LangChain 12调用模型HuggingFace中的Llama2和Google Flan t5 |
您所在的位置:网站首页 › huggingface的modelgenerate › LangChain 12调用模型HuggingFace中的Llama2和Google Flan t5 |
LangChain 12调用模型HuggingFace中的Llama2和Google Flan t5
|
LangChain系列文章 LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieveLangChain 5易速鲜花内部问答系统LangChain 6根据图片生成推广文案HuggingFace中的image-caption模型LangChain 7 文本模型TextLangChain和聊天模型ChatLangChainLangChain 8 模型Model I/O:输入提示、调用模型、解析输出LangChain 9 模型Model I/O 聊天提示词ChatPromptTemplate, 少量样本提示词FewShotPromptLangChain 10思维链Chain of Thought一步一步的思考 think step by stepLangChain 11实现思维树Implementing the Tree of Thoughts in LangChain’s Chain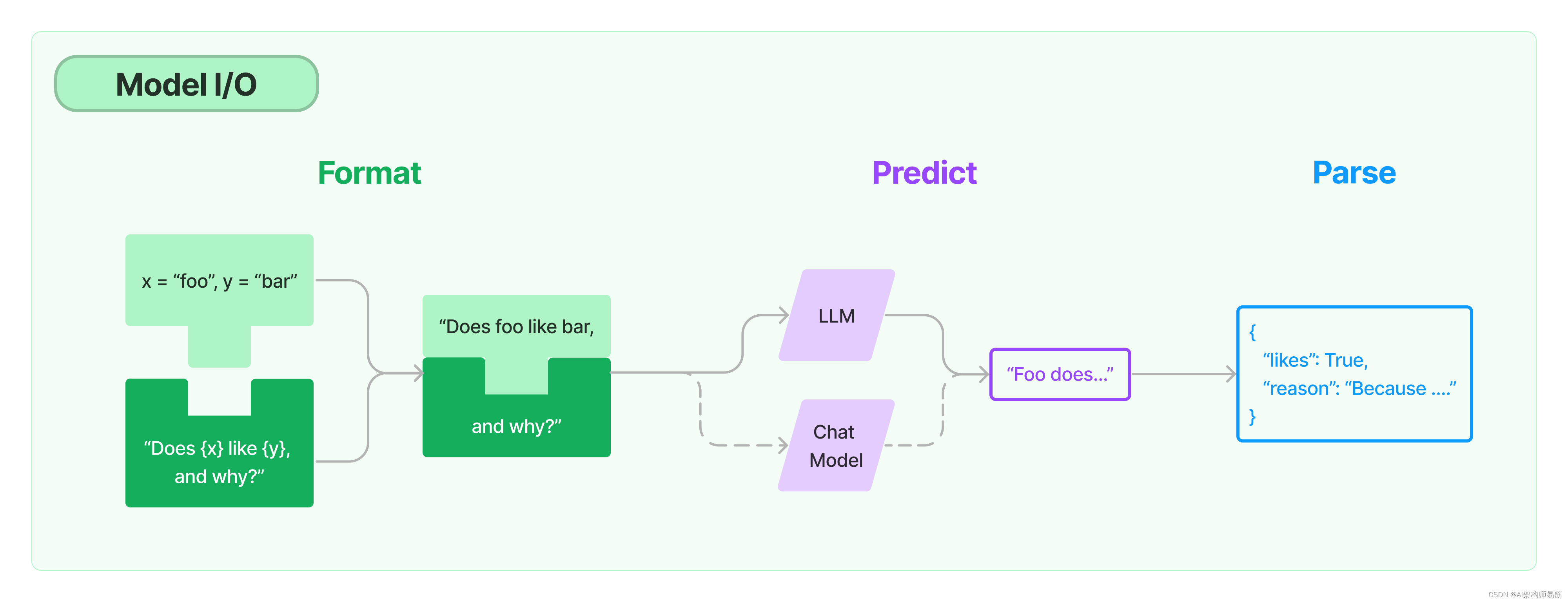
这里会用到开源的LLM,也就是Predict的Model部分。 Hugging Face 的 transformers 库。 1. Hugging Face 设置用 HuggingFace 跑开源模型注册并安装 HuggingFace 第一步,还是要登录 HuggingFace 网站,并拿到专属于你的 Token。 点击Hugging Face token获取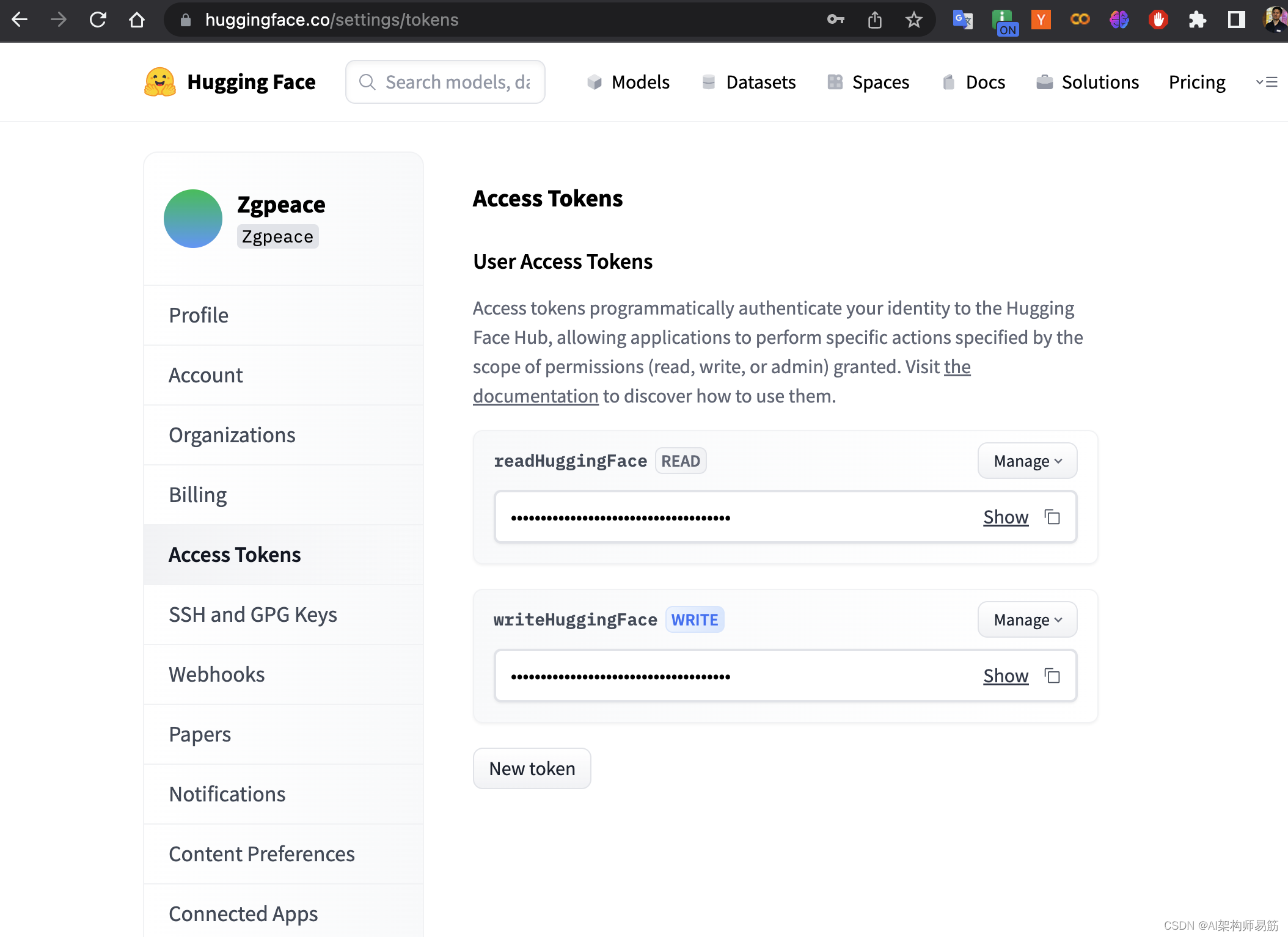 第二步,用 pip install transformers 安装 HuggingFace Library 详见这里。第三步,在命令行中运行 huggingface-cli login,设置你的 API Token。 第二步,用 pip install transformers 安装 HuggingFace Library 详见这里。第三步,在命令行中运行 huggingface-cli login,设置你的 API Token。 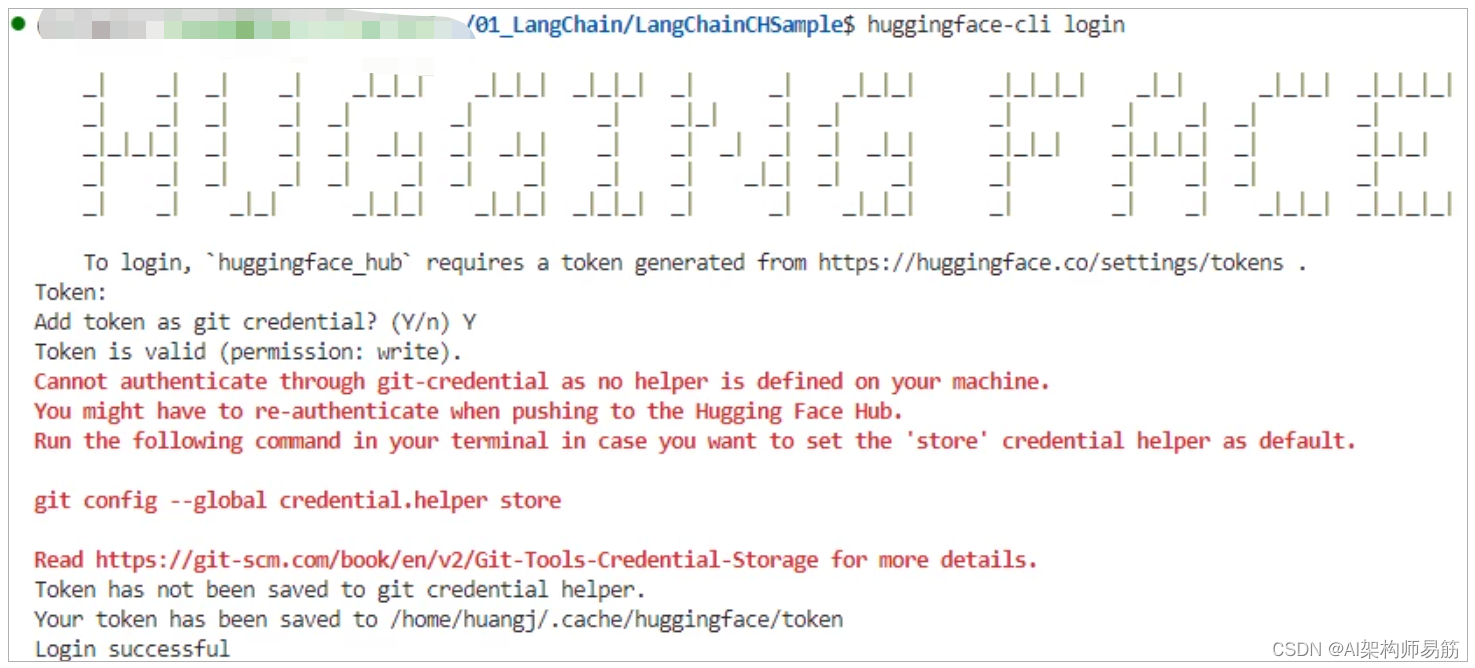
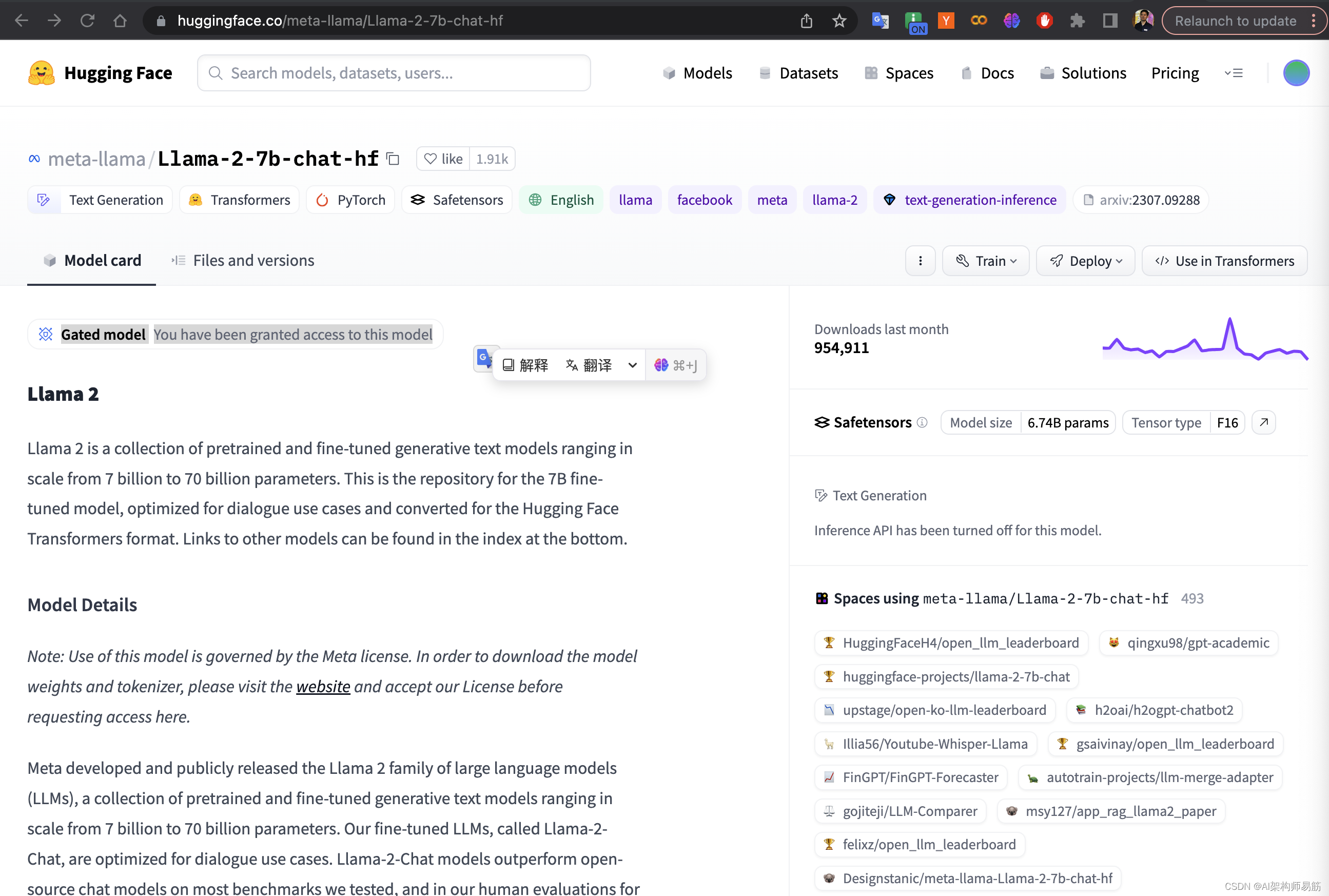
Llama-2-7b-chat-hf 需要申请才能用,点击链接申请 申请成功会有提示: Gated model You have been granted access to this model
