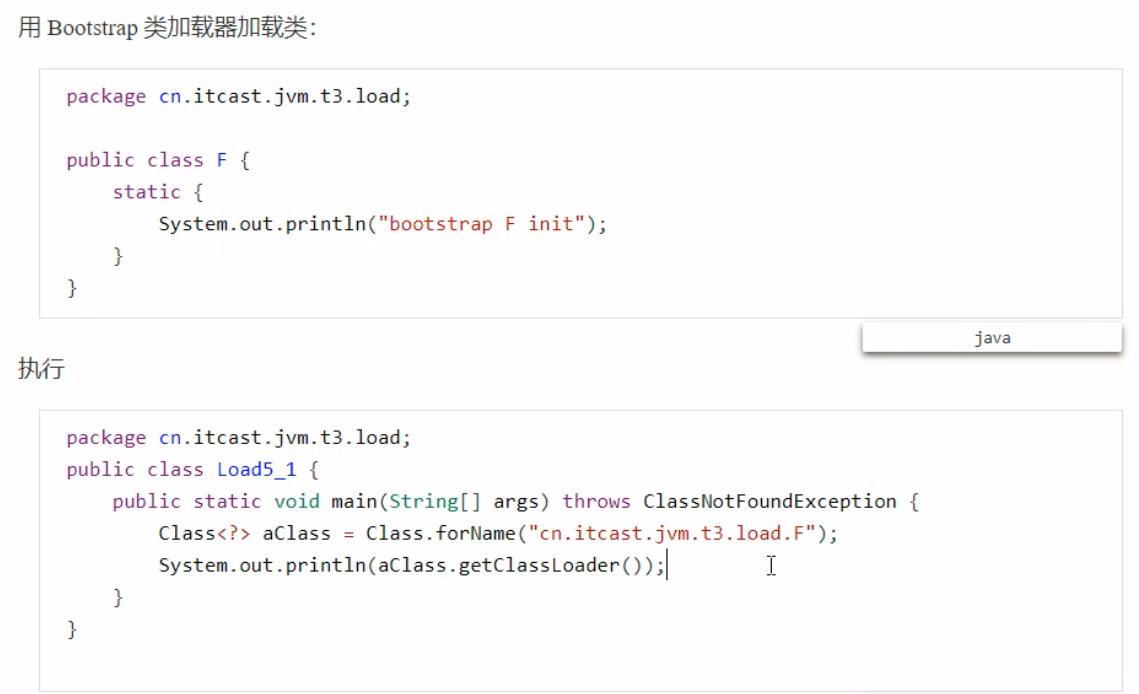
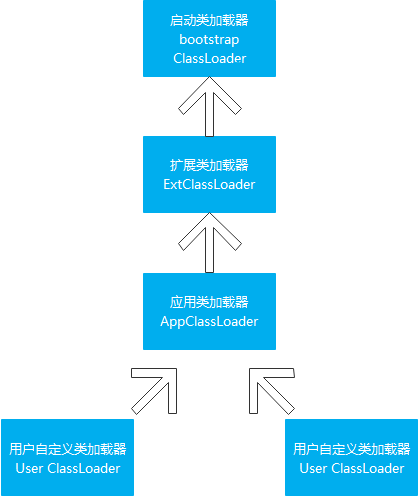
因为启动类加载器使用的是C++编写的,所以打印结果是null;如果是应用程序类加载器和扩展类加载器,则分别打印AppClassLoader、ExtClassLoader。 扩展类加载器
所谓的双亲委派,就是指调用类加载器的loadClass()方法时,查找类的规则。 这里的双亲,翻译为上级更合适,因为它们并没有继承关系 线程上下文类加载器
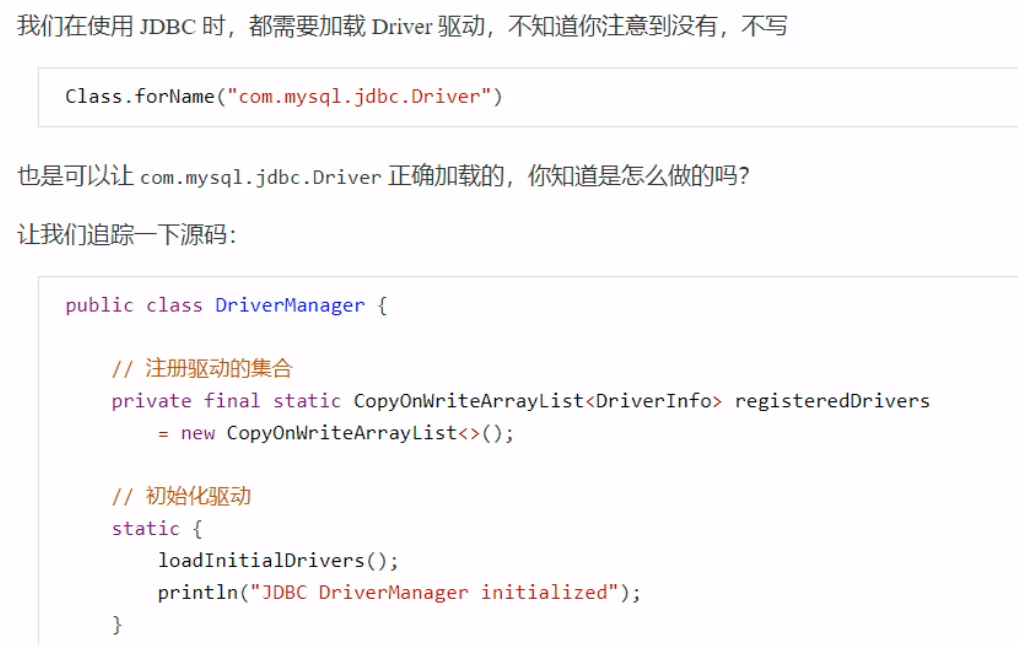
在JDk源码中,使用的是ClassLoader.getSystemClassLoader()方法来加载DriverManager类的。这一加载器其实就是ApplicationClassLoader加载器。所以真正开始使用的不是启动类加载器bootstrap,反而是应用程序类加载器,打破了原有的双亲委派模式。
使用线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader()方法进行设置,如果创建线程时还未设置,他将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。 有了线程上下文加载器,JNDI服务【Java Naming and Directory Interface(JAVA命名和目录接口)】就可以使用它去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则,但这也是无可奈何的事情。Java中所有涉及SPI的加载动作基本上都采用这种方式,例如JNDI、JDBC、JCE、JAXB和JBI等。 部分源代码如下所示:
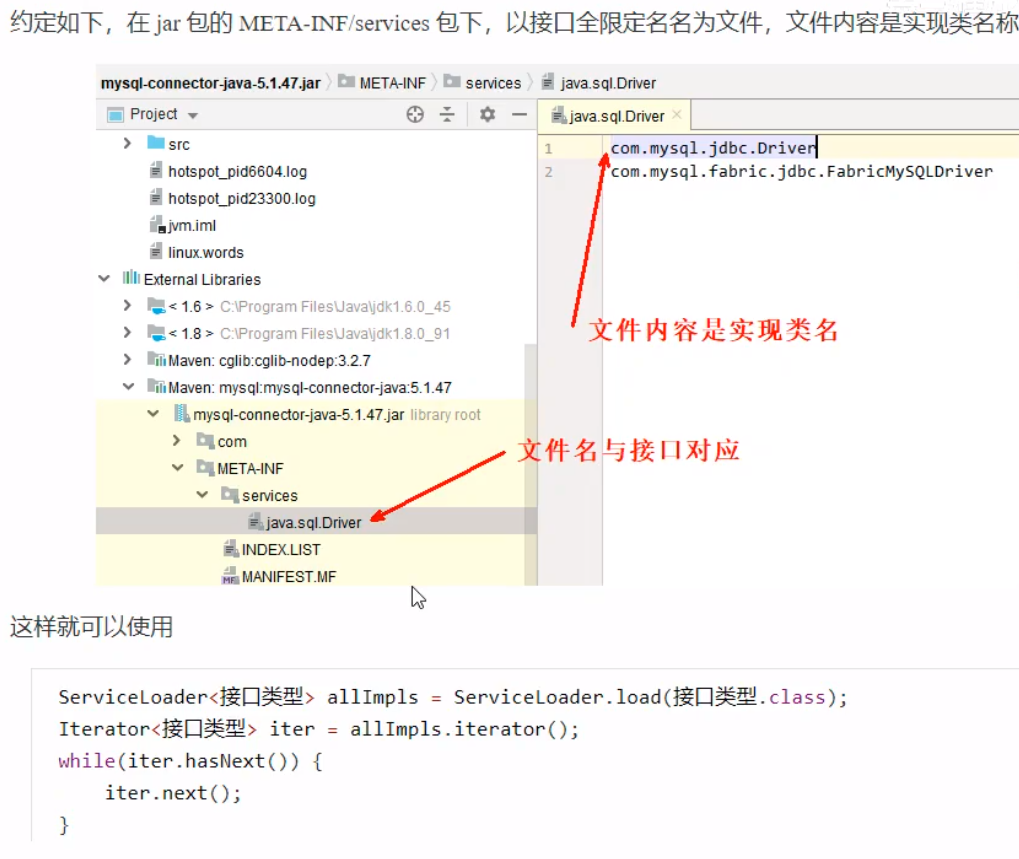
SPI(Service Provider Interface)的使用在一些项目中,在jar包下会有一个META-INF的文件夹,里面有一个services的子文件夹,内部存放着一些类的全限定名文件,文件内容是实现类名称。
