python+opencv进行表格识别并写入excel中 |
您所在的位置:网站首页 › excel提取数据生成新表格的方法有哪些图片 › python+opencv进行表格识别并写入excel中 |
python+opencv进行表格识别并写入excel中
|
效果图如下: 直接上代码: import cv2 import numpy as np import math import xlwt src='图片路径' raw = cv2.imread(src, 1) # 灰度图片 gray = cv2.cvtColor(raw, cv2.COLOR_BGR2GRAY) binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5) # 展示图片 rows, cols = binary.shape scale2=15 scale = 20 # 自适应获取核值 # 识别横线: kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (cols // scale, 1)) kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT, (cols // scale2, 1)) eroded = cv2.erode(binary, kernel, iterations=1) dilated_col = cv2.dilate(eroded, kernel1, iterations=1) # cv2.imwrite("横线图.jpg", dilated_col) # 识别竖线: # scale = 40#scale越大,越能检测出不存在的线 kernel2 = cv2.getStructuringElement(cv2.MORPH_RECT, (1, rows // scale2)) kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, rows // scale)) eroded = cv2.erode(binary, kernel, iterations=1) dilated_row = cv2.dilate(eroded, kernel2, iterations=1) # cv2.imwrite("竖线图.jpg", dilated_row) # cv2.imwrite("3.png", dilated_row) # 将识别出来的横竖线合起来 bitwise_and = cv2.bitwise_and(dilated_col, dilated_row)#对二值图进行与操作 # cv2.imwrite("交点二值图.jpg", bitwise_and) # 标识表格轮廓 merge = cv2.add(dilated_col, dilated_row) ret,binary = cv2.threshold(merge, 127, 255, cv2.THRESH_BINARY) _,contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) area=[] for k in range(len(contours)): area.append(cv2.contourArea(contours[k])) max_idx = np.argmax(np.array(area)) m_d_r=[] m_u_l=[] max_p=0 min_p=1e6 for l1 in contours[max_idx]: for l2 in l1: if sum(l2)>max_p: max_p=sum(l2) d_r=l2 if sum(l2) 0) # print(xs) # # print('---------------------------------') # print(ys) # 横纵坐标数组 y_point_arr = [] x_point_arr = [] # 通过排序,排除掉相近的像素点,只取相近值的最后一点 # 这个10就是两个像素点的距离,不是固定的,根据不同的图片会有调整,基本上为单元格表格的高度(y坐标跳变)和长度(x坐标跳变) i = 0 sort_x_point = np.sort(xs) # print(sort_x_point) for i in range(len(sort_x_point) - 1): if sort_x_point[i + 1] - sort_x_point[i] > 3: x_point_arr.append(sort_x_point[i]) i = i + 1 # 要将最后一个点加入 x_point_arr.append(sort_x_point[i]) i = 0 sort_y_point = np.sort(ys) for i in range(len(sort_y_point) - 1): if sort_y_point[i + 1] - sort_y_point[i] > 3: y_point_arr.append(sort_y_point[i]) i = i + 1 y_point_arr.append(sort_y_point[i]) h_list=[y_point_arr[i+1]-y_point_arr[i] for i in