文件代码LLM/hf_google_flan_t5.py # 导入dotenv库,用于从环境配置文件.env中加载环境变量。 # 这通常用于安全地管理敏感数据,例如API密钥。 from dotenv import load_dotenv # 执行load_dotenv函数,从.env文件加载环境变量到Python的环境变量中。 load_dotenv() # 从transformers库导入T5Tokenizer和T5ForConditionalGeneration。 # 这些是用于NLP的预训练模型和对应的分词器。 from transformers import T5Tokenizer, T5ForConditionalGeneration # 从预训练模型"google/flan-t5-small"加载T5分词器。 # 这个模型专门用于文本生成任务,如翻译、摘要等。 tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-small") # 加载预训练的T5条件生成模型。 model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-small") # 定义输入文本,这里是一个英译德的翻译任务。 input_text = "translate English to German: How old are you?" # 使用分词器处理输入文本,将文本转换为模型可理解的输入ID。 # return_tensors="pt"表示返回的是PyTorch张量。 input_ids = tokenizer(input_text, return_tensors="pt").input_ids # 使用模型生成响应,即对输入文本进行翻译。 outputs = model.generate(input_ids) # 解码模型输出,将生成的ID转换回文本格式,并打印出来。 print(tokenizer.decode(outputs[0]))执行结果 (.venv) [zgpeace@zgpeaces-MBP langchain-llm-app (feature/textAndChat ✗)]$ python LLM/hf_google_flan_t5.py You are using the default legacy behaviour of the . This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained. /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/transformers/generation/utils.py:1273: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation. warnings.warn( Wie ich er bitten? 3. 调用Llama2 # 导入dotenv库,用于从环境配置文件.env中加载环境变量。 # 这主要用于安全地管理敏感数据,例如API密钥。 from dotenv import load_dotenv # 调用load_dotenv函数来从.env文件加载环境变量。 