Python抓取数据如何设置爬虫ip |
您所在的位置:网站首页 › hp4200设ip › Python抓取数据如何设置爬虫ip |
Python抓取数据如何设置爬虫ip
|
在写爬虫爬取github数据的时候,国内的ip不是非常稳定,在测试的时候容易down掉,因此需要设置爬虫ip。本片就如何在Python爬虫中设置爬虫ip展开介绍。 也可以爬取外网 爬虫编写 需求 做一个通用爬虫,根据github的搜索关键词进行全部内容爬取。 代码 首先开启爬虫ip,在设置中修改HTTP端口。  在爬虫中根据设置的系统爬虫ip修改proxies的端口号: import requests from lxml import html import time etree = html.etree def githubSpider(keyword, pageNumberInit): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.62', } # 搜索的关键词 keyword = keyword # 查询的起始页数 pageNum = pageNumberInit # 设置一个通用的url模板 url = 'https://github.com/search?p=%d&q={}'.format(keyword) # 根据爬虫ip配置端口进行修改 proxies = {'http': 'http://jshk.com.cn:30008', 'https': 'http://jshk.com.cn:30009'} status_code = 200 while True and pageNum: # 对应页码的url new_url = format(url % pageNum) # 使用通用爬虫对url对应的一整张页面进行爬取 response = requests.get(url=new_url, proxies=proxies, headers=headers) status_code = response.status_code # 状态码 if status_code == 404: # 最后一页 print("===================================================") print("结束") return if (status_code == 429): # 访问次数过多 print("正在重新获取第" + str(pageNum) + "页内容....") if (status_code == 200): # 正常爬取 print("===================================================") print("第" + str(pageNum) + "页:" + new_url) print("状态码:" + str(status_code)) print("===================================================") page_text = response.text tree = etree.HTML(page_text) li_list = tree.xpath('//*[@id="js-pjax-container"]/div/div[3]/div/ul/li') for li in li_list: name = li.xpath('.//a[@class="v-align-middle"]/@href')[0].split('/', 1)[1] link = 'https://github.com' + li.xpath('.//a[@class="v-align-middle"]/@href')[0] # 解决没有star的问题 try: stars = li.xpath('.//a[@class="Link--muted"]/text()')[1].replace('\n', '').replace(' ', '') except IndexError: print("名称:" + name + "\t链接:" + link + "\tstars:" + str(0)) else: print("名称:" + name + "\t链接:" + link + "\tstars:" + stars) pageNum = pageNum + 1 if __name__ == '__main__': githubSpider("hexo",1) # 输入搜索关键词和起始页数爬取结果如下,包含搜索结果的名称、链接以及stars: 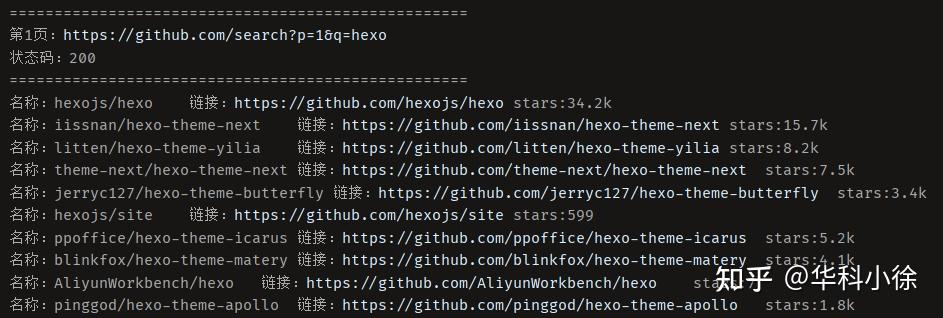 后记 爬取公网的简单测试,状态码: import requests #配置爬虫ip proxies={'http': 'http://jshk.com.cn:30008', 'https': 'http://jshk.com.cn:30009'} response = requests.get('https://www.google.com/',proxies=proxies) print(response.status_code) |
【本文地址】