nvidia |
您所在的位置:网站首页 › gpu占用率和显存占用率忽上忽下 › nvidia |
nvidia
|
一、nvidia-smi
解释二: 参数: GPU:GPU编号 Name:GPU型号 Persistence-M:持续模式的状态。持续模式虽然耗能⼤,但是在新的GPU应⽤启动时,花费的时间更少,这⾥显⽰的是off的状态; Fan:风扇转速,从0到100%之间变动; Temp:温度,单位是摄⽒度; Perf:性能状态,从P0到P12,P0表⽰最⼤性能,P12表⽰状态最⼩性能(即 GPU 未⼯作时为P0,达到最⼤⼯作限度时为P12)。 Pwr:Usage/Cap:能耗; 【*】Memory Usage:显存使用率; Bus-Id:涉及GPU总线的东西,domain:bus:device.function; Disp.A:Display Active,表示GPU的显示是否初始化; 【*】Volatile GPU-Util:浮动的GPU利用率; Uncorr. ECC:Error Correcting Code,错误检查与纠正; Compute M:compute mode,计算模式。 下面的 Processes 表示每个进程对 GPU 的显存使用率。 2、 命令:nvidia-smi -L #列出所有可用的 NVIDIA 设备信息。
3、 命令3:watch -n 1 nvidia-smi #每 1s 显示 GPU 使用情况,在原有上面修改方式刷新
5、其他刷新频率 nvidia-smi -l 5 # 每隔5秒刷新一次 nvidia-smi -lms # 每隔1ms刷新一次,( L小写字母,不是1) nvidia-smi -lms 500 # 每隔500毫秒刷新一次二、 显存占用高,但是CPU使用率低 参考地址:TensorFlow 显存占用率高 GPU利用率低 - it610.com 显存占用率:5456MiB/6144MiB = 88.80% GPU利用率(GPU-Util):0% (即使100ms刷新一次也捕捉不到GPU利用率的提高) PS: 这里先补充一个知识,回想一下CPU和内存的关系,同理,GPU和显存是两回事,理所当然,GPU利用率和显存占用率也是两回事,现在的情况相当于:内存快占满,但CPU使用率很低,eg: 如Java中while(true)创建对象,内存会爆,但是CPU使用率并不高。 上述显卡显存占用率高,GPU利用率低的情况出现在笔记本跑深度学习时,最初以为是显存太低的缘故(load一个batch_size((一次训练的图片数))的数据即过载),换在16G显存的服务器中跑,同样出现该问题: 修改batch_size(一次训练的图片数)大小,无效,改大改小都不行。 