load_dotenv() # 从transformers库导入AutoTokenizer和AutoModelForCausalLM。 # 这些用于自动加载和处理预训练的语言模型。 from transformers import AutoTokenizer, AutoModelForCausalLM # 加载tokenizer,用于将文本转换为模型能理解的格式。 # 这里使用的是预训练模型"meta-llama/Llama-2-7b-chat-hf"。 tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf") # 加载预训练的因果语言模型。 # 指定模型的设备为"auto",以自动选择运行模型的最佳设备(CPU或GPU)。 model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf") # 将模型分配到适当的设备上 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device) # 定义一个提示文本,要求生成关于水果的爱情故事。 prompt = "你是一位起水果运营专家,请讲一个动人的关于水果的爱情故事。" # 使用tokenizer处理输入文本,并将其转移到模型的设备上。 # 这里return_tensors="pt"表示返回的是PyTorch张量。 inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # 使用模型生成回应,设置最大长度、采样参数以控制生成的文本多样性。 outputs = model.generate(inputs["input_ids"], max_length=2000, do_sample=True, top_p=0.95, top_k=60) # 将生成的输出解码为文本,并跳过特殊标记。 response = tokenizer.decode(outputs[0], skip_special_tokens=True) # 打印生成的故事。 print(response)执行结果,老机器了macOS pro, 16G内存,跑步了。。 $ python LLM/hf_llama.py [1] 2024 killed /usr/local/bin/python3.10 LLM/hf_llama.py /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown warnings.warn('resource_tracker: There appear to be %d '这个错误信息包含了两个部分,一个是进程被终止(killed),另一个是关于资源泄漏的警告(leaked semaphore objects)。 进程被终止([1] 2024 killed) 内存不足:最常见的原因是系统内存不足。当 Python 脚本使用的内存超过系统可用内存时,操作系统会终止进程以防止系统崩溃。