[学习笔记]多元线性回归分析 |
您所在的位置:网站首页 › excel多元回归分析步骤2022 › [学习笔记]多元线性回归分析 |
[学习笔记]多元线性回归分析
|
回归分析是数据分析中最基础最重要的分析工具,绝大多数的数据分析问题,都可以使用回归的思想来解决。回归分析的任务就是,通过研究自变量x和因变量y的相关关系,尝试去解释y的形成机制,进而达到通过x去预测y的目的。 常见的回归分析有:线性回归、0-1回归、定序回归、计数回归和生存回归,其划分的依据是因变量y的类型。 本文没有大量的公式推导,更多的是感性的理解(主要是打公式太难了,哭) 1.2回归分析与相关性分析 回归性分析与相关性分析研究的目的不同,相关性是研究两个或者两个以上处于同等地位的随机变量间的相关关系的统计分析方法。例如:人的身高和体重之间。而回归分析侧重于研究随机变量间的依赖关系,以便去用一个变量去预测另一个变量。例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是回归。 1.3 回归分析研究的问题 (i)建立因变量y与自变量x1,x2…xm之间的回归模型(经验公式); (ii)对回归模型的可信度进行检验; (iii)判断每个自变量xi对y的影响是否显著; (iv)诊断回归模型是否适合这组数据; (v)利用回归模型对y进行预报或控制; 可以将回归分析的作用归纳为:识别重要变量、判断相关性的方向、估计权重(回归系数) 2. 基础知识 2.1 数据表的基础知识 2.2数据的标准化处理 2.2.1数据的中心化处理 数据中心化处理就是使得样本的均值变成0,这样不会改变样本点的相互位置,也不改变相关性,却给技术上提供了便利。 2.2.2 数据无量纲化处理 为了使得每一个变量都有同等的表现力,消除量纲效应,在数据分析中对量纲进行压缩处理,使得每个变量的方差变成1,即: 2.2.3 标准化处理 就是对数据同时进行中心化和压缩处理,即; 3. 线性回归模型 3.1 一元线性回归 3.1.1一元线性回归模型与最小二乘法估计 模型: 3.1.2拟合效果的分析 3.1.2.1残差的样本方差 残差是原始数据与对应回归方程的值之间的差值(下图红圈处就是一个残差),残差的样本均值为0,残差的样本方差用MSE来表示(方差之和除以n-2,因为是n-2个自由度)。 3.1.2.2判定系数(拟合优先度) 变异程度(variation)是观测值与一个中心值散布或分散的量。也就是各个值与平均值的差值。在这里用样本方差来描述这种变异。因此我们可以通过观测值的变异程度与回归方程得到的拟合值的变异程度做比较来得到一个数据,用来说明该回归方程拟合的好坏。 3.1.2.3显著性检验 回归模型的线性关系检验: 在拟合回归方程之前,我们曾假设数据总体是符合线性正态误差模型,也就是说y和x之间是线性关系,符合: 回归系数的显著性检验: 对于回归方程的检验包括两个方面:一个是对模型的检验,也就是上面的检验。另一个是对模型的回归参数进行检验,即是检验每一个自变量对因变量的影响程度是否显著。采用的方法是t分布检验。检验过程略。 3.2多元线性回归 3.2.1多元线性回归模型为: 3.2.2 参数估计 同样是用最小二乘法估计,求误差平方和的最小值。求最小值过程略(反正是用计算机算的,笑)。 3.2.3 回归分析的假设检验 就是检验模型是否合理,如同一元线性回归方程的假设检验,针对每个beta进行假设。令H0:beta j=0(j=1,…,m)同样利用F检验。但是注意,接受H0只能说明y与x1…xm的线性关系不明显,可能存在非线性关系。 还有一些衡量y与x1,…,xm 相关程度的指标,如用回归平方在总平方和中的比值定义复判定系数。 4. 利用回归模型进行预测 当回归模型和系数通过检验过后,可由给定的x0(一套x确定值,从回归方程的第一个x1到最后一个xm)预测y0,y0是随机的。 如果是点预测,显然其预测值为: |
