使用Pyspark库读取kafka流数据 |
您所在的位置:网站首页 › etltools消费Kafka › 使用Pyspark库读取kafka流数据 |
使用Pyspark库读取kafka流数据
|
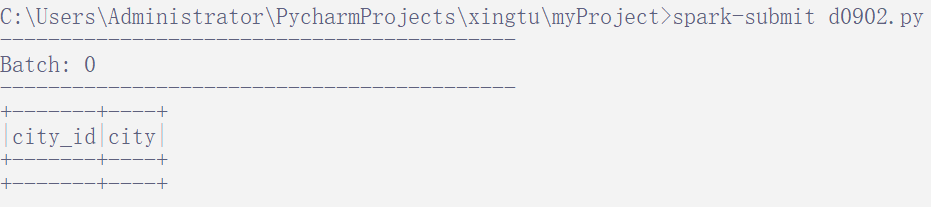
前提条件: 首先我们需要准备5个连接和读取kafka的jar包,放入到 spark 目录的 jars 文件夹中。 commons-pool2-2.9.0.jar:在 Spark、Kafka 等分布式系统中经常用于创建和管理连接池等资源。 spark-streaming-kafka-0-10_2.12-3.0.0.jar:它提供了与 Kafka 集成所需的类和方法,可以从 Kafka 主题中以低延迟、高吞吐量的方式读取和处理数据。 spark-token-provider-kafka-0-10_2.12-3.0.0.jar:这个 JAR 包是 Spark 使用的 Kafka 0.10 版本的令牌提供者。在使用 Spark 与 Kafka 集成时,可能需要提供适当的令牌提供者以进行身份验证和访问控制等安全性操作。 kafka-clients-2.3.0.jar:这是 Kafka 客户端库的 JAR 包,用于与 Kafka 集群进行通信。它提供了处理与 Kafka 相关的核心功能,包括生产者和消费者 API、分区分配、消息序列化和反序列化等。 spark-sql-kafka-0-10_2.12-3.0.0.jar:这是 Spark SQL 与 Kafka 集成的 JAR 包。它提供了与 Kafka 版本集成所需的类和方法,可用于将 Spark SQL 与 Kafka 进行无缝集成,通过 SQL 查询和处理 Kafka 中的数据。 jar包的下载链接:百度网盘 请输入提取码 提取码:ntcf 编写脚本: 基本思路是 1. 先创建spark应用入口,实例化SparkSession; 2. 通过spark读取kafka主题的数据; 3. 通过StructType定义数据的格式; 4. 获取kafka流数据,并且按照上一步定义的格式来解析数据; 5. 对数据进行应用,我这里演示的是将数据再次输出打印到控制台 # 导入 SparkSession 模块,用于创建 Spark 应用程序的入口点 from pyspark.sql import SparkSession # 导入 from_json 函数,该函数用于解析 JSON 数据 from pyspark.sql.functions import from_json # 用于定义 JSON 数据的模式 from pyspark.sql.types import StructType, StructField, StringType, IntegerType # 创建 SparkSession 对象 spark = SparkSession.builder.appName("read_kafka_json").getOrCreate() # Kafka 服务器地址 bootstrap_servers = "192.168.222.132:9092" # 定义 JSON 数据的模式 schema = StructType([ StructField("city_id", IntegerType()), StructField("city", StringType()) ]) # 从 Kafka 中读取流数据并解析 JSON df = spark.readStream.format("kafka") \ .option("kafka.bootstrap.servers", bootstrap_servers) \ .option("subscribe", "test") \ .load() \ .selectExpr("CAST(value AS STRING)") \ #选择 value 列并将其数据类型转换为字符串 .select(from_json("value", schema).alias("data")) \ #将 JSON 字符串解析为结构化的数据,使用给定的模式,并将其重命名为 data .select("data.*") #选择解析后的数据的所有字段 # 将解析后的数据流显示到控制台上,指定输出模式为 “append”,表示在控制台上追加显示新到达的数据 query = df.writeStream \ .outputMode("append") \ .format("console") \ .start() # 等待查询结束,保持 Spark 会话的活动状态,以便持续显示 Kafka 数据 query.awaitTermination()运行脚本: 我们通过 spark-submit 运行脚本文件之后,在控制台会看到我们自己定义的表格结构,只不过数据是空值:
那么我们打开 kafka 服务器的生产者窗口,并且输入对应格式的数据,这里我只是简单的去生成一个数据,你们也可以通过flume或者logstash等采集数据:
然后在我们的spark-submit窗口中,也会同步的看到这个被格式化的数据了:
|


【本文地址】
今日新闻 |
推荐新闻 |