以这样的方式得到实现类,体现的是【面向接口编程+解耦】的编程思想,在一些框架中都使用了这一思想:JDBC、Servlet初始化器、Spring容器、Dubbo(对SPI进行了扩展)。
步骤: 继承 ClassLoader 父类 要遵从双亲委派机制,重写 findClass 方法 注意不是重写 loadClass 方法,否则不会走双亲委派机制 读取类文件的字节码 调用父类的 defineClass 方法来加载类 使用者调用该类加载器的 loadClass 方法 运行期优化运行期间,JVM虚拟机会对代码做一定的优化。 编译器 编译器是一种计算机程序,负责把一种编程语言编写的源码转换成另外一种计算机代码,后者往往是以二进制的形式被称为目标代码(object code)。这个转换的过程通常的目的是生成可执行的程序。 编译器的产出是「另外一种代码」,然后这些代码等着被别人拿来执行,如果还不能直接被执行,那么还需要再编译或解释一遍,再交由计算机硬件执行。 编译器,往往是在「执行」之前完成,产出是一种可执行或需要再编译或者解释的「代码」。 解释器 解释器是一种计算机程序,它直接执行由编程语言或脚本语言编写的代码,并不会把源代码预编译成机器码。一个解释器,通常会用以下的策略来执行程序代码: 分析源代码,并且直接执行。 把源代码翻译成相对更加高效率的中间码,然后立即执行它。 执行由解释器内部的编译器预编译后保存的代码。 两者的异同 相同点:都是一种计算机程序 不同点:①编译器将源码转换成另一种计算机代码,解释器执行代码;②编译器不执行程序代码,解释器执行程序代码 即时编译JIT编译器,英文写作Just-In-Time Compiler,中文意思是即时编译器。
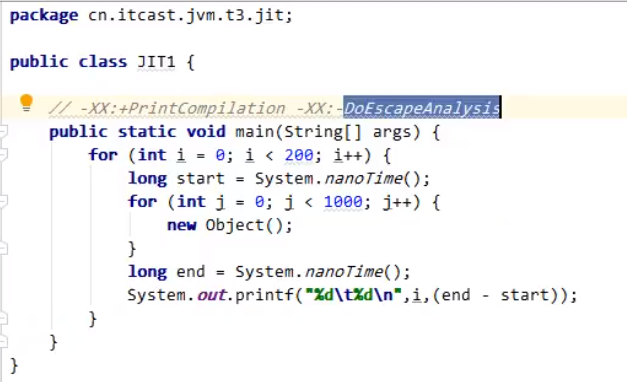