怎么解决呢? 答: 试了n多的方法,终于找到原因: 训练的原始图片大小为3024 * 4032,实际大小为2-3M,太大了。。。 如果解释为什么,则先了解一个背景知识,类似于CPU与内存的关系,在GPU工作流水线中,也是按照显存准备数据——GPU拿数据运算——显存准备数据——GPU拿数据运算 …的方式工作的。如果图片的分辨率太大,图片放入显存直接爆了,GPU利用率当然也无从谈起,外在表现就是显存几乎占满,但同时GPU等不到数据,一直空闲。解决方法是将图片分辨率改小就OK了。 所以这个问题的解决思路是这样的: ① 确认代码在GPU上跑了 方法可以top-down: * 单独建测试文件test.py,代码: import os from tensorflow.python.client import device_lib os.environ["TF_CPP_MIN_LOG_LEVEL"] = "99" if __name__ == "__main__": print(device_lib.list_local_devices())如果正常的话,会打印GPU信息。 或者也可以直接运行项目的训练模型,如果TensorFlow调用了GPU,也会输出类似上面测试代码的运行效果——输出的GPU信息(猜测是TensorFlow内部也有类似上面的打印GPU信息的代码),此时(必须正在运行TensorFLow代码)查看nvidia-smi的线程信息会有python.exe(): 好,已经能够确定TensorFlow调用了GPU跑代码。 ② 观察显存和GPU利用率 一定要使用动态刷新nvidia-smi命令,因为有时GPU利用率是跳跃式变化的,同时尽量关 闭其他使用GPU的程序,单独观察tensorflow利用情况。 显存占用低,GPU利用率低 很明显,这是因为batch_size太小,显存没完全利用,GPU没有喂饱,尝试增大batch_size显存占用高,GPU利用率低 大概率batch_size太高,即显存成为bottle_neck,GPU一直在等显存的数据。如果batch_size已经为1,问题依旧,则考虑是不是单张图片分辨率太大的问题。 |
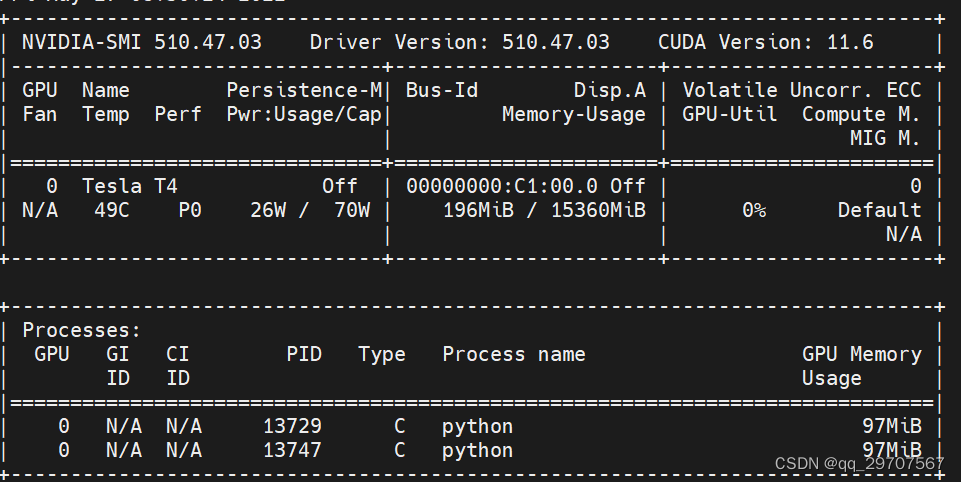

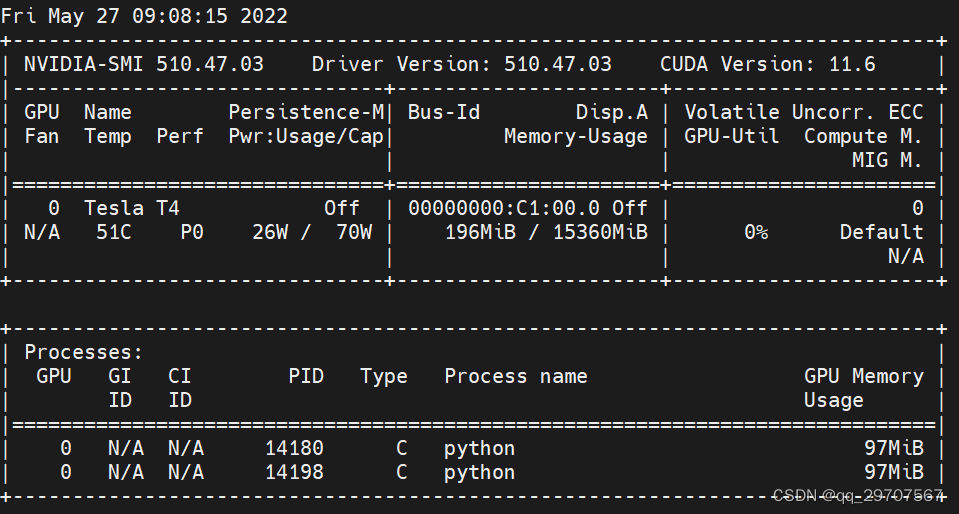 4、nvidia-smi -l #每1s显示gpu的使用情况,追加方式刷新
4、nvidia-smi -l #每1s显示gpu的使用情况,追加方式刷新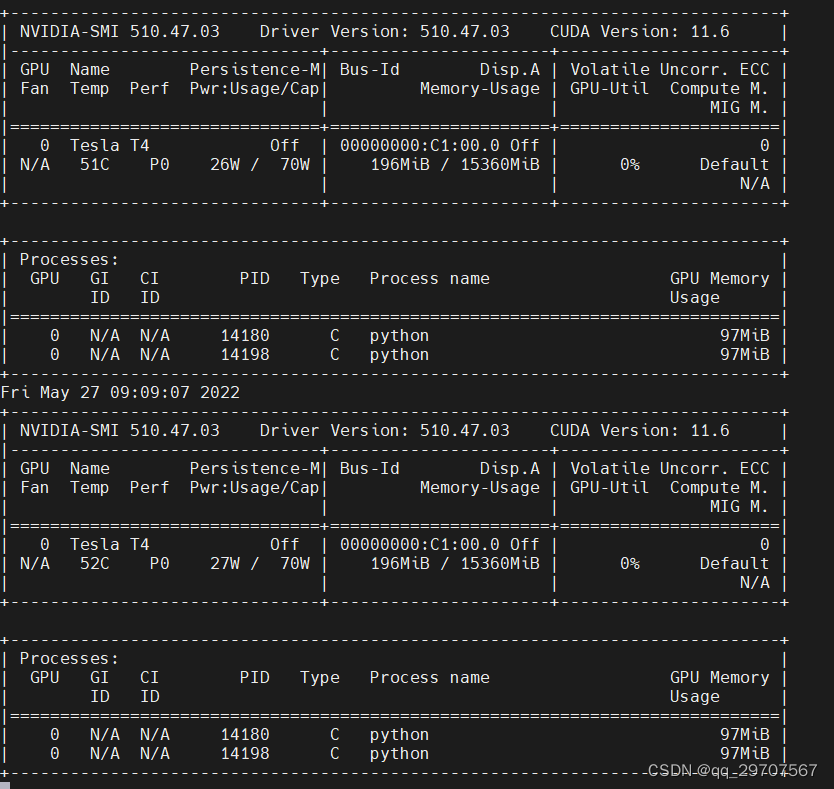
【本文地址】
今日新闻 |
推荐新闻 |