对抗训练的理解,以及FGM、PGD和FreeLB的详细介绍 |
您所在的位置:网站首页 › fgm翻译成中文 › 对抗训练的理解,以及FGM、PGD和FreeLB的详细介绍 |
对抗训练的理解,以及FGM、PGD和FreeLB的详细介绍
|
对抗训练基本思想——Min-Max公式
很简单——梯度上升。所以说,对抗训练本质上来说,在一个step中,实际上进行了两次梯度更新,只不过是被更新的对象是不同的—— 首先先做梯度上升,找到最佳扰动r,使得loss最大;其次梯度下降,找到最佳模型参数(所有层的模型参数,这一步和正常模型更新、梯度下降无异),使loss最小。 具体情况如图所示:
注:所谓“attack”,即: 它是谁:attack就是将已算出的扰动加到embedding上的操作;它从哪来(定位在哪):attack操作是在梯度上升使loss最大、求best扰动r的过程中进行的,它的目的就是看看怎么attack才能得到最佳扰动;它要干啥(作用):对word-embedding层attack后,计算“被attack后的loss”,即对抗loss(adv_loss),然后据此做梯度上升,对attack的扰动r进行梯度更新。 常见的几种对抗训练算法 a. Fast Gradient Method(FGM)
前置:设置PGD的扰动积累步数为K步 计算在正常embedding下的loss和grad(即先后进行forward、backward),在此时,将模型所有grad进行备份;K步的for循环: # 反向传播(计算grad)是为了计算当前embedding权重下的扰动r。同时为了不干扰后序扰动r的计算,还要将每次算出的grad清零 a. 对抗攻击:如果是首步,先保存一下未经attack的grad。然后按照PGD公式以及当前embedding层的grad计算扰动,然后将扰动累加到embedding权重上; b. if-else分支: i. 非第K-1步时:模型当前梯度清零; ii. 到了第K-1步时:恢复到step-1时备份的梯度(因为梯度在数次backward中已被修改); c. 使用目前的模型参数(包括被attack后的embedding权重)以及batch_input,做前后向传播,得到loss、更新grad恢复embedding层2.a时保存的embedding的权重(注意恢复的是权重,而非梯度)optimizer.step(),梯度下降更新模型参数。这里使用的就是累加了K次扰动后计算所得的grad 我个人对PGD和FreeLB的比较:PGD是在累积扰动: PGD每一轮都用上一轮的loss,重新计算扰动r,因为每轮计算完毕后,PGD都会 model.zero_grad(),这导致每一轮算出的新扰动r_t和之前的扰动没有累加关系。这一步步的迭代,其实和经典模型训练一样,经过K次梯度上升,找到最佳 δ \delta δFreeLB每轮计算则不做model.zero_grad(),相当于每轮的 loss.backward()都在param.grad上做累加,不论是delta.grad还是其余模型的model.params.grad都是如此,所以相当于: 根据原始的正常loss -> grad_0根据扰动r_1计算出adv_loss_1 -> grad_1…根据扰动r_k-1计算出adv_loss_k-1 -> grad_k-1但以上grad永远都是在累加的,所以model.params.grad = sum(grad_0, grad_1,…, grad_k-1),所以相当于K轮用了K个不同的、逐渐递进(这个递进指的是越来越“好”、即使adv_loss越来越大的)对抗样本(对抗样本=delta + embeds_init),用它们得到的每一次梯度一起对模型参数进行更新 所以,可以说PGD更精确、更谨慎、更符合梯度上升的一贯作风;FreeLB更粗放、更快,论文原文还说FreeLB此举可以更容易找到最佳扰动r——具体原因是什么,我没参透… PGD”官方“实现 class PGD(): def __init__(self, model, emb_name, epsilon=1., alpha=0.3): # emb_name这个参数要换成你模型中embedding的参数名 self.model = model self.emb_name = emb_name self.epsilon = epsilon self.alpha = alpha self.emb_backup = {} self.grad_backup = {} def attack(self, is_first_attack=False): for name, param in self.model.named_parameters(): if param.requires_grad and self.emb_name in name: if is_first_attack: self.emb_backup[name] = param.data.clone() norm = torch.norm(param.grad) if norm != 0: r_at = self.alpha * param.grad / norm param.data.add_(r_at) param.data = self.project(name, param.data, self.epsilon) def restore(self): for name, param in self.model.named_parameters(): if param.requires_grad and self.emb_name in name: assert name in self.emb_backup param.data = self.emb_backup[name] self.emb_backup = {} def project(self, param_name, param_data, epsilon): r = param_data - self.emb_backup[param_name] if torch.norm(r) > epsilon: r = epsilon * r / torch.norm(r) return self.emb_backup[param_name] + r def backup_grad(self): for name, param in self.model.named_parameters(): if param.requires_grad and param.grad is not None: self.grad_backup[name] = param.grad.clone() def restore_grad(self): for name, param in self.model.named_parameters(): if param.requires_grad and param.grad is not None: param.grad = self.grad_backup[name] PGD训练中使用代码 pgd = PGD(model) K = 3 for batch_input, batch_label in data: # 正常训练 loss = model(batch_input, batch_label) loss.backward() # 反向传播,得到正常的grad pgd.backup_grad() # 对抗训练 for t in range(K): pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data if t != K-1: model.zero_grad() else: pgd.restore_grad() loss_adv = model(batch_input, batch_label) loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度 pgd.restore() # 恢复embedding参数 # 梯度下降,更新参数 optimizer.step() model.zero_grad() c. FreeLB前面实际上已经对FreeLB做了介绍了,这里直接放代码 FreeLB”官方“实现 class FreeLB(object): def __init__(self, adv_K, adv_lr, adv_init_mag, adv_max_norm=0., adv_norm_type='l2', base_model='bert'): self.adv_K = adv_K self.adv_lr = adv_lr self.adv_max_norm = adv_max_norm self.adv_init_mag = adv_init_mag # adv-training initialize with what magnitude, 即我们用多大的数值初始化delta self.adv_norm_type = adv_norm_type self.base_model = base_model def attack(self, model, inputs, gradient_accumulation_steps=1): input_ids = inputs['input_ids'] if isinstance(model, torch.nn.DataParallel): embeds_init = getattr(model.module, self.base_model).embeddings.word_embeddings(input_ids) else: embeds_init = getattr(model, self.base_model).embeddings.word_embeddings(input_ids) if self.adv_init_mag > 0: # 影响attack首步是基于原始梯度(delta=0),还是对抗梯度(delta!