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。执行效率上简单比较一下 Interpreter < C1 < C2 ,总的目标是发现热点代码( hotspot 名称的由来),并优化之。 逃逸分析 逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。 JVM判断新创建的对象是否逃逸的依据有: 一、对象被赋值给堆中对象的字段和类的静态变量。 二、对象被传进了不确定的代码中去运行。 对于逃逸分析,目的就是发现新建的对象是否“逃逸”。在下面的代码中,后续的执行阶段中已经完成了逃逸分析,循环后期的运行速度大幅提升。高亮部分就是关闭逃逸分析。逃逸分析完成之后,代码的执行速度会大大加快,执行效率也会提升。
实验案例中的代码:
针对(静态)变量读写进行优化
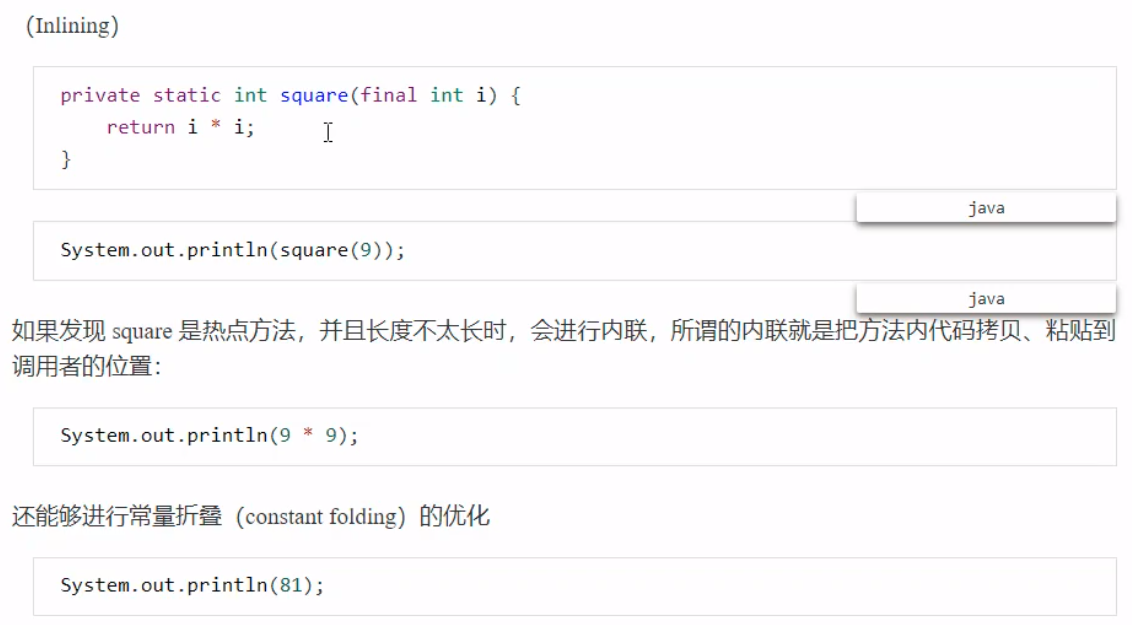
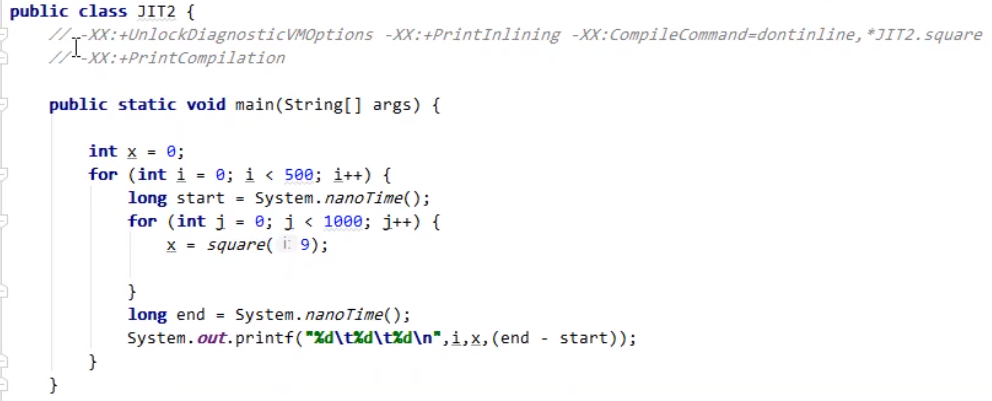
方法是否内联会影响到成员变量读取的优化。 在测试代码(如下)中,这种优化相当于首次读取就已经完成了求长度以及取下标的操作,省去了1999次Field读取操作。 但是如果刚才的代码没有进行方法内联(被禁用),则不会进行上述的首次读取缓存操作,最终会导致效率下降。
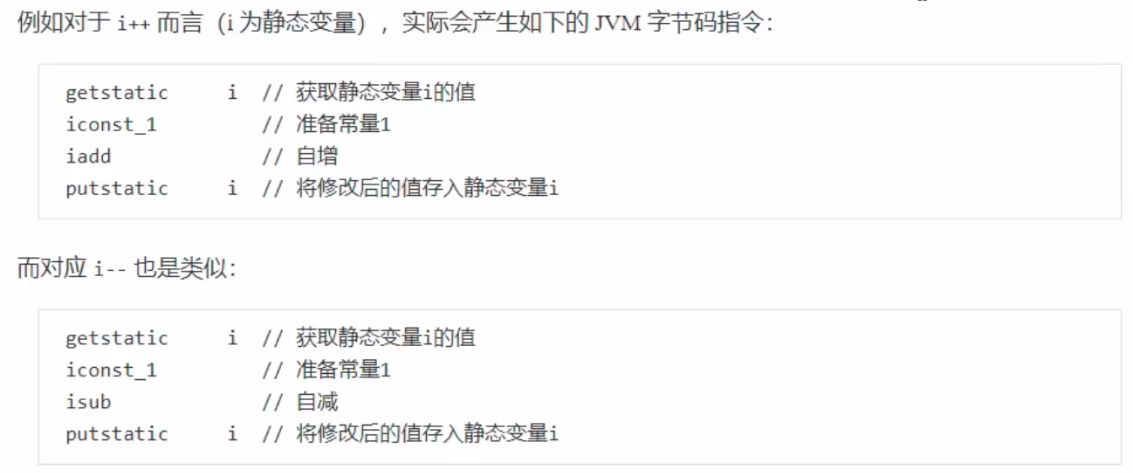
定义 反射机制是在运行状态中,对于任意的一个类,都能够知道这个类的所有属性和方法,对任意一个对象都能够通过反射机制调用一个类的任意方法,这种动态获取类信息及动态调用类对象方法的功能称为java的反射机制。 作用 ①动态地创建类的实例,将类绑定到现有的对象中,或从现有的对象中获取类型。 ②应用程序需要在运行时从某个特定的程序集中载入一个特定的类。 优化 反射的方法调用,在第1-15次调用中是非常快的,也就是前十五次的反射调用是非常快的,但是在第十六次及以后,对于反射的调用就变得很慢了。原因是在反射相关的源码中,有一个名为膨胀阈值的参数,缺省值为15。 