range(len(y_point_arr)-1)] w_list=[x_point_arr[i+1]-x_point_arr[i] for i in range(len(x_point_arr)-1)] col_alpha=['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] print(h_list) print(w_list) import xlsxwriter workbook = xlsxwriter.Workbook('chineseQA.xlsx') #创建工作簿 worksheet = workbook.add_worksheet() for i in range(len(w_list)): worksheet.set_column('{}:{}'.format(col_alpha[i],col_alpha[i]),w_list[i]/6) for j in range(len(h_list)): worksheet.set_row(j,h_list[j]) def islianjie(p1,p2,img):#p的格式是先y后x if p1[0]==p2[0]: for i in range(min(p1[1],p2[1]),max(p1[1],p2[1])+1): if sum([img[j,i] for j in range(max(p1[0]-5,0),min(p1[0]+5,img.shape[0]))])==0: return False return True elif p1[1]==p2[1]: for i in range(min(p1[0],p2[0]),max(p1[0],p2[0])+1): if sum([img[i,j] for j in range(max(p1[1]-5,0),min(p1[1]+5,img.shape[1]))])==0: return False return True else: return False class cell: def __init__(self,lt,rd,belong): self.lt=lt self.rd=rd self.belong=belong lt_list_x=x_point_arr[:-1] lt_list_y=y_point_arr[:-1] rd_list_x=x_point_arr[1:] rd_list_y=y_point_arr[1:] d={} for i in range(len(lt_list_x)): for j in range(len(lt_list_y)): d['cell_{}_{}'.format(i,j)]=cell([lt_list_x[i],lt_list_y[j]],[rd_list_x[i],rd_list_y[j]],[lt_list_x[i],lt_list_y[j]]) for i in range(len(lt_list_x)): for j in range(len(lt_list_y)): p1=[d['cell_{}_{}'.format(i,j)].rd[1],d['cell_{}_{}'.format(i,j)].lt[0]]#左下点 p2=[d['cell_{}_{}'.format(i,j)].rd[1],d['cell_{}_{}'.format(i,j)].rd[0]]#右下点 p3=[d['cell_{}_{}'.format(i,j)].lt[1],d['cell_{}_{}'.format(i,j)].rd[0]]#右上点 if not islianjie(p1,p2,merge): d['cell_{}_{}'.format(i,j+1)].belong=d['cell_{}_{}'.format(i,j)].belong if not islianjie(p2,p3,merge): d['cell_{}_{}'.format(i+1,j)].belong=d['cell_{}_{}'.format(i,j)].belong crop_list={} for i in range(len(lt_list_x)): for j in range(len(lt_list_y)): crop_list['{},{}'.format(d['cell_{}_{}'.format(i,j)].belong[0],d['cell_{}_{}'.format(i,j)].belong[1])]=d['cell_{}_{}'.format(i,j)].rd w_h_list=[] zmax=0 zmin=1e6 zlt=[] zrd=[] for key in crop_list.keys(): lt=[int(i) for i in key.split(',')] rd=crop_list[key] # print(lt,rd) if sum(rd)>zmax: zrd=rd zmax=sum(rd) if sum(lt) |
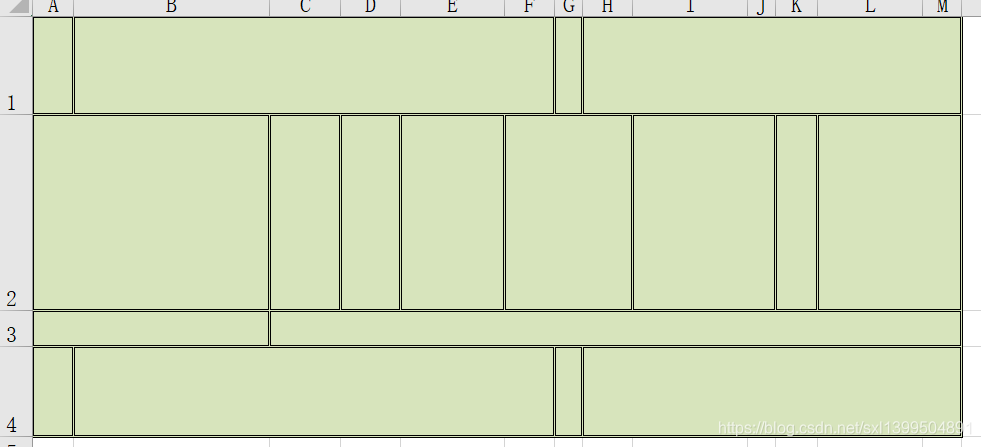
 对于任意图标都不需要自定义模板,直接程序生成,不过需要注意,图中的表格必须是水平的,无法适配倾斜的表格。
对于任意图标都不需要自定义模板,直接程序生成,不过需要注意,图中的表格必须是水平的,无法适配倾斜的表格。【本文地址】
今日新闻 |
推荐新闻 |