 1. 回归分析的概念 1.1回归分析的基本概念 在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。在大数据分析中,回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。
1. 回归分析的概念 1.1回归分析的基本概念 在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。在大数据分析中,回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。 例如在上表中可以看出,我们所涉及的是样本点x变量类型的数据表。如果用m个变量,并进行n次采样,得到n个样本点,就可以用构成的数据表写成一个nxm维的矩阵。 因此对于数据的处理也就是对于矩阵的处理。
例如在上表中可以看出,我们所涉及的是样本点x变量类型的数据表。如果用m个变量,并进行n次采样,得到n个样本点,就可以用构成的数据表写成一个nxm维的矩阵。 因此对于数据的处理也就是对于矩阵的处理。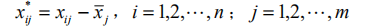
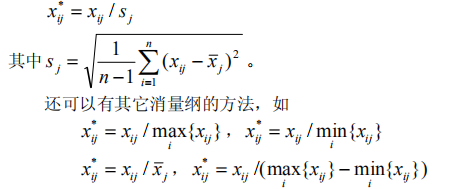
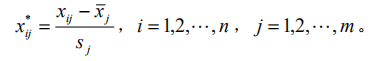
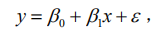 其中beta是回归系数,ε作为随机误差项,且ε服从正态分布。 最小二乘法就如字面意思所说,使得yi与y-hat(y的正上方有一个^)之差(断句)平方和的最小值。这样能够使回归方程尽可能的贴合原始数据。
其中beta是回归系数,ε作为随机误差项,且ε服从正态分布。 最小二乘法就如字面意思所说,使得yi与y-hat(y的正上方有一个^)之差(断句)平方和的最小值。这样能够使回归方程尽可能的贴合原始数据。 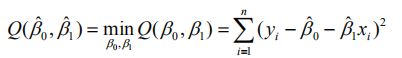 通过多元函数的极值求解方式可以得beta0 和beta1
通过多元函数的极值求解方式可以得beta0 和beta1 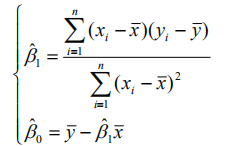 如果原始数据是已经被标准化过后的数据,那么beta0和beta1就有了新的含义。Beta0=0,beta1=rxy,回归方程是y-hat=rxy x,这时beta1可以表示y与x的相关程度。
如果原始数据是已经被标准化过后的数据,那么beta0和beta1就有了新的含义。Beta0=0,beta1=rxy,回归方程是y-hat=rxy x,这时beta1可以表示y与x的相关程度。 判定依据,残差越小说明拟合值与观测值越接近各观测点在拟合直线周围聚集的紧密程度越高,也就是说,拟合方程的能力越强。
判定依据,残差越小说明拟合值与观测值越接近各观测点在拟合直线周围聚集的紧密程度越高,也就是说,拟合方程的能力越强。 判定依据,R2的范围在0到1的闭区间,R2如果等于1说明此时原数据的总变异完全可以由拟合值的变异来解释,并且残差为零( SSE = 0 ),即拟合点与原数据完全吻合;当 0 R^2时,回归方程完全不能解释原数据的总变异, y 的变异完全由与 x无关的因素引起,这时 SSE = SST 。判定系数是一个很有趣的指标:一方面它可以从数据变异的角度指出可解释的变异占总变异的百分比,从而说明回归直线拟合的优良程度;另一方面,它还可以从相关性的角度,说明原因变量 y 与拟合变量 y-hat的相关程度,从这个角度看,拟合变量 y-hat与原变量 y 的相关度越大,拟合直线的优良度就越高。