ReflectionFactory.inflationThreshold(); private static int inflationThreshold = 15;注意:通过查看 ReflectionFactory 源码可知: sun.reflect.noInflation 可以用来禁用膨胀(直接生成 GeneratedMethodAccessorl ,但首次生成比较耗时,如果仅反射调用一次,不划算)sun.reflect.inflationThreshold 可以修改膨胀阈值要想直接使用生成的MethodAccessor,而非使用本地的MethodAccessor,可以使用RefletionFactory.noInflation = true;来禁用膨胀。 五、内存模型 Java内存模型Java内存模型是指Java Memory Model(JMM),内存模型与之前的内存结构不是同一个概念。 JMM定义了一套在多线程读写共享数据(成员变量、数组)时,对数据的原子性、可见性、有序性的规则和保障。 原子性在Java中,由两个线程,对一个静态变量0分别进行5000次的自增和自减,最终输出的结果会是0吗?答案是不一定,多次运行的结果并不相同,可能是正数,也可能是负数,也可能是0。原因是因为:Java中对静态变量的自增自减操作并不是原子操作。
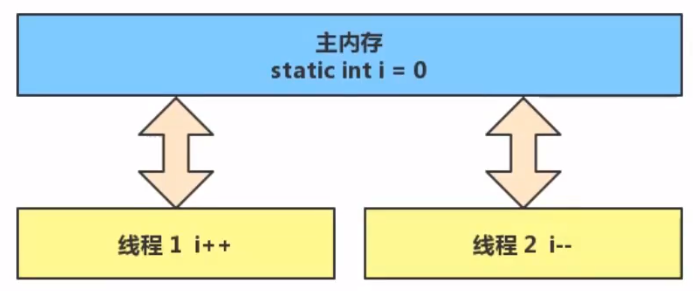
Java中对于静态变量的自增自减会在主内存和线程内存中进行数据交换。也就是说,对于共享的变量,比如静态变量,进行线程操作的话,会在主内存和线程内存中进行数据交换。共享变量储存在主内存中,这里的主内存区别于计算机组成原理中的主存。
之前的案例中,出现负数的情况,有可能如下所示:
正数的情况就是将线程1、2的执行顺序调换了,这种情况就属于更新数据丢失,最终打印的值并不能体现实际的变换过程。因为在实际的运行过程中,线程是会交错运行的,这就是导致刚才的案例结果不确定的原因。 要避免这样的更新丢失情况出现,解决办法就是使用同步synchronized()。 