这在运行大型机器学习模型(如LLM)时尤其常见。 4. Langchain 调用google flan t5, Llama2回答问题文件LLM/langchain_hf_google_flan_t5.py (代码参考了黄佳老师的课程Demo,如需要知道代码细节请读原文) # 导入dotenv库,用于从.env文件加载环境变量。 # 这对于管理敏感数据,如API密钥,非常有用。 from dotenv import load_dotenv # 调用load_dotenv函数来加载.env文件中的环境变量。 load_dotenv() # 从langchain库导入所需的类。 from langchain.prompts import PromptTemplate from langchain.llms import HuggingFaceHub from langchain.chains import LLMChain # 初始化Hugging Face Hub中的语言模型。 # 这里使用的是"google/flan-t5-small"作为repo_id来指定模型。 # repo_id="meta-llama/Llama-2-7b-chat-hf"是另一个可选的模型。 llm = HuggingFaceHub( repo_id="google/flan-t5-small" # repo_id="meta-llama/Llama-2-7b-chat-hf" ) # 创建一个简单的问答模板。 # 模板包含了问题(question)和回答(Answer)的格式。 template = """Question: {question} Answer: """ # 创建一个PromptTemplate对象,基于上面定义的模板和输入变量。 prompt = PromptTemplate(template=template, input_variables=["question"]) # 使用LLMChain,它是一种将提示和语言模型结合起来的方法。 # 这里将前面创建的prompt和llm(语言模型)结合起来。 llm_chain = LLMChain( prompt=prompt, llm=llm ) # 定义一个问题. question = "Please tell a lovely story." # 使用llm_chain运行模型,传入问题,并打印结果。 # 这将根据提供的问题生成回答。 print(llm_chain.run({"question": question}))运行结果 (.venv) [zgpeace@zgpeaces-MBP langchain-llm-app (feature/textAndChat ✗)]$ python LLM/langchain_hf_google_flan_t5.py /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/huggingface_hub/utils/_deprecation.py:127: FutureWarning: '__init__' (from 