判定依据,R2的范围在0到1的闭区间,R2如果等于1说明此时原数据的总变异完全可以由拟合值的变异来解释,并且残差为零( SSE = 0 ),即拟合点与原数据完全吻合;当 0 R^2时,回归方程完全不能解释原数据的总变异, y 的变异完全由与 x无关的因素引起,这时 SSE = SST 。判定系数是一个很有趣的指标:一方面它可以从数据变异的角度指出可解释的变异占总变异的百分比,从而说明回归直线拟合的优良程度;另一方面,它还可以从相关性的角度,说明原因变量 y 与拟合变量 y-hat的相关程度,从这个角度看,拟合变量 y-hat与原变量 y 的相关度越大,拟合直线的优良度就越高。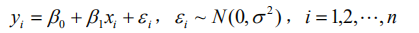 但是我们这样假设是否正确呢?此时我们假设H0:beta1=0,如果H0假设成立则yi=beta0 x+ε(这个模型被称为选模型)。把当beta0≠0时的模型称为全模型(就是上面那个模型)。在分别用最小二乘法拟合全模型和选模型,并求出误差平方和(前者符合公式SSE,后者符合公式SST,因此比较SSE与SST)。 如果全模型的误差不比选模型的误差小多少,即(SST-SSE)差额很小时,说明beta1项没有起多大作用,因此H0成立。如果(SST-SSE)差额很大时,说明了增加x的线性项目之后,拟合方程误差大幅度减小,应该否定H0.认为总体参数 beta1 显著不为零。 至于如何判断这种差额呢?用F检验即可完成。检验过程略。
但是我们这样假设是否正确呢?此时我们假设H0:beta1=0,如果H0假设成立则yi=beta0 x+ε(这个模型被称为选模型)。把当beta0≠0时的模型称为全模型(就是上面那个模型)。在分别用最小二乘法拟合全模型和选模型,并求出误差平方和(前者符合公式SSE,后者符合公式SST,因此比较SSE与SST)。 如果全模型的误差不比选模型的误差小多少,即(SST-SSE)差额很小时,说明beta1项没有起多大作用,因此H0成立。如果(SST-SSE)差额很大时,说明了增加x的线性项目之后,拟合方程误差大幅度减小,应该否定H0.认为总体参数 beta1 显著不为零。 至于如何判断这种差额呢?用F检验即可完成。检验过程略。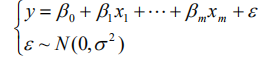 式子中beta0、beta1…betam、Sigma都是与x无关的未知参数,其中beta0、beta1…betam称为回归系数。 现在如果有n个独立观测数据(yi,xi1,… ,xim),i=1,…,n,n>m,即可得到一个n*m的矩阵。
式子中beta0、beta1…betam、Sigma都是与x无关的未知参数,其中beta0、beta1…betam称为回归系数。 现在如果有n个独立观测数据(yi,xi1,… ,xim),i=1,…,n,n>m,即可得到一个n*m的矩阵。 
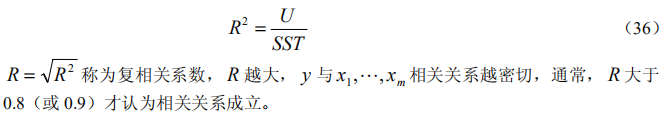 3.2.4回归系数的假设检验和区间估计 针对回归系数的检验,同样是利用t分布对每个beta进行检验,检验过程省略。
3.2.4回归系数的假设检验和区间估计 针对回归系数的检验,同样是利用t分布对每个beta进行检验,检验过程省略。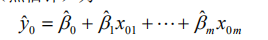 如果是区间预测,可以给定α计算出y0的预测区间,结果较为复杂,但当n较大时x0i接近平均值xi-bar(头上有横线的那种)可以简化为
如果是区间预测,可以给定α计算出y0的预测区间,结果较为复杂,但当n较大时x0i接近平均值xi-bar(头上有横线的那种)可以简化为 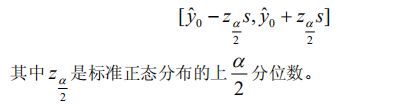
【本文地址】
今日新闻 |
推荐新闻 |