synchronized (Object) { // 要进行原子操作的代码 }同步的大体概念是使用monitor监视需要同步的线程的运行情况,Owner中的线程与EntryList中的线程、WaitSet中的线程,当同步中的线程正在运行的时候,就会让其他想要访问或者使用同步代码块中的变量的线程阻塞或者等待,从而达到原子性的效果。 如何理解:你可以把obj想象成一个房间,线程t1,t2想象成两个人。 当线程t1执行到synchronized(obj)时就好比t1进入了这个房间,并反手锁住了门,在门内执行count++代码。 这时候如果t2也运行到了synchronized(obj) 时,它发现门被锁住了,只能在门外等待。 当t1执行完synchronized{}块内的代码,这时候才会解开门上的锁,从obj房间出来。t2 线程这时才可以进入obj房间,反锁住门,执行它的count–代码。 注意:上例中t1和t2线程必须用synchronized锁住同一个obj对象,如果t1锁住的是m1对象,t2 锁住的是m2对象,就好比两个人分别进入了两个不同的房间,没法起到同步的效果。 可见性
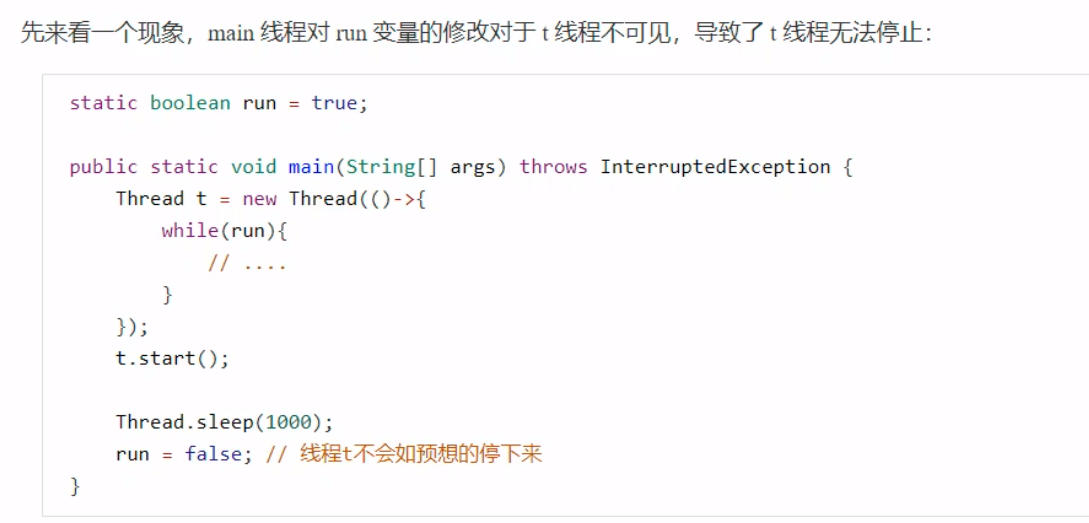
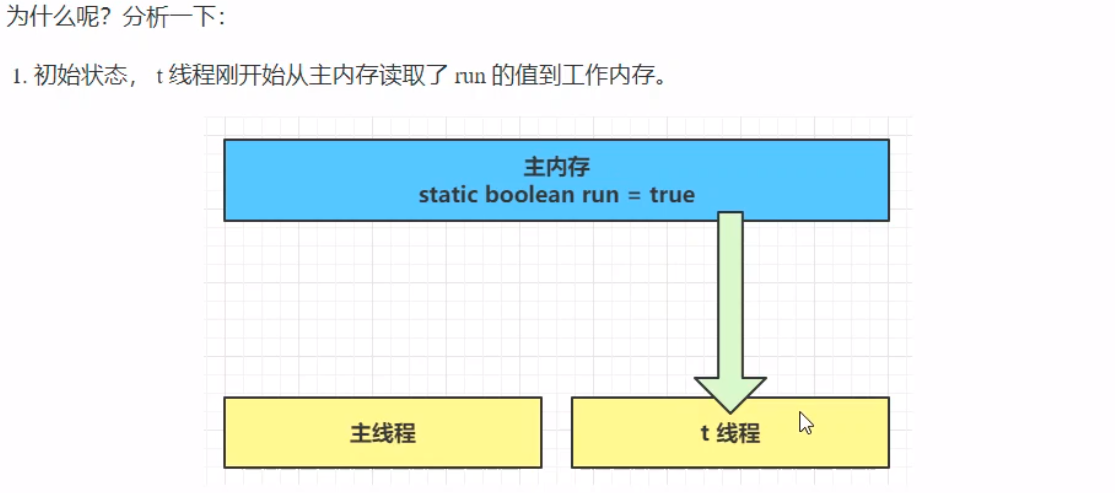
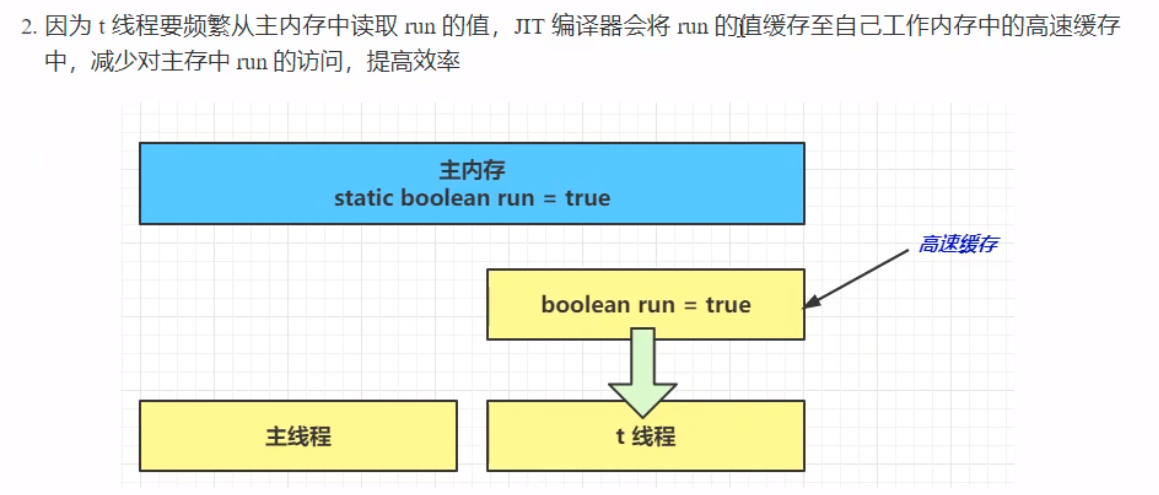
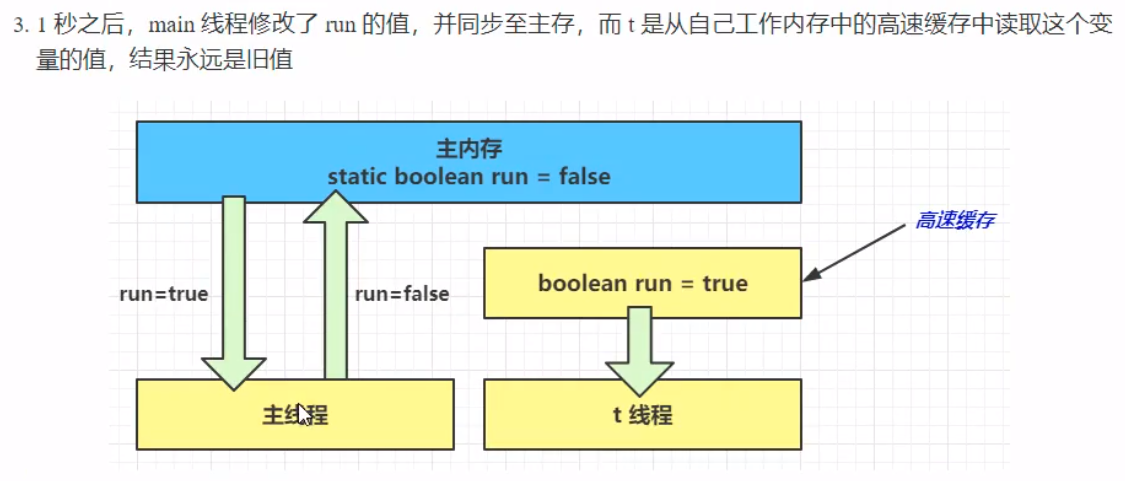
在这个案例中,循环并不会像预期中的那样停下来,会陷入一个死循环中。 但是:在该代码中,将while()语句块中添加System.out.println()语句,程序也能自己停下来。这是因为:println()方法中使用了synchronized()方法,会强制将t线程读取的JIT编译器的优化产生的高速缓存区转换为主内存,获取到run变量的更新,最终导致程序自主停止。 在涉及到synchronized()语句时,特定情况下,既可以保证原子性,也能够保证可见性。 下图表明了为何会出现程序的可见性问题(JIT编译器优化后的高速缓存):