'huggingface_hub.inference_api') is deprecated and will be removed from version '1.0'. `InferenceApi` client is deprecated in favor of the more feature-complete `InferenceClient`. Check out this guide to learn how to convert your script to use it: https://huggingface.co/docs/huggingface_hub/guides/inference#legacy-inferenceapi-client. warnings.warn(warning_message, FutureWarning) The sandstones are a great place to go.答非所问,以下截图为证 修改为Llama-2 model llm = HuggingFaceHub( # repo_id="google/flan-t5-small" repo_id="meta-llama/Llama-2-7b-chat-hf" )Llama2 还行 zgpeace at zgpeaces-MBP in ~/Workspace/LLM/langchain-llm-app (develop●) (.venv) $ python LLM/langchain_hf_google_flan_t5.py /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/huggingface_hub/utils/_deprecation.py:127: FutureWarning: '__init__' (from 'huggingface_hub.inference_api') is deprecated and will be removed from version '1.0'. `InferenceApi` client is deprecated in favor of the more feature-complete `InferenceClient`. Check out this guide to learn how to convert your script to use it: https://huggingface.co/docs/huggingface_hub/guides/inference#legacy-inferenceapi-client. warnings.warn(warning_message, FutureWarning) Of course, I'd be happy to tell you a story. Here's one that
|
 token 这是到macOS 的文件中.zshrc, 文件.env 中填写对应的key
token 这是到macOS 的文件中.zshrc, 文件.env 中填写对应的key

【本文地址】