=0) input_mask = inputs['attention_mask'].to(embeds_init) input_lengths = torch.sum(input_mask, 1) if self.adv_norm_type == "l2": delta = torch.zeros_like(embeds_init).uniform_(-1, 1) * input_mask.unsqueeze(2) dims = input_lengths * embeds_init.size(-1) mag = self.adv_init_mag / torch.sqrt(dims) delta = (delta * mag.view(-1, 1, 1)).detach() elif self.adv_norm_type == "linf": delta = torch.zeros_like(embeds_init).uniform_(-self.adv_init_mag, self.adv_init_mag) delta = delta * input_mask.unsqueeze(2) else: delta = torch.zeros_like(embeds_init) # 扰动初始化 loss, logits = None, None for astep in range(self.adv_K): delta.requires_grad_() inputs['inputs_embeds'] = delta + embeds_init # 累积一次扰动delta inputs['input_ids'] = None outputs = model(**inputs) loss, logits = outputs[:2] # model outputs are always tuple in transformers (see doc) loss = loss.mean() # mean() to average on multi-gpu parallel training loss = loss / gradient_accumulation_steps loss.backward() delta_grad = delta.grad.clone().detach() # 备份扰动的grad if self.adv_norm_type == "l2": denorm = torch.norm(delta_grad.view(delta_grad.size(0), -1), dim=1).view(-1, 1, 1) denorm = torch.clamp(denorm, min=1e-8) delta = (delta + self.adv_lr * delta_grad / denorm).detach() if self.adv_max_norm > 0: delta_norm = torch.norm(delta.view(delta.size(0), -1).float(), p=2, dim=1).detach() exceed_mask = (delta_norm > self.adv_max_norm).to(embeds_init) reweights = (self.adv_max_norm / delta_norm * exceed_mask + (1 - exceed_mask)).view(-1, 1, 1) delta = (delta * reweights).detach() elif self.adv_norm_type == "linf": denorm = torch.norm(delta_grad.view(delta_grad.size(0), -1), dim=1, p=float("inf")).view(-1, 1, 1) # p='inf',无穷范数,获取绝对值最大者 denorm = torch.clamp(denorm, min=1e-8) # 类似np.clip,将数值夹逼到(min, max)之间 delta = (delta + self.adv_lr * delta_grad / denorm).detach() # 计算该步的delta,然后累加到原delta值上(梯度上升) if self.adv_max_norm > 0: delta = torch.clamp(delta, -self.adv_max_norm, self.adv_max_norm).detach() else: raise ValueError("Norm type {} not specified.".format(self.adv_norm_type)) if isinstance(model, torch.nn.DataParallel): embeds_init = getattr(model.module, self.base_model).embeddings.word_embeddings(input_ids) else: embeds_init = getattr(model, self.base_model).embeddings.word_embeddings(input_ids) return loss, logits FreeLB训练中使用代码 if args.do_adv: inputs = { "input_ids": input_ids, "bbox": layout, "token_type_ids": segment_ids, "attention_mask": input_mask, "masked_lm_labels": lm_label_ids } loss, prediction_scores = freelb.attack(model, inputs) loss.backward() optimizer.step() scheduler.step() model.zero_grad() FreeLB需要注意的点 FreeLB原论文提到,对抗训练本不该和dropout一起使用。原因也比较好理解:如果你使用了dropout,那么每次前向传播时,你都会面对不同的网络结构——因为你也不知道这次哪个神经元会被dropout掉,这就导致,在优化扰动r的梯度上升过程中,你K-step面对的网络结构都不同,相当于在面对K个不同的loss-function在寻找最佳扰动r,这会导致结果的不稳定。作者给出的方案是,在K-step的梯度上升过程中,使用一个确定不变的dropout方案,该方案由θ(m)指定,该函数即服从简单的伯努利分布。这样,相当于既做了dropout,又避免了K次对不同的loss-function进行求导。不过由于上述方案有点麻烦,所以我直接在加入对抗训练时,将dropout设为0。后来发现这种操作会导致结果的下降;而即使让dropout保持原样(注意,BERT-model中有两个dropout参数:attention_probs_dropout_prob、 hidden_dropout_prob ,默认都是0.1),对抗训练依旧会对结果有较大提升。 所以说,综上,我们可将对抗训练整体思想总结为:内层梯度上升优化扰动 δ \delta δ,外层梯度下降优化模型参数 Θ \Theta Θ注:本文所提到的代码,均援引自:https://github.com/lonePatient/TorchBlocks/blob/master/torchblocks/callback/adversarial.py |

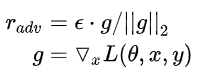

【本文地址】