由于主线程和t线程读取的变量并不是在同一个区域,从而导致主线程修改的变量值没有传到t线程,这就是可见性的问题。这样导致了主线程的修改失败,从而使得刚才的程序一直陷入死循环。 解决办法 引入关键字volatile(易变),前面讲到的synchronized是一种阻塞式同步,在线程竞争激烈的情况下会升级为重量级锁,性能相对更低,而volatile则是java虚拟机提供的最轻量级的同步机制。 volatile可以用来修饰成员变量和静态成员变量,它可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作volatile变量都是直接操作主存。 volatile adj.易变的; 无定性的; 无常性的; 可能急剧波动的; 不稳定的; 易恶化的; 易挥发的; 易发散的; 解决可见性的痛点在于:数据的更新不能即使更新到每一个线程中,导致数据被”脏读“。而volatile的出现正是为了解决这种现象的出现。 被volatile修饰的变量能够保证每个线程能够获取该变量的最新值,从而避免出现数据脏读的现象。
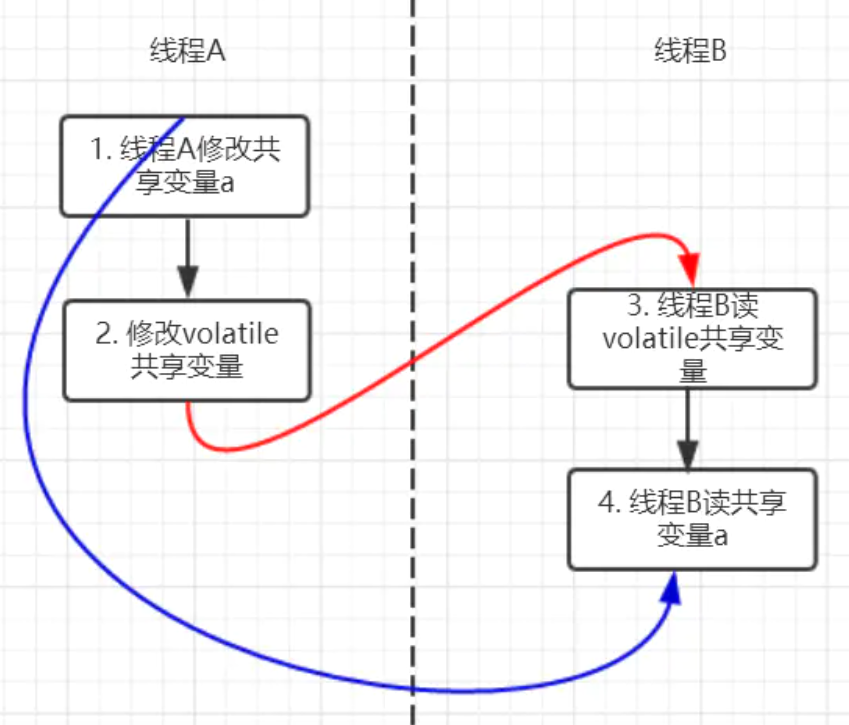
它保证的是在多个线程之间,一个线程对volatile变量的修改对另一个线程可见,保证的是可见性,不能保证原子性。仅用在一个写线程,多个读线程的情况。 有序性
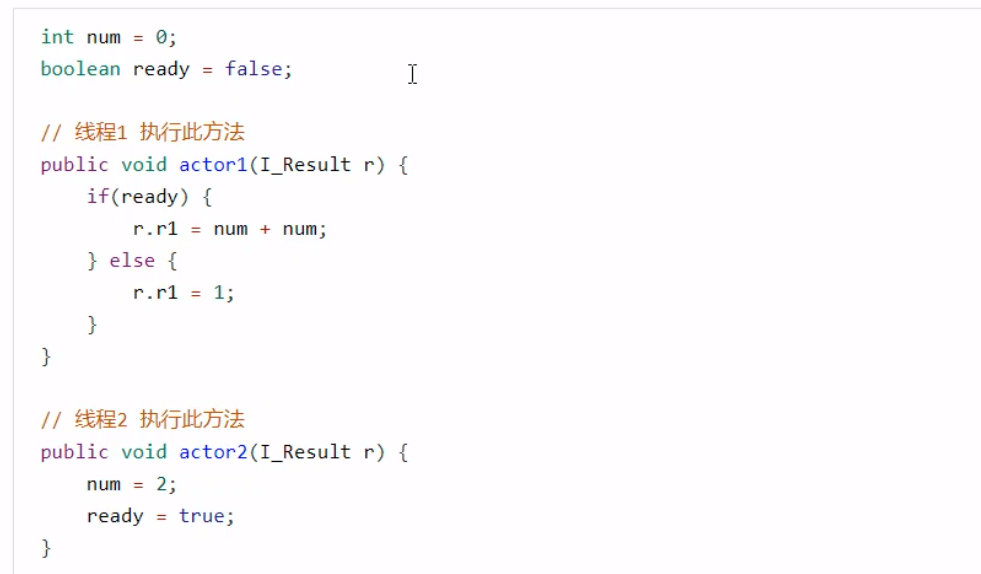
上面这段代码被执行后,可能有几种情况? 情况1:线程1先执行,这时 ready = false ,所以进入 else 分支结果为 1情况2:线程2先执行 num = 2 ,但没来得及执行 ready = true ,线程 1 执行,还是进入 else 分支,结果为 1情况3:线程2执行到 ready = true ,线程 1 执行,这回进入 if 分支,结果为 4 (因为 num 已经执行过了)除了这三种情况,还有可能结果为0。因为在线程2执行ready = true,切换到线程1,进入if分支,相加为0,再切回线程执行num = 2。 