论文笔记:Gate |
您所在的位置:网站首页 › gsm论文 › 论文笔记:Gate |
论文笔记:Gate
|
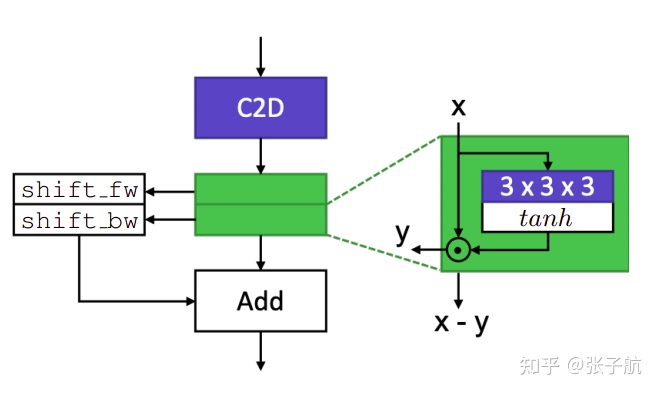
论文笔记:Gate-Shift Networks for Video Action Recognition(GSM) 代码链接: https://github.com/swathikirans/GSM 文章链接: https://arxiv.org/pdf/1912.00381.pdf 文章提出动机:当前视频行为识别各式各样,但没有达到像图像识别,ALexnet那样的效果。3D卷积参数多,计算量大,在数据集不多的情况下效果不尽如人意。因此借鉴TSM的时间移位思想(shift_forward,shift_backward),和GST的分组卷积思想。提出GSM(Gate-Shift Module) 文章思想:将输入的特征,划分为两个部分,分别进行2D卷积(空间建模)和3D卷积(时序建模)。本文提出了一种自适应划分的方法,自适应的判断对输入的特征哪一部分进行空间建模,哪一部分进行时序建模。 方法: 将输入的特征 X 沿着channel维度等划分为2部分 X1,X2,代码里为均分,前32channel为一部分,后32channel为一部分。分别对 X1,X2,进行三维卷积然后乘tanH,得到门控 feature: g1,g2将特征分为两个部分:
问题及看法: 1.为什么划分为两个特征? 参考GST分组卷积的思路 ,在保证效果的同时,减少参数计算 2.为什么进行前向shift和反向shift,有什么依据吗? 参考TSM模块,在2D卷积的基础上,进行时间移位,融合时序信息,进行时序建模。 疑惑: 1.为什么说,文章可以自适应的判断对输入的特征哪一部分进行空间建模,哪一部分进行时序建模。这里的“哪一部份”是指时序上的不同部分,还是指channel上的不同部分? 2.文章中说,门控可以根据训练数据的不同自适应的改变模型,是什么意思?可否举例说明? |
【本文地址】
今日新闻 |
推荐新闻 |