这种现象叫做指令重排,是JIT编译器在运行时做的一些优化。 解决方法就是使用volatile修饰变量,可以禁用指令重排。 同一个线程内,JVM会在不影响正确性的前提下调整语句的执行顺序。 这种特性我们称之为【指令重排】,多线程下的指令重排会影响正确性,例如double-check locking模式实现单例。
以上的实现特点是: 懒惰实例化首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁happens-before happens-before规定了哪些写操作对其他的读操作可见,它是可见性和有序性的一套规则总结。 t.join()方法只会使主线程(或者说调用t.join()的线程)进入等待池并等待t线程执行完毕后才会被唤醒。并不影响同一时刻处在运行状态的其他线程。 CAS和原子类
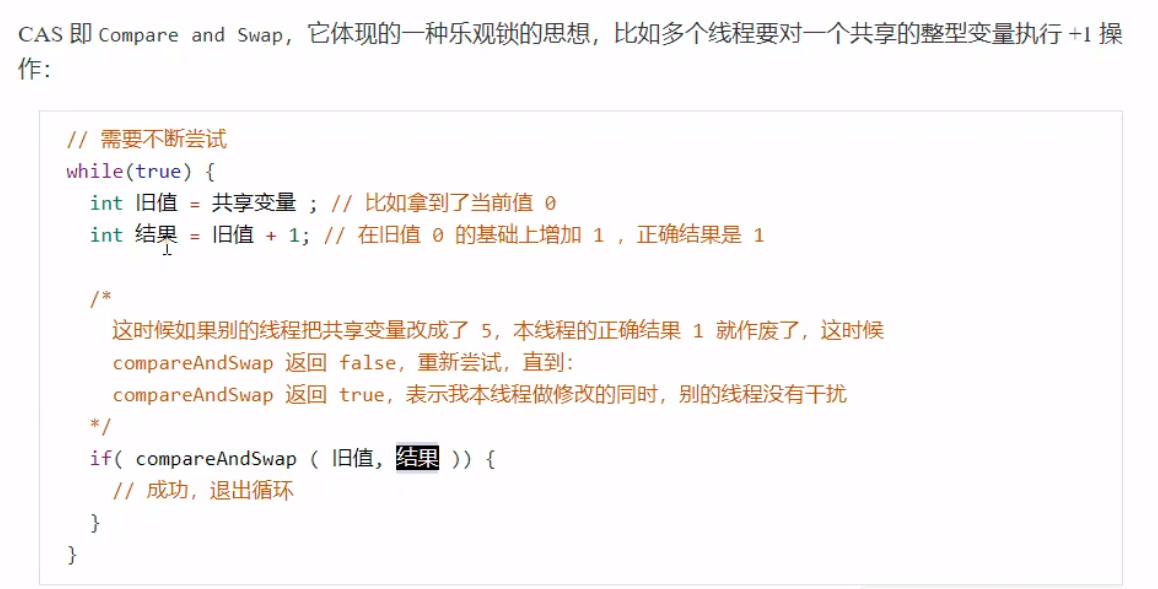
乐观锁和悲观锁 CAS是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试。synchronized是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。原子操作类 juc (java.utilconcurrent) 中提供了原子操作类,可以提供线程安全的操作,例如:AtomicInteger、AtomicBoolean 等,它们底层就是采用 CAS 技术 + volatile 来实现的。 synchronized优化Java HotSpot虚拟机中,每个对象都有对象头(包括class指针和Mark Word)。Mark Word平时存储这个对象的哈希码、分代年龄,当加锁时,这些信息就根据情况被替换为标记位、线程锁记录指针、重量级锁指针、线程ID等内容。 轻量级锁如果一个对象虽然有多线程访问,但多线程访问的时间是错开的(也就是没有竞争),那么可以使用轻量级锁来优化。这就好比学生(线程A)用课本占座,上了半节课,出门了(CPU时间到),回来一看, 发现课本没变,说明没有竞争,继续上他的课。 如果这期间有其它学生(线程B) 来了,会告知(线程A)有并发访问,线程A随即升级为重量级锁,进入重量级锁的流程。 而重量级锁就不是那么用课本占座那么简单了,可以想象线程A之前,把座位用一个铁栅栏围起来。 锁膨胀
①减少上锁时间:同步代码块中的代码尽量短 ②减少锁的粒度 将一个锁拆分成多个锁,提高并发度 ConcurrentHashMapLongAdder 分为 base 和 cells 两部分。没有并发争用的时候或者是 cells 数组正在初始化的时候,会使用 CAS 来累加值到 base ,有并发争用,会初始化 cells 数组,数组有多少个 cell ,就允许有多少线程并行修改,最后将数组中每个 cell 累加,再加上 base 就是最终的值LinkedBlockingQueue 入队和出队使用不同的锁,相对于 LinkedBlockingArray 只有一个锁效率要高在访问 hashmap 的时候,只锁住链表头,每次只锁住一个链表,其他链表的读取不受影响,相当于锁的粒度减少了,降低了上锁的难度。 ③锁粗化 多次循环进入同步块不如同步块内多次循环另外 JVM 可能会做相应的优化:把多次 append 的加锁操作粗化为一次(因为都是对同一个对象加锁,没必要重入多次) new StringBuffer().append("a").append("b").append("c");锁粗化在实际操作中使用比较多,在多次循环步骤需要加锁的时候,建议将锁加在循环外部,将整个循环部分放在锁的内部,减少上锁的次数,这就是属于锁粗化,避免在循环的时候,每进行一次循环,加一次锁。 ④锁消除 JVM会进行代码的逃逸分析。例如某个加锁对象是方法的局部变量,不会被其他线程所访问到,这时候就会被即时编译器忽略掉所有同步操作。 ⑤读写分离 CopyOnWriiteArrayList CopyOnWriteSet |























































【本文地址】
今日新闻 |
推荐新闻 |